-
1. 准备工作
-
2. 字符串基础
-
2.1 创建字符串或字符向量
-
2.2 字符串长度:str_length() 函数
-
2.3 字符串组合:str_c() 函数
-
2.4 字符串取子集:str_sub() 函数
-
2.5 区域设置
-
-
3. 用正则表达式进行模式匹配:str_view()函数
-
3.1 基础匹配
-
3.2 锚点
-
3.3 字符类与字符选项
-
3.4 重复
-
3.5 分组与回溯引用
-
-
4. 工具
-
4.1 匹配检测:str_detect() 函数
-
4.2 提取匹配内容:str_extract() 函数
-
4.3 分组匹配:str_match() 函数
-
4.4 替换匹配内容:str_replace() 函数
-
4.5 拆分:str_split() 函数
-
4.6 定位匹配内容:str_locate()
-
-
5. 其他类型的模式
-
5.1 regex() 函数
-
5.2 fixed() 函数
-
5.3 coll() 函数
-
5.4 boundary() 函数
-
-
6. 正则表达式的其他应用
-
6.1 apropos() 函数
-
6.2 dir() 函数
-
-
7. stirngi
1. 准备工作
stringr 不是tidyverse 核心 R 包的一部分,故需要使用命令来加载它。
library(tidyverse)
library(stringr)2. 字符串基础
2.1 创建字符串或字符向量
(1)用单引号或双引号来创建字符串。
单引号和双引号在 R中没有区别。一般用双引号。单引号通常用于分隔包含"的字符向量。
string1 <- "This is a string" #用"创建字符串
string2 <- 'To put a "quote" inside a string, use single quotes' #字符串中含"时,用"来创建字符串
如果要在字符串中包含一个'或",需要用 \ 对其进行“转义”(也就是说,\在字符串中有特殊含义,即“转义”):
writeLines("\'") # writelines() 函数用于查看字符串的初始内容
'
writeLines('\"')
"
如果要在字符串中包含一个反斜杠,需要用两个反斜杠:\。
writeLines('\\')
\
其他特殊字符列表(用 ?'"' 或 ?"'" 命令来查看)
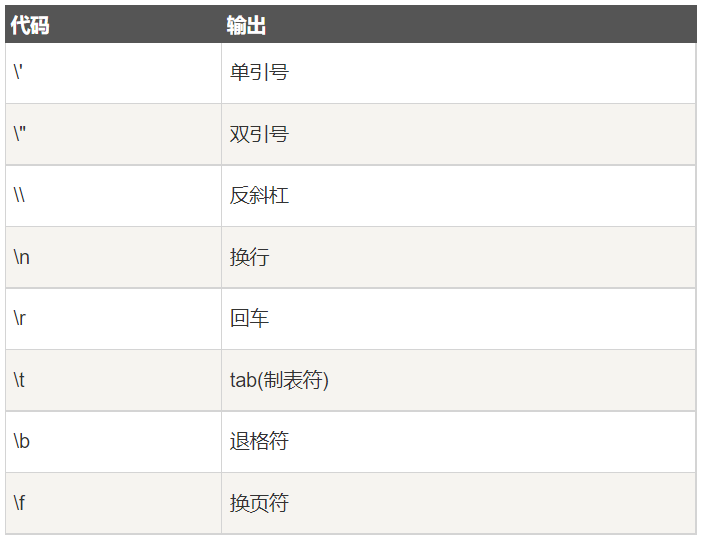
writeLines("\u00b5")
μ
(2)用 c() 函数来创建字符向量(包含多个字符串)
c("one", "two", "three")
[1] "one" "two" "three"2.2 字符串长度:str_length() 函数
-
功能:返回字符串中的字符数量:
-
用法:str_length(string)
str_length(c("a", "R for data science", NA))
[1] 1 18 NA2.3 字符串组合:str_c() 函数
(1)str_c() 函数-stringr包中的函数
-
功能:将多个字符串连接成一个字符串。
-
用法:str_c(..., sep = "", collapse = NULL)
-
参数 ... :字符串列表或字符向量
-
参数 sep :分隔符,默认不分隔
-
参数 collapse :将字符向量中的字符串合并,并用提供的分隔符分隔
str_c("x", "y", "z") # 输入为3个字符串"x", "y", "z"
[1] "xyz"
str_c("x", "y", "z", sep = ", ") # 用“逗号+空格”分隔
[1] "x, y, z"
str_c(c("x", "y", "z"), collapse = ", ") # 输入为1个字符向量c("x", "y", "z")
[1] "x, y, z"
-
长度为 0 的对象会被丢弃,这与 if 结合起来特别有用
name <- "Hadley"
time_of_day <- "morning"
birthday <- TRUE
str_c(
"Good ", time_of_day, " ", name,
if (birthday) " and HAPPY BIRTHDAY",
"."
)
[1] "Good morning Hadley and HAPPY BIRTHDAY."
birthday <- FALSE
str_c(
+ "Good ", time_of_day, " ", name,
+ if (birthday) " and HAPPY BIRTHDAY",
+ "."
