全文主角
class TreeNode {
int value;
TreeNode left;
TreeNode right;
TreeNode(int val){
value = val;
}
}
本次讨论二叉树的序列化 / 反序列化,下面按照 两序、层序、前序 三种办法依次分析并给出参考代码实现,这三种方式按思考形式由浅至较浅,代码量由多到较少。
一. 两序遍历(前序 + 中序)
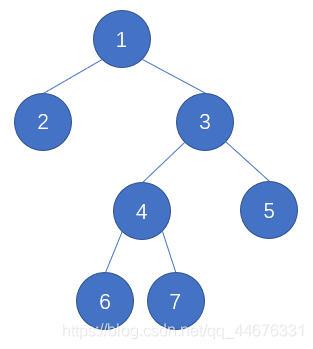
对于上面的主角,其前序、中序遍历的结果分别是
前序:1 2 3 4 6 7 5
中序:2 1 6 4 7 3 5
我们都知道,
前序遍历的特点是,对于任意节点,先打印自己的值,再遍历左子树,再遍历右子树;
中序遍历的特点是,对于任意节点,先遍历左子树,再打印自己的值,再遍历右子树。
我们从根节点出发,对比前序和中序遍历的结果
前序:1 2 3 4 6 7 5
中序:2 1 6 4 7 3 5
可以看到,
- 前序的第一个值是根节点的值;
- 从中序找到根节点的值,发现其左序列包含了根节点左子树的全部值,右序列包含了根节点右子树全部的值
如果把中序的结果以根节点为分界线,拆成两个子序列,然后对这两个子序列重新进行前序遍历,可得到如下结果
(1)原中序遍历的 左子序列
前序:2
中序:2
(2)原中序遍历的 右子序列
前序:3 4 6 7 5
中序:6 4 7 3 5
将(1)(2)的结果同整体的遍历比较,发现原中序的左子序列、右子序列,在原前序中是连续的。
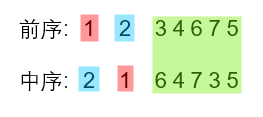
为了进一步验证不是巧合,我们拿绿色部分的序列再次尝试得到如下结果
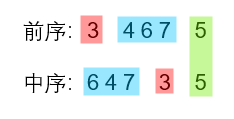
再拿蓝色部分验证
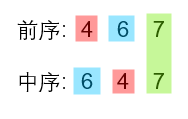
经多次比对,我们得出了结论:
- 前序的第一个值,就是当前节点的值
- 找到中序中对应的当前节点值,则其左、右子序列在前序中是连续的
- 对于中序的 任意左、右子序列 都满足以上两点
根据以上三点结论,我么可以通过二叉树的前序+中序遍历结果,还原出原二叉树
//前序遍历:1,2,3,4,6,7,5,
public void frontScan(TreeNode node, StringBuilder sb){
if(node != null){
sb.append(node.value).append(',');
frontScan(node.left, sb);
frontScan(node.right, sb);
}
}
//中序遍历:2,1,6,4,7,3,5,
public void mediumScan(TreeNode node, StringBuilder sb){
if(node != null){
mediumScan(node.left, sb);
sb.append(node.value).append(',');
mediumScan(node.right, sb);
}
}
//序列化
public String serialize(TreeNode root){
//前序和中序遍历结果用 '&' 分隔
StringBuilder res = frontScan(root);
if(res.length() > 0) {
res.setCharAt(res.length() - 1, '&');
}
res.append(mediumScan(root));
if(res.length() > 0){
res.setLength(res.length() - 1)
}
return res.toString();
}
反序列化步骤:
① 把序列化的String还原成俩数组
② 以前序为主,序列第一个值就是当前节点
③ 在中序中找到该值,以此作为分界点,把中序拆成左、右两部分
④ 把前序也拆成两部分,元素数量同中序左、右部分相等(忽略首元素)
//把序列化得到的字符串还原成前序、中序数组
public TreeNode decode(String serial){
if(serial == null || serial.equals("")) return null;
String[] fm = serial.split("&");
int[] frontScan = parse(fm[0]);
int[] mediumScan = parse(fm[1]);
return build(frontScan, mediumScan);
}
//把 String[] 转换成 int[]
private int[] parse(String array){
String[] elements = array.split(",");
int[] res = new int[elements.length];
for (int i = 0; i < elements.length; i++) {
res[i] = Integer.parseInt(elements[i]);
}
return res;
}
//重建二叉树
//fs:前序遍历结果 ms:中序遍历结果
private TreeNode build(int[] fs, int[] ms){
//前序的首元素 是当前节点值
TreeNode node = new TreeNode(fs[0]);
