一、etcd介绍
etcd 是一个高度一致的分布式键值(key-value)存储,它提供了一种可靠的方式来存储需要由分布式系统或机器集群访问的数据。它可以优雅地处理网络分区期间的领导者选举,即使在
领导者节点中也可以容忍机器故障。
etcd 是用Go语言编写的,它具有出色的跨平台支持,小的二进制文件和强大的社区。etcd机器之间的通信通过Raft共识算法处理。
etcd有V2和V3两个版本,V3版本供了更多功能并提高了性能,应用程序使用新的grpc API访问mvcc存储,mvcc存储区和旧存储区v2是分开且隔离的,写入存储v2不会影响mvcc存储,写入mvcc存储也不会影响存储v2。
etcd工作原理:
etcd集群本身是一个分布式系统,由多个节点相互通信构成整体对外服务,每个节点都存储了完整的数据,并且通过Raft协议保证每个节点维护的数据是一致的,在ETCD集群中任意时刻至多存在一个有效的主节点,由主节点处理所有来自客户端写操作,通过Raft协议保证写操作对状态机的改动会可靠的同步到其他节点,Raft协议
如下图所示:
Raft协议主要分为三个部分:选举,复制日志,安全性。
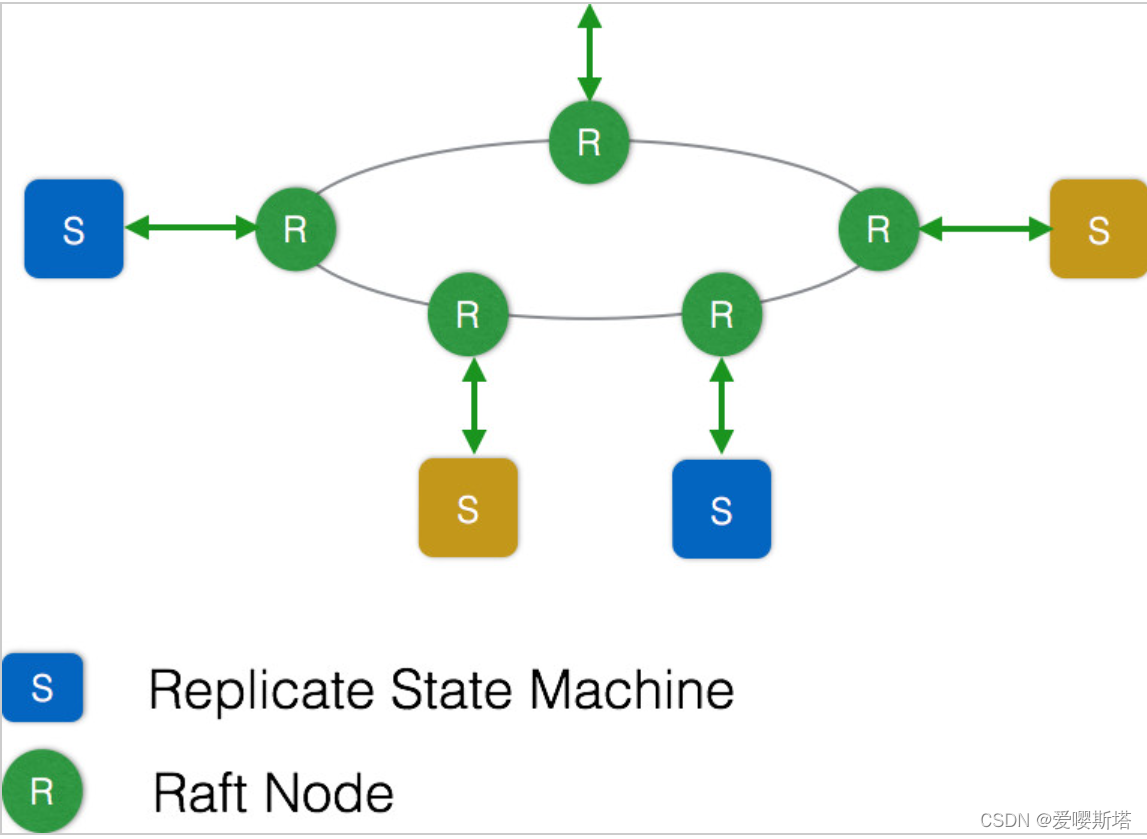
复制日志:
日志复制是指主节点将每次操作形成日志条目,并持久化到本地磁盘,然后通过网络IO发送给其他节点。其他节点根据日志的逻辑时钟(TERM)和日志编号(INDEX)来判断是否将该日志记录持久化到本地。当主节点收到包括自己在内超过半数节点成功返回,那么认为该日志是可提交的(committed),并将日志输入到状态机,将结果返回给客户端。
这里需要注意的是,每次选举都会形成一个唯一的TERM编号,相当于逻辑时钟,每一条日志都有全局唯一的编号。
主节点通过网络IO向其他节点追加日志。若某节点收到日志追加的消息,首先判断该日志的TERM是否过期,以及该日志条目的INDEX是否比当前以及提交的日志的INDEX跟早。若已过期,或者比提交的日志更早,那么就拒绝追加,并返回该节点当前的已提交的日志的编号。否则将日志追加,并返回成功
当主节点收到其他节点关于日志追加的回复后,若发现有拒绝,则根据该节点返回的已提交日志编号,发生其编号下一条日志。
按照日志复制的逻辑,我们可以看到,集群中慢节点不影响整个集群的性能。另外一个特点是,数据只从主节点复制到Follower节点,这样大大简化了逻辑流程;
Raft日志复制路程如下图所示:
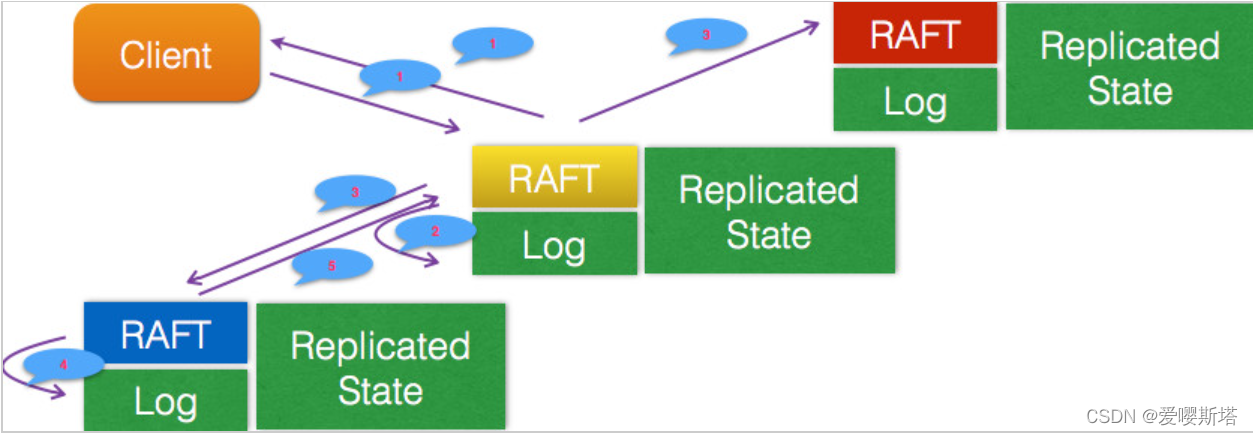
安全:
