一、背景
因工作需要,开发人员(我)需要对自己开发的一些接口进行高并发压力测试。并根据压力测试出来的性能问题针对性解决。
压测不通过的问题有很多种,优化点也有很多。本文只讨论关于JVM能够优化的点。
本文主要记录解决问题的思路,以及用到的方法,给出的解决方案并不能作为其他任何问题的参考。
二、压测指标
使用JMeter进行压力测试。压测指标为:
- 并发线程数:400
- 思考时间:0秒
- 步长:5秒
- 并发时长:60min
如何使用JMeter的压力测试和压测指标的概念,可以看我写的另一篇文章,或者自行百度。
三、前置知识准备
Eclipse MemoryAnalyzer
这是一款Eclipse旗下的 Java内存分析器。可以在网上自行百度并下载。
抓Dump文件
Dump文件概念如下图
如何抓取内存镜像呢?可以使用下面的命令
jmap -dump:format=b,file=文件名
抓取Dump文件的时机?
jmap命令抓取的是当前的内存快照。比如经过一次压测,直接把对应的Docker容器压的OOM了,此时压测不要停,然后立刻执行 jmap 命令,抓取此时此刻的内存快照。就可以维持事故现场。
四、定位问题并进行解决
首先启动 二、压测指标这一节的高强度压测,在压测的过程中,首先我们在Docker容器中使用了 jps命令查看Java进程:

