文章目录
网络KPI介绍
- 什么是KPI?
KPI可以看作是一种时间序列,时间序列包含时间戳以及时间戳上对应的取值。(例如股票走势,气温变化,心电图等等都可以被看做时间序列)
-
什么是网络KPI?
网络设备在运行的过程中会持续的产生大量的数据,例如告警,KPI,日志,MML等等。KPI是能够反映网络性能与设备运行状态的一类指标。比较常见的KPI指标有:
| KPI类别 | 举例 | 特征 | |
|---|---|---|---|
| 1 | 成功率类指标 | 附着成功率,下载成功率 | 整体上相对平稳 |
| 2 | 次数类指标 | 请求次数,错误码次数 | 突变频率较多 |
| 3 | 时延类指标 |
网络设备KPI也可以看做是时间序列。
KPI的规模庞大,一个网元的原始KPI 5000+,衍生KPI约00+
KPI的表现形式也各不相同,例如
异常检测步骤
网络KPI异常检测是工程师的‘眼睛’,帮助工程师看到问题要识得庐山真面目,必须采用有效的KPI异常检测方法
举例说明
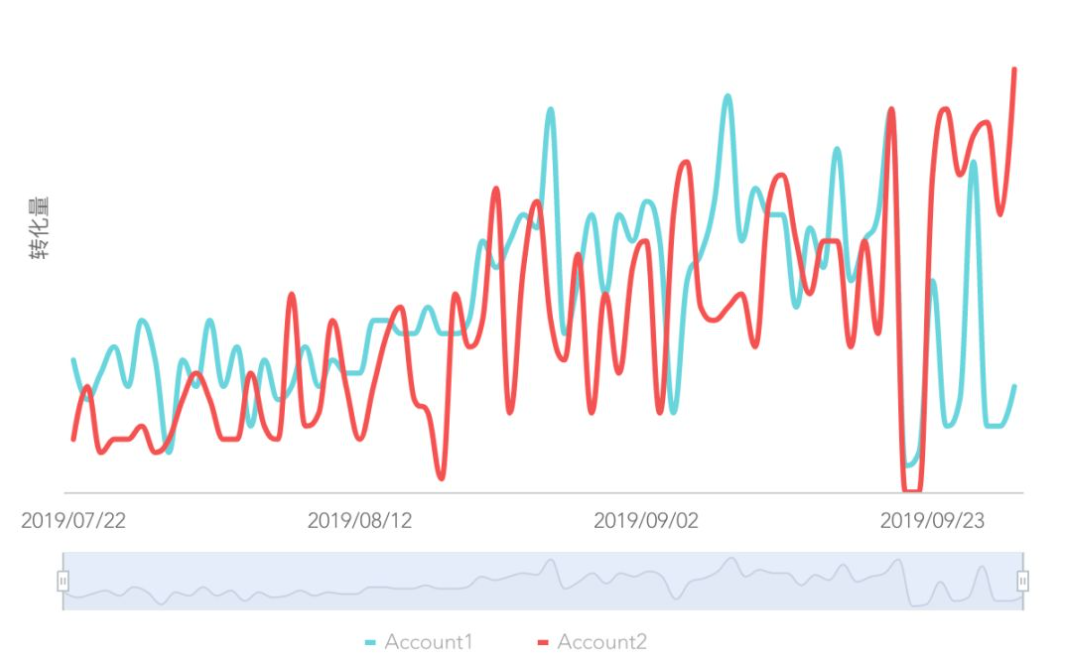
比如说我们要预测2019年11月29日1:00的数据。我们要它进行异常检测,那么我们可以取11月29号0:00到0:55分的历史数据。进行构造模型。记作F,此模型即可以给出11月29日1:00预测的下载成功率是92.7,得到数据之后与1:00的真实结果71.12进行对比。用残差的方式进行相见,可以得到相减值为21.58,假如说我们定义的异常门限为10。则可以发现残差已经大于门限,此时即可以上报异常。

遇到的难点有:
- 时间序列相对复杂
- 函数F()构造复杂
这就需要我们有有效的KPI异常检测方法
异常表现形式
成功率指标在某一时刻突降
错误码指标在某一时刻突增
可以看到在图片中出现了明显的突增(错误码)和突降(成功率)