选举和复制日志并不能保证节点间数据一致。当一个某个节点挂掉了,一段时间后再次重启,并刚好当选为主节点。而在其挂掉这段时间内,集群若有超过半数节点存活,集群会正常工作,那么会有日志提交,这些提交的日志无法传递给挂掉的节点。当挂掉的节点再次当选举节点,它将缺失部分已提交的日志。在这样场景下,按Raft协议,它将自己日志复制给其他节点,会将集群已经提交的日志给覆盖掉,这显然是不可接受的,对于出现这种问题解决办法:
①、其他协议解决这个问题的办法是,新当选的主节点会询问其他节点,和自己数据对比,确定出集群已提交数据,然后将缺失的数据同步过来。这个方案有明显缺陷,增加了集群恢复服务的时间(集群在选举阶段不可服务),并且增加了协议的复杂度。
②、Raft解决的办法是,在选举逻辑中,对能够成为主节点加以限制,确保选出的节点已定包含了集群已经提交的所有日志。如果新选出的主节点已经包含了集群所有提交的日志,那就不需要从和其他节点比对数据了,简化了流程,缩短了集群恢复服务的时间。
为什么只要仍然有超过半数节点存活,一定能够选出包含所有日志数据的节点作为主节点呢?因为已经提交的日志必然被集群中超过半数节点持久化,显然前一个主节点提交的最后一条日志也被集群中大部分节点持久化。当主节点挂掉后,集群中仍有大部分节点存活,那这存活的节点中一定存在一个节点包含了已经提交的日志了,因此要求etcd集群节点数量为奇数(3,5,7,9……)。
高可用集群
二、服务发现
服务发现要解决的也是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务,要如何才能找到对方并建立连接。
本质上来说,服务发现就是想要了解集群中是否有进程在监听udp或tcp端口,并且通过名字就可以查找和连接。
要解决服务发现的问题,需要有下面三大支柱,缺一不可:
①、一个强一致性、高可用的服务存储目录。基于Raft算法的etcd天生就是这样一个强一致性高可用的服务存储目录。
②、一种注册服务和监控服务健康状态的机制。用户可以在etcd中注册服务,并且对注册的服务设置key TTL,定时保持服务的心跳以达到监控健康状态的效果。
③、一种查找和连接服务的机制。通过在etcd指定的主题下注册的服务也能在对应的主题下查找到。为了确保连接,我们可以在每个服务机器上都部署一个Proxy模式的etcd,这样就可
以确保能访问etcd集群的服务都能互相连接。
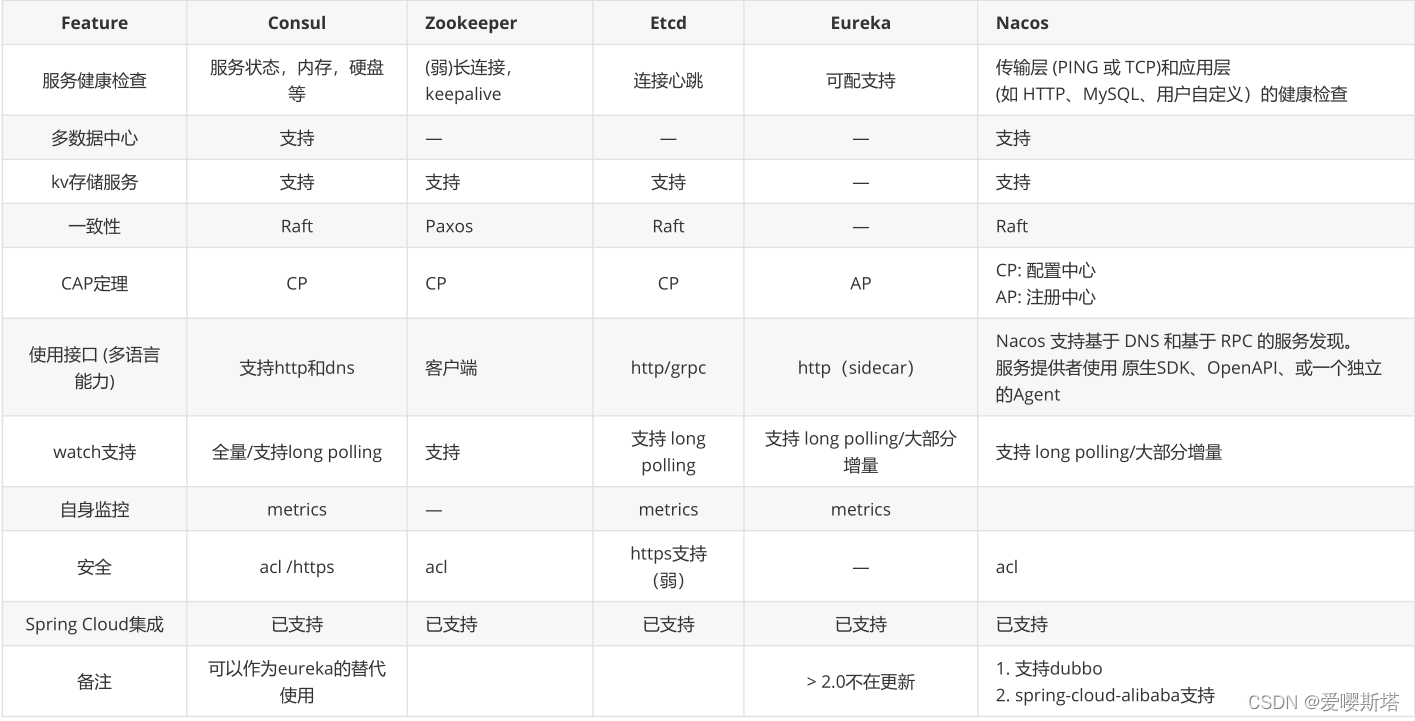
三、Raft选举算法
