目录
事务
multi,exec,discard
redis事务是一个单独的隔离操作:事务中的所有命令都会序列化,按顺序地执行。事务在执行的过程中,不会被其它客户端发送来的命令请求所打断。Redis事务的主要作用就是串联多个命令防止别的命令插队
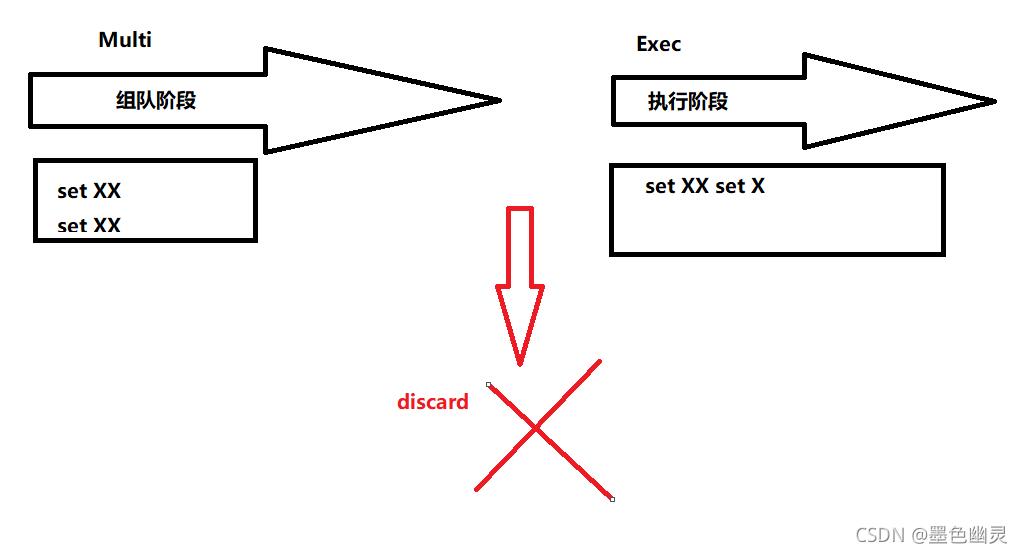
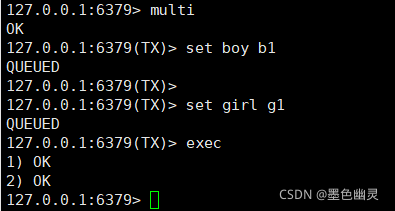
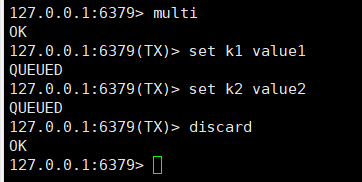
从输入Multi命令开始,输入的命令都会依次进入命令队列中,但不会执行,直到输入Exec后Redis会将之前的命令队列中的命令依次执行。组队过程中可以通过discard来放弃组队。
事务错误处理
组队中某个命令 出现错误,执行时整个的所有队列都会被取消
执行中某个命令报出错误,则只有报错命令不会执行,而其它命令都会执行
事务特性
单独的隔离操作;
没有隔离级别概念
不保证原子性
事务冲突,锁操作(乐观锁和悲观锁)
事务冲突
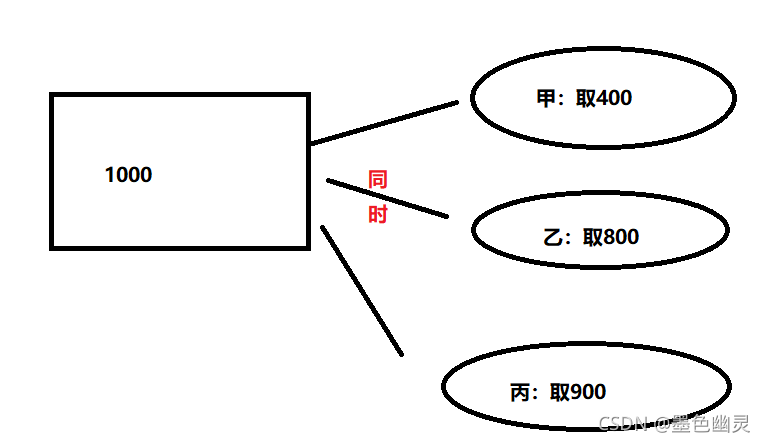
悲观锁:
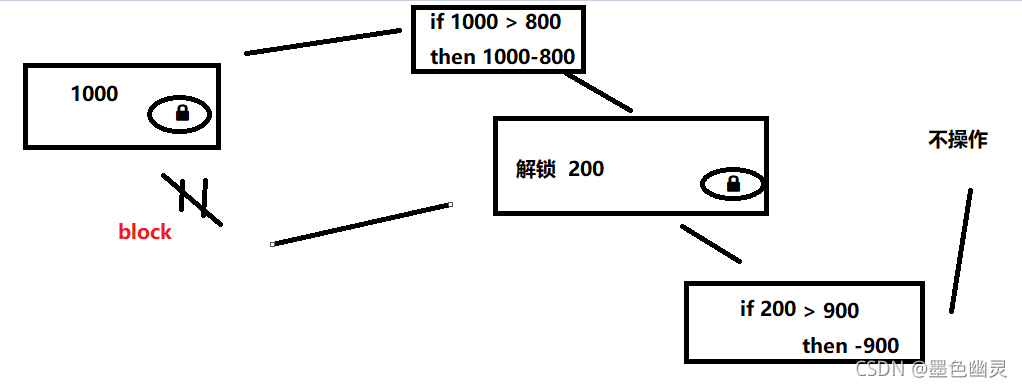
每次拿数据都认为别人会修改,所以每次拿数据时都上锁
乐观锁
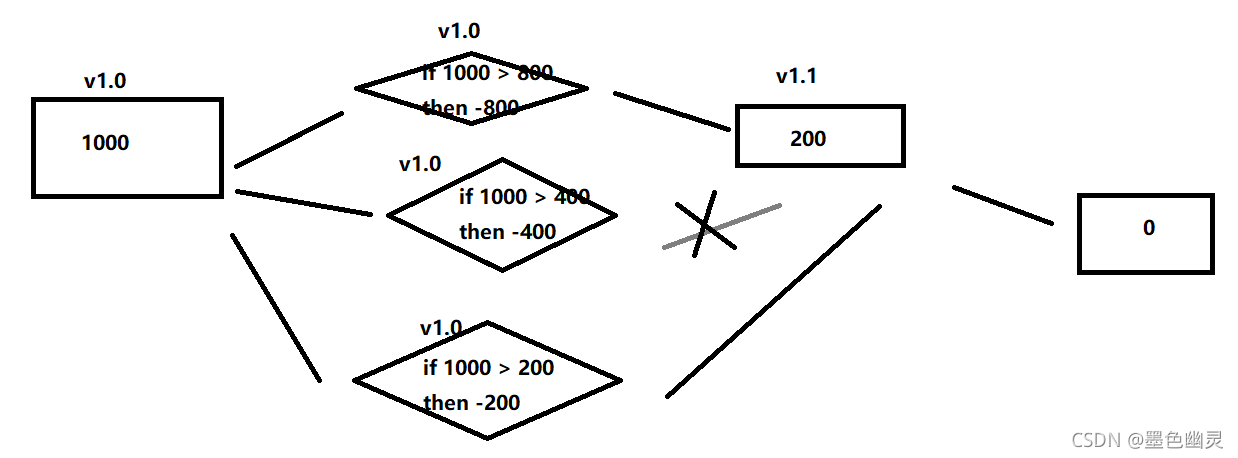
根据版本号来操作。
案例:超卖
package com.redis.demo.test;
import com.redis.demo.conf.JedisPoolUtil;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.Transaction;
import java.io.IOException;
import java.util.List;
public class TestKiller {
public static void main(String[] args) {
}
public static boolean doSecKill(String uid,String prodid) throws IOException{
/*uid和prodid非空判断*/
if(uid ==null || prodid == null){
return false;
}
/*连接redis,单例模式*/
JedisPool jedisPool = JedisPoolUtil.getJedisPoolInstance();
Jedis jedis = jedisPool.getResource();