更复杂的表现形式
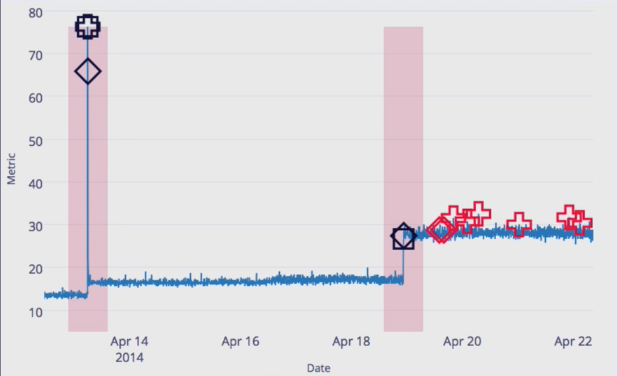
序列平移异常
此案例来自于某一设备温度时间序列,根据经验来看,此设备温度应该维持在10度-20度之间,可以看到在图片左侧有非常明显的突增,温度突增到80度,而右侧的徒增则不是特别明显,但是右侧对于设备的影响非常严重(不允许超过20度),这就是对设备门限的控制得当
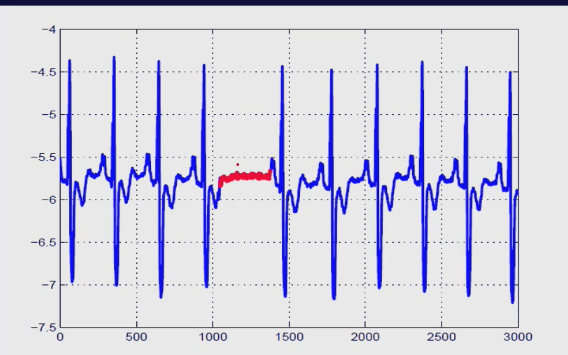
模式变换
此图为心电图,人的心跳反应在心电图上就是相当于周期波动,可以看到在中间有一段红色相对平坦的信号,可以看出它与正常信号的差异非常明显,由于他没有波动,可以认为此人此时心跳可能骤停
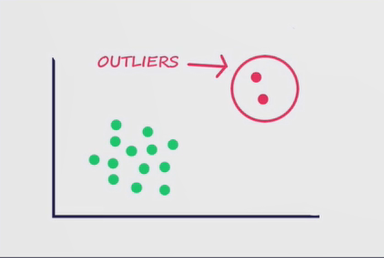
异常定义
离群点与异常
离群点:离群点Outlier是一个更广泛的概念,通常指与样本总体差别较大的点
异常的定义:异常是样本空间中的一种样本,它们与样本空间中其他样本是如此的不同,以致人们不得不怀疑它们是通过另外一种机制产生的。-Hawkins,1980
如下图所示,正常的预测点位于绿色部分,异常的预测点位于红色圆圈
再如下图所示,身高2.26米,是一个离群点身高3米,是异常,
即认为人类不可能身高3米或者身高2.72米

离群点与异常的不同:
- 离群点虽然与样本总体差别较大,但仍在可接受的范围内,只是出现的概率较小一些
- 异常则完全由不同的机制产生
- 实践当中通常不加以严格区分
不同领域的异常
异常的定义中没有说明数据类型,因此适用广泛,包括表格数据、图像、文本、时间序列,异常的定义都是一致的
例如下图可以看到右侧黑色车辆有一个轧白线的的违章动作,对于交警处理违章问题帮助很大
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X2qGIPKg-1644336390625)(C:/Users/19867/AppData/Roaming/Typora/typora-user-images/image-20220127110918206.png)]
此图为NLP自然语言处理,正常评论为与内容相关的评论,而恶意评论则是一些与内容不相干的评论