然后使用jstat -gcutil 117 1000命令,117是进程号,1000是ms,也就是每秒钟打印一次。
jstat命令是对Java应用程序的资源和性能进行实时的命令行的监控,包括了对Heap size和垃圾回收状况的监控。
使用jstat实时监控的结果如下图(图中的单位是百分比):
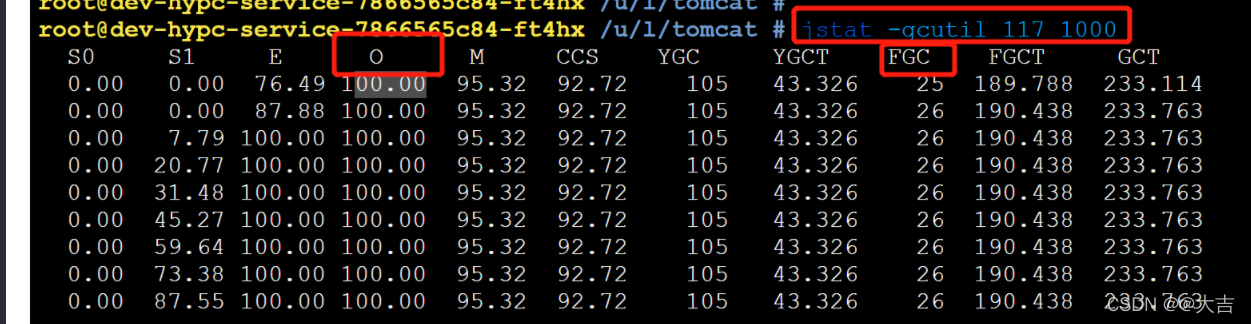
上图中的统计图表,我们只需要关心O区域(Old老年代,单位是百分比),和FGC(Full GC,单位是次数)。
上图给我们呈现的结果是:经过不停的压力测试,老年代内存已经居高不下了,而且频繁Full GC,且每次GC 并不能释放掉O区内存。这说明引用未被释放,可能是内存泄漏问题引起的。
