前言
本来计划上一篇是最近的最后一篇,然后,这周手上还分的一点活,按照计划处理完成了,这会顺便跟大家分享下。
内容是java端操作ES做分组、聚合统计。
一、需求场景
其实需求也不复杂,就是一个红外感应的物联网设备进出都有统计上报流水,然后客户提出需要对这些数据进行统计,计算客流数量,进行展示。
二、需求分析
经过沟通确认,这个需求可以沉淀升级为一个通用的流水分组聚合统计接口。拆解结果,接口具体要求:
1、区分项目
2、租户下设备 (分组)
3、设备属性(分组)
4、统计类型 (平均值、求数目、求和)
5、时间过滤 (自定义起止时间、本周、本月、本年)
以上逻辑结果不入库,随时来随时查
于是最终确定:接口需要支持多字段分组、同时多聚合统计、数据时间支持自定义等周期、增加支持项目id传参/从token登录获取项目信息
1.ES索引策略
我们这边的索引策略是设备流水以月构建,前缀标识流水类型,比如设备流水的索引以deviceflow-开头。
2.接口实现逻辑
时间有点紧,不做详细解释,代码上我基本都写了解释。先说下大流程:
1、获取项目id:可以前端传参,可以从登录信息获取,入参又开关字段(基本条件)
2、计算索引:时间区间是必须的,这里支持自定义,或者周期(基本条件)
3、ES查询对象:设置索引信息
4、组织boolQuery查询,设置过滤条件
5、设置包含字段、排除字段、设置查询大小
6、设置分组参数
7、设置聚合统计参数
8、建立ES连接,执行查询
9、解析查询结果
## 3.具体代码 *service实现方法:*
@Override
public List<Map<String, Object>> getDeviceCollectDataAggFromEs(
RequestModel<EsDeviceCollectModel> requestModel) {
Long projectId = requestModel.getCustomQueryParams().getProjectId();
Boolean useTenant = requestModel.getCustomQueryParams().getUseTenant();
List<Map<String, Object>> dataList = new ArrayList<>();
LinkappTenant currentTenant = linkappTenantService.currentTenant();
Assert.notNull(currentTenant, "当前租户为空");
Assert.notNull(currentTenant.getProjectId(), "当前租户项目id为空");
//项目id
if (useTenant) {
//使用登录租户信息
projectId = CommonUtils.parseLong(currentTenant.getProjectId());
}
if (projectId == null) {
log.warn("--设备采集数据周期内按设备、采集类型、聚合类型分组统计项目id为空");
return null;
}
//处理时间
EsDeviceCollectUtil.initRangeTime(requestModel);
//重装后的参数
LOGGER.info("getDeviceCollectDataAggFromEs 重组后的参数:" + JSONObject.toJSONString(requestModel));
//获取索引
String indices = EsCalendar.getDeviceFlowIndex(
requestModel.getCustomQueryParams().getStartTime(),
requestModel.getCustomQueryParams().getEndTime());
//ES查询请求对象
SearchRequest searchRequest = new SearchRequest(indices);
//忽略不可用索引,允许索引不不存在,通配符表达式将扩展为打开的索引
searchRequest.indicesOptions(IndicesOptions.fromOptions(true, true, true, false));
//组织查询条件对象
QueryBuilder boolquery = QueryBuilders.boolQuery();
RestHighLevelClient hclient = eSconfig.getFactory().getRhlClient();
// 查询条件,可以参考官网手册
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
//增加项目ID过滤
boolQuery.must(QueryBuilders.matchPhraseQuery("projectId", projectId));
boolQuery.must(boolquery);
//增加过滤条件
//增加设备编码过滤
String deviceCode = requestModel.getCustomQueryParams().getDeviceCode();
if (org.apache.commons.lang3.StringUtils.isNotBlank(deviceCode)) {
boolQuery.filter(QueryBuilders.termQuery("deviceCode", deviceCode));
}
String ftm = "yyyy-MM-dd HH:mm:ss";
String startTimeStr = cn.hutool.core.date.DateUtil.format(
requestModel.getCustomQueryParams().getStartTime(), ftm);
String endTimeStr = cn.hutool.core.date.DateUtil.format(
requestModel.getCustomQueryParams().getEndTime(), ftm);
//增加时间过滤
boolQuery.filter(
QueryBuilders.rangeQuery("createTime").gte(startTimeStr).lte(endTimeStr).format(ftm));
//查询来源构建
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(boolQuery);
//设置包含字段、排除字段
String[] includeFields = new String[]{
};
String[] excludeFields = new String[]{
"sourceRef"};
searchSourceBuilder.fetchSource(includeFields, excludeFields);
// 取数大小
int index = 0;
int size = 0;
searchSourceBuilder.from(index * size).size(size);
//分组key
List<String> groupKeyList = new ArrayList<>();
//一级分组,按项目id分
String rootGroupKey = "agg-projectId-groups";
TermsAggregationBuilder projectGroupTerm = AggregationBuilders.terms(rootGroupKey)
.field("projectId");
groupKeyList.add(rootGroupKey);
//分组参数
//聚合计算参数
List<String> aggKeyList = new ArrayList<>();
List<String> groupsList = requestModel.getCustomQueryParams().getGroupsList();
if (CollectionUtil.isNotEmpty(groupsList)) {
for (int i = 0; i < groupsList.size(); i++) {
String groupField = groupsList.get(i);
