我们知道mvcc多版本 控制机制可以保证 在可重复读的隔离级别下 当他查询一条sql 语句的时候 比方说 id=1 即使其他事务吧这个结果集修改了
只要当前事务没有提交 此时再查询的时候 id=1 永远不会变
串行化 所有的操作都会加锁,来实现的隔离性 串行化是有性能问题的
呢么mvcc是怎么保证的呢?
我们首先说下undo日志版本链,比方说当你减库存的时候吧 库存从10扣减到了4
你在修改i的时候 吧数据库改成4了 ,他实际上是会给你记录一个日志的吧改之前的数据记录在undo日志里 ,你回头如果这个事务要回滚的时候,我就根据我这个undo日志表去回滚他
undo日志 就是说你要改一条数据 改之前回吧原始的旧的给保留一份 再去对这条数据进行修改,如果没有改成功 对数据根据undo日志进行回滚操作
我们针对一行数据可能会做很多次操作 对于数据库来说 会把每一次修改的undo日志 用一个指针串联起来

类似于这样的,在一个表中,mysql 会在底层加2个隐藏字段,比如说account表trx_id [事务id ] roll_pointer[回滚指针]
我根据这个指针找到之前的老数据 我回头如果事务提交失败 回滚的时候就可以根据这个指针回滚了
然后每一次修改都会更改 trx_id 以及 增加指针连接到之前的数据,这个叫做一条数据的回滚版本链
mvcc机制 假设我这个事务读到的 lilei300 只要当前这个事务不提交 只要再读这个数据 数据是一致的,但是 有可能这条数据 已经让其他事务更改了
到底怎么实现的
数据库的数据 对应的是有一系列的undo回滚日志的记录的