科普一下内存泄露和内存溢出:

使用MemoryAnalyzer进一步分析
现在看来,容器已经被我们压爆了。此时不要停掉压测,而是抓取Dump文件。将该dump文件导入 MemoryAnalyzer工具,进行分析。
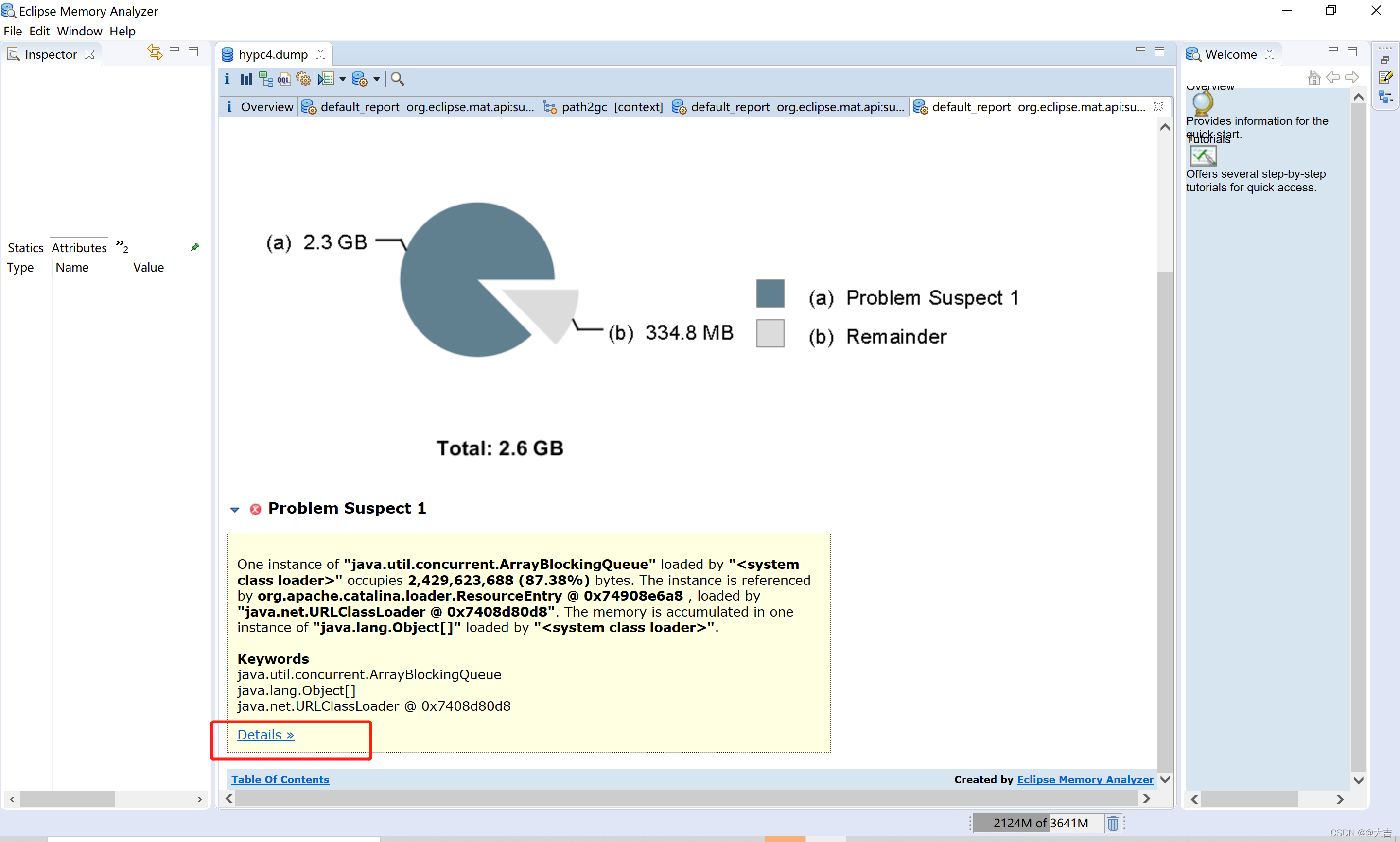
导入完成之后,利用MemoryAnalyzer 的 leak suspects功能分析可能泄露的图表:
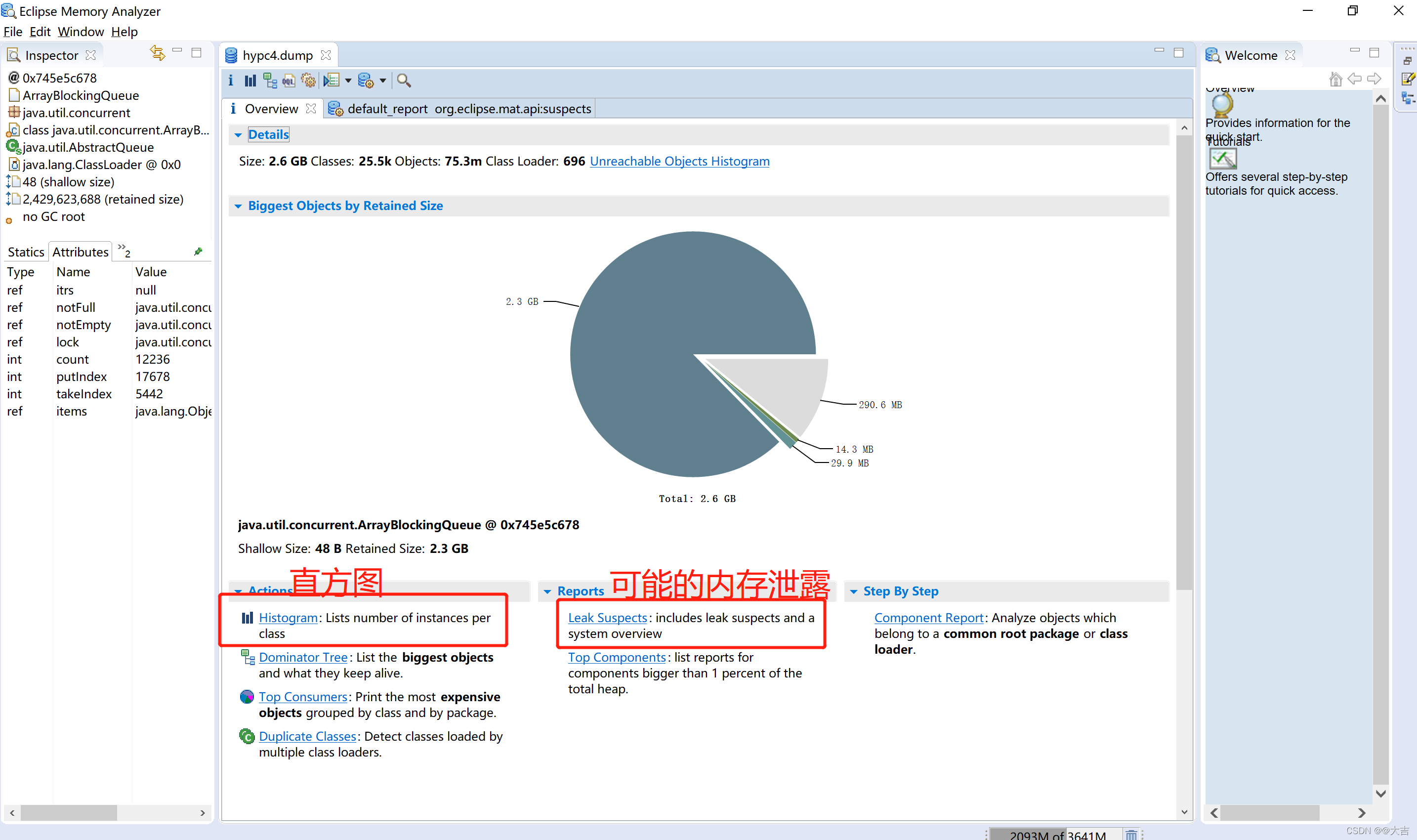
