概念
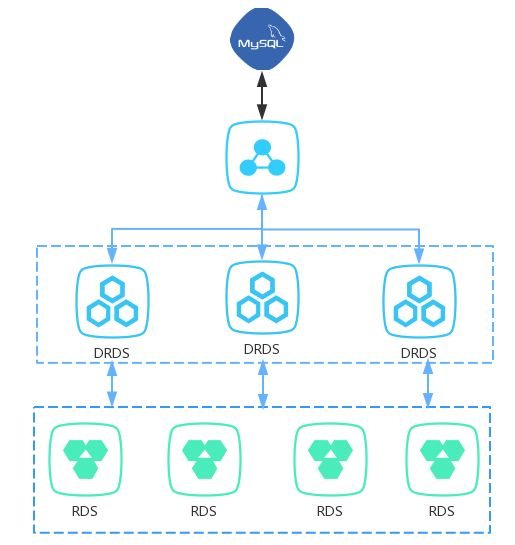
对于DRDS的数据库的分表,查询时SQL中的where条件尽量会带上分库分表键,这样DRDS会将这个查询路由到具体的分库中,以提高查询效率。如果SQL的where条件中没有分库分表键,DRDS会进行一次全表扫描。
针对这种场景,DRDS提供了异构索引来解决这个问题。异构索引会将源表数据实时同步到按照不同字段分库分表的目标表中,以达到使用不同的分库分表键查询数据都不会走全表扫描的目的。
什么是“异构索引表”?
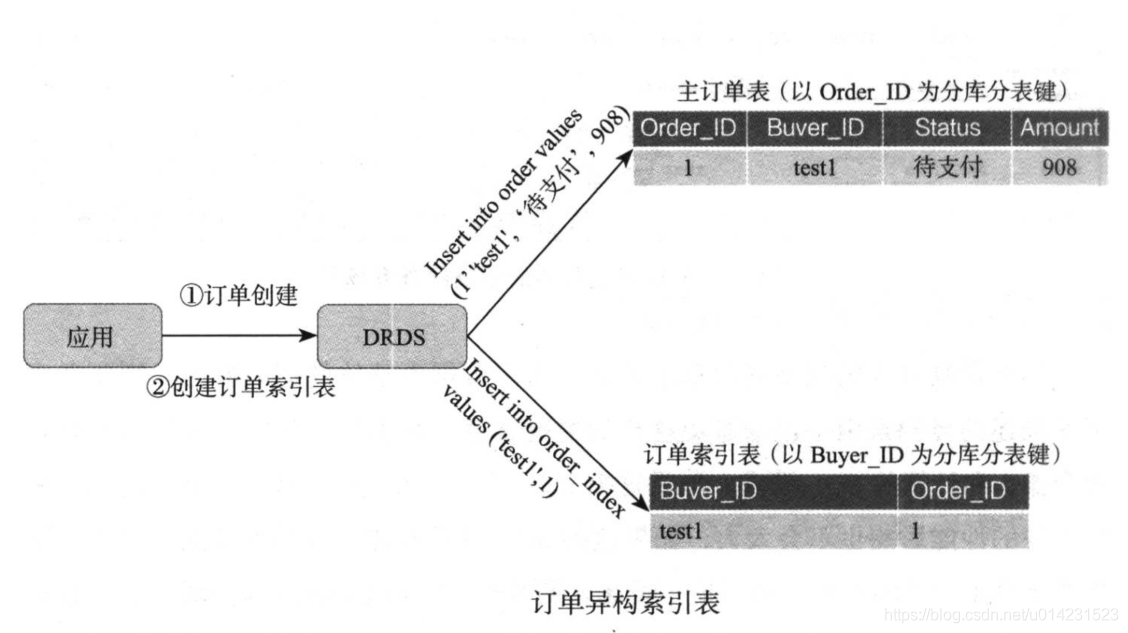
也就是应用在创建或者更新一条订单ID为分库分表键的订单数据时,会保存一份按照买家ID为分库分表键的订单索引数据,其结果就是:同一买家的所有订单索引表都保存在统一数据库中,这就是给订单创建了“异构索引表”。
典型的异构索引应用场景:电商网站的订单表
在DRDS中创建结构相同分表键不同的两张表,分别按照买家ID和卖家ID来分库分表,底层将数据实时的从源表同步到目标表,不同用户登录查询时去对应表中查找,避免全表扫描。