+ )
[1] "Good morning Hadley."
-
str_c() 函数是向量化的,它可以自动循环短向量,使得其与最长的向 量具有相同的长度:
str_c("prefix-", c("a", "b", "c"), "-suffix") # "prefix-"和 "-suffix"是短向量,c("a", "b", "c")是长向量
[1] "prefix-a-suffix" "prefix-b-suffix" "prefix-c-suffix"
-
缺失值是可传染的。如果想要将它们输出为 "NA",可以使用 str_ replace_na():
x <- c("abc", NA) # 1个字符向量,包含2个字符串
str_c("|-", x, "-|") # 组合字符串,没有特殊说明时,缺失值可传染
[1] "|-abc-|" NA
str_c("|-", str_replace_na(x), "-|") # 用 str_replace_na()将缺失值输出为 "NA",
[1] "|-abc-|" "|-NA-|"
(2) paste() 和 paste0() 函数-R语言内置函数
-
功能:连接字符串
-
用法:
-
paste (..., sep = " ", collapse = NULL, recycle0 = FALSE) #可自定义分隔符,默认为空格
-
paste0(..., collapse = NULL, recycle0 = FALSE) #字符串间紧密连接
x <- "apple"
y <- "banana"
paste(x,y)
[1] "apple banana"
paste0(x,y)
[1] "applebanana"
-
处理NA时与str_c()的区别:str_c()中NA有传染性,paste()将NA返回成字符
x <- "apple"
z <- NA
paste(x,z)
[1] "apple NA"
str_c(x,z)
[1] NA2.4 字符串取子集:str_sub() 函数
-
功能:提取或修改字符串的一部分。
-
用法:str_sub(string, start = 1L, end = -1L)
-
参数start和end:Start给出第一个字符的位置(默认为第一个),end给出最后一个字符的位置(默认为最后一个字符)。
x <- c("Apple", "Banana", "Pear")
str_sub(x, 1, 3)
[1] "App" "Ban" "Pea"
-
即使字符串过短, str_sub() 函数也不会出错,它将返回尽可能多的字符:
str_sub("a", 1, 5)
[1] "a"
-
用 str_sub()替换字符串:通过 函数的赋值形式来实现
str_sub(x, 1, 1) <- str_to_lower(str_sub(x, 1, 1)) # str_to_lower()将文本转化为小写
x
[1] "apple" "banana" "pear"2.5 区域设置
(1)str_to_upper(),str_to_title()
-
功能:将文本转化为大写
-
用法:str_to_upper(string, locale = "en")
-
参数locale:区域设置,默认为“en”(英语)。区域设置可以参考 ISO 639 语言编码标准,语言编码是 2 或 3 个字母的缩写,见下表,如“tr”(土耳其语)
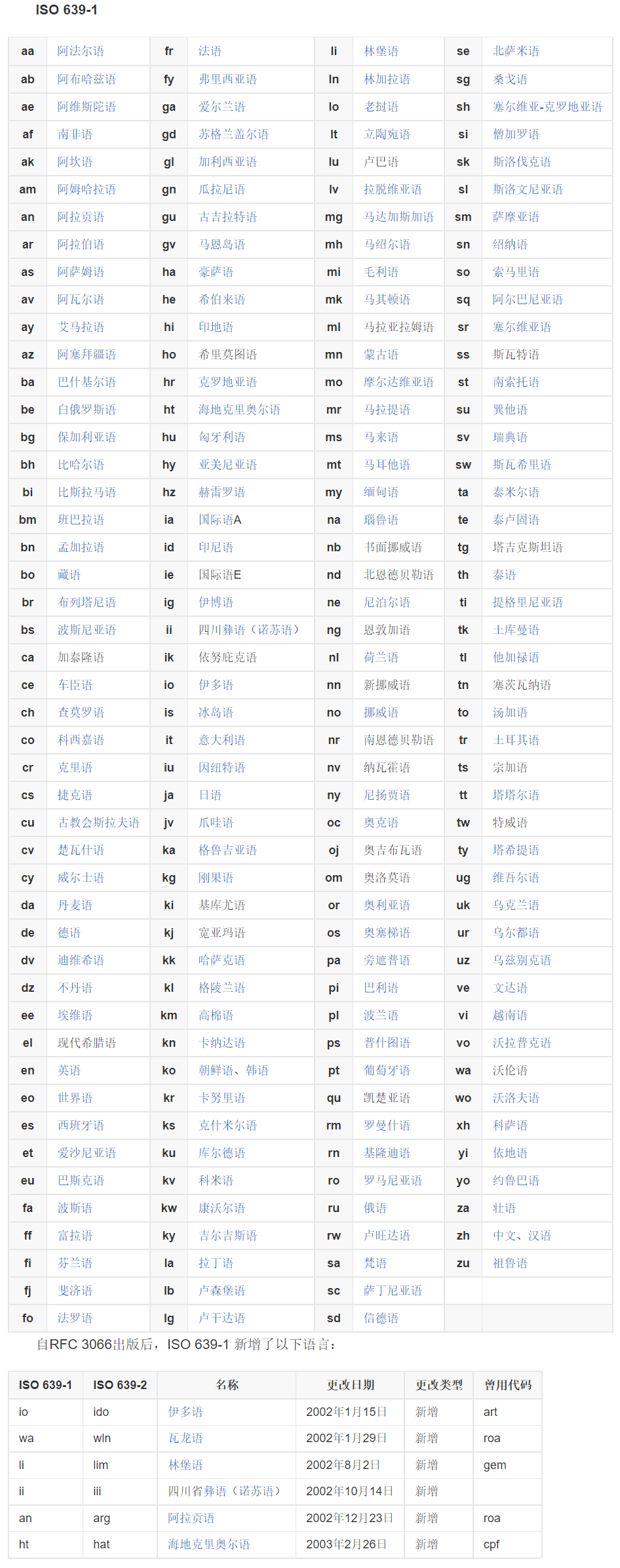
str_to_upper(c("i", "ı"), locale = "tr") # 土耳其语中有带点和不带点的两个i,它们在转换为大写时是不同的:
[1] "İ" "I"
str_to_upper(c("i", "ı")) #默认区域设置是英语,转化成大写时是一样的
[1] "I" "I"
(2) str_sort() 和 str_order() 函数
-
功能:排序
-
参数locale:区域设置
x <- c("apple", "eggplant", "banana")