集群一般是由两个或两个以上的服务器组建而成,每个服务器都是一个节点。数据库集群、管理集群...数据库集群提供了读写功能,管理集群提供了管理、故障恢复等功能。
对于一个集群来说,多个节点的协同和管理是非常重要的。而主节点则实现了协同和管理,主节点的存在,就可以保证其他节点的有序运行,以及数据库集群中的写入数据在每个节点上
的一致性。
这里的一致性是指,数据在每个集群节点中都是一样的,不存在不同的情况。分布式选举的作用就是选出一个主节点,由它来协调和管理其他节点,以保证集群有序运行和节点间数据的
一致性。
Raft 算法是典型的多数派投票选举算法,其选举机制与我们日常生活中的民主投票机制类似,核心思想是“少数服从多数”。
也就是说,Raft 算法中,获得投票最多的节点成为主节点。
采用 Raft 算法选举,集群节点的角色有 3 种:
①、Leader: 即主节点,同一时刻只有一个 Leader,负责协调和管理其他节点;
②、Candidate: 即候选者,每一个节点都可以成为 Candidate,节点在该角色下才可以被选为新的 Leader;
③、Follower: Leader 的跟随者,不可以发起选举。
Raft 选举的流程,可以分为以下几步:
①、初始化时,所有节点均为 Follower 状态。
②、 开始选主时,所有节点的状态由 Follower 转化为 Candidate,并向其他节点发送选举请求。
③、其他节点根据接收到的选举请求的先后顺序,回复是否同意成为主。这里需要注意的是,在每一轮选举中,一个节点只能投出一张票。
④、若发起选举请求的节点获得超过一半的投票,则成为主节点,其状态转化为 Leader,其他节点的状态则由 Candidate 降为 Follower。Leader 节点与 Follower 节点之间会定期发送
心跳包,以检测主节点是否活着。
⑤、 当 Leader 节点的任期到了,即发现其他服务器开始下一轮选主周期时,Leader 节点的状态由 Leader 降级为 Follower,进入新一轮选主
每一轮选举,每个节点只能投一次票。
这种选举就类似人大代表选举,正常情况下每个人大代表都有一定的任期,任期到后会触发重新选举,且投票者只能将自己手里唯一的票投给其中一个候选者。
对应到 Raft 算法中,选主是周期进行的,包括选主和任值两个时间段,选主阶段对应投票阶段,任值阶段对应节点成为主之后的任期。
但也有例外的时候,如果主节点故障,会立马发起选举,重新选出一个主节点。
Google 开源的 Kubernetes,擅长容器管理与调度,为了保证可靠性,通常会部署 3 个节点用于数据备份。
这 3 个节点中,有一个会被选为主,其他节点作为备份。
