文章目录
java集合类库详细解析
集合的概述(重点)
集合的由来
- 当需要在Java程序中记录单个数据内容时,则声明一个变量
- 当需要在Java程序中记录多个类型相同的数据内容时,声明一个一维数组
- 当需要在Java程序中记录多个类型不同的数据内容时,则创建一个对象
- 当需要在Java程序中记录多个类型相同的对象数据时,创建一个对象数组
- 当需要在Java程序中记录多个类型不同的对象数据时,则准备一个集合
集合的框架结构
- Java中集合框架顶层框架是:java.util.Collection集合 和 java.util.Map集合
- 其中Collection集合中存取元素的基本单位是:单个元素
- 其中Map集合中存取元素的基本单位是:单对元素
Collection集合(重点)
基本概念
- java.util.Collection接口是List接口、Queue 接口以及Set接口的父接口,因此该接口里定义的方法 既可用于操作List集合,也可用于操作Queue集合和Set集合。
集合框架

常用的方法(练熟、记住)
| 方法声明 | 功能介绍 |
|---|---|
| boolean add(E e); | 向集合中添加对象 |
| boolean addAll(Collection<? extends E > c) | 用于将参数指定集合c中的所有元素添加到当前集合 中 |
| boolean contains(Object o); | 判断是否包含指定对象 |
| boolean containsAll(Collection<?> c) | 判断是否包含参数指定的所有对象 |
| boolean retainAll(Collection<?> c) | 保留当前集合中存在且参数集合中存在的所有对象 |
| boolean remove(Object o); | 从集合中删除对象 |
| boolean removeAll(Collection<?> c) | 从集合中删除参数指定的所有对象 |
| void clear(); | 清空集合 |
| int size(); | 返回包含对象的个数 |
| boolean isEmpty(); | 判断是否为空 |
| boolean equals(Object o) | 判断是否相等 |
| int hashCode() | 获取当前集合的哈希码值 |
| Iterator iterator() | 获取当前集合的迭代器 |
| Object[] toArray() | 将集合转换为数组 |
-
方法的使用
-
创建Collection对象 并打印
/ 1.创建Collection 对象 // Collection c = new Collection(); // Collection是抽象类不能实例化对象 // 接口类型的引用指向实现类对象形成多态 Collection c = new ArrayList(); // 默认打印格式是 [元素1, 元素2, ....] System.out.println("集合中的元素有:" + c); // [] -
往创建的Collection对象中逐个添加元素
// 2.向集合中添加元素 并打印 boolean flag = c.add(new String("张三")); System.out.println(flag); // true System.out.println(c); //[张三] flag = c.add(Integer.valueOf(20)); System.out.println(flag); // true System.out.println(c); // [张三, 20] flag = c.add(new Student(1001, "李四")); System.out.println(flag); // true System.out.println(c); // [张三, 20, Student{id=1001, name='李四'}] -
往创建的Collection对象中添加对个元素
Collection c1 = new ArrayList(); c1.add("张三"); // 常量池 c1.add("4"); // 自动装箱技术 System.out.println("集合中的元素有" + c1); // [张三, 4] flag = c.addAll(c1); // 有打印结果可知相当于追加 System.out.println(flag); System.out.println(c); // [张三, 20, Student{id=1001, name='李四'}, 张三, 4]注意 add(c1) 和 addAll(c1) 的区别
- add(c1) 是把c1当做整体添加到集合中 --> 打印结果是 [张三, 20, Student{id=1001, name=‘李四’}, [张三, 4]]
- addAll(c1) 是把c1中的元素逐个添加到集合中 --> 打印结果是 [张三, 20, Student{id=1001, name=‘李四’}, 张三, 4]
-
判断集合中是否包含指定的单个元素