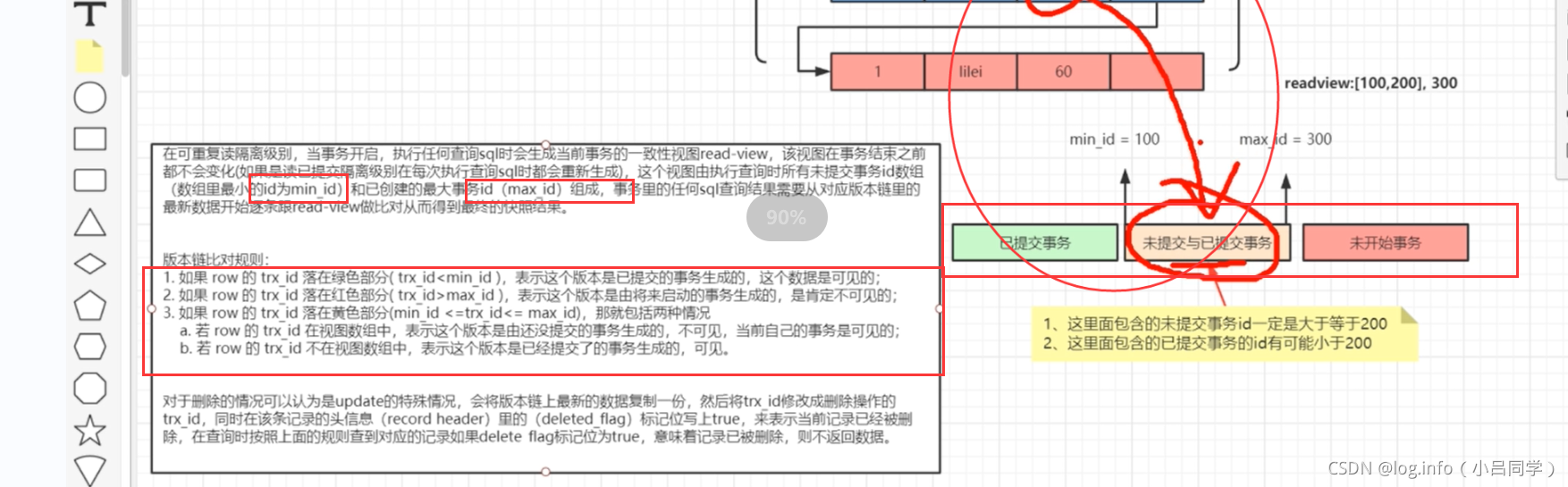
在可重复读隔离级别,当事务开启,执行任何查询sql时会生成当前事务的一致性视图read-view,[当前事务的一致性视图]--->[所有未提交的事务组成的一个数组,以及已创建的最大事务组成]
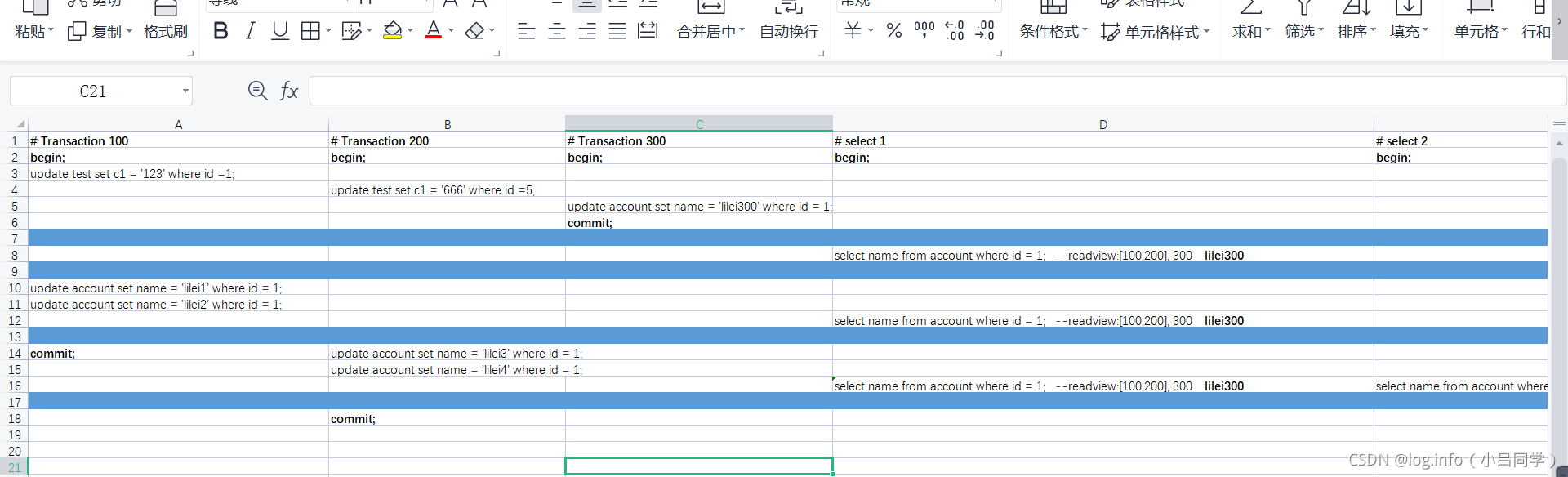
我此时begin 开启好几个客户端 我会在这几个客户端做几个操
作,操作的先后顺序 按照excel表格 的先后顺序
我们的事务开启他并不是事务真正的起点 真正的起点是当你执行第一条修改操作语句,比如说update insert delete 执行这样的语句的时候才会生成之后生成事务id .执行select 不会生成一个真正的事务Id
第一个事务开启
执行一条update 语句 事务id 生成了 100,
事务2 开启 事务id 也生成了 200,
事务3 开启 事务id为300 此时这个事务会commit

假设account表中 原始记录有一个记录 id=1 name为lilei ,在insert的时候
生成这个事务id为60的这条记录
当我们执行 update account set name ='lilei300' where id =1 把我们的呢个值修改了 300
此时我不管有没有commit,此时这个undo版本链的数据
实际上已经生成一个最新的[事务id 300]// 不管有没有提交
undo版本连的数据已经变成300了
又begin了一条 查询数据 select name from account where id =1