Kubernetes 的选主采用的是开源的 etcd 组件。而,etcd 的集群管理器 etcd,是一个高可用、强一致性的服务发现存储仓库,就是采用了 Raft 算法来实现选主和一致性的。
Raft 算法具有选举速度快、算法复杂度低、易于实现的优点;
缺点是,它要求系统内每个节点都可以相互通信,且需要获得过半的投票数才能选主成功,因此通信量大。
该算法选举稳定性比 Bully 算法好,这是因为当有新节点加入或节点故障恢复后,会触发选主,但不一定会真正切主,除非新节点或故障后恢复的节点获得投票数过半,才会导致切主。
四、etcd术语
Raft:etcd所采用的保证分布式系统强一致性的算法。
Node:一个Raft状态机实例。
Member: 一个etcd实例。它管理着一个Node,并且可以为客户端请求提供服务。
Cluster:由多个Member构成可以协同工作的etcd集群。
Peer:对同一个etcd集群中另外一个Member的称呼。
Client: 向etcd集群发送HTTP请求的客户端。
WAL:预写式日志,etcd用于持久化存储的日志格式。
snapshot:etcd防止WAL文件过多而设置的快照,存储etcd数据状态。
Proxy:etcd的一种模式,为etcd集群提供反向代理服务。
Leader(领导者):Raft算法中通过竞选而产生的处理所有数据提交的节点。
Follower(跟随者):竞选失败的节点作为Raft中的从属节点,为算法提供强一致性保证。
Candidate:当Follower超过一定时间接收不到Leader的心跳时转变为Candidate开始Leader竞选。
Term:某个节点成为Leader到下一次竞选开始的时间周期,称为一个Term。
Index:数据项编号。Raft中通过Term和Index来定位数据。
五、etcd安装
1、上传etcd安装包(网络下载太慢了)

解压:tar -zxvf etcd-v3.4.3-linux-amd64.tar.gz

2、切换至etcd根目录,将etcd和etcdctl二进制文件复制到/usr/local/bin目录这样系统中可以直接调用etcd/etcdctl这两个程序
cp etcd etcdctl /usr/local/bin

3、查看etcd版本
etcd --version

4、输入命令etcd,即可启动一个单节点的etcd服务,ctrl+c即可停止服务
xxxx-xx-xx xx:xx:xx.xxxxxx I | embed: name = default