// 4.判断集合中是否包含指定的单个元素 System.out.println(c); flag = c.contains("张三"); // true System.out.println(flag); flag = c.contains(3); // false System.out.println(flag); flag = c.contains(4); // true System.out.println(flag); // contains方法的工作原理是:Objects.equals(o, e),其中o代表contains方法的形式参数,e代表集合中的每个元素 // 也就是contains的工作原理就是 拿着参数对象与集合中已有的元素依次进行比较,比较的方式调用Objects中的equals方法 // 而该方法equals的工作原理如下: /* public static boolean equals(Object a, Object b) { 其中a代表Person对象,b代表集合中已有的对象 return (a == b) || (a != null && a.equals(b)); 元素包含的第一种方式就是:Person对象与集合中已有对象的地址相同 第二种方式就是:Person对象不为空,则Person对象调用equals方法与集合中已有元素相等 } */ // 当Student类中没有重写equals方法时,则调用从Object类中继承下来的equals方法,比较两个对象的地址 false // 当Student类中重写equals方法后,则调用重写以后的版本,比较两个对象的内容 true flag = c.contains(new Student(1001, "李四")); // false 重写之后返回 true System.out.println(flag);-
注意
自定义类放入Collection中调用contains()方法需要在自定义类中重写equals 和 hashCode 方法 原理在上面
-
-
判断当前集合中是否包含指定集合的所有元素
// 5.判断当前集合中是否包含指定集合的所有元素 Collection c2 = new ArrayList(); c2.add("张三"); c2.add(4); // 注意 注意集合c中包含所有c2的元素时 才返回true 否则返回 false flag = c.containsAll(c2); // true -
判断当前集合中是否包含指定集合的所有元素
// 5.判断当前集合中是否包含指定集合的所有元素 Collection c2 = new ArrayList(); c2.add("张三"); c2.add(4); // 注意 注意集合c中包含所有c2的元素时 才返回true 否则返回 false flag = c.containsAll(c2); // true System.out.println(c2); System.out.println(c); System.out.println(flag); -
计算两个集合的交集
// 6.计算两个集合的交集 flag = c2.retainAll(c2); // false 表示当前集合没有发生改变 [张三, 4] // 计算集合c 和c2 的交集并保存到c2中 取代c2中原先的数值 // c中的额集合是 [张三, 张三, 4] c2的集合是 [张三, 4] 返回值是 true flag = c.retainAll(c2); -
实现集合中单个元素和所有元素的删除
// 7.实现集合中单个元素和所有元素的删除 // 删除单个元素 flag = c.remove(1); // c1中的元素有 [张三, 张三, 4] 所以返回 false flag = c.remove("张三"); // [张三, 4] 有多个相同的元素 只删除一个 // 删除多个元素 flag = c.removeAll(c2); // [张三, 4] c和c2均为 执行之后为 [] -
实现集合和数组类型之间的转换 通常认为:集合是用于取代数组的结构
// 10.实现集合和数组类型之间的转换 通常认为:集合是用于取代数组的结构 // 实现集合向数组类型的转换 Object[] objects = c2.toArray(); // [张三, 4] // 打印数组中的所有元素 System.out.println("数组中的元素有:" + Arrays.toString(objects)); // [张三, 4] // 实现数组类型到集合类型的转换 Collection objects1 = Arrays.asList(objects); // [张三, 4]
-
Iterator接口(重点)
基本概念
- java.util.Iterator接口主要用于描述迭代器对象,可以遍历Collection集合中的所有元素
- java.util.Collection接口继承Iterator接口,因此所有实现Collection接口的实现类都可以使用该迭 代器对象
常用的方法
| 方法声明 | 功能介绍 |
|---|---|
| boolean hasNext() | 判断集合中是否有可以迭代/访问的元素 |
| E next() | 用于取出一个元素并指向下一个元素 |
| void remove() | 用于删除访问到的最后一个元素 |
-
方法使用
-
使用迭代器的方式遍历集合 [张三, 4, 李四]
// 1.声明一个集合对象 Collection cs = new ArrayList(); cs.add("张三"); cs.add(4); cs.add("李四"); System.out.println(cs); // 获取迭代器对象 Iterator iterator = cs.iterator(); // cs 中的集合元素 [张三, 4, 李四] while (iterator.hasNext()){ System.out.println(iterator.next()); } -
使用迭代器删除集合中的张三
// 使用迭代器删除里面的元素 张三 // 由于迭代器重置 iterator = cs.iterator(); while (iterator.hasNext()){ Object obj = iterator.next(); if ("张三".equals(obj)){ iterator.remove(); // 使用迭代器的remove方法没有问题 // 使用集合的remove方法编译ok 云像是发生ConcurrentModificationException 并发修改异常 // cs.remove(obj); } } System.out.println(cs); // [4, 李四]
-
-
案例题目:
如何使用迭代器实现toString方法的打印效果?
