原文转自:微信公众号
云原生CTO
欢迎阅读 Kubernetes Operator Dev的 N 部分系列的第二部分。
如果你想从理论上了解operator是什么以及它们是如何工作的,请参阅第一部分。
在这一部分,我们将探索如何使用Kubebuilder来简化operator的编写。所以,我们让我们let's go!
Kubebuilder: https://github.com/kubernetes-sigs/kubebuilder

Kubebuilder是什么?
编写Kubernetes operator涉及到处理Kubernetes API,如创建、观察、列出对象等。为了解决这个问题,您可以使用像client-go和controller-runtime这样的抽象库在Kubernetes集群上执行CRUD操作。但是,即使从头开始使用它们来编写一个成熟的operator,最终也会涉及大量的复杂性、学习曲线和样板代码来处理。
因此,为了避免这种麻烦,有多种sdk可以帮助我们简化和加快编写operator的过程。其中一个是Kubebuilder。
client-go: https://github.com/kubernetes/client-go
controller-runtime: https://github.com/kubernetes-sigs/controller-runtime

Kubebuilder是一个由controller-runtime支持的出色SDK,它可以帮助您轻松快速地在 Go 中编写Kubernetes operator,方法是处理多种忙碌的事情,例如以组织良好的方式引导大量样板代码,设置有用的 Makefile make,目标是构建、运行和部署operator、构建 CRD、设置相关的 Dockefile、RBAC、涉及部署operator的多个 YAML 等等。
在这篇文章中,我们将看到它的实际应用。
但在继续之前!
我希望尽可能保持本系列文章的示例性和相关性。为了确保这一点,我将以项目优先的方式解释所有概念和主题。在此过程中,我们将深入到operator的开发中,这样你们就可以理解Kubernetes operator开发的所有概念以便你们能够从绝对实用的角度理解和关联 Kubernetes operator dev的所有概念。最后,一旦我们完成了本系列文章,我们最终会得到一个成熟的 Kubernetes operator,它是从我们经历的所有概念中逐步诞生的产物
