Spark -map算子
map算子:
object Spark01_Oper {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("Value")
val cs = new SparkContext(conf)
val make = cs.makeRDD(1 to 10)
//map算子
val mapRdd = make.map(x => x * 2)
mapRdd.collect().foreach(println)
}
}
map 算子是一个一个的去计算传入的所有分区中的数据。
mapPartRdd算子
object Spark02_OPer {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("mapPart")
val sc = new SparkContext(conf)
//map算子
val list = sc.makeRDD(1 to 10)
val mapPartRdd = list.mapPartitions(datas => {datas.map(data => data*2)})
mapPartRdd.collect().foreach(println)
}
}
mapPartRdd 算子 类似于map但是他是以分区来进行数据计算的,而他在进行计算时的输出值是一个列表
mapPartitionsWithIndex算子
object Spark03_OPer {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("With")
val sc = new SparkContext(conf)
val list = sc.makeRDD(1 to 10,2)
val indexRDD = list.mapPartitionsWithIndex {
case (num, datas) => {
datas.map((_,"分区号:"+num))
}
}
indexRDD.collect().foreach(println)
}
}mapPartitionsWithIndex算子类似于mapPartiyions但是在func会带有一个表示分区的索引值,所以func的函数类似会多一个 Int。
spark的可能出现的问题:
因为每次计算数据都会生产新的数据出现但是没有进行删除,一直累积就会造成内存溢出的(OOM)
Driver与Executor的区别
Driver:
Driver只要创建了Spark上下文对象的类都可以说是Driver,Driver是Spark中Application也即代码的发布程序,可以理解为我们编写spark代码的主程序,其次他还负责Executor的进行任务分配,Driver只能存在一个
Executor:
Executor是Spark中负责资源计算的,他可以存在多个。
区别:
Drvier像一个老大,而Executor是Driver的手下,Driver负责将任务分配给Executor来进行执行。
Linux拾遗
linux的开关机方法
1.关机: shutdown -h 重启:shutdown -r
2.关机: inti -0 重启: init -6
3.关机: poweroff 重启:reboot
service 与systemctl的区别
service:
可以启动、停止、重新启动和关闭系统服务,还可以显示所有系统服务的当前状态,service命令的作用是去/etc/init.d目录下寻找相应的服务,进行开启和关闭等操作
systemctl:
是一个systemd工具,主要负责控制systemd系统和服务管理器,是service和chkconfig 命令的组合
网络设备的操作:


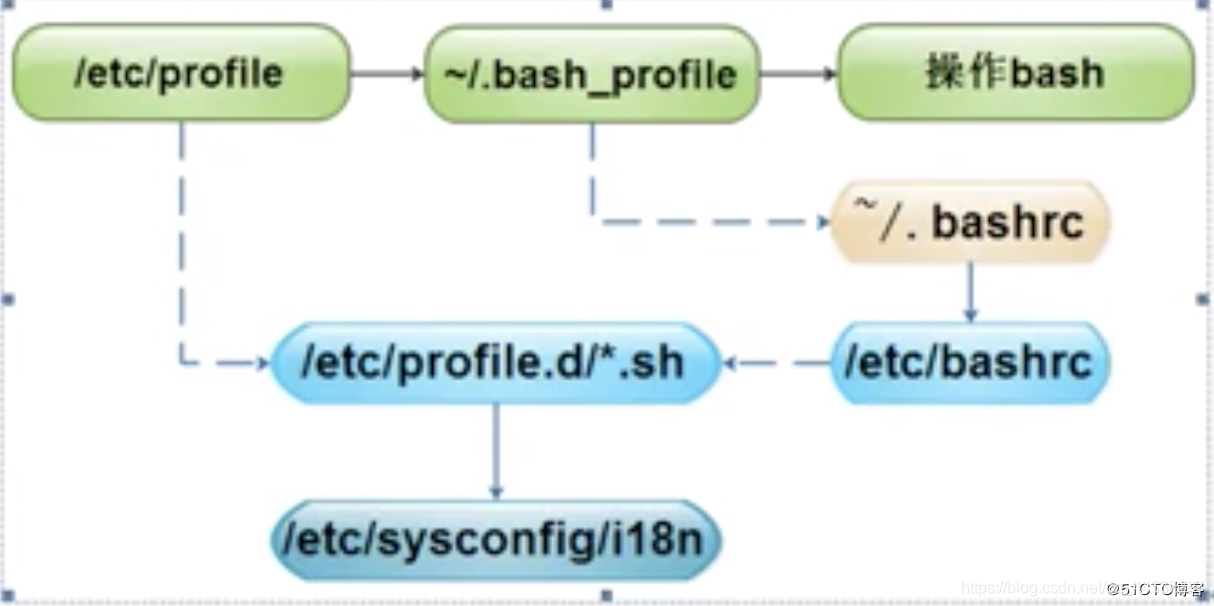
环境变量加载顺序