xxxx-xx-xx xx:xx:xx.xxxxxx I | embed: data dir = default.etcd
xxxx-xx-xx xx:xx:xx.xxxxxx I | embed: member dir = default.etcd/member
xxxx-xx-xx xx:xx:xx.xxxxxx I | embed: heartbeat = 100ms
xxxx-xx-xx xx:xx:xx.xxxxxx I | embed: election = 1000ms
xxxx-xx-xx xx:xx:xx.xxxxxx I | embed: snapshot count = 100000
xxxx-xx-xx xx:xx:xx.xxxxxx I | embed: advertise client URLs = http://localhost:2379
xxxx-xx-xx xx:xx:xx.xxxxxx I | etcdserver: starting member 8e9e05c52164694d in cluster cdf818194e3a8c321.name表示节点名称,默认为default。
2.data-dir 保存日志和快照的目录,默认为当前工作目录default.etcd/目录下。
3.在http://localhost:2380和集群中其他节点通信。
4.在http://localhost:2379提供客户端交互。
5.heartbeat为100ms,该参数的作用是leader多久发送一次心跳到followers,默认值是100ms。
6.election为1000ms,该参数的作用是重新投票的超时时间,如果follow在该时间间隔没有收到心跳包,会触发重新投票,默认为1000ms。
7.snapshot count为10000,该参数的作用是指定有多少事务被提交时,触发截取快照保存到磁盘 8.集群和每个节点都会生成一个uuid。
9.启动的时候会运行raft,选举出leader

六、创建一个etcd服务
1、建立etcd相关目录(即数据文件和配置文件的保存位置)
mkdir -p /var/lib/etcd/ && mkdir -p /etc/etcd/

2、创建etcd配置文件
vim /etc/etcd/etcd.conf
输入内容:
# 节点名称 ETCD_NAME="etcd0" # 指定数据文件存放位置 ETCD_DATA_DIR="/var/lib/etcd/"
按住i进行编辑,按Esc,输入":wq"进行强制保存退出

3、创建systemd配置文件