//从中序里找到当前节点值的索引位置
int index = findIndex(ms, fs[0]);
//如果当前节点还有左子树
if(index > 0){
//原中序的左子序列
int[] msNew = new int[index];
System.arraycopy(ms, 0, msNew, 0, index);
//原中序的右子序列
int[] fsNew = new int[index];
System.arraycopy(fs, 1, fsNew, 0, index);
//重建左子树
node.left = build(fsNew, msNew);
}
//如果当前节点还有右子树
if(index != -1 && index < ms.length - 1){
int[] msNew = new int[ms.length - index - 1];
System.arraycopy(ms, index + 1, msNew, 0, msNew.length);
int[] fsNew = new int[msNew.length];
System.arraycopy(fs, index + 1, fsNew, 0, fsNew.length);
node.right = build(fsNew, msNew);
}
return node;
}
private int findIndex(int[] ms, int aim){
for (int i = 0; i < ms.length; i++) {
if(ms[i] == aim) return i;
}
return -1;
}
缺点:
- 序列化时需要遍历两次二叉树,当节点数量较多时,效率不高,而且序列化字符串偏长
- 反序列化时创建的左、右子序列数组对象较多
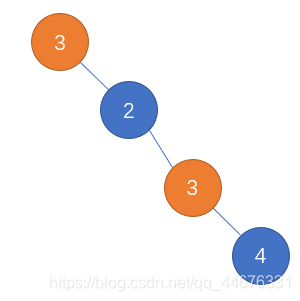
- 如果二叉树内意外地出现了重复节点,则反序列化结果可能错误,比如下面这种情况

前序:3 2 3 4
中序:3 2 3 4
经反序列化 重建完的树是这样的
二. 层序
前序 / 中序遍历是逮着一条道走到黑的方式,叫深度搜索,而层序遍历是一层一层的遍历,叫广度搜索。
如果将二叉树按层编号,就是下面这个样子
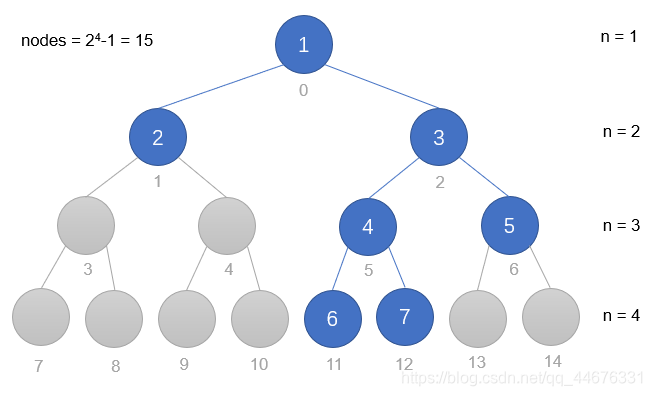
如果二叉树的父节点编号为 i,则其左儿子编号为 2*i+1 ,右儿子编号为 2*i+2
如果二叉树的最大高度为 n,则其满节点数为 2n-1
按照上图的编号,我们可以把所有节点装进一个数组里 —— 序列化;
根据父子节点编号关系,重建二叉树 —— 反序列化。
序列化步骤:
① 开辟空间足够大的数组 2n-1
② 层序遍历,把节点装进数组对应的位置上
//确定树高度
public int getN(TreeNode node){
//null节点 n = 0
if(node == null){
return 0;
}
//选取左、右子树较高的那个叉
int leftN = getN(node.left);
int rightN = getN(node.right);
return Math.max(leftN, rightN) + 1;
}
//层序遍历二叉树,填装节点
public String fillNodes(TreeNode root){
if(root == null) return "";
//开辟足够空间的节点数组
TreeNode[] nodes = new TreeNode[ (int)Math.pow(2, getN(root)) - 1 ];
//借助队列结构,层序遍历
//nodeQueue暂存节点,indexQueue暂存节点对应的编号
Queue<TreeNode> nodeQueue = new LinkedList<>();
Queue<Integer> indexQueue = new LinkedList<>();
nodeQueue.offer(root);
indexQueue.offer(0);
while(!nodeQueue.isEmpty()){
TreeNode node = nodeQueue.poll();
int index = indexQueue.poll();
nodes[index] = node;
//填node.left
if(node.left != null){
nodeQueue.offer(node.left);
indexQueue.offer(index * 2 + 1);
}
//填node.right
if(node.right != null){
nodeQueue.offer(node.right);
indexQueue.offer(index * 2 + 2);
}
}
//二叉树的最后一层可能有很多null(该树最后一层有2个null)
//优化一下TreeNode[]长度,把最后一层的null去掉(优化可选)
int length = nodes.length;
for (int i = length - 1; i >= 0; i--) {
if(nodes[i] == null){
length--;
}else{
break;
}
}
//序列化
StringBuilder sb = new StringBuilder();
for (int i = 0; i < length; i++) {