String groupKey = "agg-" + groupField + "-group";
TermsAggregationBuilder groupTerm = AggregationBuilders.terms(
groupKey).field(groupField);
groupKeyList.add(groupKey);
if (i == groupsList.size() - 1) {
//处理聚合计算语义
EsDeviceCollectUtil.initAggFun(groupTerm, requestModel, aggKeyList);
}
projectGroupTerm.subAggregation(groupTerm);
}
} else {
EsDeviceCollectUtil.initAggFun(projectGroupTerm, requestModel, aggKeyList);
}
//查询对象增加计算条件
searchSourceBuilder.aggregation(projectGroupTerm);
searchRequest.source(searchSourceBuilder);
try {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// 查询结果
LOGGER.info("设备数据详情ES请求searchSourceBuilder数据:" + searchSourceBuilder);
LOGGER.info("设备数据详情ES请求数据:" + searchRequest);
SearchResponse searchResponse = hclient.search(searchRequest, RequestOptions.DEFAULT);
stopWatch.stop();
LOGGER.info("查询用时ms:" + stopWatch.getTotalTimeMillis());
//解析查询结果
dataList = EsDeviceCollectUtil.analyzeSearchResponse(searchResponse,groupKeyList,aggKeyList);
} catch (Exception e) {
LOGGER.error("getDeviceCollectDataAggFromEs 搜索ES数据,索引:" + indices + "异常:", e);
}
return dataList;
}
计算索引方法
/**
* @param beginTime 开始时间
* @param endTime 结束时间
* @return 索引拼接,
*/
public static String getDeviceFlowIndex(Date beginTime, Date endTime) {
Assert.isTrue(beginTime.before(endTime),
"开始时间" + cn.hutool.core.date.DateUtil.formatDate(beginTime) + "需小于结束时间"
+ cn.hutool.core.date.DateUtil.formatDate(endTime));
StringJoiner sj = new StringJoiner(",");
while (cn.hutool.core.date.DateUtil.beginOfMonth(beginTime).isBeforeOrEquals(
cn.hutool.core.date.DateUtil.beginOfMonth(endTime))) {
sj.add("deviceflow-" + cn.hutool.core.date.DateUtil.format(beginTime, "yyyyMM"));
beginTime = cn.hutool.core.date.DateUtil.offsetMonth(beginTime, 1);
}
return sj.toString();
}
EsDeviceCollectUtil工具类:
import cn.hutool.core.collection.CollectionUtil;
import cn.hutool.core.date.DateUtil;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.search.aggregations.AggregationBuilder;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.ParsedAggregation;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.aggregations.bucket.terms.Terms.Bucket;
import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder;
import org.elasticsearch.search.aggregations.metrics.avg.ParsedAvg;
import org.elasticsearch.search.aggregations.metrics.sum.ParsedSum;
import org.elasticsearch.search.aggregations.metrics.valuecount.ParsedValueCount;
import org.springframework.util.Assert;
/**
* Es查询工具
*
* @author zhengwen
**/
public class EsDeviceCollectUtil {
public static void initRangeTime(RequestModel<EsDeviceCollectModel> requestModel) {
EsDeviceCollectModel esDeviceCollectModel = requestModel.getCustomQueryParams();
//统计类型
Assert.notNull(esDeviceCollectModel.getCycleTypeEnum(), "统计周期类型不能为空");
EsConstantEnum.CycleTypeEnum cycleTypeEnum = esDeviceCollectModel.getCycleTypeEnum();
Date now = DateUtil.date();
Date startTime = now;
Date endTime = now;
//根据类型重置时间周期
switch (cycleTypeEnum) {
case CUSTOM:
Assert.notNull(esDeviceCollectModel.getStartTime(), "开始时间为空");
Assert.notNull(esDeviceCollectModel.getEndTime(), "结束时间为空");
startTime = DateUtil.beginOfSecond(esDeviceCollectModel.getStartTime());
endTime = DateUtil.endOfSecond(esDeviceCollectModel.getEndTime());
break;
case DAY:
startTime = DateUtil.beginOfDay(now);
endTime = DateUtil.endOfDay(now);
break;
case WEEK:
startTime = DateUtil.beginOfWeek(now);
endTime = DateUtil.endOfWeek(now);
break;
case MONTH:
startTime = DateUtil.beginOfMonth(now);
endTime = DateUtil.endOfMonth(now);
break;
case YEAR:
startTime = DateUtil.beginOfYear(now);
endTime = DateUtil.endOfYear(now);
break;
default:
//未知默认当天?还是抛出异常?