因此,让我与大家分享我们将要构建的operator,最后,它会是什么样子
PostgresWriter
我们将在本系列文章中构建的operator名为一个“PostgresWriter”的自定义资源。这个想法很简单。比方说,我们在世界的某个角落有一个Postgres DB。
与“postgresqlwriter”资源相关的清单如下:
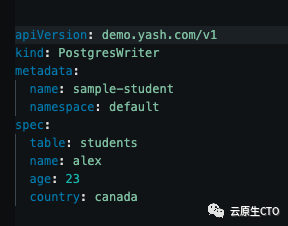
每当将这样的清单应用/创建到 Kubernetes集群时,我们的operator将捕获该事件并执行以下三件事:
- 解析
spec传入的“Postgres_writer”资源的创建和识别table,name,age和country`。 - 以<传入
postgres-writer资源的命名空间>/<传入postgres-writer资源的名称>的格式(default/sample-student在本例中)形成与上述传入“postgres-writer”资源对应的唯一id。
因为在 Kubernetes 中,对于某个资源类型(在我们的例子中是 PostgresWriter),命名空间/名称组合在整个集群中始终是唯一的。在我们的 Postgres数据库中插入一个新行,spec.table并相应地使用 spec.name,spec.age和spec.country字段,主键将是我们形成的上述唯一 id(命名空间/传入资源的名称)。
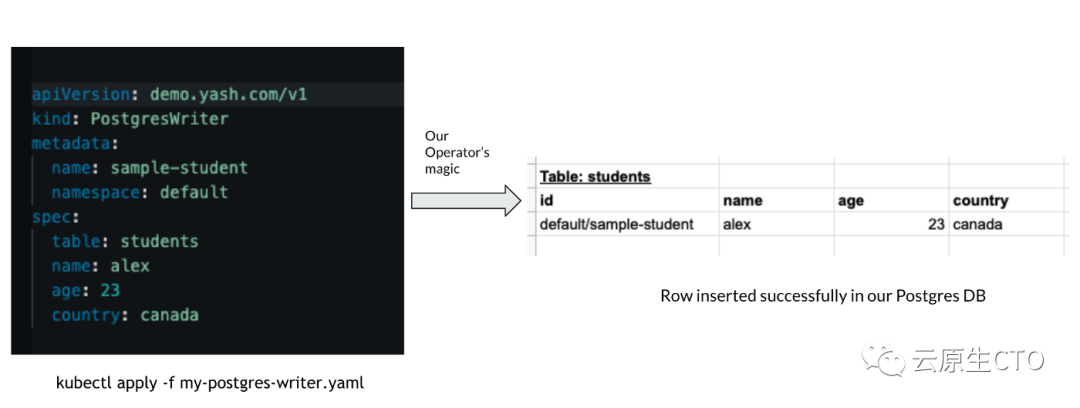
operator和自定义资源的高级流程
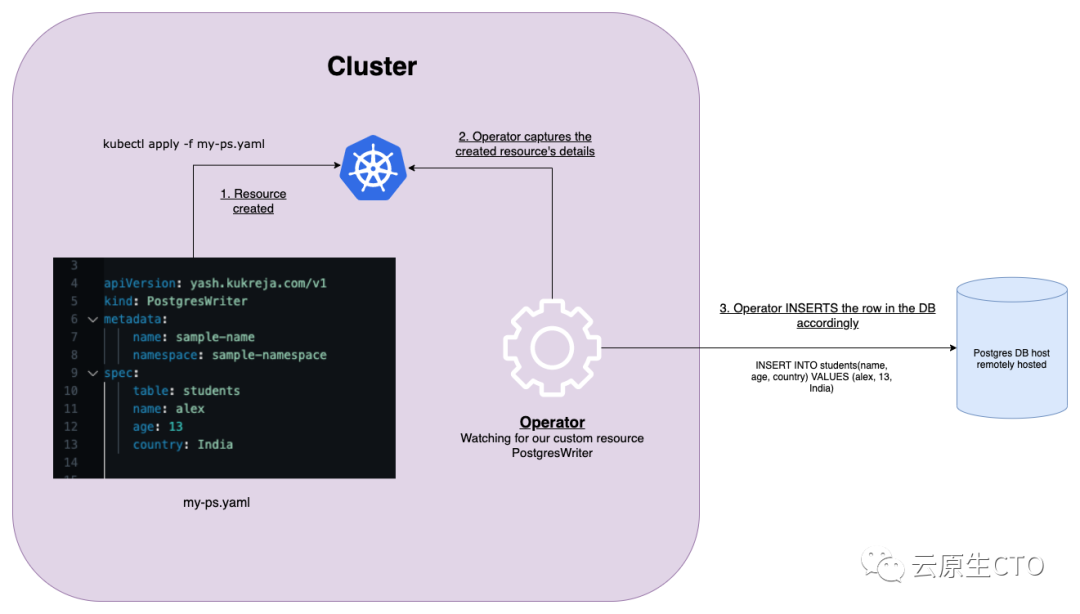
我们的operator在行动中稍微深入的流程
此外,每当PostgresWriter要删除上述资源时,我们的operator都会DELETE相应地从 PostgresDB 中删除与该资源对应的行,以保持 PostgresDB 的行和PostgresWriter集群上存在的资源彼此一致。
对于上面的例子,如果我们kubectl delete使用上面的sample-studentPostgresWriter 资源,那么我们的operater将因此删除与 id对应的行default/sample-student。这将确保对于PostgresWriter我们集群中的每个资源,在我们的 PostgresDB 中只有一行,不多也不少。
所以,让我们潜入吧!