总结:异常的两个特点:明显区别,极少出现
异常检测的主要方法
1基于距离的方法
1.1根据样本集X计算当前样本x的预测值x0
1.2计算样本真实值x与x0的距离d=|x-x0|
1.3若距离大于阈值t,则判断为异常
2基于分布的方法
2.1根据样本集X计算当前样本x的分布f(x)
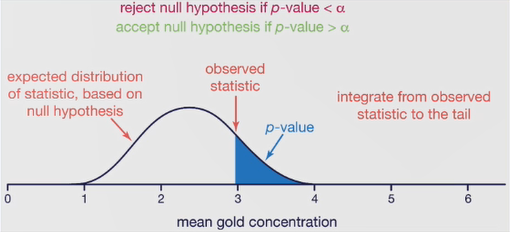
2.2根据分布f和样本真实值x做假设检验,计算p值
2.3若p值低于显著性水平a(0.05),则认为检测到异常
时间序列异常检测的难点
时间序列检测的难点最主要的就是门限的设置,因为不同人对异常的感受是不一样的,有的人可能感受很敏感,有的人觉得无所谓,他们心目中的门限可能有高有低,这是一个很难去统一的标准。
异常是与众不同的,但是这个"众"我们应该怎样去定义,下面通过一个例子来解释
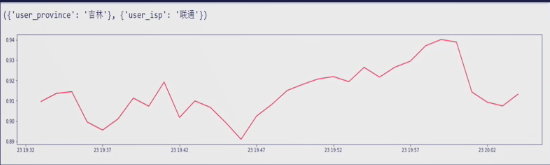
下面这个图为时间序列,可能很难发现他有与众不同的点
但是将时间序列拉长后如下图所示
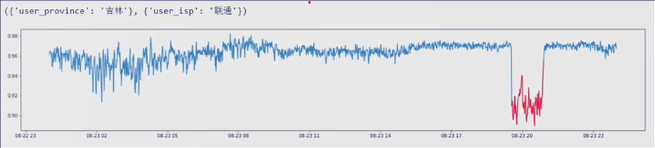
可以看出红色部分本身即为异常
异常检测常见方法
Z-score方法
一组正态分布样本中,偏离均值3倍标准差之外的区间的概率密度很低,若样本落在这个区间,则很可能是异常
Zscore是衡量正态分布样本的偏离程度的指标
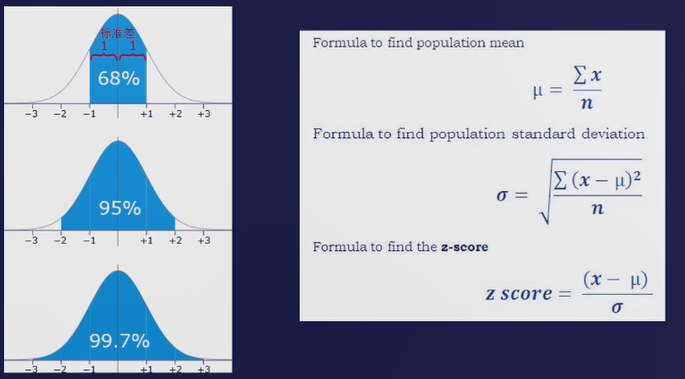
将时间序列每个时间戳的点视为一个样本用z-score计算每个时间点的偏离程度,若大于阈值(3)则判断为异常
注明:只能检测明显的值异常,不能检测序列异常