vim /etc/systemd/system/etcd.service
输入内容:
[Unit] Description=Etcd Server After=network.target After=network-online.target Wants=network-online.target [Service] User=root Type=notify WorkingDirectory=/var/lib/etcd/ ## 根据实际情况修改EnvironmentFile和ExecStart这两个参数值 ## 1.EnvironmentFile即配置文件的位置,注意“-”不能少 EnvironmentFile=-/etc/etcd/etcd.conf ## 2.ExecStart即etcd启动程序位置 ExecStart=/usr/local/bin/etcd Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target

4、启动/停止/查看etcd服务
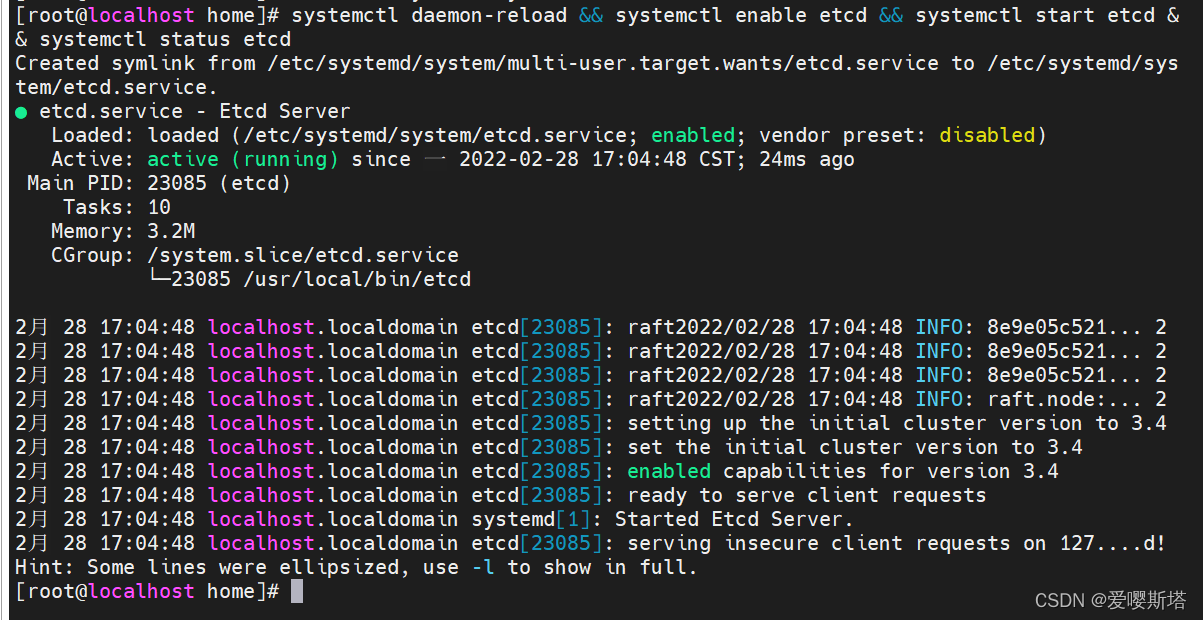
systemctl daemon-reload && systemctl enable etcd && systemctl start etcd && systemctl status etcd
七、etcd基本使用
etcdctl是一个命令行客户端,可以对etcd服务进行测试或者手动修改数据库内容。另外,etcdctl还支持HTTP API(之后介绍)。
etcdctl支持的命令大体上分为数据库操作和非数据库操作两类。
1、帮助命令
etcdctl -h
2、put 放入数据
etcdctl put /testdir/testkey "Hello world"
--sort 对结果进行排序
--consistent 将请求发给主节点,保证获取内容的一致性。在客户端放入数据:键为aa,值为123

3、get拿取数据
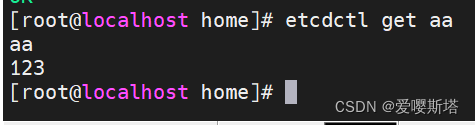
4、del 删除数据
清空数据
etcdctl del / --prefix
删除所有/test前缀的节点
etcdctl del /test --prefix

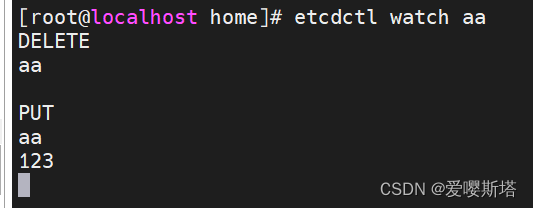
5、watch,监测一个键值的变化,一旦键值发生更新,就会输出最新的值并退出
etcdctl watch key1
本期内容结束~~~~~~~~~~