安装 Kubebuilder
为了设置我们的项目/operator,我们需要 Kubebuilder。为此,我们需要安装它 请在您的计算机上安装 Go。现在,在终端中运行以下几行来安装 Kubebuilder
# download kubebuilder and install locally.
curl -L -o kubebuilder https://go.kubebuilder.io/dl/latest/$(go env GOOS)/$(go env GOARCH)
chmod +x kubebuilder && mv kubebuilder /usr/local/bin/
引导我们的operator让我们首先为我们的项目/operator创建一个目录并进入其中。
mkdir -p postgres-writer-operator
cd postgres-writer-operator
现在是Kubebuilder的神奇部分。运行以下命令来引导我们的项目。
kubebuilder init \
--domain yash.com \
--repo github.com/yashvardhan-kukreja/postgres-writer-operator \
--project-name postgres-writer-operator \
--license apache2 \
--skip-go-version-check

随意更改--repo``--domain根据您的意愿:)
此命令定义与我们的项目相关的基本通用文件并设置基本依赖项。基本上,它只是一些与您的项目相关的元信息。
但是,这还不够,因为正如我在我们的operator的描述中提到的,我们的operator将监视一个名为PostgresWriter的自定义资源。由于它是一个自定义资源,我们必须定义它的 CRD,编写等效的 Go 代码,将它附加到我们的operator,我们将运行另一个神奇的命令来为我们引导它:)
kubebuilder create api \
--group demo \
--version v1 \
--kind PostgresWriter \
--resource true \
--controller true \
--namespaced true
上面的命令将引导所有与PostgresWritercustom资源相关的所需文件和代码,并将其附加到我们的operator中,使我们可以轻松开始编写我们喜爱的operator。但像group,controller,namespaces,api这些可怕的术语是什么?
请不要担心,让我一步一步,或者逐字逐句地解释这个命令
kubebuilder ——这是我们使用的引导工具。
create api ——这意味着在我们的项目中执行创建(引导)自定义资源的操作。但是为什么叫它“创建api”而不是“创建operator”呢?
这是因为Kubernetes本身就是一个API驱动的工具,即使通过创建/部署一个operator,我们也只是向Kubernetes添加了一些新的API端点。这就是为什么Kubernetes认为我们在“创建api”。
--group demo --version v1 --kind PostgresWriter ——Kubernetes 中的每种资源type/kind都通过其 group-version-kind(或 GVK)的组合进行唯一标识。因此,Kubernetes API以分层的方式组织资源,而且,GVK 旨在以有组织的方式在 Kubernetes API中放置和集成资源。
要在Kubernetes中识别任何资源的GVK,只需查看其YAML中的apiVersion和kind字段。例如,对于Kubernetes中的Deployment资源,apiVersion是apps/v1,表示它属于apps组,它的Kind类型是Deployment,它的版本是v1。
在我们的例子中,如果你看下面与我们的PostgresWriterresource对应的样例YAML,组是demo.yash.com(命令中的" group "参数+ " domain "参数),kind是PostgresWriter,version是v1
--resource true———通过这个,我们告诉 Kubebuilder 我们正在尝试构建一个自定义资源 PostgresWriter,并且我们希望一些样板代码和文件也围绕我们的自定义资源进行 boostrapped。
--controller true —— 通过这种方式,我们告诉 Kubebuilder 我们希望我们的operator监视我们的PostgresWriter资源并通过controller协调它来对它采取行动。这将使 Kubebuilder 引导一些围绕“Reconcile()”方法(协调循环)的样板代码,以及使用我们项目的controller runtime管理器设置我们的operator/controller的方法。
--namespaced true ——通过这种方式,我们告诉 Kubebuilder 考虑PostgresWriter将其用作命名空间资源,这与 ClusterRoles、ClusterRoleBindings 等集群范围的资源不同。
