项目背景与需求
DMP项目介绍
随着互联网的发展,互联网的广告推送逐渐诞生了AdNetwork(广告网络)、AdExchange和DSP 需求方平台。
互联网的广告资源非常丰富,除了微博,微信这样的大平台外,很多小媒体也能够提供大量优质的广告位。大量的小媒体组成了一个很大的盘子,于是有AdNetwork平台为对接广告主和媒体,为广告主提供统一的界面,联络多家媒体, 行成统一的定价。
但AdNetwork 不止一家,小媒体们会选择不同的 AdNetwork,很多广告主依然面临选择困难。很多优质媒体由于不满意AdNetwork的定价策略未加入,于是产生了AdExchange广告交易平台试图统一AdNetwork。
AdExchange相对于AdNetwork采用了实时的交易定价,类似于股票的撮合交易。大体流程是媒体发起广告请求给 RTB 系统, 请求广告进行展示,广告主根据自己需求决定是否竞价, 以及自己的出价。会有多个广告主同时出价, 价高者得。
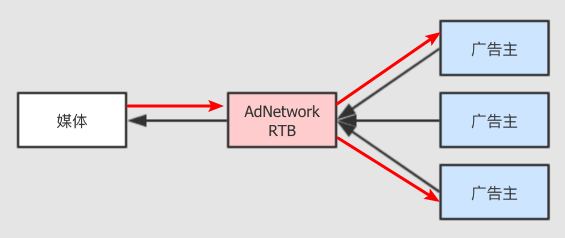
AdExchange 的RTB 让广告的展示价格更透明更公平,让媒体得到了最大化的广告费。但是对于广告主来说,只关心能否让合适的人看到了这些广告,同等价格内广告效果能否更好。于是DSP (需求方平台)应运而生, 主要负责和 AdExchange 交互辅助广告主进行实时竞价。
有了DSP 平台,广告主就可以针对自己想要的目标受众投放广告了。 比如说, 一个广告主是卖化妆品的, 他可以设置投放广告的标签为 20 岁上下, 女性, 时尚人士。DMP, 全称 Data Management Platform,即数据管理平台,就管理了用户的标签数据。
DMP 主要负责收集用户数据并为用户打上标签,DSP 主要通过标签筛选用户,所以需要为用户数据打上标签,这个也可以称为用户画像。

中国程序化广告生态图
DMP的主要任务
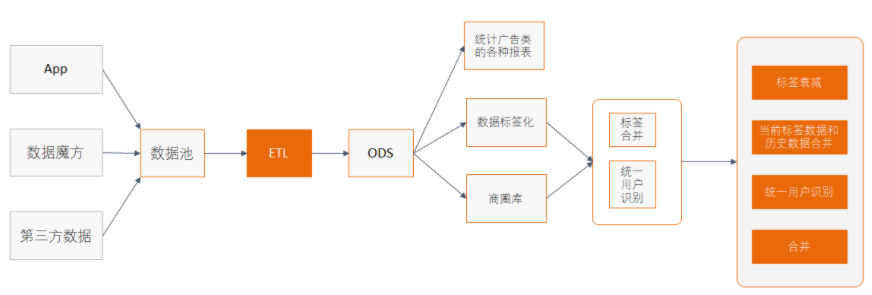
DMP的数据主要来自于:
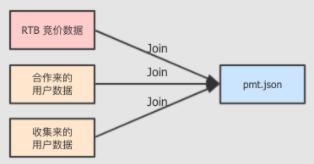
数据来自于以往的竞价记录(以往的交易)和收集到的用户数据(第三方或自己收集)。
这里有一份pmt.json的样例数据用于测试,pmt.json是一个JSON Line 文件,共三千条数据,每一条数据都是一个独立的 JSON 字符串,共90个字段:

本文只演示简单的打标签和统一用户识别的需求,所需要用到的字段含义如下:
| 字段 | 解释 |
|---|---|
| adspacetype | 广告位类型,1 : Banner,2 : 插屏,3 : 全屏 |
| channelid | 频道 ID |
| keywords | 关键字 |
| sex | 用户性别 |
| age | 用户年龄 |
| imei | 手机串码 |
| imeimd5 | IMEI 的 MD5 值 |
| imeisha1 | IMEI 的 SHA-1 值 |
| mac | 手机 MAC 地址 |
| macmd5 | MAC 的 MD5 值 |
| macsha1 | MAC 的 SHA-1 值 |
| openudid | 苹果设备的识别码 |
| openudidmd5 | OpenUDID 的 MD5 值 |
| openudidsha1 | OpenUDID 的 SHA-1 值 |
| idfa | 手机 APP 的广告码 |
| idfamd5 | IDFA 的 MD5 值 |
| idfasha1 | IDFA 的 SHA-1 值 |
需求说明
首先,我们根据adspacetype,channelid,keywords,sex,age打标签,然后对后续的唯一标识字段进行合并。例如某用户在一个时间点上, 汇报了 mac, udid, 另外一个时间点汇报了 mac, uuid,这两条数据实际就归属于同一个用户,需要对这些数据进行合并。
最终结果,标签按照一定规范使用一个JSON字符串存储在一个字段中;取第一个有效ID作为这个用户的ID。
前置知识已经放在前面的文章里:
PySpark与GraphFrames的安装与使用
https://xxmdmst.blog.csdn.net/article/details/123009617networkx快速解决连通图问题
https://xxmdmst.blog.csdn.net/article/details/123012333PySpark求解连通图问题
https://xxmdmst.blog.csdn.net/article/details/123036398
开始编码
下面我们回到广告项目的数据处理问题,pmt.json数据集下载:https://pan.baidu.com/s/1_qx2nc2r3H5eQiSfnUxx3Q?pwd=xhzw
PySpark解决需求
首先创建spark会话对象,启动本地伪分布式集群:
from pyspark.sql import SparkSession, Row
from graphframes import GraphFrame
spark = SparkSession \
.builder \
.appName("PySpark") \
.master("local[*]") \
.getOrCreate()
sc = spark.sparkContext
sc.setCheckpointDir("checkpoint")
spark
读取数据并筛选需要的列:
data = spark.read.json("pmt.json")