// 使用迭代器实现toSting的打印集合中的元素 StringBuilder sb = new StringBuilder(); iterator = cs.iterator(); sb.append("["); while (iterator.hasNext()){ Object obj = iterator.next(); // 当获取到后一个元素时 加 ] if (!iterator.hasNext()) sb.append(obj).append("]"); // 否则拼接元素 逗号加空格 else sb.append(obj).append(",").append(" "); } System.out.println(sb); // [4, 李四]
for each循环(重点)
基本概念
- Java5推出了增强型for循环语句,可以应用数组和集合的遍历
- 是经典迭代的“简化版”
语法格式
for(元素类型 变量名 : 数组/集合名称) {
循环体;
}
-
使用for each 替代迭代器
for (Object obj : cs){ // cs集合内的元素时 [4, 李四] System.out.println(obj); }
执行流程
- 不断地从数组/集合中取出一个元素赋值给变量名并执行循环体,直到取完所有元素为止
List集合(重中之重)
基本概念
-
java.util.List集合是Collection集合的子集合,该集合中允许有重复的元素并且有先后放入次序。
-
该集合的主要实现类有:ArrayList类、LinkedList类、Stack类、Vector类
-
其中ArrayList类的底层是采用动态数组进行数据管理的,支持下标访问,增删元素不方便。
// 1.声明一个List接口类型的引用指向ArrayList类型的对象,形成了多态 // 由源码可知:当new对象时并没有申请数组的内存空间 List lt1 = new ArrayList(); // 2.向集合中添加元素并打印 // 由源码可知:当调用add方法添加元素时会给数组申请长度为10的一维数组,扩容原理是:原始长度的1.5倍 lt1.add("one"); System.out.println("lt1 = " + lt1); // [one] -
其中LinkedList类的底层是采用双向链表进行数据管理的,访问不方便,增删元素方便。
-
可以认为ArrayList和LinkedList的方法在逻辑上完全一样,只是在性能上有一定的差别,ArrayList 更适合于随机访问而LinkedList更适合于插入和删除;在性能要求不是特别苛刻的情形下可以忽略这个差别。
-
其中Stack类的底层是采用动态数组进行数据管理的,该类主要用于描述一种具有后进先出特征的 数据结构,叫做栈(last in first out LIFO)。
-
其中Vector类的底层是采用动态数组进行数据管理的,该类与ArrayList类相比属于线程安全的 类,效率比较低,以后开发中基本不用。扩大2倍
常用的方法
| 方法声明 | 功能介绍 |
|---|---|
| void add(int index, E element) | 向集合中指定位置添加元素 |
| boolean addAll(int index, Collection<? extends E> c) | 向集合中添加所有元素 |
| E get(int index) | 从集合中获取指定位置元素 |
| int indexOf(Object o) | 查找参数指定的对象 |
| int lastIndexOf(Object o) | 反向查找参数指定的对象 |
| E set(int index, E element) | 修改指定位置的元素 |
| E remove(int index) | 删除指定位置的元素 |
| List subList(int fromIndex, int toIndex) | 用于获取子List |
-
方法使用
-
向集合List中添加元素首位置 末尾位置 中间位置
// 1.准备一个List集合 List l = new ArrayList(); // 分别向集合 l 中 首位置 末位位置 中间位置添加元素 "张三” “李四” 5 l.add(0,"张三"); // [张三] // l.add(3,"5"); 编译过 运行异常 IndexOutOfBoundsException 索引越界异常 l.add(4); // [张三, 4] 如果改变集合顺序可以省略 下标 l.add(1,"李四"); // [张三, 李四, 4] -
获取指定的元素值
// 2.根据索引值获取指定元素 l 中的元素是 [张三, 李四, 4] // 注意 get的返回值是Object类型 是String类的父类 所以需要向上转型 需要用 instanceof 判断 此处省略 String str = (String) l.get(1); // 李四 // 注意 获取元素时进行向上转型时一定要慎重 因为容易发生类型转换异常 // String str1 = (String) l.get(2); // 编译通过 运行发生 ClassCastException 类型转换异常 -
使用get方法取集合中的所有元素并按照 [张三, 李四, 4] 格式打印
// 3.使用get方法取集合中的所有元素并按照 [张三, 李四, 4] 格式打印 StringBuilder builder = new StringBuilder(); builder.append("["); for (int i = 0; i < l.size(); i++){ Object o = l.get(i); if(i == l.size() -1){ builder.append(o).append("]"); }else { builder.append(o).append(", "); } } System.out.println(builder); -
查找指定元素出现的索引位置
// 4.查找指定元素出现的索引位置 [张三, 李四, 4] System.out.println("张三第一次出现的做引位置是 " + l.indexOf("张三")); // 0 l.add("张三"); System.out.println("张三 反向出现的索引位置是 " + l.lastIndexOf("张三")); // 3 -
修改集合中的指定位置元素
// 5.修改集合的指定位置元素 [张三, 李四, 王五, 张三] Integer i = (Integer) l.set(2, "王五"); // 返回值是被修改元素的值 4 修改后的元素是: [张三, 李四, 王五, 张三] -
删除集合中的所有元素使用remove方法
// 6.删除集合中的所有元素使用remove方法 // 执行结果错误 因为使用remove方法删除元素是 size的值在变化 // for (int j = 1; j < l.size(); /*j++*/){ // 解决方案一 for (int j = l.size() -1; j >= 0; j--){ // 解决方案二 System.out.println("被删除的元素是: " + l.remove(0)); } while (l.size() != 0){ // 解决方案三 System.out.println("被删除的元素是: " + l.remove(0)); } -