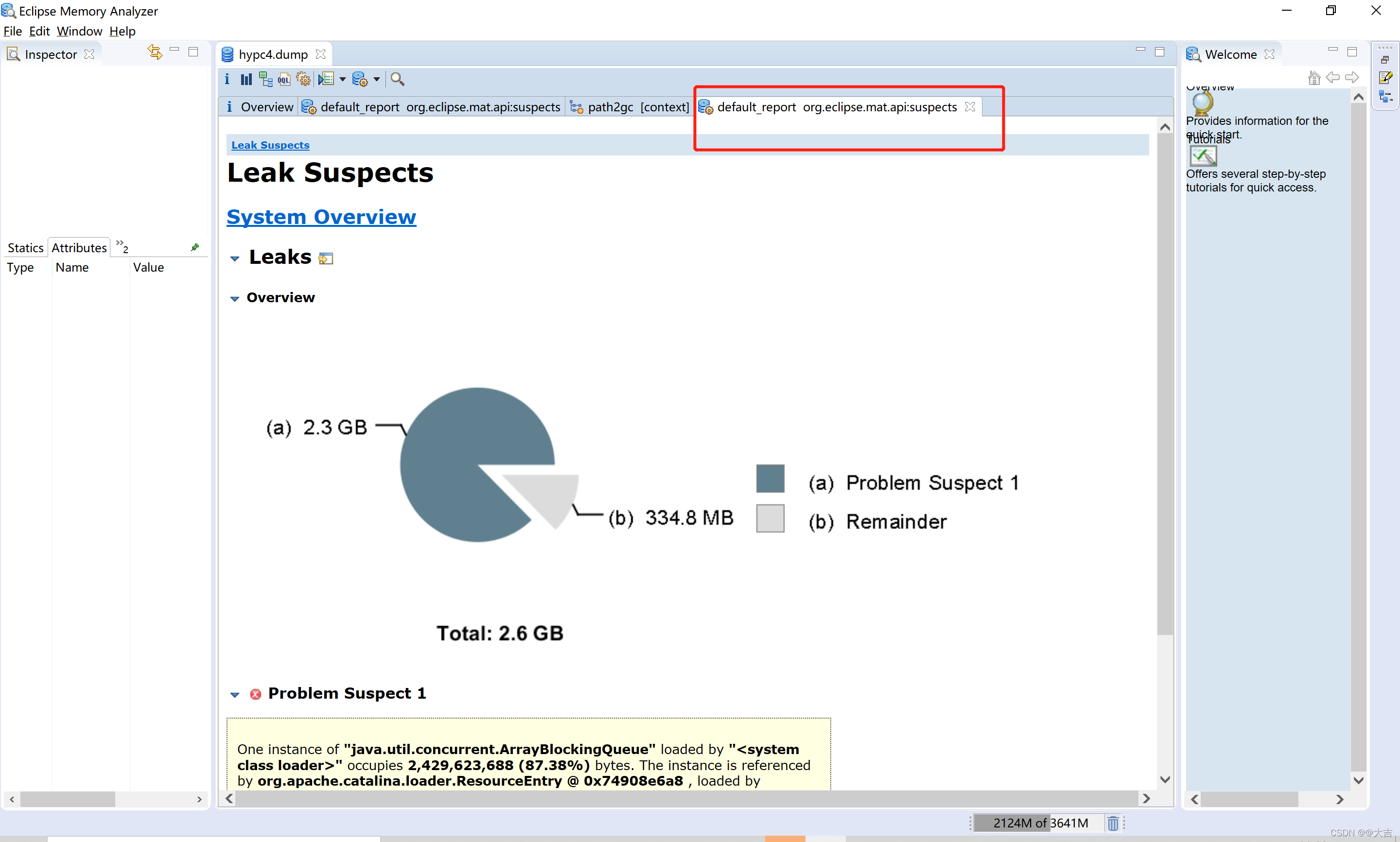
点击details查看详情:
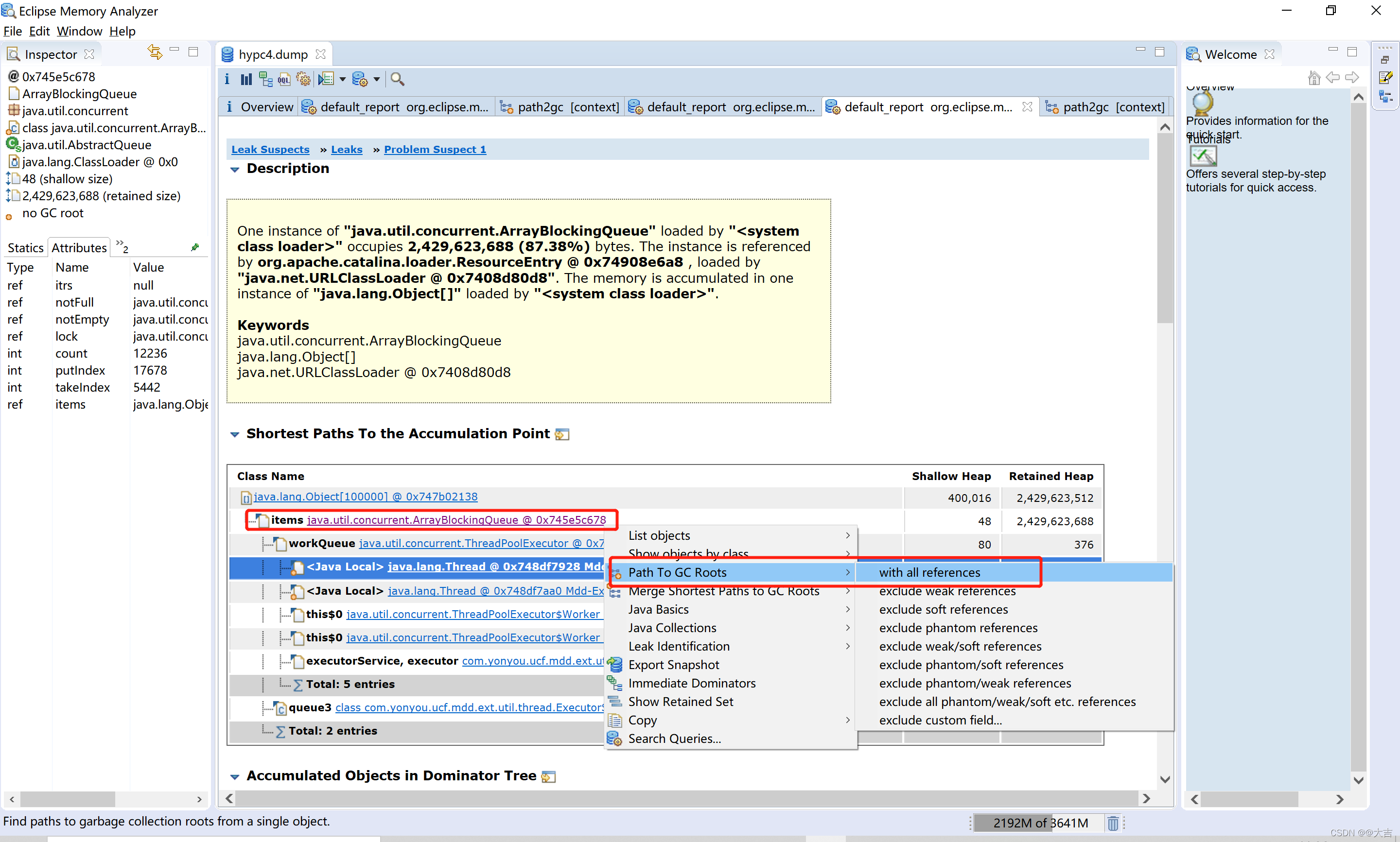
查看其所有引用:
得到下图:
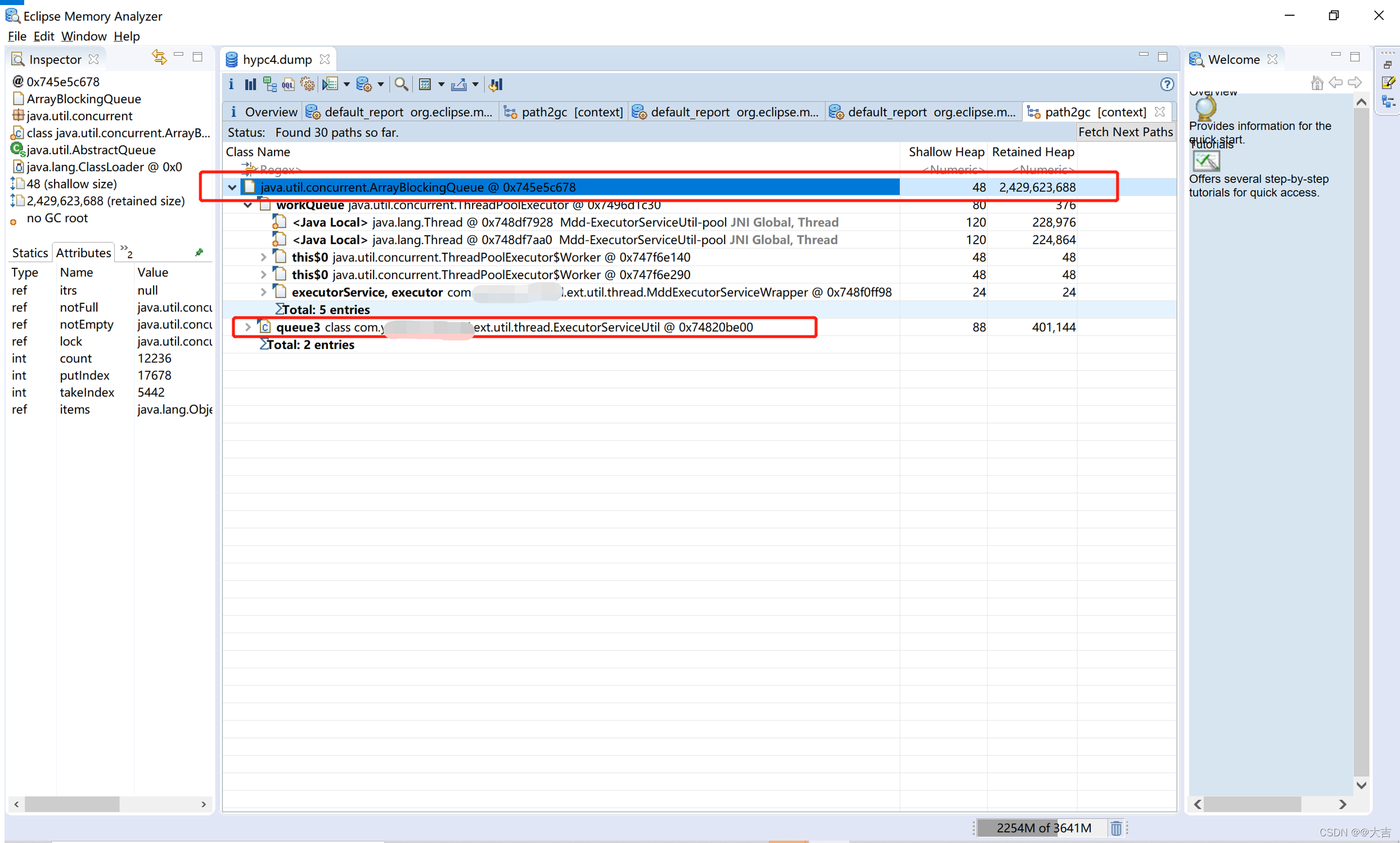
这里我们可以看到两个指标:shallow heap 和 Retained Heap
shallow heap 和 Retained Heap
对象的 Shallow heap 是其自身在内存中的大小。
Retained heap 指的就是在垃圾回收特定对象时将释放的内存量。