startTime = DateUtil.beginOfDay(now);
endTime = DateUtil.endOfDay(now);
break;
}
esDeviceCollectModel.setStartTime(startTime);
esDeviceCollectModel.setEndTime(endTime);
}
/**
* 初始化处理terms与agg
*
* @param groupTerm 分组term
* @param requestModel 查询入参对象
* @param aggKeyList aggList
*/
public static void initAggFun(TermsAggregationBuilder groupTerm,
RequestModel<EsDeviceCollectModel> requestModel, List<String> aggKeyList) {
List<Map<String, String>> aggList = requestModel.getCustomQueryParams().getAggsList();
if (CollectionUtil.isNotEmpty(aggList)) {
for (int j = 0; j < aggList.size(); j++) {
String aggKey = "";
Map<String, String> aggMap = aggList.get(j);
Iterator<String> it = aggMap.keySet().iterator();
while (it.hasNext()) {
AggregationBuilder tmpAggBuilder = null;
String key = it.next();
String val = aggMap.get(key);
if (org.apache.commons.lang3.StringUtils.isNotBlank(key)
&& org.apache.commons.lang3.StringUtils.isNotBlank(val)) {
switch (val) {
case "avg":
aggKey = "avg_" + key;
tmpAggBuilder = AggregationBuilders.avg(aggKey).field(key);
break;
case "count":
aggKey = "count_" + key;
tmpAggBuilder = AggregationBuilders.count(aggKey).field(key);
break;
case "sum":
aggKey = "sum_" + key;
tmpAggBuilder = AggregationBuilders.sum(aggKey).field(key);
break;
default:
break;
}
if (tmpAggBuilder != null) {
aggKeyList.add(aggKey);
//聚合没有先后
//分组条件连上聚合计算
groupTerm.subAggregation(tmpAggBuilder);
}
}
}
}
}
}
/**
* 解析ES查询结果
*
* @param searchResponse ES查询结果
* @param groupKeyList 分组keyList
* @param aggKeyList 聚合keyList
*/
public static List<Map<String, Object>> analyzeSearchResponse(
SearchResponse searchResponse, List<String> groupKeyList, List<String> aggKeyList) {
List<Map<String, Object>> dataList = new ArrayList<>();
if (CollectionUtil.isNotEmpty(groupKeyList) && CollectionUtil.isNotEmpty(aggKeyList)) {
List<? extends Terms.Bucket> lastBucket = null;
Map<String, Object> groupDataMp = new HashMap<>();
String lastGroupKey = "";
Aggregations aggregations = searchResponse.getAggregations();
for (int i = 0; i < groupKeyList.size(); i++) {
//数据在最里层的buckets里
String groupKey = groupKeyList.get(i);
String[] groupKeyArr = groupKey.split("-");
Terms aggGroups = aggregations.get(groupKey);
List<? extends Terms.Bucket> buckets = aggGroups.getBuckets();
if (CollectionUtil.isNotEmpty(buckets)) {
Terms.Bucket bucket = buckets.get(0);
groupDataMp.put("dataCount", bucket.getDocCount());
aggregations = bucket.getAggregations();
if (i == groupKeyList.size() - 1) {
//最后一级分组
lastGroupKey = groupKeyArr[1];