str_sort(x, locale = "en") # 英语
[1] "apple" "banana" "eggplant"
str_sort(x, locale = "haw") # 夏威夷语
[1] "apple" "eggplant" "banana"
# 用英语和夏威夷与排序时的结果是不一样的3. 用正则表达式进行模式匹配:str_view() 函数
正则表达式(Regular Expression)
是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。描述了一种字符串匹配的模式(pattern)。通常被用来检索、替换那些符合某个模式(规则)的文本。许多程序设计语言都支持利用正则表达式进行字符串操作。
str_view() 和 str_view_all() 函数
-
用法:
str_view(string, pattern, match = NA) 显示第一个匹配
str_view_all(string, pattern, match = NA) 显示所有匹配
-
参数match:为TRUE时只显示匹配项,为FALSE时只显示不匹配项,为NA时显示匹配项和不匹配项(默认)
-
要显示str_view()匹配的结果,还需要额外安装两个 R 包:htmltools 和 htmlwidgets。
-
很多 stringr 函数都是成对出现的:一 个函数用于单个匹配,另一个函数用于全部匹配,后者会有后缀 _all。
# htmltools包可以用 library() 直接安装
library(htmltools)
# htmlwidgets包直接安装不,可以试着用下面命令安装
BiocManager::install("htmlwidgets")
library(htmlwidgets)
-
str_view()匹配的结果显示在右下角窗格中
3.1 基础匹配
(1) 精确匹配字符串
x <- c("apple", "banana", "pear")
str_view(x, "an")

(2)用.可以匹配任意字符(除了换行符)(但只能匹配1个字符):
str_view(x, ".a.")

(3)如何匹配字符 . 呢?
. 可以匹配任意字符,正则表达式用\来去除某些字符的特殊含义,因此,要匹配.,需要的正则表达式是\.(前面加1个\来去除.匹配任意字符的特殊含义,使其仅用来匹配.)。
\ 在字符串中也用作转义字符(去除某些字符的特殊含义),因此,正则表达式 \. 的字符串形式应是 \\.
str_view(c("abc", "a.c", "bef"), "a\\.c")

(4)如何匹配\呢?
要匹配\,需要的正则表达式是\\,对应的字符串形式为"\\\\"
x <- "a\\b"
writeLines(x)
a\b
str_view(x, "\\\\")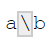
3.2 锚点
默认情况下,正则表达式会匹配字符串的任意部分。
需要从字符串的开头或末尾进行匹配时,要设置锚点。
-
^ 从字符串开头进行匹配。
-
$ 从字符串末尾进行匹配。
x <- c("apple", "banana", "pear")
str_view(x, "^a") # 匹配字符串开头的a
str_view(x, "a$") # 匹配字符串末尾的a
x <- c("apple pie", "apple", "apple cake")
str_view(x, "apple") #正则表达式默认匹配字符串的任意部分,只要含apple即可,这里3个字符串中的apple都会匹配到
str_view(x, "^apple$") #严格匹配到第2个字符串,不仅含apple,且字符串以a开头以e结尾
-
\b 匹配单词间的边界
x <- c("The green light in the brown box flickered.","Glue the sheet to the dark blue background.","Hedge apples may stain your hands green." )