正文
下面以大家最为熟悉的电商订单数据拆分为例。一般记录一条订单数据结构如下:

基于订单数据的分库分表场景,按照订单id取模虽然很好地满足了订单数据均匀地保存在数据库中,但在买家查看自己订单的业务场景中,就出现了全表扫描的情况,而且买家查看自己订单的请求是非常频繁的,必然给数据库带来扩展和性能的问题,有违“尽量减少事务边界”这一原则。
针对这类场景问题,最常用的是采用“异构索引表”的方式解决,即采用异步机制将原表的每一次创建或更新,都换另一个维度保存一份完整的数据表或索引表。这是另一种解决思路:拿空间换时间。
也就是应用在穿件或更新一条订单ID为分库分表键的订单数据时,也会再保存一份按照买家ID为分库分表键的订单索引数据,其结果就是同一买家的所有订单索引表都保存在同一数据库中,这就是给订单创建了异构索引表。
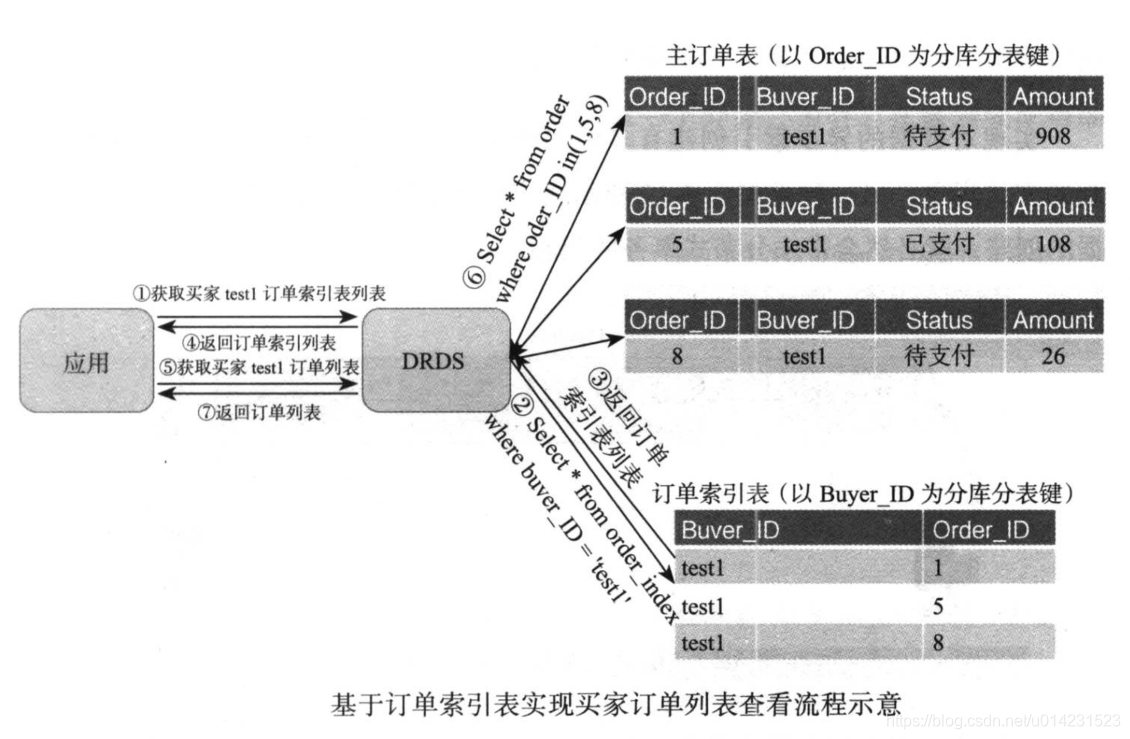
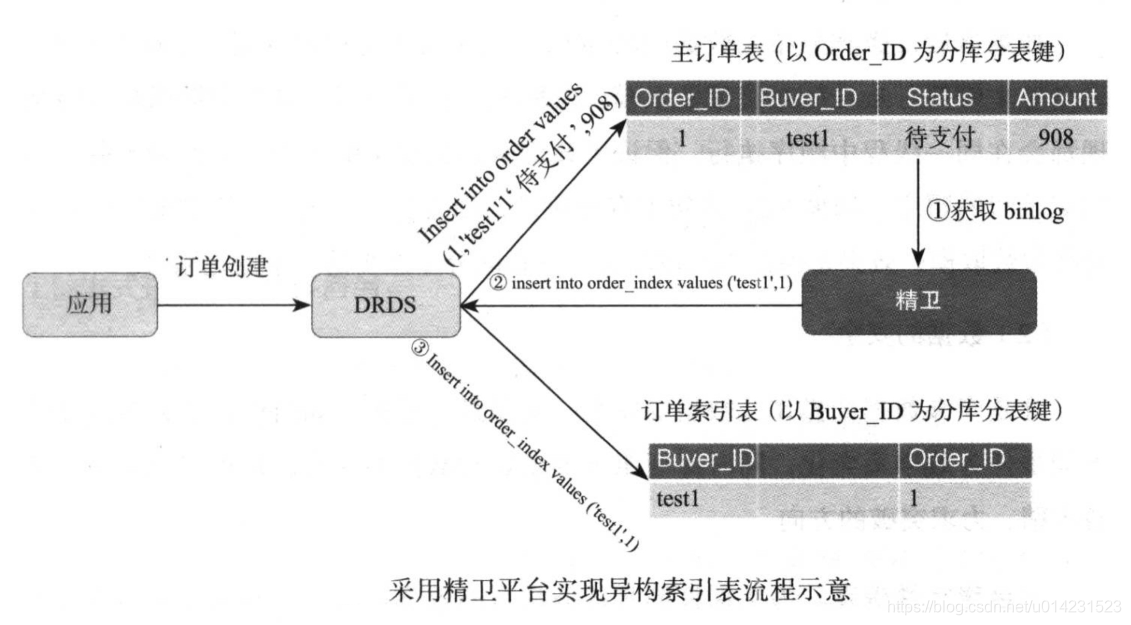
这时再来看看买家test1在获取订单信息进行页面展示时,应用对于数据库的访问流程就发生了如下图的变化。
在有了订单索引表后,应用首先会通过当前买家id(以图中test1为例):
- 首先到订单索引表中搜索出test1的所有订单索引表(步骤1),
- 因为步骤2的sql请求中带了以buyer_id的分库分表键,所以一次是效率最高的单库访问,
- 获取到了买家test1的所有订单索引表列表并由DRDS返回到前端应用(步骤3和4),
- 应用在拿到返回的索引列表后,获取到订单id列表(1,5,8),
- 再发送一次获取真正订单列表的请求(步骤5),
- 同样在步骤6的sql语句的条件中带了分库分表键order_id的列表值,所以DRDS可以精确地将此SQL请求发送到对应订单id的数据库中,而不会出现全表扫描的情况。最终通过两次访问效率最高的sql请求代替了之前的需要进行全表扫描的问题。
这是有人可能会指出,为什么不是将订单的完整数据按照买家id维度进行一次分库保存,这样就只需要进行一次按照买家id维度进行数据库的访问就获取到订单的信息了?