/*设置key*/
/*库存key*/
String kcKey = "sk" + prodid + ":qt";
/*秒杀成功用户*/
String userKey = "sk" + prodid + ":user";
/*获取库存*/
String kc = jedis.get(kcKey);
/*监视库存*/
jedis.watch(kcKey);
if(kc == null){
System.out.println("秒杀还没有开始,请等待");
jedis.close();
return false;
}
/*获取用户是否重复秒杀*/
if(jedis.sismember(userKey,uid)) {
System.out.println("已经成功秒杀,不必重复秒杀");
}
/*判断库存是否小于1*/
if(Integer.parseInt(kc) <= 0){
System.out.println("秒杀结束");
jedis.close();
return false;
}
/*秒杀过程*/
/*使用事务*/
Transaction multi = jedis.multi();
/*组队操作*/
multi.decr(kcKey);
multi.sadd(userKey,uid);
/*执行*/
List<Object> results = multi.exec();
if(results == null || results.size() == 0){
System.out.println("秒杀失败");
return false;
}
System.out.println("succeed");
return true;
}
}
Redis持久化
(这部分不是很详细,更详细要查找更多博客)
RDB
在指定时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。
备份如何执行?
创建(fork)一个子进程来进行持久化,先将数据写入到一个临时文件中,待持久化过程结束了,再用这个临时文件替换上次持久化好的文件,整个过程主进程不进行任何IO操作。如果需大规模数据恢复,RDB方式要比AOP更高效,RDB缺点是最后一次持久化后的数据可能丢失.。
AOP
AOF :Redis 默认不开启。它的出现是为了弥补RDB的不足(数据的不一致性),所以它采用日志的形式来记录每个写操作,并追加到文件中。Redis 重启的会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
改成yes开启