# 匹配x中的颜色
colors <- c("red", "orange", "yellow", "green", "blue", "purple") # 创建颜色名称向量
color_match <- str_c(colors, collapse = "|") # 将颜色名称向量转化为正则表达式
str_view_all(x,color_match) # 匹配x中的颜色
# 发现第一个句子中的flickered也被匹配到了,该怎么修改?
color_match2 <- str_c("\\b(",color_match,")\\b") # 在pattern前后加\b(单词边界)
str_view_all(x,color_match2)3.3 字符类与字符选项
很多特殊模式可以匹配多个字符。(虽然可以匹配多个,但是一次只匹配一个,想匹配多次见3.4)
-
.可以匹配除换行符外的任意字符。
-
\d 可以匹配任意数字。
-
\s 可以匹配任意空白字符(如空格、制表符和换行符)
-
[abc] 可以匹配 a、 b 或 c。
-
[^abc] 可以匹配除 a、 b、 c 外的任意字符。
注意:要想创建包含 \d 或 \s 的正则表达式,需要在字符串中对 \ 进行转义,因此需 要输入 "\\d" 或 "\\s"。
| 的优先级很低(最后才考虑|),所以 abc|xyz 匹配的是 abc 或 xyz,而不是 abcyz 或 abxyz。
如果优先级让人感到困惑,那么可以使用括号让其表达得更清晰一些:如gr(e|a)y匹配的是grey或gray。
3.4 重复
正则表达式的另一项强大功能是,其可以控制一个模式能够匹配多少次。(是将它前面的字符匹配多少次)
-
?:0 次或 1 次。相当于{0,1}
-
+:1 次或多次。相当于{1,}
-
*:0 次或多次。相当于{0,}
x <- "1888 is the longest year in Roman numerals: MDCCCLXXXVIII"
str_view(x, "CC?") #"CC?"是将第2个C匹配0次或1次,也就是说匹配的是C或CC。
str_view(x, "CC+") #"CC+"是将第2个C匹配1次或多次,也就是说匹配的是连续2个以上的C
str_view(x, 'C[LX]+') #'C[LX]+'是将[LX]匹配1次或多次,[LX]意思是匹配L或X,也就是说只要C后面接的是L或X都可以匹配到,直到不是L或X为止。
注意:这些运算符的优先级非常高(也就是说优先考虑匹配次数),因此很多时候需要使用括号
x <- c("color","colour","banana","bananana")
str_view(x, "banana+", match = TRUE) #"banana+"是将最后一个a匹配1次或多次,匹配的是banana或bananaaaa..,这里只能匹配到第3个和第4个字符串中的banana
str_view(x, "bana(na)+", match = TRUE) #"bana(na)+"是将最后的na匹配1次或多次,比如banana或bananana,这里第3个和第4个字符串可以全部匹配到
还可以精确设置匹配的次数
-
{n}:匹配 n 次。
-
{n,}:匹配 n 次或更多次。
-
{,m}:最多匹配 m 次。
-
{n, m}:匹配 n 到 m 次。
x <- "1888 is the longest year in Roman numerals: MDCCCLXXXVIII"
str_view(x, "C{2}") #"C{2}"是将C匹配2次,即匹配的是CC
str_view(x, "C{2,}") #"C{2,}"是将C匹配2次以上,也就是说可以匹配连续2个以上的C
str_view(x, "C{2,3}") #"C{2,3}"是将C匹配2~3次,也就是说匹配的是CC或CCC
正则表达式默认会匹配尽量长的字符串(默认的匹配方式是“贪婪的”,如果有长的就匹配长的,没长的就匹配略短的)。
在正则表达式后面加一个 ?,可以将匹配方式更改为“懒惰的”,即匹配尽量短的字符串。
str_view(x, "C{2,3}") #"C{2,3}"匹配方式为贪婪,如果字符串含CCC,那匹配的是CCC而非CC。当然,如果只有2个连续C那匹配的就是CC,如果有4个连续C那匹配的还是前3个C。
str_view(x, "C{2,3}?") #"C{2,3}?"匹配方式为懒惰,即匹配的是CC。
str_view(x, 'C[LX]+?') #'C[LX]+?'匹配方式为懒惰,即匹配的是CL或CX。
练习
用语言描述以下正则表达式匹配的是何种模式(仔细阅读来确认我们使用的是正则表达式,还是定义正则表达式的字符串)?