获取当前集合的子集合
// 7.获取当前集合的子集合 也就是将集合中的一部分取出来 子集合和当前集合共用一块内存地址 // 获取当前集合l中下标从1开始 到 3但不包括3 List l2 = l.subList(1, 3); // [李四, 王五]
-
-
案例题目
-
准备一个Stack集合,将数据11、22、33、44、55依次入栈并打印,然后查看栈顶元素并打印, 然后将栈中所有数据依次出栈并打印。
// 1.准备一个Stack类型的对象并打印 Stack s1 = new Stack(); // 2.将数据11、22、33、44、55依次入栈并打印 for (int i = 1; i <= 5; i++) { Object obj = s1.push(i * 11); } // 3.查看栈顶元素值并打印 Object obj2 = s1.peek(); // 55 // 4.对栈中所有元素依次出栈并打印 int len = s1.size(); for (int i = 1; i <= len; i++) { System.out.println("出栈的元素是:" + s1.pop();); // 55 44 33 22 11 }
-
Queue集合(重点)
基本概念
- java.util.Queue集合是Collection集合的子集合,与List集合属于平级关系。
- 该集合的主要用于描述具有先进先出特征的数据结构,叫做队列(first in first out FIFO)。
- 该集合的主要实现类是LinkedList类,因为该类在增删方面比较有优势。
常用的方法
| 方法声明 | 功能介绍 |
|---|---|
| boolean offer(E e) | 将一个对象添加至队尾,若添加成功则返回true |
| E poll() | 从队首删除并返回一个元素 |
| E peek() | 返回队首的元素(但并不删除) |
-
案例题目
准备一个Queue集合,将数据11、22、33、44、55依次入队并打印,然后查看队首元素并打印, 然后将队列中所有数据依次出队并打印。
// 1.准备一个Queue集合并打印 Queue queue = new LinkedList(); // 2.将数据11、22、33、44、55依次入队并打印 for (int i = 1; i <= 5; i++) { boolean b1 = queue.offer(i * 11); } // 3.然后查看队首元素并打印 System.out.println("对首元素是:" + queue.peek()); // 11 // 4.然后将队列中所有数据依次出队并打印 int len = queue.size(); for (int i = 1; i <= len; i++) { System.out.println("出队的元出队的元素是:" + queue.poll()); // 11 22 33 44 55 }
泛型机制(熟悉)
基本概念
-
通常情况下集合中可以存放不同类型的对象,是因为将所有对象都看做Object类型放入的,因此 从集合中取出元素时也是Object类型,为了表达该元素真实的数据类型,则需要强制类型转换, 而强制类型转换可能会引发类型转换异常。
-
为了避免上述错误的发生,从Java5开始增加泛型机制,也就是在集合名称的右侧使用<数据类型> 的方式来明确要求该集合中可以存放的元素类型,若放入其它类型的元素则编译报错。
-
泛型只在编译时期有效,在运行时期不区分是什么类型。
-
泛型代码演示
// 1.准备一个支持泛型机制的List集合,明确要求集合中的元素是String类型 List<String> lt1 = new LinkedList<String>(); // 2.向集合中添加元素并打印 lt1.add("one"); //lt1.add(2); Error // 3.获取集合中的元素并打印 String s = lt1.get(0); System.out.println("获取到的元素是:" + s); // one泛型简写
// Java7开始的新特性: 菱形特性 就是后面<>中的数据类型可以省略 List<Double> lt3 = new LinkedList<>();泛型笔试考点
// 试图将lt1的数值赋值给lt3,也就是覆盖lt3中原来的数值,结果编译报错:集合中支持的类型不同 //lt3 = lt1; Error
底层原理
-
泛型的本质就是参数化类型,也就是让数据类型作为参数传递,其中E相当于形式参数负责占位, 而使用集合时<>中的数据类型相当于实际参数,用于给形式参数E进行初始化,从而使得集合中所 有的E被实际参数替换,由于实际参数可以传递各种各样广泛的数据类型,因此得名为泛型。
-
如:
//其中i叫做形式参数,负责占位 其中E叫做形式参数,负责占位
//int i = 10; E = String;
//int i = 20; E = Integer;
public static void show(int i) { public interface List {
… …
} }
//其中10叫做实际参数,负责给形式参数初始化 // 其中String叫做实际参数
show(10); List lt1 = …;
show(20); List lt2 = …;
自定义泛型接口
- 泛型接口和普通接口的区别就是后面添加了类型参数列表,可以有多个类型参数,如:<E, T, … > 等。
自定义泛型类
-
泛型类和普通类的区别就是类名后面添加了类型参数列表,可以有多个类型参数,如:<E, T, … > 等。
-
实例化泛型类时应该指定具体的数据类型,并且是引用数据类型而不是基本数据类型。
-
自定义泛型类代码演示
public class Student<T> { private int id; private String name; private T gender; public Student() { } public Student(int id, String name, T gender) { this.id = id; this.name = name; this.gender = gender; } ..... public T getGender() { return gender; } public void setGender(T gender) { this.gender = gender; } } -
自定义泛型类的使用
// 1.声明一个Student类型的引用指向Student类 Student st = new Student(1001, "张三", "男"); // 未指定泛型类型 默认为 Object 类型 所用值均能传入 Student<Integer> st1 = new Student<>(1002,"李四", 1); // 指定泛型类型为 Integer类型 只能传入 Integer类型 // st1 = new Student<Integer>(1003,"李四", "男"); // 编译报错 因为类型不匹配
-
-
父类有泛型,子类可以选择保留泛型也可以选择指定泛型类型。
-
代码实现
public class SubStudent<T> extends Student<T>{ // 保留父类的泛型 可以在构造对象的时来指定T的类型 } -
创建对象