有了上述所有参数和信息,Kubebuilder 将引导基本 CRD、RBAC、Makefile、Reconciliation Loop 周围的代码等等。
剖析项目目录结构
现在,您可能会被执行我在上一节中提到的简单命令生成的这么多文件吓坏了。
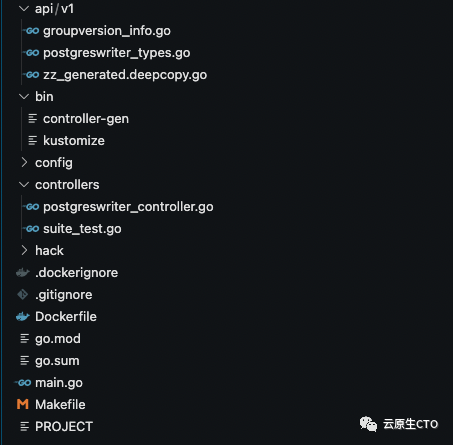
但别担心,让我剧透一下,我们只需要处理两个文件:controllers/postgreswriter_controller.go和api/v1/postgreswriter_types.go。写出整个operator。
许多其他东西大多是自动生成的,你不需要弄乱它们。
然而,我仍然很乐意以一种超级快速和简洁的方式向你们解释一些在我们的项目中自动生成的重要文件。这是因为,将来您可能会遇到一些特殊情况或一些错误,您可能需要手动调整这些文件。这就是这些知识对您有用的地方。另外,当您下次引导operator时,您会知道自己在处理什么,这总是很酷
所以,让我们剖析一下目录结构的重要部分。我会自上而下:
api/v1/*.go ——此目录包含与定义我们的PostgresWriter资源相关的所有文件。我们将相应地编辑postgreswriter_types.go并定义type PostgresWriter struct我们希望我们的PostgresWriter资源具有的结构/模式。由于api/v1/postgreswriter_types.go仅包含我们自定义资源的确切定义(通过各种结构),kubebuilder将PostgresWriter仅基于此文件生成CRD。
bin/* ——它只是包含了像其他一些工具的二进制文件controller-gen,并kustomize将于自举代码的某些部分和部署我们的操作是必需的。
config/* —— 此目录包含围绕我们的operator和自定义资源的所有 YAML相关内容。YAML 清单类似于roles、rolebindings、CRD、示例演示 YAML 等,都位于此目录下。
controllers/* ——这是将包含我们的operator的源代码的地方,即我们operator的协调循环背后的逻辑/代码,关于观察PostgresWriter资源和将我们的operator与“管理器”(稍后定义)连接的东西将在这里编程.
main.go ——这是我们运行operator的项目的入口点。这是我们的operator被实例化并附加到我们的“管理器”并执行的地方。
“
Manager”是包装一个或多个控制器/operator并将它们注册到Kubernetes集群的组件。在我们的例子中,它只是包装和注册一个operator/控制器,即PostgresWriter。所以基本上,流程是:定义operator/控制器,将其附加/与管理器一起设置并执行管理器。“定义operator/控制器”和“定义与管理器一起设置的方法”在controllers/postgreswriter_controller.go文件中完成(分别查看Reconcile和SetupWithManager方法)。实例化oeprator,用管理器设置它并执行管理器在main.go
hack/* ——此目录旨在存储基本的shell脚本或任何其他类型的“hacky”脚本,以自动化我们oeprator周围的任何类型的操作。例如,运行某些检查背后的脚本、递归格式化/linting代码的脚本、安装和设置必备工具的脚本等都将放置在这里。
Makefile ——此文件包含make围绕构建和部署我们的operator的所有相关目标以及其他内容,例如引导 CRD、实用程序代码(如带有控制器生成的 DeepCopy 方法等)。
Dockerfile —— 该文件包含 Dockerfile 脚本/指令,用于将我们的管理器(附有我们的operator并指示运行它)打包到一个 docker 镜像中,该镜像可以稍后部署在Kubernetes 集群上。
差不多就是这样!
下一步是什么?
在下一部分中,我们将从对operator进行编程开始。我们将controllers/postgreswriter_controller.go深入了解其中引导的 Go代码,我们将对其进行编辑以编程我们的operator的协调循环,即该Reconcile()文件中的方法。我们还将围绕 Postgres 设置所有方法和客户端,以使我们的operator与我们的 PostgresDB 对话。最后,我们还将在本地执行我们的operator并第一次看到它的运行情况
尾注!
非常感谢您到达这里。我希望您理解了这篇文章,并对 Kubebuilder 是什么以及它为何如此有用有了一个很好的了解。
我建议你再读一遍这篇文章,因为我能理解你是否仍然对这么多信息和行话感到困惑。但相信我,一切都会变得更容易。

5.3 参考资料
参考地址 [1]
参考资料
[1]
参考地址: https://yash-kukreja-98.medium.com/develop-on-kubernetes-series-operator-dev-understanding-and-dissecting-kubebuilder-4321d3ecd7d6