a. ^.*$ #这是正则表达式,.*表示重复0次以上的.,这里^和$表示以任意字符开始,以任意字符结束,故这个匹配的是任意字符。
b. "\\{.+\\}" #这是定义正则表达式的字符串,由于{和}在正则表达式中有特殊含义,所以\\{匹配的是单纯的{,\\}匹配的是},.+表示重复1次以上的.,.在正则表达式中可匹配任意字符,故这个匹配的是任意花括号里有至少1个字符的字符串,如"{a}"或"{abc}"等
c. \d{4}-\d{2}-\d{2} #这是正则表达式,\d可以匹配任意数字,{4}意思是将任意数字匹配4次,故这个匹配的是4位数字后接一个连字符,然后是两个数字后接一个连字符,然后是另外两个数字。这是一个正则表达式,可以匹配格式为“YYYY-MM-DD”(“%Y-%m-%d”)的日期。如2021-08-16
d. "\\\\{4}" #这是定义正则表达式的字符串,正则表达式的字符串中\\\\匹配的是\,故这个匹配的是\\\\。
找出以 3 个辅音字母开头的单词
str_view(words,"^[^aeiou]{3}",match=TRUE) #这里[^aeiou]可以匹配任意非元音字母(辅音字母),但只能匹配一个字母,{3}是匹配3次辅音字母
找出有连续 3 个或更多元音字母的单词。
str_view(words,"[aeiou]{3}",match=TRUE)
找出有连续 2 个或更多元音—辅音配对的单词
str_view(words,"([aeiou][^aeiou]){2,}",match=TRUE)3.5 分组与回溯引用
括号的作用:
-
阐明优先级,用于消除复杂表达式中的歧义。【前部分】
-
能对正则表达式进行分组,分组可以在匹配时回溯引用(如 \1、 \2 等)【本部分】
-
提取一个复杂匹配的各个 部分【后部分】
回溯引用
-
回溯引用可以匹配到捕获组曾经匹配过的结果。
-
回溯引用的标志是反斜杠后加数字
-
回溯引用中的数字是从左至右计算的。回溯引用中的\1对应第一个圆括号中的内容,\2对应第二个圆括号中的内容。
# 找出名称中有重复的一对字母的所有水果
str_view(fruit, "(..)\\1", match = TRUE) #"(..)\\1"中..表示匹配任意两个字符,\1表示回溯引用第一个()中的内容,由于用字符串表示,所以表示为\\1,故这个匹配的是名称中有重复的一对字母的所有水果
练习
用语言描述以下正则表达式会匹配何种模式? (.)\1\1 #同一字符重复3次,如"aaa" "(.)(.)\\2\\1" #一对字符镜像出现,如"abba" (..)\1 #任意2个字符重复,如"a1a1" "(.).\\1.\\1" #注意这是定义正则表达式的字符串,表示“一个字符后面跟着任意字符,原始字符,任何其他字符,再重复原始字符”,如"abaca"或"b8b.b",即一共5个字符,第1、3、5个字符一样,其余随意。 "(.)(.)(.).*\\3\\2\\1" 表示“三个字符,后面跟着0个或多个任意字符,后面跟着三个相同的字符,只是顺序相反”,如“abcsgasgddsadgsdgcba”或“abccba”或“abc1cba”。
4. 工具
基本思想:将一个复杂问题分解为多个简单问题
4.1 匹配检测:str_detect() 函数
(1)str_detect() 函数
-
功能:确定一个字符向量能否匹配一种模式,判断的是能否匹配,故结果是逻辑向量,即TRUE或FALSE
-
用法:str_detect(string, pattern, negate = FALSE),negate为TRUE 则返回不匹配的元素
# 判断x的3个字符串中是否含e
x <- c("apple", "banana", "pear")
str_detect(x, "e")
[1] TRUE FALSE TRUE
str_detect(x, "e", negate = TRUE)
[1] FALSE TRUE FALSE
-
从数学意义上来说,逻辑向量中的 FALSE 为 0, TRUE 为 1。这使得在匹配特别大的向量时,sum() 和 mean() 函数能够发挥更大的作用:
# 以t开头的常用单词有多少个?
sum(str_detect(words, "^t")) # words中共有980个单词,其中以t开头的有65个,也就是说str_detect(words, "^t")的结果中有65个TRUE(数学意义上=1),915个FALSE(数学意义上=0),65个1与915个0的和为65。
[1] 65
# sum(..., na.rm = FALSE)函数中的...可以是数字,也可以是逻辑向量
# 以元音字母结尾的常用单词的比例是多少?
mean(str_detect(words, "[aeiou]$")) # words中共有980个单词,其中以元音字母结尾的有271个,也就是说str_detect(words, "^t")的结果中有271个TRUE(数学意义上=1),709个FALSE(数学意义上=0),271个1与709个0的均值为0.2765306。
[1] 0.2765306
-
str_detect() 函数的一种常见用法是选取出匹配某种模式的元素。
# 通过逻辑取子集方式,来选取出匹配某种模式的元素
# [是取子集函数,调用方式为x[i],逻辑向量取子集方式可提取出TRUE值对应的所有元素(见课本15.4.5向量取子集)
words[str_detect(words, "x$")] #提取出 words 中str_detect(words, "x$")结果为TRUE(以x结尾)的元素
[1] "box" "sex" "six" "tax"
# 或用str_subset() 包装器函数,来来选取出匹配某种模式的元素
str_subset(words, "x$")
[1] "box" "sex" "six" "tax"
-
如果正则表达式过于复杂,则应该将其分解为几个更小的子表达式,将每个子表达式的匹配结果赋给一个变量,并使用逻辑运算组合起来。
# 找出以 x 开头或结尾的所有单词
# 用str_subset()函数选取匹配某种模式的元素
str_subset(words,"^x|x$") # words中没有以x开头的单词,以x结尾的单词有4个
[1] "box" "sex" "six" "tax"
# 通过逻辑取子集方式选取匹配某种模式的元素
words[str_detect(words,"^x|x$")] #选出 words 中结果为TRUE的元素
[1] "box" "sex" "six" "tax"
# 将其分解为2个简单问题,将结果赋值给变量,然后使用逻辑运算组合起来
start_with_x <- str_detect(words,"^x")
end_with_x <- str_detect(words,"x$")
words[start_with_x|end_with_x]
[1] "box" "sex" "six" "tax"
-
字符串通常会是数据框的一列,此时我们可以使用 filter 操作
df <- tibble(word = words, i = seq_along(word)) #seq_along()用于生成序列,df是一个数据框(2个向量,一个word,一个序号)
df %>% filter(str_detect(words, "x$")) #筛选出df中word以x结尾的行
# A tibble: 4 x 2
word i
<chr> <int>
1 box 108
2 sex 747
3 six 772
4 tax 841
(2)str_count()函数
-
功能:返回字符串中匹配的数量
-
用法:str_count(string, pattern = "")
x <- c("apple", "banana", "pear")
str_count(x, "a") # 返回字符串中a的个数
[1] 1 3 1
mean(str_count(words, "[aeiou]")) # str_count(words, "[aeiou]")返回words中每个单词中含元音字母的个数,求均值即为“平均来看,每个单词中含元音字母的个数”
