抓包测试
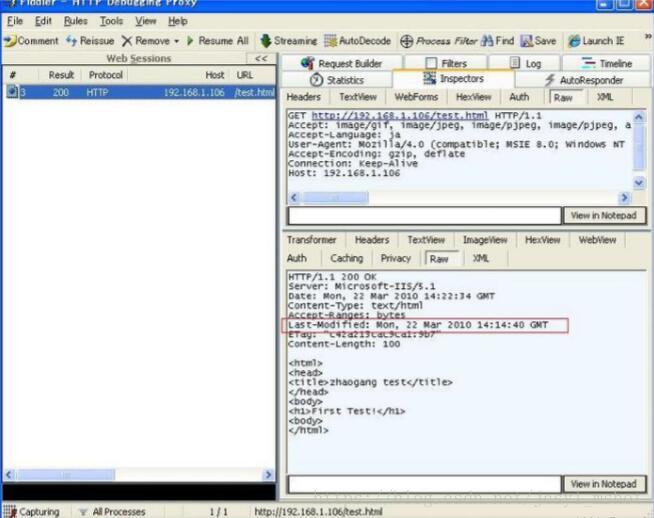
1.首先在服务器创建一个简单的 HTML 文件,用浏览器访问一下,成功表示 HTML 页 面。Fiddler 就会产生下面的捕获信息。 需要留意的是
(1)因为是第一次访问该页面,客户端发请求时,请求头中没有 If-Modified-Since 标 签。
(2)服务器返回的 HTTP 状态码是 200,并发送页面的全部内容。
(3)服务器返回的 HTTP 头标签中有 Last-Modified,告诉客户端页面的最后修改时间。
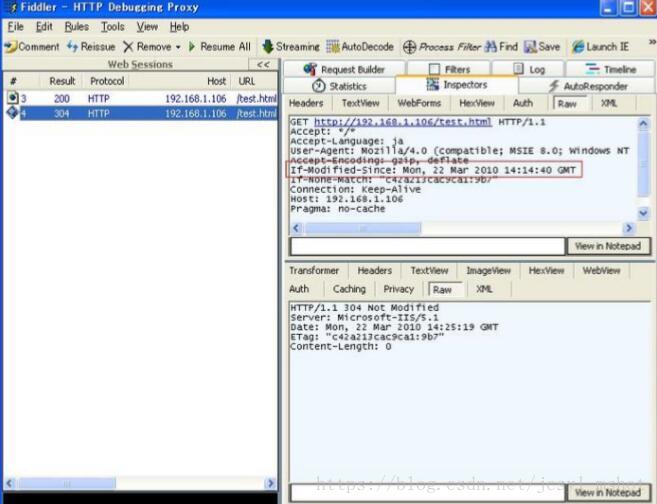
2.在浏览器中刷新一下页面,Fiddler 就会产生下面的捕获信息。 需要注意的是
(1)客户端发 HTTP 请求时,使用 If-Modified-Since 标签,把上次服务器告诉它的文 件最后修改时间返回到服务器端了。
(2)因为文件没有改动过,所以服务器返回的 HTTP 状态码是 304,没有发送页面的内 容。
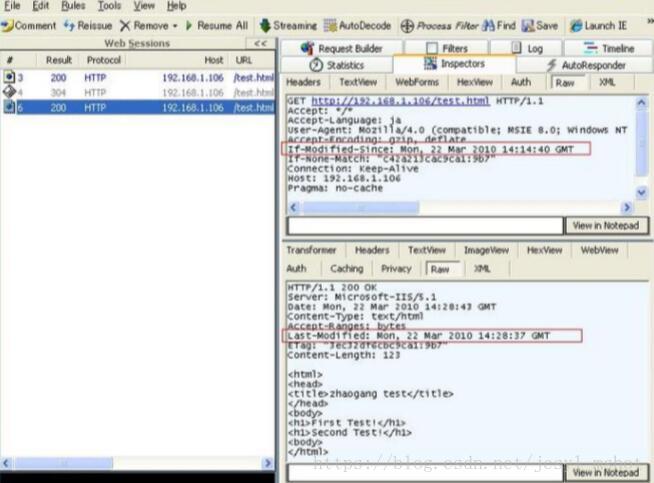
3.用文本编辑器稍微改动一下页面文件,保存。再用浏览器访问一下,Fiddler 就会产 生下面的捕获信息。
需要留意的是
(1)客户端发 HTTP 请求时,使用 If-Modified-Since 标签,把上次服务器告诉它的文 件最后修改时间返回到服务器端了。
(2)因为文件被改动过,两边时间不一致,所以服务器返回的 HTTP 状态码是 200,并 发送新页面的全部内容。
(3)服务器返回的 HTTP 头标签中有 Last-Modified,告诉客户端页面的新的最后修改 时间。
Http1.1 和 Http1.0 的区别
1.默认持久连接和流水线 HTTP/1.1 默认使用持久连接,只要客户端服务端任意一端没有明确提出断开 TCP 连 接,就一直保持连接,在同一个 TCP 连接下,可以发送多次 HTTP 请求。同时,默认采用 流水线的方式发送请求,即客户端每遇到一个对象引用就立即发出一个请求,而不必等到收到前一个响应之后才能发出下一个请求,但服务器端必须按照接收到客户端请求的先后顺序依次回送响应结果,以保证客户端能够区分出每次请求的响应内容,这样也显著地减少了整个下载过程所需要的时间。
HTTP/1.0 默认使用短连接,要建立长连接,可以在请求消息中包含 Connection: Keep-Alive 头域,如果服务器愿意维持这条连接,在响应消息中也会包含一个 Connection: Keep-Alive 的头域。Connection 请求头的值为 Keep-Alive 时,客户端通知服务器返回本次 请求结果后保持连接;Connection 请求头的值为 close 时,客户端通知服务器返回本次请 求结果后关闭连接。
2.分块传输数据 HTTP/1.0 可用来指定实体长度的唯一机制是通过 Content-Length 字段。静态资源的 长度可以很容易地确定,但是对于动态生成的响应来说,为获取它的真实长度,只能等它 完全生成之后,才能正确地填写 Content-Length 的值,这便要求缓存整个响应,在服务 器端占用大量的缓存,从而延长了响应用户的时间。
HTTP/1.1 引入了被称为分块(chunked)的传输方法。该方法使发送方能将消息实体 分割为任意大小的组块(chunk),并单独地发送他们。在每个组块前面,都加上了该组块 的长度,使接收方可确保自己能够完整地接收到这个组块。更重要的是,在最末尾的地方,发送方生成了长度为零的组块,接收方可据此判断整条消息都已安全地传输完毕。这样也 避免了在服务器端占用大量的缓存。Transfer-Encoding:chunked 向接收方指出:响应 将被分组块,对响应分析时,应采取不同于非分组块的方式。
