
通常来说,Redis 一共有 6 种缓存淘汰策略,其中,常用的 allkeys-lru 和 volatile-lru 里面都提到了 LRU 的概念,实际上 LRU 就是缓存淘汰策略的基础算法。现在,就由 LRU 引出今天要说的话题:学习 LRU、LFU、FIFO 算法原理,了解缓存淘汰策略的真相。
正文
LRU、LFU、FIFO 算法的含义:
- FIFO:First In First Out,先进先出,淘汰最早被缓存的对象;
- LRU:Least Recently Used,淘汰最长时间未被使用的数据,以时间作为参考;
- LFU:Least Frequently Used,淘汰一定时期内被访问次数最少的数据,以次数作为参考;
这些算法在不同层次的缓存上执行时拥有不同的效率和代价,需根据具体场合选择最合适的一种。
1. FIFO
FIFO(First in First out),先进先出,这个概念在队列 Queue 里也提到过,它的核心原则就是:如果一个数据最先进入缓存中,则应该最早淘汰掉。
最常见是实现是使用一个双向链表保存数据:
- 新访问的数据插入FIFO队列尾部,数据在FIFO队列中顺序移动;
- 如果Cache存满数据,则把队列头部数据删除,然后把新的数据添加到队列末尾;
- 在访问数据的时候,如果在Cache中存在该数据的话,则返回对应的value值,否则返回-1。
结构图如下:

2. LRU
LRU 表示以时间作为参考,淘汰最长时间未被使用的数据。其核心思想是:如果数据最近被访问过,那么将来被访问的几率也更高。
LRU 也是最常用的淘汰策略,在 Redis 中不管是 allkeys-lru 和 volatile-lru,其实底层原理都一样。
最常见的实现是使用一个链表保存缓存数据:
- 新访问的数据插入到链表头部;
- 每当缓存命中(即链表数据被访问),将该数据从新插入到链表头部;
- 当链表满的时候,将链表尾部的数据(不常用数据)丢弃。
结构图如下:

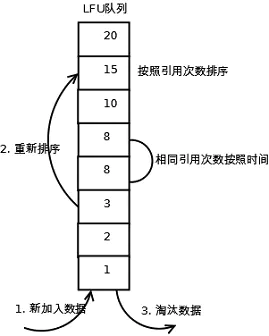
3. LFU
LFU 表示以次数为参考,淘汰一定时期内被访问次数最少的数据,其核心思想是:如果数据过去被访问多次,那么将来被访问的频率也更高。
- 新加入数据插入到队列尾部(引用计数初始值为 1);
- 当队列中的数据被访问后,引用计数 +1,队列按次数重新排序;
- 当需要淘汰数据时,将排序的队列末尾的数据(访问次数最少)删除。
结构图如下:
补充:
1.Two queues(2Q)
阅读文章时看到有人介绍了一种 Two queues(2Q)的算法,我在源码中没有找到,但是看原理确实没问题,补充在这里:

2Q 算法由2种队列(FIFO队列和LRU队列)结合而成,其核心思想是:两个队列各自按照自己的方法淘汰数据,又避免了各自算法中的劣势:
- 当数据第一次访问时,数据先被插入到前置的 FIFO 队列;
- 如果数据在 FIFO 队列中一直没有被再次访问,则最终按照 FIFO 规则淘汰;
- 如果数据在 FIFO 队列中被再次访问,则将数据移到 LRU 队列头部,此后按照 LRU 规则淘汰。