结束这个进程,然后到另一个客户端查看:

文件存在了
AOP和RDB同时开启时,系统默认取AOP数据
主从复制
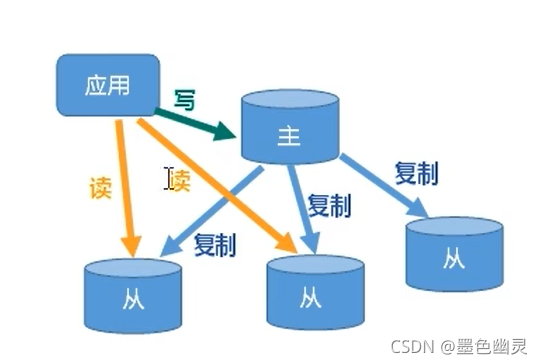
读写分离,主机做写操作,从机做读操作
创建一主二从
新建文件夹,配置三个文件,路径如下(路径随意):(这个redis.conf是复制过去的)
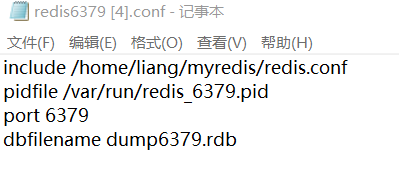
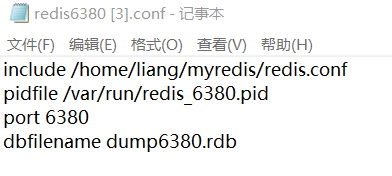
然后看看各个文件配置(这里在xftp上用记事本编辑了),其它文件也一致,只是要改成相应端口号:
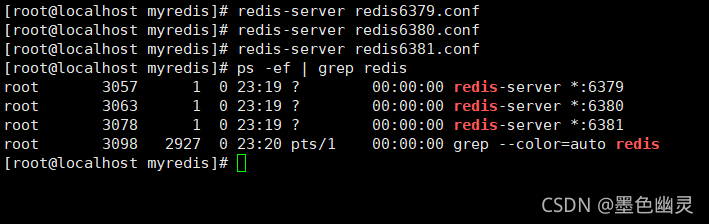
启动它们,查看情况
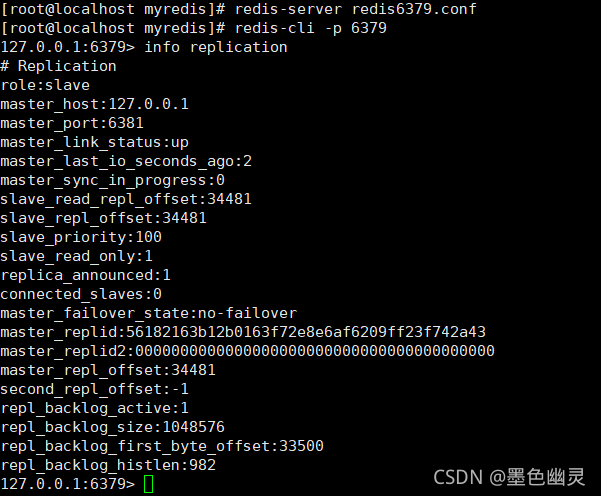
用三个窗口分别连接:redis-cli -p 端口号
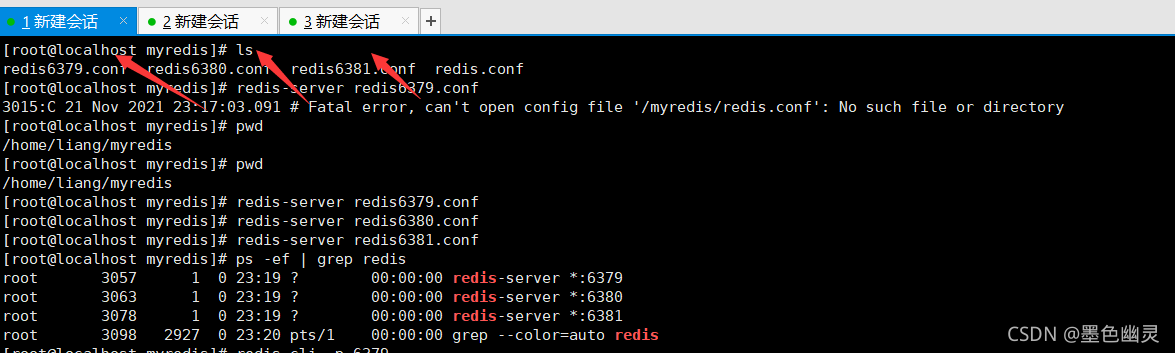
输入info replication
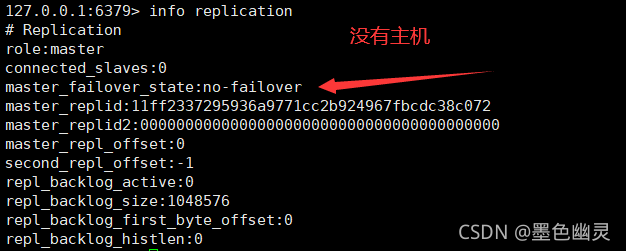
没有配置相关的从和主
配置主从
在从机上执行 slaveof 主机ip 端口号