[1] 1.991837
# 哪个单词包含最多数量的元音字母?
vowels <- str_count(words, "[aeiou]")
words[which(vowels == max(vowels))]
[1] "appropriate" "associate" "available" "colleague" "encourage" "experience"
[7] "individual" "television"
# 哪个单词包含最大比例的元音字母? (提示:分母应该是什么?)
prop_vowels <- str_count(words, "[aeiou]") / str_length(words)
words[which(prop_vowels == max(prop_vowels))]
[1] "a"
-
str_count() 也完全可以同 mutate() 函数一同使用
df %>% mutate(vowels = str_count(word, "[aeiou]"), consonants = str_count(word, "[^aeiou]")) #在df基础上添加2列vowels和consonants,表示每个单词中含元音字母和辅音字母的个数
# A tibble: 980 x 4
word i vowels consonants
<chr> <int> <int> <int>
1 a 1 1 0
2 able 2 2 2
3 about 3 3 2
4 absolute 4 4 4
5 accept 5 2 4
6 account 6 3 4
7 achieve 7 4 3
8 across 8 2 4
9 act 9 1 2
10 active 10 3 3
# ... with 970 more rows
注意:匹配从来不会重叠。
str_count("abababa", "aba") # "abababa"中,模式 "aba" 会匹配2次,而不是3次
[1] 24.2 提取匹配内容:str_extract() 函数
-
功能:提取匹配的实际文本
# 找出包含一种颜色的所有句子
colors <- c("red", "orange", "yellow", "green", "blue", "purple") #创建一个颜色名称向量
color_match <- str_c(colors, collapse = "|") #将颜色名称向量转换成一个正则表达式
has_color <- str_subset(sentences, color_match) #选取出包含一种颜色的句子
matches <- str_extract(has_color, color_match) #从选取出的句子中提取出颜色
head(matches) #显示前6个匹配结果
[1] "blue" "blue" "red" "red" "red" "blue"
-
str_extract(string, pattern) 只提取第一个匹配
-
str_extract_all(string, pattern, simplify = FALSE) 可以提取全部匹配。
# 逻辑向量取子集方式一般与比较函数结合起来使用效果更佳,提取出TRUE值对应的所有元素(见课本15.4.5向量取子集)
> (more <- sentences[str_count(sentences, color_match) > 1])
[1] "It is hard to erase blue or red ink."
[2] "The green light in the brown box flickered."
[3] "The sky in the west is tinged with orange red."