lastBucket = buckets;
} else {
groupDataMp.put(groupKeyArr[1], bucket.getKey());
}
}
}
//读取最终数据
dataList = readSearchData(lastGroupKey, lastBucket, groupDataMp, aggKeyList);
}
return dataList;
}
/**
* 读取ES查询结果
*
* @param lastGroupKey 最后一个分组key
* @param lastBucket 最里层的bucket
* @param groupDataMp 分组数据map
* @param aggKeyList 聚合key list
*/
private static List<Map<String, Object>> readSearchData(String lastGroupKey,
List<? extends Bucket> lastBucket,
Map<String, Object> groupDataMp, List<String> aggKeyList) {
List<Map<String, Object>> ls = new ArrayList<>();
for (Terms.Bucket bucket : lastBucket) {
if (CollectionUtil.isNotEmpty(aggKeyList)) {
Object obj = new Object();
Map<String, Object> mp = new HashMap<>();
mp.putAll(groupDataMp);
mp.put(lastGroupKey, bucket.getKey());
for (int i = 0; i < aggKeyList.size(); i++) {
mp.put("dataCount", bucket.getDocCount());
String aggKey = aggKeyList.get(i);
//这里值处理count条数处理为long,其余均有可能是小数或整数
ParsedAggregation pa = bucket.getAggregations().get(aggKey);
//解析聚合统计值,其实有些有特殊精度要求可能要做差异处理
obj = parsedAggValue(pa);
mp.put(aggKey, obj);
}
ls.add(mp);
}
}
return ls;
}
/**
* 解析聚合统计值
*
* @param pa 聚合统计值对象
* @return object对象
*/
private static Object parsedAggValue(ParsedAggregation pa) {
Object obj = null;
String pat = pa.getType();
switch (pat) {
case "sum":
ParsedSum sum = (ParsedSum) pa;
double douSum = sum.getValue();
if ("Infinity".equals(douSum + "")) {
//obj = "Infinity";
obj = null;
} else {
obj = BigDecimal.valueOf(douSum);
obj = NumberUtil.bigDecimalRoundHalfUp((BigDecimal) obj, 2);
}
break;
case "avg":
ParsedAvg avg = (ParsedAvg) pa;
double douAvg = avg.getValue();
if ("Infinity".equals(douAvg + "")) {
//obj = "Infinity";
obj = null;
} else {
obj = BigDecimal.valueOf(douAvg);
obj = NumberUtil.bigDecimalRoundHalfUp((BigDecimal) obj, 2);
}
break;
case "value_count":
ParsedValueCount count = (ParsedValueCount) pa;
long countValue = count.getValue();
if ("Infinity".equals(countValue + "")) {
//obj = "Infinity";
obj = null;
} else {
obj = countValue;
}
break;
default:
break;
}
return obj;
}
}
用到的部分对象已脱敏,也不是什么核心对象,就是入参对象,博友可以替换为自己的入参对象,只要能取到对应参数就行。
三、效果
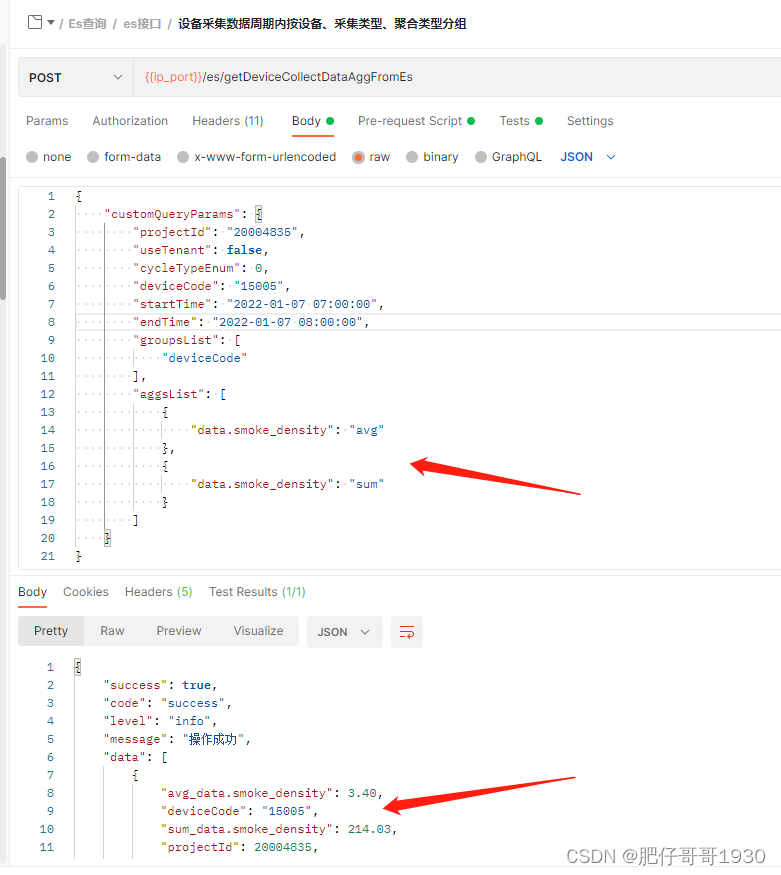
参数解释
{
"customQueryParams": {
"projectId": "20004835", //项目id,非必传
"useTenant": false, //是否使用租户信息,true:通过token读取租户信息获取project,false:使用项目id传参
"cycleTypeEnum": 0, //统计实际周期类型 0自定义(使用传参起止时间) 1本日 2本周 3本月 4本年
"deviceCode": "15005", //设备编码
"startTime": "2022-01-07 07:00:00", //开始时间,非必传
"endTime": "2022-01-07 08:00:00", //结束时间,非必传
"groupsList": [ //分组字段,注意分组字段是data里的,需要data
"deviceCode"