所以根据上图可知,假如垃圾回收释放掉了queue3这个引用,将能够释放出O区大量空间。而且该分析工具已经精确到了类。只需要按图索骥找到这个类和这个引用即可。
解决问题
根据经验得知,ArrayBlockingQueue:在java多线程操作中, BlockingQueue,jdk内部尤其是一些多线程,大量使用了blockingQueue 来做的。说明是某个线程池出现了问题。
再看引用链上的queue3,定位到了ExecutorServiceUtil这个类。然后我们去代码里找到这个类,和queue3这个对象:
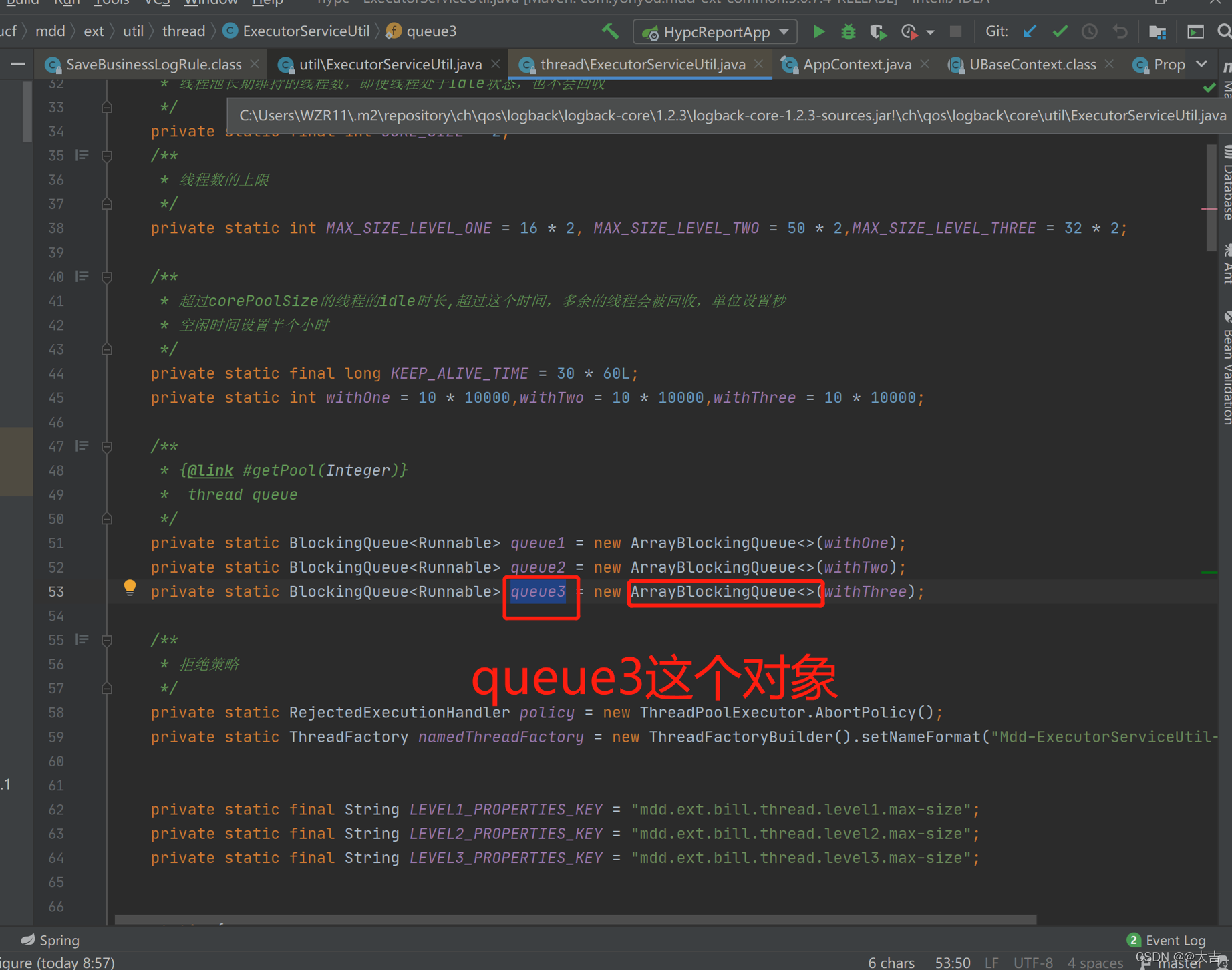
说明大量调用了 queue3 ,线程池线程占满了,而且现有线程没执行完,导致内存一直被占用。由于线程没执行完,所以不能释放,所以老年代内存越积越多。最后OOM。
解决方案呼之欲出:调大该线程池连接数,或者直接扩充Docker实例。这两种方法都可以解决。
后记
这次高并发下产生的性能问题可以借助MemoryAnalyzer分析出来,但是还有一些问题就不是借助 JVM 分析出来了。有可能网络调用超时,也有可能前端问题。这些都有可能。性能优化这个话题比较大,本人也只是会一点皮毛,浅记于此。
随后我将更新 使用 Arthas 工具的trace命令查看执行时间,逐层跟踪,定位并解决高并发下性能问题,作为工作的整理和记录。