-
# str_extract() 只提取第一个匹配
> str_extract(more, color_match)
[1] "blue" "green" "orange"
# str_extract() 可以提取全部匹配,并返回为一个列表
> str_extract_all(more, color_match)
[[1]]
[1] "blue" "red"
[[2]]
[1] "green" "red"
[[3]]
[1] "orange" "red"
-
str_extract_all()的参数 simplify 默认为FALSE,返回字符向量列表;如果为TRUE,则返回一个字符矩阵,其中较短的匹配会扩展到与最长的匹配具有同样的长度:
# simplify = TRUE,返回一个矩阵
> str_extract_all(more, color_match, simplify = TRUE)
[,1] [,2]
[1,] "blue" "red"
[2,] "green" "red"
[3,] "orange" "red"
# 较短的匹配会扩展到与最长的匹配具有同样的长度
> x <- c("a", "a b", "a b c")
> str_extract_all(x, "[a-z]", simplify = TRUE)
[,1] [,2] [,3]
[1,] "a" "" ""
[2,] "a" "b" ""
[3,] "a" "b" "c"
练习
从 Harvard sentences 数据集中提取以下内容。
a. 每个句子的第一个单词。
pattern <- "[A-Za-z][A-Za-z']*"
b. 以 ing 结尾的所有单词。
pattern <- "\\b[A-Za-z]+ing\\b"
c. 所有复数形式的单词。
pattern <- "\\b[A-Za-z]{3,}s\\b"4.3 分组匹配:str_match() 函数
-
功能:可以给出每个独立分组。
-
用法:
-
str_match(string, pattern)
-
str_match_all(string, pattern)
-
结果:str_match() 返回的不是字符向量,而是一个矩阵,其中一列是完整匹配,后面的列是每个分组的匹配:
# 用括号来提取一个复杂匹配的各个部分
> noun <- "(a|the) ([^ ]+)"
> has_noun <- sentences %>% str_subset(noun) %>% head(10)
# str_extract()函数可以给出完整匹配,返回的是字符向量
> has_noun %>% str_extract(noun)
[1] "the smooth" "the sheet" "the depth" "a chicken" "the parked" "the sun" "the huge"
[8] "the ball" "the woman" "a helps"
# str_match()函数则可以给出每个独立分组,返回的是一个矩阵,其中一列是完整匹配,后面的列是每个分组的匹配:
> has_noun %>% str_match(noun)
[,1] [,2] [,3]
[1,] "the smooth" "the" "smooth"
[2,] "the sheet" "the" "sheet"
[3,] "the depth" "the" "depth"
[4,] "a chicken" "a" "chicken"
[5,] "the parked" "the" "parked"
[6,] "the sun" "the" "sun"
[7,] "the huge" "the" "huge"
[8,] "the ball" "the" "ball"
[9,] "the woman" "the" "woman"
[10,] "a helps" "a" "helps"
-
如果数据是保存在 tibble 中的,那么使用 tidyr::extract() 会更容易。这个函数的工作方式 与 str_match() 函数类似,只是要求为每个分组提供一个名称,以作为新列放在 tibble 中:
# tidyr::extract()的第一个参数是数据框,第2个参数是列名,第3个参数是正则表达式,remove = TRUE表示从输出数据帧中移除输入列。
> tibble(sentence = sentences) %>% tidyr::extract(sentence, c("article", "noun"), "(a|the) ([^ ]+)", remove = FALSE )
# A tibble: 720 x 3
sentence article noun
<chr> <chr> <chr>
1 The birch canoe slid on the smooth planks. the smooth
2 Glue the sheet to the dark blue background. the sheet
3 It's easy to tell the depth of a well. the depth
4 These days a chicken leg is a rare dish. a chicken
5 Rice is often served in round bowls. NA NA
6 The juice of lemons makes fine punch. NA NA
# ... with 714 more rows4.4 替换匹配内容:str_replace() 函数
-
功能:用新字符串替换匹配内容
-
用法:str_replace(string, pattern, replacement) replacement表示替换的字符向量,即把pattern匹配到的内容替换为replacement
-
用法1:用固定字符串替换匹配内容(replacement为固定字符串)
> x <- c("apple", "pear", "banana")
> str_replace(x, "[aeiou]", "-") #将x中的第1个元音字母替换为-
[1] "-pple" "p-ar" "b-nana"
> str_replace_all(x, "[aeiou]", "-") #将x中的所有元音字母替换为-
[1] "-ppl-" "p--r" "b-n-n-"
-
用法2:通过提供一个命名向量,使用 str_replace_all() 函数可以同时执行多个替换
> x <- c("1 house", "2 cars", "3 people")
> str_replace_all(x, c("1" = "one", "2" = "two", "3" = "three"))
[1] "one house" "two cars" "three people"
-
用法3:用回溯引用来插入匹配中的分组
# 交换句子中第二个单词和第三个单词的顺序
> sentences %>%
+ str_replace("([^ ]+) ([^ ]+) ([^ ]+)", "\\1 \\3 \\2") %>%
+ head(3)
[1] "The canoe birch slid on the smooth planks." "Glue sheet the to the dark blue background."
[3] "It's to easy tell the depth of a well."
练习
(1) 使用反斜杠替换字符串中的所有斜杠。
str_replace_all("past/present/future", "/", "\\\\")
(2) 使用 replace_all() 函数实现 str_to_lower() 函数的一个简单版。
replacements <- c("A" = "a", "B" = "b", "C" = "c", "D" = "d", "E" = "e", "F" = "f", "G" = "g", "H" = "h", "I" = "i", "J" = "j", "K" = "k", "L" = "l", "M" = "m", "N" = "n", "O" = "o", "P" = "p", "Q" = "q", "R" = "r", "S" = "s", "T" = "t", "U" = "u", "V" = "v", "W" = "w", "X" = "x", "Y" = "y", "Z" = "z")
lower_words <- str_replace_all(words, pattern = replacements)
head(lower_words)
(3) 交换 words 中单词的首字母和末尾字母,其中哪些字符串仍然是个单词?
swapped <- str_replace_all(words, "^([A-Za-z])(.*)([A-Za-z])$", "\\3\\2\\1")
intersect(swapped, words)4.5 拆分:str_split() 函数
-
功能:将字符串拆分为多个片段
-
用法:
-
str_split(string, pattern, n = Inf, simplify = FALSE)
-
str_split_fixed(string, pattern, n)
-
参数simplify:默认为FALSE,返回的是列表;为TRUE时返回矩阵
# 将句子拆分成单词
# simplify默认为FALSE,返回的是列表
> sentences %>% head(3) %> str_split(" ") #在空格处拆开。
[[1]]
[1] "The" "birch" "canoe" "slid" "on" "the" "smooth" "planks."