我们可以看到下图中间的绿色线为均值,上下面的绿线为标准差,且有3个值Outlier位于绿线外面
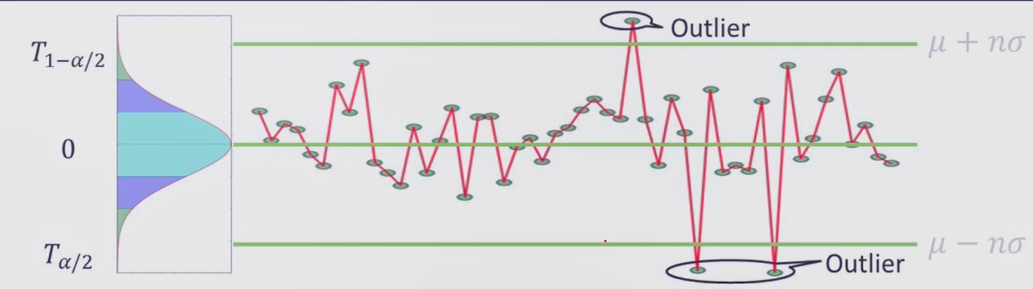
Z-score方法弊端:没有用到任何时间序列的信息,也就是说这个时间序列是否有序,检测出的异常不会发生变化这显然是不符合我们需求的,因为很多异常可能是一些局部的特征,所以此方法不能用于检测序列的异常
滑动平均法(Moving Average,MA)
MA的方法利用到了序列的特征,滑动平均法基于最近时刻的值估计当前时刻的取值
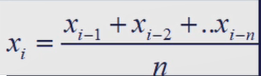
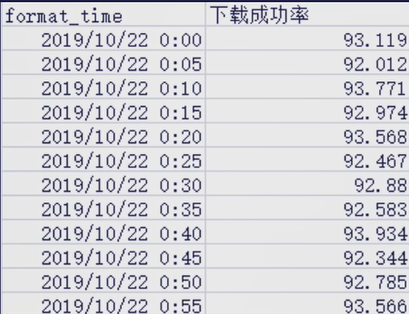
例如在下面的时间序列,我们要预测1:00的下载成功率,那就把0:00到0:55的下载成功率取平均值,即可以得到1:00滑动平均的结果为3
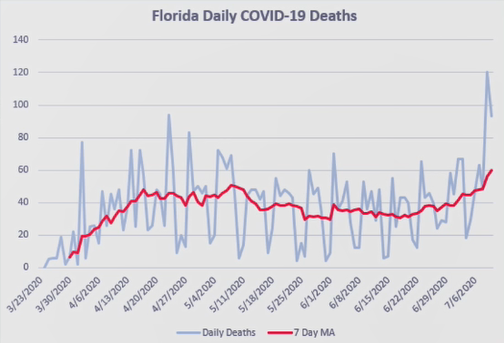
此图展示了美国佛罗里达州的新冠人数,蓝色线为真实值,红色线基于7天平均值的预测值
指数加权滑动平均法(Exponential Weighted Moving Average,EWMA)
由于序列的距离-相似性,越近的点相似度越高,因此在做滑动平均时采取等权重是不合适的,直观上来说应当给较近的点较高的权重
第i时刻的加权求和满足:

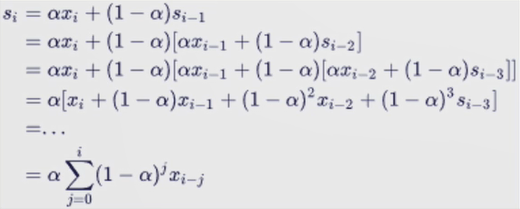
Si为当前时刻的真实值,α为衰减因子,值越大则最近数据的权重越高,历史数据的权重越低
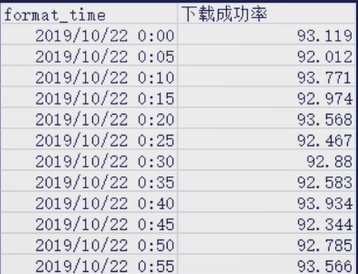
采用EWMA,设a=0.5,则预测下一时刻2019/10/22 1:00的取值为93.166
同比与环比
环比:当前时刻与前一时刻之比