这是一个好问题,其实淘宝的没订单数据就是在异构索引表中全复制的,即订单按照买家id维度进行分库分表的订单索引表跟以订单id维度进行分库分表的订单表中的字段完全一样,这样确实避免了多一次的数据库访问。但一般来说,应用可能会按照多个维度创建多个异构索引表,如果全部采用全复制的方法会带来大量的数据冗余,从而增加不少数据存储成本。
另外,在某些场景中,在获取主业务的列表时,可能需要依赖此业务表所在数据库的子业务表信息,比如订单示例中的主、子订单,因为是以订单id的维度进行分库分表,所以该订单相关的子订单、订单明细表都会保存在同一个数据库中,如果我们仅仅是对主订单信息进行查询获取包含了子订单信息的订单列表时,就会出现跨库join的问题,其对分布数据层带来的不良影响其实跟之前所说的全表扫描是一样 的。所以还是建议采用仅仅做异构索引表,而不是数据全复制。
实现对数据的异构索引创建有多种实现方式:
- 一种是数据库层采用数据复制的方式实现;
- 另一种是如图所示,在应用层实现,在这一层实现异构索引数据的创建,就必然会带来分布式事务的问题。
这里给大家介绍的是目前阿里内部使用的方式,命名为精卫(精卫填海)。
1、精卫
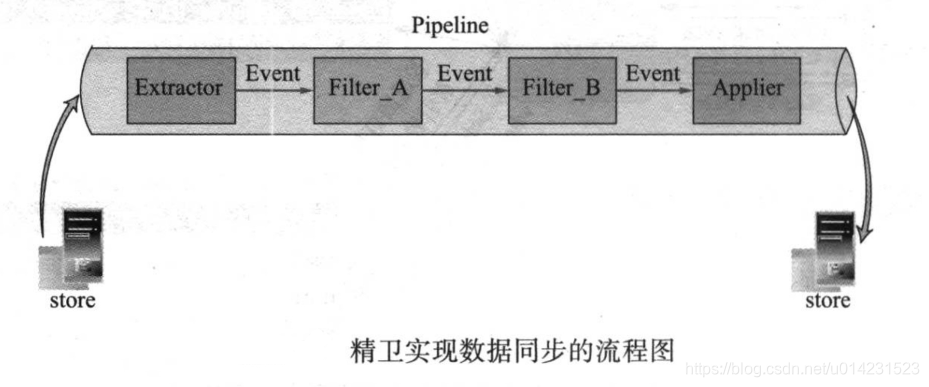
精卫是一个基于Mysql的实时数据复制框架,也可以认为是一个Mysql的数据触发器+分发管道。
精卫通过抽取器(Extractor)获取到订单数据创建在Mysql数据库中产生的binlog日志,并转换为event对象,然后通过过滤器Filter(比如字段过滤、转换等)或基于接口自定义开发的过滤对event对象中的数据进行处理,最终对分发器Applier将结果转换为发给DRDS的sql语句。
通过精卫实现异构索引数据的过程如图:
2、多线程管道实现
简单提一句:
在精卫早期,数据的同步均采用单线程管道任务模式。但是随着业务的发展,需要同步的数据量越来越大,单纯的单线程管道任务已成为系统瓶颈,后来开发了对多线程的支持。
但多线程管道就会带来数据同步的问题。在对binlog数据进行多线程并行处理后,就不能保证在源数据库中执行的SQL语句在目标数据库的顺序一致,这样在某些场景中一定会出现数据不一致性的问题。对于这个问题,目前精卫中提供的解决思路是保证同一条记录或针对同一分库分表发生的数据同步按照顺序执行。
如果最后发送到分布式数据层的SQL语句中没有分库分表键,则通过对“库名+表名+主键值”哈希后对线程数取模,这样就能让同一条记录的数据同步事件处理都会在同一线程中顺序执行,保证了该记录多次变更的顺序性,但是不能保证不同记录间的顺序。
如果sql语句中有分库键,则通过“库名+分库键值”哈希后对线程取模,效果是保证不同逻辑表针对相同分库逻辑的记录变化顺序。