一、概述
CRF的能力在于信息的依赖性和状态转移处理,它可以表达任意的状态转移和依赖关系。而信息表达能力不足则可以依靠Transformer来处理。在论文中的这幅图展示了各种模型之间是如何进行转换的,在使用CRFs时,Linear-chain CRFs会使用的更多一些:

二、NLP信息提取中的CRF Modeling详解
- Applications of CRFs
CRFs已经广泛应用在各种不同的领域,包括文本处理,计算机视觉,生物信息等。linear-chain CRFs的应用包括NER,shallow parsing,查出文本中的语义角色,音调重音的预测,机器翻译中的单词分配,文本文档中表格信息的提取,中文分词等等。
2. Linear-chain CRFs详解
为了促进Linear-chain CRFs的理解,考虑由一个HMM的联合概率p(y, x)产生的条件概率p(y|x),关键点在于条件概率事实上是一个具有对feature函数进行特定选择的CRF。HMM的联合概率可以表示如下:

这里,θ = {θij , µoi}是这个概率分布的有实际值的参数,Z是一个正则化常量,概率之和等于1,θij = log p(y ‘ = i|y = j) ,µoi = log p(x = o|y = i).

每一个feature函数具有这样的形式:fk(yt , yt−1, xt),xt代表输入,yt表示当前的状态,依赖它前面的一个状态yt−1。为了复制,需要为每一个转移(i, j)定义一个feature:
![]()
为每一个状态观察pair (i, o)定义一个feature:
![]()
通常把一个feature函数标记为fk,范围包括所有的fij和所有的fio。这样就可以把HMM表示为:

根据上面的公式推导出条件概率公式:

上面条件概率分布表示的是一种特殊的Linear-chain CRF,它只包括当前单词的identity的feature,但是很多其它的linear-chain CRFs使用了关于输入的更丰富的features,当前单词的前缀和后缀,围绕它的单词的identity等。
假设Y,X是随机vectors,而具有实际值的一套feature函数表示为:
![]()
那么Linear-chain CRF的概率分布可以表示如下:

这里的正则化函数Z(x)表示如下:

其它类型的Linear-chain CRF也是有用的,譬如在HMM中,从一个状态i到状态j的转移获得同样的分数,log p(yt = j|yt−1 = i),这与输入无关。在一个CRF中,可以允许转移(i, j)依赖于当前观察的vector,简单添加一个feature:1{yt=j}1{yt−1=1}1{xt=o},具有这种转移feature的CRF通常被用在文本应用中。
为了在Linear-chain CRF的定义中指出每个feature函数能够依赖任意时间点的观察,把fk的观察参数标记为vector xt,可以理解为包含了全局观察x的所有组件,例如CRF使用下一个单词xt+1作为一个feature,然后feature vector xt被假设包括 单词xt+1的indentity。
从Linear-chain CRF到General CRF的转换相当直接,我们简单地使用linear-chain factor graph转换到一个更加general的factor graph。
假设G是Y的一个factor graph,那么对于任何固定的x来说p(y|x)是一个CRF,根据G进行因数分解。在linear-chain的场景中,同样的weights经常被用作每个时间点的factors Ψt(yt , yt−1, xt),可以把G的factors划分为一个集合C = {C1, C2, . . . Cp },每个Cp是一个clique template,每个template包含一套factors,从而可以把CRF表示为:
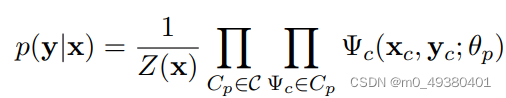
其中每个factor参数化之后表示为:

关于clique template的使用,譬如在对图像进行建模时,可以基于不同的scale使用不同的clique template,这取决于找到兴趣点的算法的结果。
3. General CRFs详解
General CRFs也被应用于NLP的几个任务,一个promising application会同时执行多个标注任务。例如,一个用于POS tagging和名词类词组分块的2级动态CRF的表现好于一次处理一个任务的情况。另外一个应用是多标签分类(譬如在对话过程中用户输入可以包含多个意图的情况),即一个instance可以有多个分类标签,而不是为每个类别训练一个单独的标签。有这样一种CRF,它可以通过学习类别之间的依赖关系来改善分类表现。
skip-chain CRF是一个在信息提取中表示长距离(long-distance)依赖性的一个general CRF,关于长距离依赖,举个例子,假设一个人说了很长的一段话,中间的一大段内容都无关紧要,而预测需要的关键信息是在这段话的开头部分体现出来的,那么如果要在这段话的结尾根据关键信息来进行预测,这时就需要使用长距离依赖了。
图形化的CRF结构可以被应用在名词指代问题处理中,即判断文档中有哪些指代,譬如文档中出现的Mr. President 和he都是指向同一个实体。论文也提到了使用全连接CRF来学习各种指代之间的距离度量来推理如何对应到图形分区。类似的模型也被应用在对手写字符进行分段。
在计算机视觉方面,也有人使用grid-shaped CRFs来标注和分割图片。在CRF的一些应用方面,即使图形化模型很难进行描述,依然存在有效的动态编程。
在定义一个General CRF需要考虑的最重要的点在于指定重复结构和参数系,很多推荐的形式是指定clique templates。例如动态CRF允许在每个时间点有多个分类,而不是单分类,这种方式类似于动态Bayesian网络。