// 3.保留父类的泛型 可以在构造对象的时来指定T的类型 SubStudent<String> student = new SubStudent<>(); student.setGender("男"); // Student{id=0, name='null', gender=男}
-
-
子类必须是“富二代”,子类除了指定或保留父类的泛型,还可以增加自己的泛型。
-
代码实现
public class SubStudent<T, T1> extends Student<T>{ // 保留父类的泛型,同时在子类中增加新的泛型 } -
创建对象
// 4.保留父类的泛型,同时在子类中增加新的泛型 SubStudent<String,Integer> student = new SubStudent(); student.setGender("男"); // Student{id=0, name='null', gender=男}
-
-
不保留泛型并且没有指定类型
-
代码实现
public class SubStudent extends Student{ // 不保留泛型并且没有指定类型 此时Student 类中默认为 Object类型 专业术语 擦除 } -
创建对象
// 1.声明一个没有指定泛型类型的SubStudent类 自动生成为 Object 类型 SubStudent student = new SubStudent(); student.setGender("男"); // {id=0, name='null', gender=男}
-
-
保留泛型但指定了泛型的类型
-
代码实现
public class SubStudent extends Student<Integer>{ // 不保留泛型但指定了泛型的类型 此时的 Student类中的 T 被指定为 Integer 类型 } -
创建对象
// 2.声明不保留泛型 但父类指定泛型 // 指定父类中的泛型子类可以省略 默认继承父类指定的额泛型 SubStudent student = new SubStudent(); // student.getGender("男"); 与指定的类型不匹配 编译报错 student.setGender(1); // Student{id=0, name='null', gender=1}
-
自定义泛型方法
-
泛型方法就是我们输入参数的时候,输入的是泛型参数,而不是具体的参数。我们在调用这个泛型 方法的时需要对泛型参数进行实例化。
-
泛型方法的格式:
[访问权限] <泛型> 返回值类型 方法名([泛型标识 参数名称]) { 方法体; }-
代码演示
// 自定义泛型方法 实现数组的打印 public <T1> void show(T1[] arr){ for (T1 t1 : arr) { System.out.println(arr); } } -
方法的调用
Integer[] arr = { 11, 22, 33, 44, 55}; st1.show(arr);
-
-
在静态方法中使用泛型参数的时候,需要我们把静态方法定义为泛型方法。
-
代码演示
// 自定义泛型方法 实现数组的打印 public static <T1> void show(T1[] arr){ // 这个是泛型方法 所以可以加Static关键字 for (T1 t1 : arr) { System.out.println(t1); } } // 不是泛型方法,该方法不能使用static关键字修饰,因为该方法中的T需要在new对象时才能明确类型 public T getGender(int i) { return gender; }
-
泛型在继承上的体现
-
如果B是A的一个子类或子接口,而G是具有泛型声明的类或接口,则G并不是G的子类型!
比如:String是Object的子类,但是List并不是List的子类。
通配符的使用
-
有时候我们希望传入的类型在一个指定的范围内,此时就可以使用泛型通配符了。
-
如:之前传入的类型要求为Integer类型,但是后来业务需要Integer的父类Number类也可以传 入。
-
泛型中有三种通配符形式:
<?> // 无限制通配符:表示我们可以传入任意类型的参数。 <? extends E> // 表示类型的上界是E,只能是E或者是E的子类。 <? super E> // 表示类型的下界是E,只能是E或者是E的父类。- ?通配符的使用 Dog 是 Animal的子类
// 1.声明两个集合进行测试 List<Animal> lt1 = new LinkedList<>(); List<Dog> lt2 = new LinkedList<>(); // 2.将lt1的数值赋值与lt2 也就是List<Animal> 类型向 List<Dag> 类型的转换 // lt1 = lt2 // Error 类型之间不具备父子类关系 // 3.使用通配符作为公共父类 List<?> lt3 = new LinkedList<>(); lt3 = lt1; // 可以发生List<Animal> 类型到 List<?> 之间的转换 lt3 = lt2; // 可以发生List<Dog> 类型到 List<?> 之间的转换 // 4.向公共类中添加元素和获取元素 // lt3.add(new Animal()) // Error 不能存放Animal类型的对象 因为 ? 可以代表任意类型的数据 如果代表比Animal更小的子类 会出现异常 // lt3.add(new Dog()) // rror 不能存放Dog类型的对象 不支持元素的添加操作 Object o = lt3.get(0); // OK 支持元素的获取操作 全部当做Object类型处理 }- <? extends E> 通配符的使用
// 3.使用有限制的通配符进行使用 List<? extends Animal> lt4 = new LinkedList<>(); // 不支持元素的添加操作 //lt4.add(new Animal()); //lt4.add(new Dog()); //lt4.add(new Object()); // 获取元素 Animal animal = lt4.get(0); - <? super E> 通配符的使用
List<? super Animal> lt5 = new LinkedList<>(); lt5.add(new Animal()); lt5.add(new Dog()); //lt5.add(new Object()); Error: 超过了Animal类型的范围 Object object = lt5.get(0);
Set集合(熟悉)
基本概念
-
java.util.Set集合是Collection集合的子集合,与List集合平级。
-
该集合中元素没有先后放入次序,且不允许重复。 (去重)
-
该集合的主要实现类是:HashSet类 和 TreeSet类以及LinkedHashSet类。
-
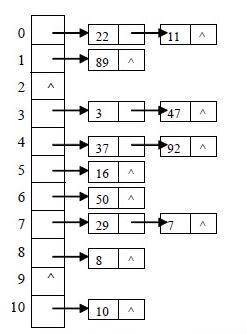
其中HashSet类的底层是采用哈希表进行数据管理的。
-
其中TreeSet类的底层是采用红黑树进行数据管理的。

- 其中LinkedHashSet类与HashSet类的不同之处在于内部维护了一个双向链表,链表中记录了元 素的迭代顺序,也就是元素插入集合中的先后顺序,因此便于迭代。
常用的方法
-
参考Collection集合中的方法即可!