],
"aggsList": [ //聚合统计字段,注意统计字段是data里的,需要data.,key是字段,value是聚合类型
{
"data.smoke_density": "avg"
},
{
"data.smoke_density": "sum"
}
]
}
}
补充个参考:
//根据多列进行分组求和
//根据 任务id分组进行求和
SearchRequestBuilder sbuilder = client.prepareSearch("hottopic").setTypes("hot");
//根据taskid进行分组统计,统计出的列别名叫sum
TermsAggregationBuilder termsBuilder = AggregationBuilders.terms("sum").field("taskid");
//根据第二个字段进行分组
TermsAggregationBuilder aAggregationBuilder2 = AggregationBuilders.terms("region_count").field("birthplace");
//如果存在第三个,以此类推;
sbuilder.addAggregation(termsBuilder.subAggregation(aAggregationBuilder2));
SearchResponse responses= sbuilder.execute().actionGet();
//得到这个分组的数据集合
Terms terms = responses.getAggregations().get("sum");
List<BsKnowledgeInfoDTO> lists = new ArrayList<>();
for(int i=0;i<terms.getBuckets().size();i++){
//statistics
String id =terms.getBuckets().get(i).getKey().toString();//id
Long sum =terms.getBuckets().get(i).getDocCount();//数量
System.out.println("=="+terms.getBuckets().get(i).getDocCount()+"------"+terms.getBuckets().get(i).getKey());
}
//分别打印出统计的数量和id值
//对多个field求max/min/sum/avg
SearchRequestBuilder requestBuilder = client.prepareSearch("hottopic").setTypes("hot");
//根据taskid进行分组统计,统计别名为sum
TermsAggregationBuilder aggregationBuilder1 = AggregationBuilders.terms("sum").field("taskid")
//根据tasktatileid进行升序排列
.order(Order.aggregation("tasktatileid", true));
// 求tasktitleid 进行求平均数 别名为avg_title
AggregationBuilder aggregationBuilder2 = AggregationBuilders.avg("avg_title").field("tasktitleid");
//
AggregationBuilder aggregationBuilder3 = AggregationBuilders.sum("sum_taskid").field("taskid");
requestBuilder.addAggregation(aggregationBuilder1.subAggregation(aggregationBuilder2).subAggregation(aggregationBuilder3));
SearchResponse response = requestBuilder.execute().actionGet();
Terms aggregation = response.getAggregations().get("sum");
Avg terms2 = null;
Sum term3 = null;
for (Terms.Bucket bucket : aggregation.getBuckets()) {
terms2 = bucket.getAggregations().get("avg_title"); // org.elasticsearch.search.aggregations.metrics.avg.InternalAvg
term3 = bucket.getAggregations().get("sum_taskid"); // org.elasticsearch.search.aggregations.metrics.sum.InternalSum
System.out.println("编号=" + bucket.getKey() + ";平均=" + terms2.getValue() + ";总=" + term3.getValue());
四、总结
- ES还是强啊,比关系型数据库做分组聚合快多了
- 大数据的流程都差不多,基本思路都是数据初筛查 + filter,以前搞Hbase也是scan + filter
- 其实idea、DBeaver等都是有连接ES的支持的,通过x-pack-sql-jdbc连接的,无奈我们的版本太低,目测至少要6.8才支持
- 我这里的聚合数据一定是在分组里,也就是最内层的bucket里,解析思路博友们可以细细看下
这真的是最近的最后一篇了,希望能帮到大家,加油技术人!