在6380执行后,查看主从情况:
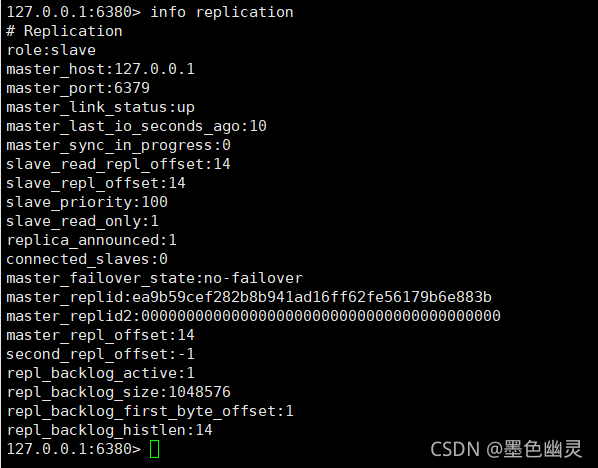
可以看到,主机信息添加上去了;
主机情况如下:
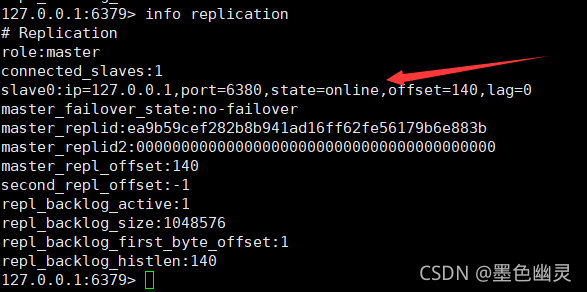
同理,配置6381的,再info查看:

测试
尝试在从机上 写操作,但失败了

当从服务器挂掉,重新启动需要从新主从配置,当配置完成后数据同步;
当主服务器挂掉,从服务器仍知道主服务器信息,重启后,主服务器仍然知道从服务器信息
复制原理:
1、当从连接上主,从服务器向主服务器发送进行同步信息
2、当主服务器接到从服务器发送过来同步消息,把主服务器数据进行持久化rdb文件,把rdb文件发送从服务器,从服务器拿到rdb文件进行读取
3、每次主服务器进行写操作后,和从服务器进行数据同步
薪火相传
反客为主
slaveof no one
从机执行此命令变为主机
哨兵模式
一主二从的前提下,
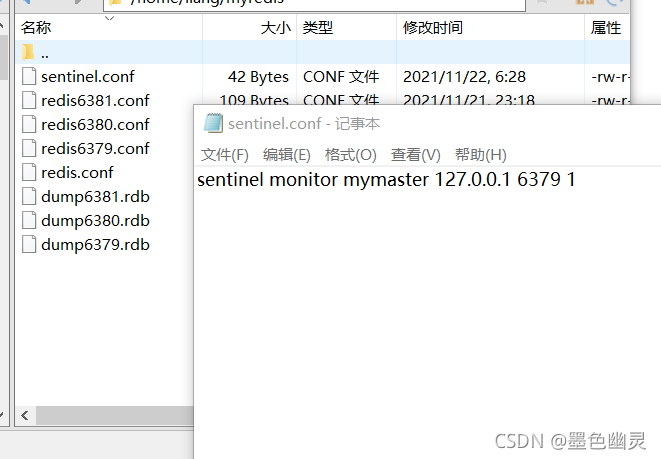
自定义目录/myredis 目录下新建sentinel.conf文件,名字不能错,添加如图内容:
再开一个窗口,执行
redis-sentinel.conf
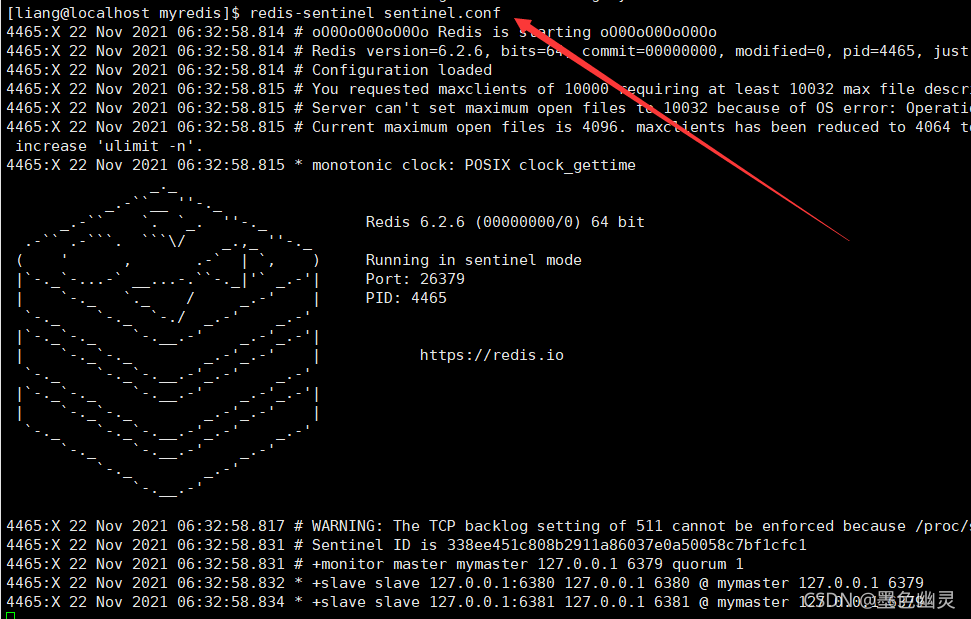
测试一下
将6379shutdown了,在哨兵控制台有输出

在6381也可以看到,主机变成6381了
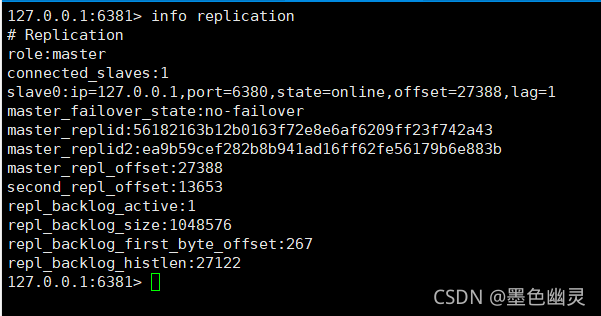
重启6379,发现6379为6381的从机
选择条件
1、选择优先级靠前的:在redis.conf中默认:slave-priorty 100,值越小优先级越高(replica-priority)
2、偏移量:指获得原主机数据最全的
3、选择runid最小的从服务,每个redis实例启动后会随机生成一个40位的runid
集群
集群搭建
实现对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。Redis集群通过分区来提供一定程度的可用性,即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令要求。
创建6个conf文件,并添加如下内容”