-
案例题目
准备一个Set集合指向HashSet对象,向该集合中添加元素"two"并打印,再向集合中添加元 素"one"并打印,再向集合中添加元素"three"并打印,再向集合中添加"one"并打印。
// 1.声明一个Set对象 指向HashSet集合 指定泛型为 String类型 // Set<String> s = new HashSet<>(); Set<String> s = new LinkedHashSet<>(); // 将放入的元素使用双链表连接起来 有先有后顺序 // 2.往集合中依次添加元素 one two three one s.add("two"); // [two] s.add("one"); // [one, two] 没有后放入次序 LinkedHashSet之后是 [two, one] s.add("three"); // [one, two, three] LinkedHashSet之后是 [two, one, three] s.add("one"); // [one, two, three] 不允许防重复元素 LinkedHashSet之后是 [two, one, three] // 2.打印Set集合中的对象 System.out.println(s); // [one, two, three] LinkedHashSet之后是 [two, one, three]
元素放入HashSet集合的原理
- 使用元素调用hashCode方法获取对应的哈希码值,再由某种哈希算法计算出该元素在数组中的索 引位置。
- 若该位置没有元素,则将该元素直接放入即可。
- 若该位置有元素,则使用新元素与已有元素依次比较哈希值,若哈希值不相同,则将该元素直接放入。
- 若新元素与已有元素的哈希值相同,则使用新元素调用equals方法与已有元素依次比较。
- 若相等则添加元素失败,否则将元素直接放入即可。
- 思考:为什么要求重写equals方法后要重写hashCode方法呢?
- 解析:当两个元素调用equals方法相等时证明这两个元素相同,重写hashCode方法后保证这两个元 素得到的哈希码值相同,由同一个哈希算法生成的索引位置相同,此时只需要与该索引位置已有元 素比较即可,从而提高效率并避免重复元素的出现。
TreeSet集合的概念
- 二叉树主要指每个节点最多只有两个子节点的树形结构。
- 满足以下3个特征的二叉树叫做有序二叉树。
- 左子树中的任意节点元素都小于根节点元素值;
- 右子树中的任意节点元素都大于根节点元素值;
- 左子树和右子树的内部也遵守上述规则;
- 由于TreeSet集合的底层采用红黑树进行数据的管理,当有新元素插入到TreeSet集合时,需要使 用新元素与集合中已有的元素依次比较来确定新元素的合理位置。
- 比较元素大小的规则有两种方式:
-
使用元素的自然排序规则进行比较并排序,让元素类型实现java.lang.Comparable接口;
-
代码实现
public class Students implements Comparable<Students>{ private String name; private int age; .... @Override public String toString() { return "Students{" + "name='" + name + '\'' + ", age=" + age + '}'; } @Override public int compareTo(Students o) { // return 0; // 表示相等 添加元素认为形同 第一种 // return -1; // 调用对象小于参数对象 第二种 // return 1; // 调用对象大于参数对象 第三种 // return this.getName().compareTo(o.getName()); 第四种 // 当名字相同时 比较年龄 第五种 int ia = this.getName().compareTo(o.getName()); return ia == 0 ? this.getAge() - o.getAge() : ia; } } -
调用及结果显示
// 准备一个TreeSet集合 并放入Person类型的队形并打印 Set<Students> s1 = new TreeSet<>(); s1.add(new Students("zhangsan",20)); s1.add(new Students("lisi", 22)); s1.add(new Students("wangwu",21)); // 第一种 return 0 时 // System.out.println(s1); 返回 [Students{name='zhangsan', age=20}] // 第二种 return -1 时 // System.out.println(s1); // 返回[Students{name='wangwu', age=21}, Students{name='lisi', age=22}, Students{name='zhangsan', age=20}] // 第三种 return 1 时 // System.out.println(s1); // 返回 [Students{name='zhangsan', age=20}, Students{name='lisi', age=22}, Students{name='wangwu', age=21}] // 第四种 return this.getName().compareTo(o.getName()) 时 // System.out.println(s1); // 返回[Students{name='lisi', age=22}, Students{name='wangwu', age=21}, Students{name='zhangsan', age=20}] s1.add(new Students("lisi", 25)); // 第五种 名字相同时 比较年龄 // System.out.println(s1); // 返回 [Students{name='lisi', age=22}, Students{name='lisi', age=25}, Students{name='wangwu', age=21}, Students{name='zhangsan', age=20}] }
-
-
使用比较器规则进行比较并排序,构造TreeSet集合时传入java.util.Comparator接口;
-
匿名颞部类实现Comparator接口