3.状态码 100 Continue HTTP/1.1 加入了一个新的状态码 100 Continue,用于客户端在发送 POST 数据给服 务器前,征询服务器的情况,看服务器是否处理 POST 的数据。 当要 POST 的数据大于 1024 字节的时候,客户端并不会直接就发起 POST 请求, 而 是会分为 2 步: 1. 发送一个请求, 包含一个 Expect:100-continue, 询问 Server 是否愿意接受数据。 2. 接收到 Server 返回的 100 continue 应答以后, 才把数据 POST 给 Server。 这种情况通常发生在客户端准备发送一个冗长的请求给服务器,但是不确认服务器是否有能力接收。如果没有得到确认,而将一个冗长的请求包发送给服务器,然后包被服务器给抛弃了,这种情况挺浪费资源的。
4.Host 域 HTTP1.1 在 Request 消息头里多了一个 Host 域,HTTP1.0 则没有这个域。 在 HTTP1.0 中认为每台服务器都绑定一个唯一的 IP 地址,这个 IP 地址上只有一个主机。但随着虚拟 主机技术的发展,在一台物理服务器上可以存在多个虚拟主机,并且它们共享一个 IP 地址。
http 的请求方式 get 和 post 的区别
1.GET 一般用于获取或者查询资源信息,这就意味着它是幂等的(对同一个 URL 的 多个请求返回同样的结果)和安全的(没有修改资源的状态),而 POST 一般用于更新资 源信息,POST 既不是安全的,也不是幂等的。
2.采用 GET 方法时,客户端把要发送的数据添加到 URL 后面(就是把数据放置在 HTTP 协议头中,GET 是通过 URL 提交数据的),并且用“?”连接,各个变量之间用“&” 连接; HTTP 协议没有对 URL 长度进行限制,由于特定的浏览器及服务器对 URL 的长度存 在限制,所以传递的数据量有限; 通过 GET 提交数据,用户名和密码将明文出现在 URL 上,因为(1)登录页面有可能被 浏览器缓存,(2)其他人查看浏览器的“历史纪录”,那么别人就可以拿到你的账号和密码 了。
而 POST 把要传递的数据放到 HTTP 请求报文的消息体中; HTTP 协议也没有进行大小限制,起限制作用的是服务器的处理程序的能力,但是,传送的数据量比 GET 方法更大 些;由于传递的数据在消息体中,安全性高,但其实用抓包软件(如 httpwatch)进行抓包 的话,可以看到传递的数据内容的。
3.GET 请求的数据会被浏览器缓存起来,会留下历史记录;而 POST 提交的数据不 会被浏览器缓存,不会留下历史记录。
http 的安全问题
a、通信使用明文不加密,内容可能被窃听
b、不验证通信方身份,可能遭到伪装
c、无法验证报文完整性,可能被篡改
HTTPS 就是 HTTP 加上加密处理(一般是 SSL 安全通信线路)+认证+完整性保护
Https 的作用
• 内容加密 建立一个信息安全通道,来保证数据传输的安全;
• 身份认证 确认网站的真实性
• 数据完整性 防止内容被第三方冒充或者篡改
1. 对称加密算法
用于对真正传输的数据进行加密。
2.非对称加密算法
用于在握手过程中加密生成的密码。非对称加密算法会生成公钥和私钥,公钥只能用于加密数据,因此可以随意传输,而网站的私钥用于对数据进行解密,所以网站都会非常小心的保管自己的私钥,防止泄漏。
【1. 我发送给你的内容必须加密,在邮件的传输过程中不能被别人看到。
当A->B资料时,A会使用B的公钥加密,这样才能确保只有B能解开
2. 必须保证是我发送的邮件,不是别人冒充我的。
A传资料给大家时,会以自己的私钥做签章,如此所有收到讯息的人都可以用A的公钥进行验章,便可确认讯息是由 A 发出来的了】
3.散列算法
用于验证数据的完整性。
4.数字证书