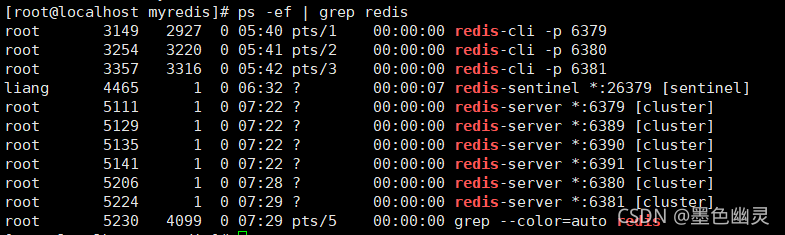
启动这六个redis
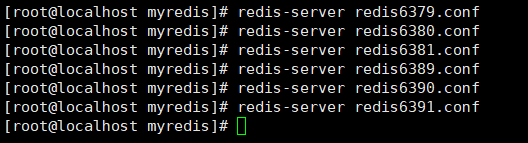
确认一下是否全部启动成功
合体
先找到安装目录下src
cd /opt/redis-6.2.6/src
然后输入:
redis-cli --cluster create --cluster-replicas 1 192.168.19.133:6379 192.168.19.133:6380 192.168.19.133:6381 192.168.19.133:6389 192.168.19.133:6390 192.168.19.133:6391
这里的1表示集群的模式
结果如下(省略很多打印内容):
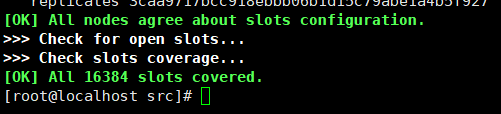
集群连接:
这里用6380,6381等都可以

看节点信息,可看到主从

集群操作
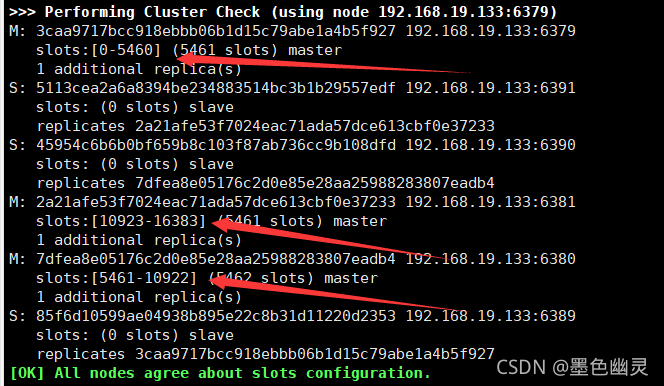
分配原则:尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
slots:插槽
来看看上面完成集群时的显示,有个19384slots
表明一个Redis集群包含16384个插槽(hash slot),数据库中每个键都属于这16384个插槽的其中一个。
集群使用公式CRC16(key) % 16384 来计算key属于哪个槽;
集群中的每个节点负责处理一部分插槽
测试:

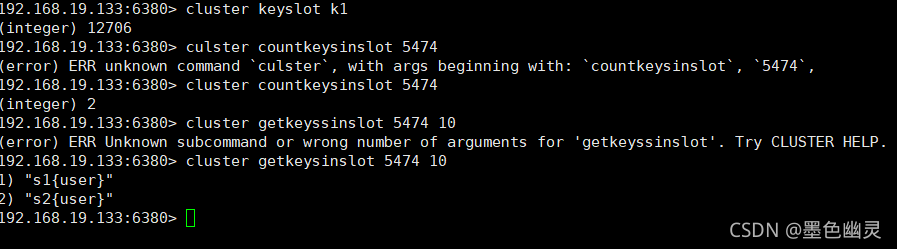
设一个值,它到6381去操作了,因为k1的插槽是在6381,
但是不能使用mset,可以用以下方式设置:

查询集群中的值
故障恢复
缓存穿透、缓存击穿
分布式锁
set users 10 nx ex 12
设置users的值为10,并设置锁和过期时间为12
新功能
ACL
IO多线程
工具支持Cluster