data = data.select([
"imei", "imeimd5", "imeisha1", "mac", "macmd5",
"macsha1", "openudid", "openudidmd5", "openudidsha1",
"idfa", "idfamd5", "idfasha1", "adspacetype",
"channelid", "keywords", "sex", "age"
])
data.take(2)
输出:
[Row(imei='', imeimd5='', imeisha1='', mac='52:54:00:b0:e5:04', macmd5='', macsha1='', openudid='ILHOYMFMOKEHZRTRCCWRMMDRALMCNAXYAYIFPHFN', openudidmd5='', openudidsha1='', idfa='', idfamd5='', idfasha1='', adspacetype=2, channelid='123510', keywords='赵立新,黄璐,梁静,老炮儿,盲山', sex='1', age='38'),
Row(imei='', imeimd5='', imeisha1='', mac='', macmd5='', macsha1='', openudid='YGWVDAVUXMFWJUDMHAOWAJUGQCJRAXYOXLHSHSGE', openudidmd5='', openudidsha1='', idfa='JMLQQLMQGHKKWDJHDUQLLIJTAJSDRIPT', idfamd5='', idfasha1='', adspacetype=2, channelid='123471', keywords='美文', sex='1', age='49')]
根据前面的思路,我们首先需要对每一行数据生成一个唯一ID,再对广告位类型,频道 ID,关键字、性别和年龄等字段进行打标签,其他字段作为主键:
keyList = ["imei", "imeimd5", "imeisha1", "mac",
"macmd5", "macsha1", "openudid", "openudidmd5",
"openudidsha1", "idfa", "idfamd5", "idfasha1"]
def createTags(pair):
row, rid = pair
tags = [f"AD{
row.adspacetype}", f"CH{
row.channelid}",
f"GD{
row.sex}", f"AG{
row.age}"]
for key in row.keywords.split(","):
tags.append(f"KW{
key}")
values = []
for key in keyList:
values.append(row[key])
values.append(tags)
values.append(rid)
return values
tagsRDD = data.rdd.zipWithUniqueId().map(createTags)
print(tagsRDD.take(2))
[['', '', '', '52:54:00:b0:e5:04', '', '', 'ILHOYMFMOKEHZRTRCCWRMMDRALMCNAXYAYIFPHFN', '', '', '', '', '', ['AD2', 'CH123510', 'GD1', 'AG38', 'KW赵立新', 'KW黄璐', 'KW梁静', 'KW老炮儿', 'KW盲山'], 0], ['', '', '', '', '', '', 'YGWVDAVUXMFWJUDMHAOWAJUGQCJRAXYOXLHSHSGE', '', '', 'JMLQQLMQGHKKWDJHDUQLLIJTAJSDRIPT', '', '', ['AD2', 'CH123471', 'GD1', 'AG49', 'KW美文'], 2]]
将其转换成DataFrame并缓存起来:
tagsDF = tagsRDD.toDF(keyList+["tags", "rid"])
tagsDF.cache()
tagsDF.checkpoint()
tagsDF.take(2)
[Row(imei='', imeimd5='', imeisha1='', mac='52:54:00:b0:e5:04', macmd5='', macsha1='', openudid='ILHOYMFMOKEHZRTRCCWRMMDRALMCNAXYAYIFPHFN', openudidmd5='', openudidsha1='', idfa='', idfamd5='', idfasha1='', tags=['AD2', 'CH123510', 'GD1', 'AG38', 'KW赵立新', 'KW黄璐', 'KW梁静', 'KW老炮儿', 'KW盲山'], rid=0),
Row(imei='', imeimd5='', imeisha1='', mac='', macmd5='', macsha1='', openudid='YGWVDAVUXMFWJUDMHAOWAJUGQCJRAXYOXLHSHSGE', openudidmd5='', openudidsha1='', idfa='JMLQQLMQGHKKWDJHDUQLLIJTAJSDRIPT', idfamd5='', idfasha1='', tags=['AD2', 'CH123471', 'GD1', 'AG49', 'KW美文'], rid=2)]