例如国家统计局计算GDP以月为单位,比如算2020年2月份的GDP有没有达到预期,就需要和上个月进行对比,这就叫做环比,环比是当前时刻与前一时刻之比。
如果是2020年2月份和2019年12月份对比,这就叫做同比,同比是当前时刻与上一周期同一时刻之比。
下图为典型的时间序列
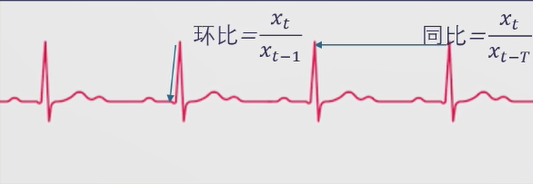
使用同比可以较容易的预测出下一个高峰的出现时间,而环比则很难预测
Boxplot方法
环比和同比在时间序列检测中的应用为Boxplot方法
Boxplot双线图是数据科学家在分析数据分布的情况下经常用的一种方法
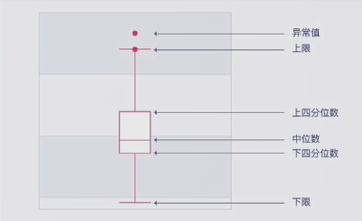
下图为100名学生的考试成绩,中位数为第50名的学生成绩,上四分数为第25名孩子的成绩,下四分数为第75名孩子的成绩
IQR为
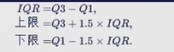
超过上限和下限的值均为异常值
下图为用Boxplot检测异常值实例(蓝色线为预测值,绿线为真实值)
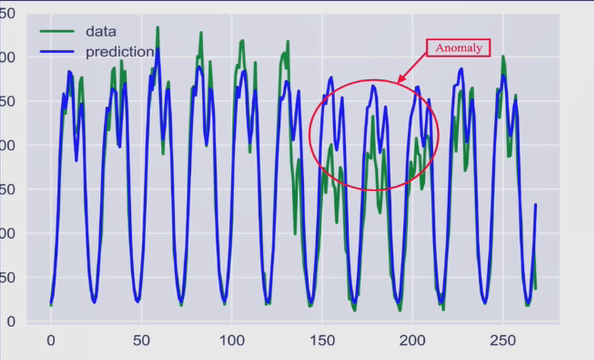
Boxplot(箱线图)通过绘制数据分布分位数的方式检测异常点分位数相比于3 sigma:无需假设正态分布,适用更广
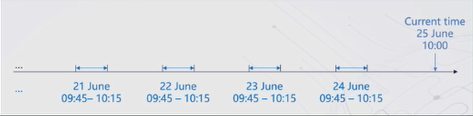
基于同比数据,更符合当前数据的分布
算法总结
z-score:异常+检测
MA,EWMA:序列+异常+检测
Boxplot:时间+序列+异常+检测
异常:零维,样本之间是独立同分布的,不存在任何顺序关系序列
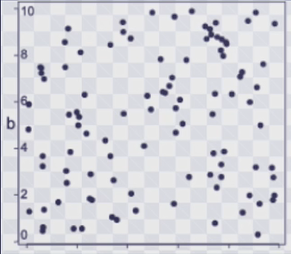
异常:一维,样本仅与前后样本有关,只在一个方向上演化
时间序列异常:二维,样本不仅与前后样本有关,也与上一周期内的样本有关,在两个方向演化
例如此飞镖盘有很多块组成,可以形成不同的分数,分数与所在的环有关,在同一个环,击中的概率相同(同比),在不同的环环比情况下外侧击中概率较大,分值相对较小(环比)

KPI异常检测实例
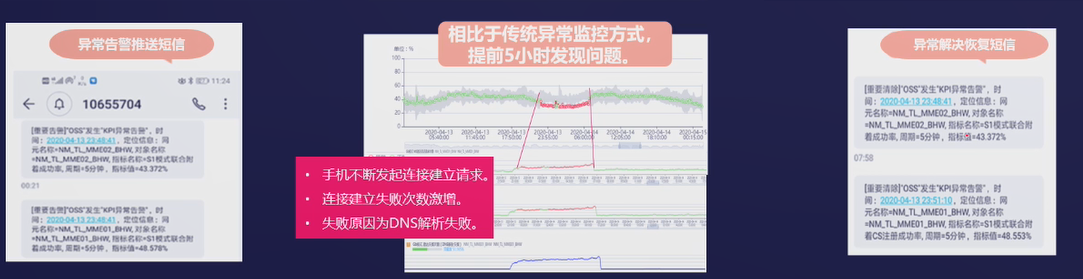
KPI异常检测帮助运营商提前5小时发现问题,保障四地市用户体验

及时发送信息
总结异常检测
异常检测的方法有很多,总结起来分为三类
0维:只看整体,不看轮廓
1维:只看轮廓,不看整体
2维:既看整体,又看轮廓

要做好时间序列异常检测,必须同时做好‘时间’、‘序列’、‘异常三个层面的工作,三者相辅相成,缺一不可。
异常检测演示
涵盖数据预处理、特征提取、模型训练、模型验证、推理执行和重训练全流程。该服务提供开发环境和模拟验证环境,内嵌华为在电信领域30多年积累的的知识和经验沉淀,内置50+电信领域资产,包括项目模板,算法、特征分析及处理SDK。帮助开发者降低开发门槛,提升开发效率,保障模型应用效果