// 准备一个比较器对象 作为参数传递传递给构造方法 // 1.匿名颞部类 Comparator<Students> comparator = new Comparator<Students>() { @Override public int compare(Students o1, Students o2) { // o1表示新增加的对象 o2表示集合中已有的对象 return o1.getAge() - o2.getAge(); // 表示按年龄比较 } }; Set<Students> s1 = new TreeSet<>(comparator); -
lambda表达式
// java8 开始可以支持lamada表达式 匿名内部类都可以用lamada表达式来简化代码 lamada表达式的语法格式是 (参数列表) -> {方法体} Comparator<Students> comparator = (Students o1, Students o2) -> { return o1.getAge() - o2.getAge();}; Set<Students> s1 = new TreeSet<>(comparator);
-
-
- 自然排序的规则比较单一,而比较器的规则比较多元化,而且比较器优先于自然排序;
Map集合(重点)
基本概念
-
java.util.Map<K,V>集合中存取元素的基本单位是:单对元素,其中类型参数如下:
K - 此映射所维护的键(Key)的类型,相当于目录。
V - 映射值(Value)的类型,相当于内容。
-
该集合中key是不允许重复的,而且一个key只能对应一个value。
-
该集合的主要实现类有:HashMap类、TreeMap类、LinkedHashMap类、Hashtable类、 Properties类。
-
其中HashMap类的底层是采用哈希表进行数据管理的。
-
其中TreeMap类的底层是采用红黑树进行数据管理的。
-
其中LinkedHashMap类与HashMap类的不同之处在于内部维护了一个双向链表,链表中记录了 元素的迭代顺序,也就是元素插入集合中的先后顺序,因此便于迭代。
-
其中Hashtable类是古老的Map实现类,与HashMap类相比属于线程安全的类,且不允许null作 为key或者value的数值。
-
其中Properties类是Hashtable类的子类,该对象用于处理属性文件,key和value都是String类 型的。
-
Map集合是面向查询优化的数据结构, 在大数据量情况下有着优良的查询性能。
-
经常用于根据key检索value的业务场景。
常用的方法
| 方法声明 | 功能介绍 |
|---|---|
| V put(K key, V value) | 将Key-Value对存入Map,若集合中已经包含该Key,则替换该Key所对 应的Value,返回值为该Key原来所对应的Value,若没有则返回null |
| V get(Object key) | 返回与参数Key所对应的Value对象,如果不存在则返回null |
| boolean containsKey (Object value); | 判断集合中是否包含指定的Key |
| boolean containsValue (Object value); | 判断集合中是否包含指定的Value |
| V remove(Object key) | 根据参数指定的key进行删除 |
| Set keySet() | 返回此映射中包含的键的Set视图 |
| Collection values() | 返回此映射中包含的值的Set视图 |
| Set<<Map.Entry<K,V>> entrySet() | 返回此映射中包含的映射的Set视图 |
-
准备一个Map集合并打印
// 1.准备一个Map集合并打印 Map<String,String> map = new HashMap<>(); // 自动调用toString方法 默认打印格式是:{key1=value1, key2=value2, ....} System.out.println("map = " + map); // {} -
向集合中添加元素
// 2.向集合中添加元素 String s = map.put("1", "one"); // s = null map = {1=one} s = map.put("2", "two"); // s = null map = {1=one, 2=two} s = map.put("3", "three"); // s = null map = {1=one, 2=two, 3=three} -
添加实现Map修改功能
// 3.添加实现Map修改功能 s = map.put("1","seven"); // s = 1 map = {1=seven, 2=two, 3=three} -
集合Map中的查找功能
// 4.实现集合中的查找功能 // 4.1 查找key值是否存在 存在true 否则false boolean b = map.containsKey("11"); // b = false b = map.containsKey("1"); // true // 4.2 查找value值是否存在 存在true 否则false b = map.containsValue("one"); // b = false b = map.containsValue("seven"); // b = true // 4.3 根据key获取元素的value值 String s1 = map.get("5"); // s1 = null s1 = map.get("1"); // s1 = seven -
集合Map中删除元素
// 5.实现根据key值来删除value String s2 = map.remove("5"); // null s2 = map.remove("1"); // s2 = seven -
Map集合的三种遍历方式