下面我们对所有唯一标识字段计算关联边并合并:
import pandas as pd
def func(pdf):
ids = pdf.rid
n = len(ids)
if n <= 1:
return pd.DataFrame(columns=["src", "dst"])
edges = []
for i in range(n-1):
for j in range(i+1, n):
edges.append((ids[i], ids[j]))
return pd.DataFrame(edges)
edge_rdds = []
for key in keyList:
edge = tagsDF.filter(tagsDF[key] != "") \
.select(key, "rid") \
.groupBy(key) \
.applyInPandas(func, "src int,dst int")
edge_rdds.append(edge.rdd)
edgesDF = sc.union(edge_rdds).toDF(["src", "dst"])
edgesDF.cache()
edgesDF.checkpoint()
edgesDF.show(5)
结果:
+----+----+
| src| dst|
+----+----+
|1538|1540|
|1538|2214|
|1538|2790|
|1538|4054|
|1538|1223|
+----+----+
only showing top 5 rows
然后获取顶点:
vertices = tagsDF.select(tagsDF.rid.alias("id"))
vertices.show(5)
+---+
| id|
+---+
| 0|
| 2|
| 4|
| 6|
| 8|
+---+
only showing top 5 rows
开始计算连通图:
gdf = GraphFrame(vertices, edgesDF)
components = gdf.connectedComponents()
components.show()
+---+---------+
| id|component|
+---+---------+
| 0| 0|
| 2| 2|
| 4| 4|
| 6| 0|
| 8| 8|
| 10| 10|
| 12| 12|
| 14| 14|
| 16| 16|
| 18| 18|
| 20| 20|
| 22| 22|
| 24| 24|
| 26| 26|
| 28| 28|
| 30| 30|
| 32| 32|
| 34| 34|
| 36| 36|
| 38| 8|
+---+---------+
然后表连接,获取每一行数据对应的唯一用户id标识component:
result = tagsDF.join(components, on=tagsDF.rid == components.id)
result.cache()
result.take(2)
[Row(imei='', imeimd5='', imeisha1='', mac='52:54:00:b0:e5:04', macmd5='', macsha1='', openudid='ILHOYMFMOKEHZRTRCCWRMMDRALMCNAXYAYIFPHFN', openudidmd5='', openudidsha1='', idfa='', idfamd5='', idfasha1='', tags=['AD2', 'CH123510', 'GD1', 'AG38', 'KW赵立新', 'KW黄璐', 'KW梁静', 'KW老炮儿', 'KW盲山'], rid=0, id=0, component=0),
Row(imei='', imeimd5='', imeisha1='', mac='', macmd5='', macsha1='', openudid='YGWVDAVUXMFWJUDMHAOWAJUGQCJRAXYOXLHSHSGE', openudidmd5='', openudidsha1='', idfa='JMLQQLMQGHKKWDJHDUQLLIJTAJSDRIPT', idfamd5='', idfasha1='', tags=['AD2', 'CH123471', 'GD1', 'AG49', 'KW美文'], rid=2, id=2, component=2)]
接下来在对每个用户聚合:
from collections import Counter
import json
def combineTags(pdf):
mainID = None
for key in keyList:
v = pdf[key].bfill().iat[0]
if v:
mainID = v
break
c = Counter()
for tags in pdf.tags.values:
for tag in tags:
c[tag] += 1
return pd.DataFrame([(mainID, json.dumps(c, ensure_ascii=False))])
result2 = result.groupBy("component").applyInPandas(
combineTags, schema="mainID string, tags string"
)
result2.show()
+--------------------+--------------------+