一个事务,只要执行一个查询sql语句 会对当前这个事务生成一个read-view
这个read-view 是所有未提交的事务组成的一个数组 以及整个数据库已创建的最大的事务id
[100,200--->还没有提交][300 当前的最大事务id]
此时当前这个session还没有执行更新语句 没有事务Id,当开启这个session的时候 read-view[100,200],300
查询完这个sql的时候 当前这个事务会生成一个read-view
呢么 当前这个事务有一个read-view了 name=lilei300是怎么计算出来的呢
当执行这个查询sql的时候
select name from account where id =1,他会从这个undo 日志版本链最新的记录开始去找,找我当前的事务 到底该去读那一条记录
他会把read-view和undolog表中的事务id做对比
mysql 根据read-view 会去做几个区间
mysql 会对于我们当前这个查询事务生成一个read-view 基于这个 read-view会把mysql的所有事务归结为3类[区间的设定]

比如说当前的readview 是[100,200] 300
小于最小的为已提交的事务,大于最大都是将来【未开始的事务】
在[100-300] 数据是未提交或已提交的事务
mysql 底层会根据你整个事务根据readview 帮你划分这3个区间[小于100 的已经提交了,大于300 的还未开始的 其他所有的事务 都是未提交的或者 已提交的]
然后会拿undo日志链上的事务id 去一个个比对看他会落在那个区间中
read-view [ 活跃的 未提交的数组的集合100,200][300 已提交的最大的事务id ]
他有个比对规则
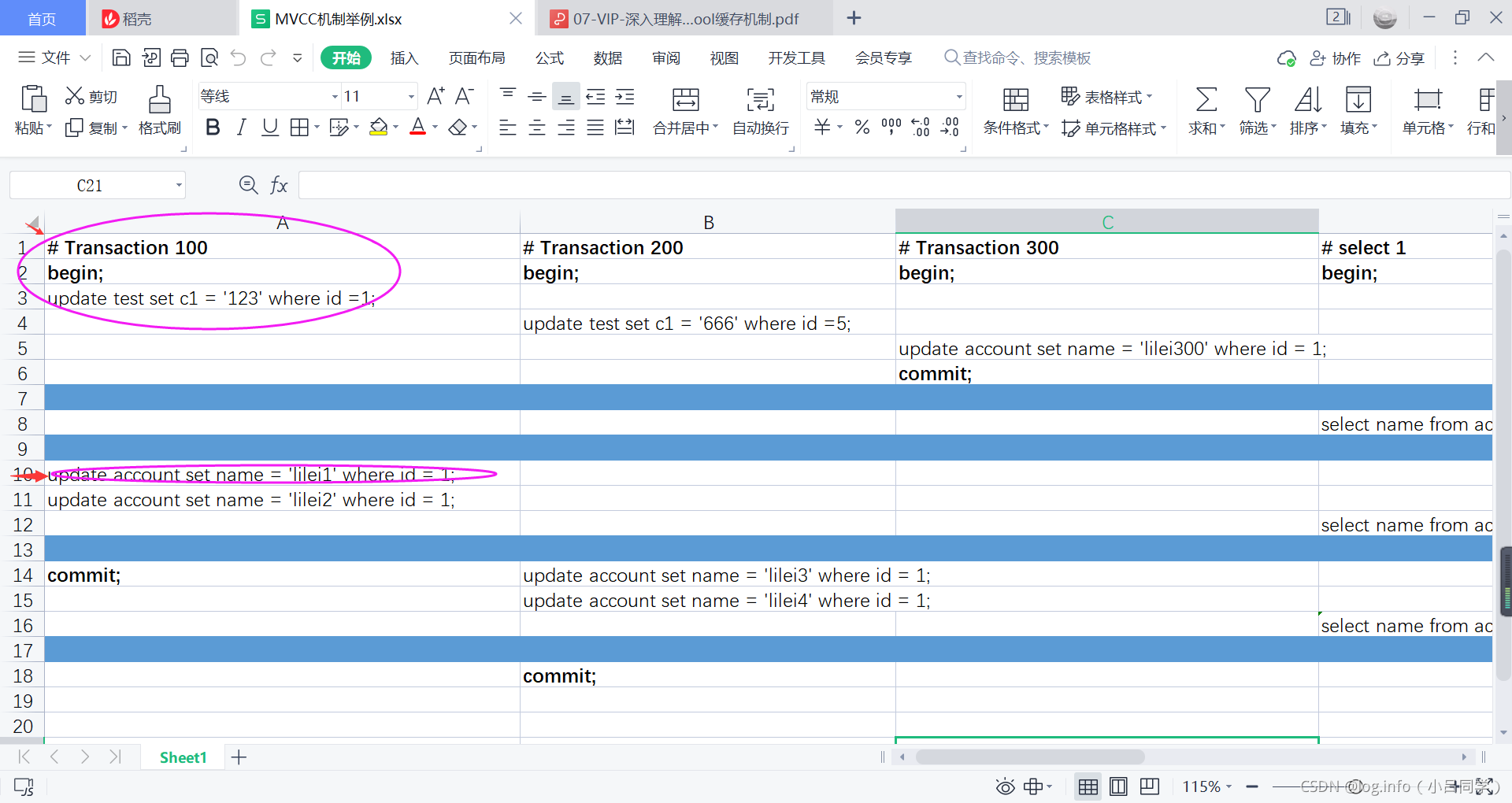
此时事务100 又执行update了 将name改了lilei2
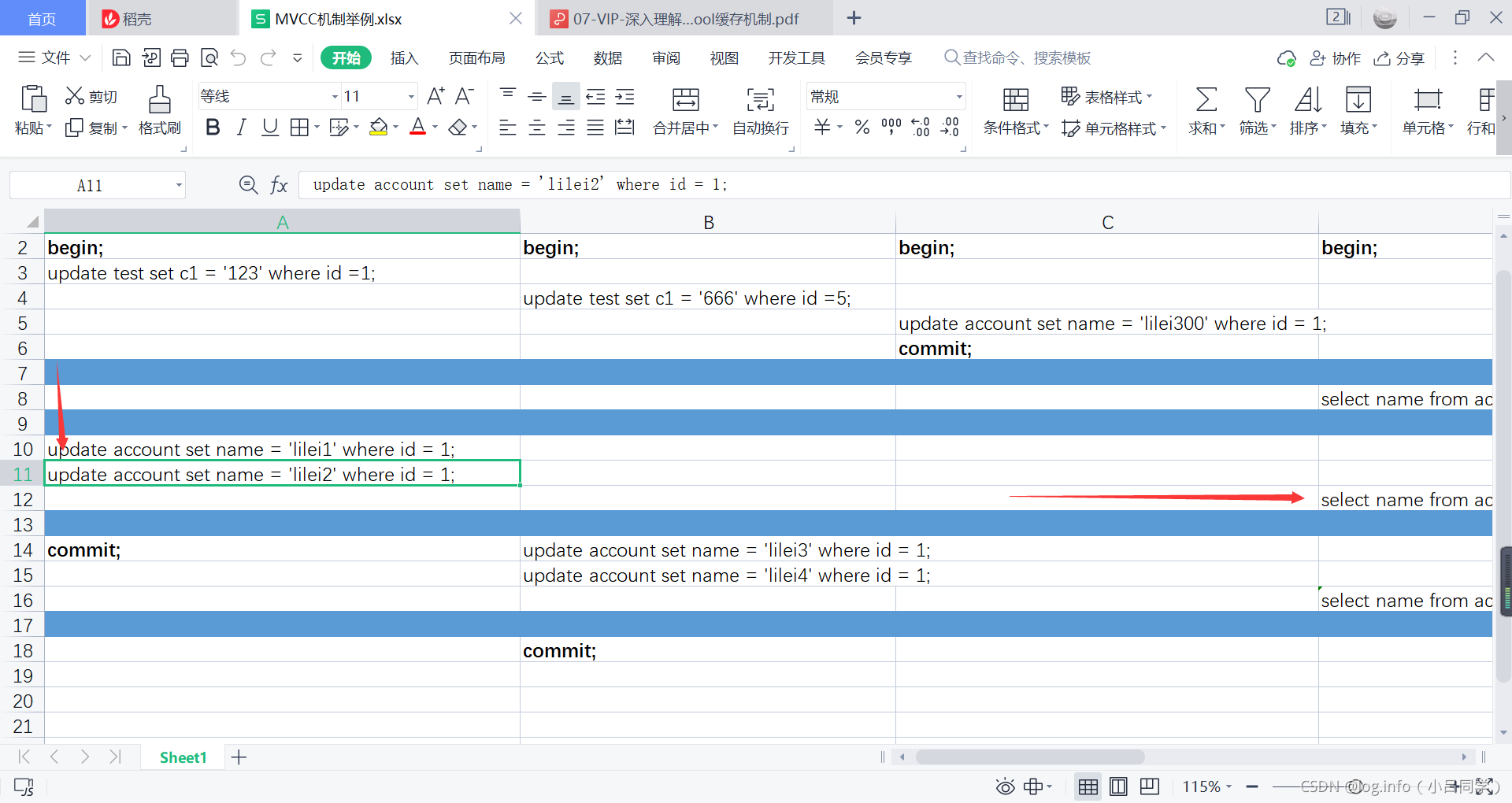
此时再执行查询的时候还是lilei 300,还是按照刚刚的版本链去比对.这条sql在查询的时候还会读readView [在同一个事务中read-view不变 也就是说还是 [活跃的未提交的数组的集合100,200][300 已提交的最大的事务id ]] 此时数据库中最新的版本链是lilei2了
我们此时继续根据这个比对规则从undo版本链路中看他能够读取那一条数据
发现还是lilei300可见
也就是说只要有更新他就会在这个undo版本链中去记录最新的事务id ,然后在可重读的时候当进行查询的时候 根据当前事务生成一个read-view
根据read-view和undo版本链的比对规则去比对看他读的是那一条数据
mvcc保证 只要这个事务没有结束 你第一次读到的是lilei300 你以后再去读的时候也是lilei300 [MVCC机制保证的隔离性]
mvcc 通过readview 和undo版本链去判断出来的
mvcc机制保证了 我们不加锁实现的隔离性 ,2个相同的查询sql 同一时刻开启事务 相同的sql 为什么结果不一样
因为查询时生成的readview不一样