// 6.Map集合的遍历 // 6.1 Map集合遍历所有key的并打印 Set<String> strings = map.keySet(); StringBuilder sb = new StringBuilder(); sb.append("Map 中所有的key是: "); for (String string : strings) { sb.append(string + " "); } System.out.println(sb); // Map 中所有的key是: 2 3 // 6.2Map集合遍历所有的value并打印 Collection<String> values = map.values(); StringBuilder sb1 = new StringBuilder(); sb1.append("Map 中所有的value是: "); for (String value : values) { sb1.append(value + " "); } System.out.println(sb1); // Map 中所有的value是: two three // 6.3Map集合遍历所有的键值对并打印 Set<Map.Entry<String, String>> entries = map.entrySet(); StringBuilder sb2 = new StringBuilder(); sb2.append("Map 中所有的键值对是: "); for (Map.Entry<String, String> entry : entries) { sb2.append(entry + " "); } System.out.println(sb2); // Map 中所有的键值对是: 2=two 3=three
元素放入HashMap集合的原理
- 使用元素的key调用hashCode方法获取对应的哈希码值,再由某种哈希算法计算在数组中的索引位置。
- 若该位置没有元素,则将该键值对直接放入即可。
- 若该位置有元素,则使用key与已有元素依次比较哈希值,若哈希值不相同,则将该元素直接放 入。
- 若key与已有元素的哈希值相同,则使用key调用equals方法与已有元素依次比较。
- 若相等则将对应的value修改,否则将键值对直接放入即可。
相关的常量
- DEFAULT_INITIAL_CAPACITY : HashMap的默认容量是16。
- DEFAULT_LOAD_FACTOR:HashMap的默认加载因子是0.75。
- threshold:扩容的临界值,该数值为:容量*填充因子,也就是12。
- TREEIFY_THRESHOLD:若Bucket中链表长度大于该默认值则转化为红黑树存储,该数值是8。
- MIN_TREEIFY_CAPACITY:桶中的Node被树化时最小的hash表容量,该数值是64。
Collections类
基本概念
- java.util.Collections类主要提供了对集合操作或者返回集合的静态方法。
常用的方法
| 方法声明 | 功能介绍 |
|---|---|
| static<T extends Object & Comparable <? super T>> T max(Collection<Collection>coll) | 根据元素的自然顺序返回给定集 合的最大元素 |
| static T max(Collection/<? extends T/> coll, Comparator/<? super T/> comp) | 根据指定比较器引发的顺序返回 给定集合的最大元素 |
| static <T extends Object & Comparable<?super T>> T min(Collection<? extends T> coll) | 根据元素的自然顺序返回给定集 合的最小元素 |
| static T min(Collection<? extends T> coll, Comparator<? super T> comp) | 根据指定比较器引发的顺序返回 给定集合的最小元素 |
| static T max(Collection/<? extends T/> coll, Comparator/<? super T/> comp) | 将一个列表中的所有元素复制到 另一个列表中 |
| 方法声明 | 功能介绍 |
|---|---|
| static void reverse(List<?> list) | 反转指定列表中元素的顺序 |
| static void shuffle(List<?> list) | 反转指定列表中元素的顺序 |
| static <T extends Comparable<? super T>> void sort(List list) | 根据其元素的自然顺序将指定列表按升 序排序 |
| static void sort(List list, Comparator<? super T> c) | 根据指定比较器指定的顺序对指定列表 进行排序 |
| static void swap(List<?> list, int i, int j) | 交换指定列表中指定位置的元素 |
-
方法的使用
// 1.准备一个集合并初始化 List<Integer> lt1 = Arrays.asList(10, 30, 20, 50, 45); // 2.实现集合中元素的各种操作 System.out.println("集合中的最大值是:" + Collections.max(lt1)); // 50 System.out.println("集合中的最小值是:" + Collections.min(lt1)); // 10 // 实现集合中元素的反转 Collections.reverse(lt1); System.out.println("lt1 = " + lt1); // [45, 50, 20, 30, 10] // 实现两个元素的交换 Collections.swap(lt1, 0, 4); System.out.println("交换后:lt1 = " + lt1); // [10, 50, 20, 30, 45] // 实现元素的排序 Collections.sort(lt1); System.out.println("排序后:lt1 = " + lt1); // [10, 20, 30, 45, 50] // 随机置换 Collections.shuffle(lt1); System.out.println("随机置换后:lt1 = " + lt1); // [30, 10, 45, 20, 50] 随机 // 实现集合间元素的拷贝 //List<Integer> lt2 = new ArrayList<>(20); List<Integer> lt2 = Arrays.asList(new Integer[10]); System.out.println("lt1的大小是:" + lt1.size()); System.out.println("lt2的大小是:" + lt2.size()); // 表示将lt1中的元素拷贝到lt2中 Collections.copy(lt2, lt1); System.out.println("lt2 = " + lt2);