| mainID| tags|
+--------------------+--------------------+
| 52:54:00:b0:e5:04|{"AD2": 2, "CH123...|
| 52:54:00:83:f5:9a|{"AD3": 3, "CH123...|
|YGWVDAVUXMFWJUDMH...|{"AD2": 1, "CH123...|
| 52:54:00:04:7c:4b|{"AD1": 3, "CH123...|
| 52:54:00:3d:65:db|{"AD3": 2, "CH123...|
| 52:54:00:c4:e6:e7|{"AD3": 3, "CH123...|
| 070264565409917|{"AD1": 2, "CH123...|
| 945658800321180|{"AD1": 1, "CH123...|
| 077683806650676|{"AD1": 2, "CH123...|
| 52:54:00:7a:8b:19|{"AD1": 7, "CH123...|
| 52:54:00:cd:e2:c1|{"AD2": 1, "CH123...|
| 52:54:00:ef:8a:18|{"AD2": 1, "CH123...|
|IPCACDLYSSJUSBKPZ...|{"AD1": 1, "CH123...|
| 52:54:00:1a:e1:69|{"AD2": 4, "CH123...|
|HQPEUGDMONXDFCVIU...|{"AD3": 3, "CH123...|
| 52:54:00:50:12:35|{"AD1": 3, "CH123...|
| 52:54:00:f5:5f:75|{"AD2": 1, "CH123...|
| 52:54:00:4e:82:9a|{"AD1": 4, "CH123...|
| 52:54:00:0c:e1:84|{"AD1": 3, "CH123...|
| 52:54:00:16:29:00|{"AD3": 1, "CH123...|
+--------------------+--------------------+
only showing top 20 rows
可以看到,这样就顺利的计算出了我们需要的结果。
最终完整代码:
from pyspark.sql import SparkSession, Row
from graphframes import GraphFrame
import pandas as pd
from collections import Counter
import json
spark = SparkSession \
.builder \
.appName("PySpark") \
.master("local[*]") \
.getOrCreate()
sc = spark.sparkContext
sc.setCheckpointDir("checkpoint")
data = spark.read.json("pmt.json")
data = data.select([
"imei", "imeimd5", "imeisha1", "mac", "macmd5",
"macsha1", "openudid", "openudidmd5", "openudidsha1",
"idfa", "idfamd5", "idfasha1", "adspacetype",
"channelid", "keywords", "sex", "age"
])
keyList = ["imei", "imeimd5", "imeisha1", "mac",
"macmd5", "macsha1", "openudid", "openudidmd5",
"openudidsha1", "idfa", "idfamd5", "idfasha1"]
def createTags(pair):
row, rid = pair
tags = [f"AD{
row.adspacetype}", f"CH{
row.channelid}",
f"GD{
row.sex}", f"AG{
row.age}"]
for key in row.keywords.split(","):
tags.append(f"KW{
key}")
values = []
for key in keyList:
values.append(row[key])
values.append(tags)
values.append(rid)
return values
tagsRDD = data.rdd.zipWithUniqueId().map(createTags)
tagsDF = tagsRDD.toDF(keyList+["tags", "rid"])
tagsDF.cache()
tagsDF.checkpoint()
def createEdges(pdf):
ids = pdf.rid
n = len(ids)
if n <= 1:
return pd.DataFrame(columns=["src", "dst"])
edges = []
for i in range(n-1):
for j in range(i+1, n):
edges.append((ids[i], ids[j]))
return pd.DataFrame(edges)
edge_rdds = []
for key in keyList:
edge = tagsDF.filter(tagsDF[key] != "") \