//该树中编号为 3 4 7 8 9 10 的都是null节点(13 14已被优化掉)
if(nodes[i] == null){
sb.append("null,");
}else{
sb.append(nodes[i].value).append(',');
}
}
return sb.toString();
}
反序列化步骤:
① 将序列化字符串拆成 String 数组 nums(字符串数字)
② 创建和 nums 等长的 TreeNode 数组
③ 扫描 nums 把有效的数值 包装成 TreeNode 装填到 TreeNode 数组
④ 按照 父子节点关系 关联引用
⑤ 返回 TreeNode 数组的首元素 —— root
public TreeNode deSerial(String serial){
if(serial == null || serial.equals("")) return null;
String[] nums = serial.split(",");
//临时节点数组,用于关联各节点之间的父子关系
TreeNode[] nodes = new TreeNode[nums.length];
//倒序装填节点,方便关联父子引用
for (int i = nodes.length - 1; i >= 0; i--) {
if(!nums[i].equals("null")){
nodes[i] = new TreeNode(Integer.parseInt(nums[i]));
if(2*i+1 < nodes.length)
nodes[i].left = nodes[2*i+1];
if(2*i+2 < nodes.length)
nodes[i].right = nodes[2*i+2];
}
}
return nodes[0];
}
缺点:
- 序列化时一次深搜、一次广搜,效率不高
- 当二叉树只有右子树的极端情况产生(线性链表)时,序列化字符串 记录了太多无用的 “null”

三. 前序
如果序列化按前序遍历的方式进行,那反序列化是否也能按前序的方式重构二叉树呢?
在 方式一 中,我们通过比对中序遍历,以中序遍历是否还有左、右子序列为基础,判断前序是否还有拆分的必要,如果单依靠前序,就需要找到另一种界限标志,判断下一步的走向。
递归方式前序遍历
① 首先打印自己的值;
② 然后向左遍历,当一个节点的左子节点为空,返回到该节点,继续向右遍历;
③ 当一个节点的右子节点为空,返回到该节点,该节点及其子树遍历完成,向上回溯。
是的,也许我们也可以用空节点作为改变方向的遍历条件
还是这棵树,这次我们给他加上叶子节点的空节点,它长这样
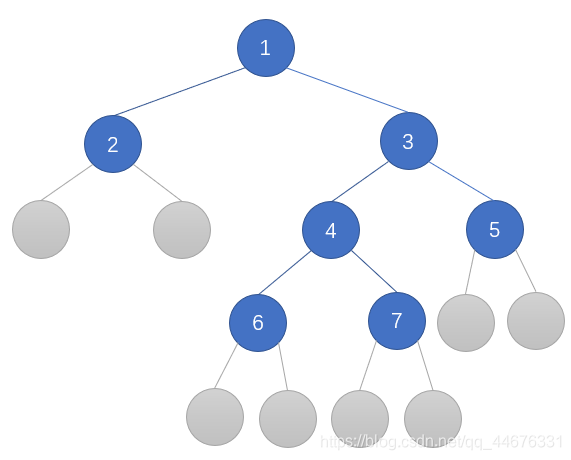
这次的前序遍历结果为:1, 2, null, null, 3, 4, 6, null, null, 7, null, null, 5, null, null
我们把以上序列添加到序列化字符串里
public String serialize(TreeNode root) {
StringBuilder res = new StringBuilder();
//利用栈暂存节点
LinkedList<TreeNode> stack = new LinkedList<>();
stack.push(root);
while(!stack.isEmpty()){
TreeNode node = stack.pop();
if(node == null){
res.append("null,");
}else{
res.append(node.value).append(',');
stack.push(node.right);
stack.push(node.left);
}
}
return res.toString();
}
反序列化步骤:
① 把序列化的字符串拆成 字符串数字数组 String[] nums
② 用递归的方式,每次方法调用都只初始化一个非 null 节点
③ 如果遇到 “null”,证明该节点是叶子节点的子节点(空节点),向上回溯;反之继续原来的路线。
//反序列化
public TreeNode deserialize(String data) {
//new int[]{-1} 是 data[] 的指针,保证 rDeserialize() 每次都能获取到 它应该处理的位置
return rDeserialize(data.split(","), new int[]{
-1});
}
//递归重构二叉树
private TreeNode rDeserialize(String[] nums, int[] p){
//每次方法调用都先把 p 指针定位到 本次方法 应该处理的位置上(线性扫描)
p[0]++;
//如果该位置是null,向上回溯
if(nums[p[0]].equals("null")){
return null;
}
//如果该位置不是null,按前序遍历的方式递归重构二叉树
TreeNode node = new TreeNode( Integer.parseInt(nums[p[0]]) );
node.left = rDeserialize(nums, p);
node.right = rDeserialize(nums, p);
return node;
}
三种方式相比下,单前序的序列化 / 反序列化在时间效率和空间消耗下平均相对较好。
感谢浏览!