.select(key, "rid") \
.groupBy(key) \
.applyInPandas(createEdges, "src int,dst int")
edge_rdds.append(edge.rdd)
edgesDF = sc.union(edge_rdds).toDF(["src", "dst"])
vertices = tagsDF.select(tagsDF.rid.alias("id"))
gdf = GraphFrame(vertices, edgesDF)
components = gdf.connectedComponents()
tmp = tagsDF.join(components, on=tagsDF.rid == components.id)
def mapTags(pdf):
mainID = None
for key in keyList:
v = pdf[key].bfill().iat[0]
if v:
mainID = v
break
c = Counter()
for tags in pdf.tags.values:
for tag in tags:
c[tag] += 1
return pd.DataFrame([(mainID, json.dumps(c, ensure_ascii=False))])
result = tmp.groupBy("component").applyInPandas(
mapTags, schema="mainID string, tags string"
)
result = result.toPandas()
result
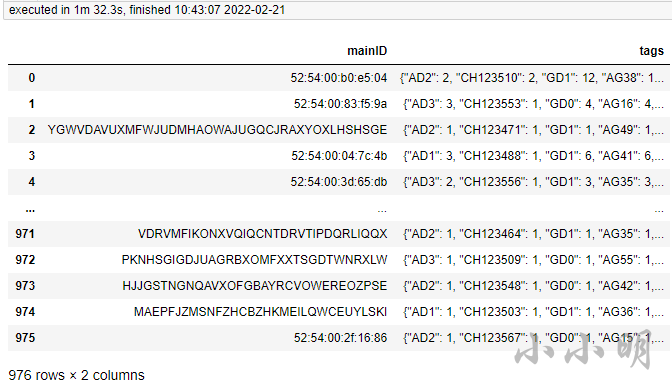
可以看到耗时1分32秒。
纯Python解决需求
可以看到使用分布式后,即使是伪分布式也是如此的慢,如果数据量是单机内存可以装的下的使用纯Python可以快无数倍,下面展示本需求的完整解决代码:
import json
import pandas as pd
import networkx as nx
from collections import Counter
import json
with open("pmt.json", encoding="u8") as f:
data = [json.loads(row) for row in f]
data = pd.DataFrame(data)[[
"imei", "imeimd5", "imeisha1", "mac", "macmd5",
"macsha1", "openudid", "openudidmd5", "openudidsha1",
"idfa", "idfamd5", "idfasha1", "adspacetype",
"channelid", "keywords", "sex", "age"
]]
data.replace("",pd.NA,inplace=True)
g = nx.Graph()
keyList = ["imei", "imeimd5", "imeisha1", "mac",
"macmd5", "macsha1", "openudid", "openudidmd5",
"openudidsha1", "idfa", "idfamd5", "idfasha1"]
g.add_nodes_from(data.index)
for c in keyList:
for ids in data.index.groupby(data[c]).values():
n = len(ids)
if n == 1:
continue
for i in range(n-1):
for j in range(i+1, n):
g.add_edge(ids[i], ids[j])
def combineTags(df):
mainID = None
for key in keyList:
v = df[key].bfill().iat[0]
if not pd.isna(v):
mainID = v
break
c = Counter()
for v in df["adspacetype"].values:
c[f"AD{
v}"] += 1
for v in df["channelid"].values:
c[f"CH{
v}"] += 1
for keywords in df.keywords.values:
for key in keywords:
c[f"KW{
key}"]+=1
for v in df["sex"].values:
c[f"GD{
v}"] += 1
for v in df["age"].values:
c[f"AG{
v}"] += 1
return (mainID, json.dumps(c, ensure_ascii=False))
result = []
for sub_g in nx.connected_components(g):
sub_g = g.subgraph(sub_g)
g_node = sub_g.nodes()
ids = list(g_node)
df_split = data.iloc[ids]
result.append(combineTags(df_split))
result = pd.DataFrame(result, columns=["mainID", "tags"])
result
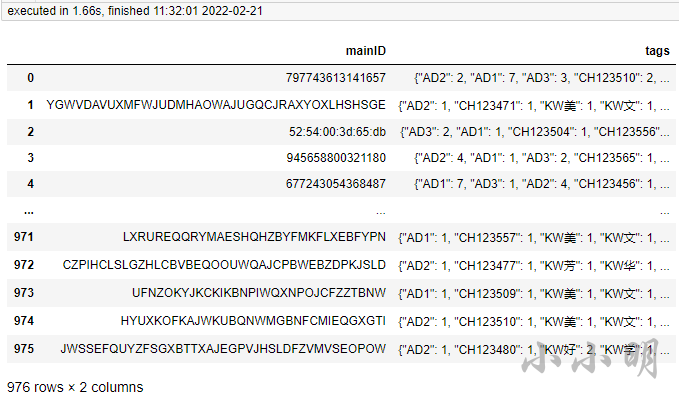
可以看到耗时仅2秒钟。