[[2]]
[1] "Glue" "the" "sheet" "to" "the" "dark"
[7] "blue" "background."
[[3]]
[1] "It's" "easy" "to" "tell" "the" "depth" "of" "a" "well."
# simplify为TRUE时返回矩阵
> sentences %>% head(3) %>% str_split(" ", simplify = TRUE)
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
[1,] "The" "birch" "canoe" "slid" "on" "the" "smooth" "planks." ""
[2,] "Glue" "the" "sheet" "to" "the" "dark" "blue" "background." ""
[3,] "It's" "easy" "to" "tell" "the" "depth" "of" "a" "well."
-
因为字符向量的每个分量会包含不同数量的片段,所以 str_split() 会返回一个列表。如果拆分的是长度为 1 的向量,那么只要简单地提取列表的第一个元素即可,.[[1]]的功能类似于head(1)
> "a|b|c|d" %>%
+ str_split("\\|") %>%
+ .[[1]] #[[是取子集函数[的变体,只提取单个元素,并丢弃名称
[1] "a" "b" "c" "d"
-
参数n:表示拆分的片段数,默认为Inf,即返回所有片段还可以设定拆分片段的最大数量:
> fields <- c("Name: Hadley: baf", "Country: NZ", "Age: 35")
# 拆分成2段,返回为矩阵
> fields %>% str_split(": ", n = 2, simplify = TRUE)
[,1] [,2]
[1,] "Name" "Hadley: baf"
[2,] "Country" "NZ"
[3,] "Age" "35"
-
参数pattern:除了模式,你还可以用boundary()来匹配字符、单词、行和句子的边界,以这些边界来拆分字符串。
> x <- "This is a sentence. This is another sentence." > str_split(x, " ")[[1]] [1] "This" "is" "a" "sentence." "This" "is" "another" "sentence." > str_split(x, boundary("word"))[[1]] [1] "This" "is" "a" "sentence" "This" "is" "another" "sentence" # 用boundary("word")的拆分效果比" "更灵活,前者结果中只有单词,后者结果中还有.
4.6 定位匹配内容:str_locate()
-
功能:定位模式在字符串中的位置。可以返回每个匹配的开始位置和结束位置。
-
用法:
-
str_locate(string, pattern)
-
str_locate_all(string, pattern)
> fruit <- c("apple", "banana", "pear", "pineapple")
> str_locate(fruit, "a")
start end
[1,] 1 1
[2,] 2 2
[3,] 3 3
[4,] 5 55. 其他类型的模式
以下3个函数是同一类型函数,都使用修饰函数控制匹配行为
5.1 regex() 函数
-
当使用一个字符串作为模式时, R 会自动调用 regex() 函数对其进行包装。
# 正常调用:当所有参数都为默认设置时,简写为仅字符串(模式)
> str_view(fruit, "nana")
# 上面形式是以下形式的简写:当需要修改默认参数时,就需要写出regex()函数
> str_view(fruit, regex("nana"))
-
用法:regex(pattern, ignore_case = FALSE, multiline = FALSE, comments = FALSE, dotall = FALSE, ...)
-
参数:后面这几个参数的默认设置都是FALSE,也就是说,当它们都是FALSE时即为我们前面所学,regex()也可以简写为仅字符串(模式),只是前面学习时未写出默认参数而已,换言之,如果这些参数为TRUE,那就是不同的意思,可以通过修改参数来控制具体的匹配方式
-
ignore_case(忽略字母大小写):默认为FALSE,匹配时字母区分有大小写。当 ignore_case = TRUE 时,忽略字母大小写,既可以匹配大写字母,也可以匹配小写字母,它总是使用当前的区 域设置:
> bananas <- c("banana", "Banana", "BANANA")
# 默认区分大小写,只能匹配到第1个字符串
> str_view(bananas, "banana")
# 不区分大小写,3个字符串都能匹配到
> str_view(bananas, regex("banana", ignore_case = TRUE))
-
multiline(多行):默认为FALSE,即没有多行的说法, ^ 和 $ 从完整字符串的开头和末尾开始匹配。当 multiline = TRUE 时,可使 ^ 和 $ 从每行的开头和末尾开始匹配:
> x <- "Line 1\nLine 2\nLine 3"
# 默认只能从完整字符串的开头开始匹配,即只能匹配到第1个Line
> str_extract_all(x, "^Line")[[1]]
[1] "Line"
# ^可以从每行的开头开始匹配,即3个Line都能匹配到
> str_extract_all(x, regex("^Line", multiline = TRUE))[[1]]
[1] "Line" "Line" "Line"
-
comments(注释):如果为TRUE,可以在复杂的正则表达式中加入注释和空白字符,以便更易理解。匹配时会忽略空格和 # 后面的内容。如果想要匹配一个空格,你需要对其进行转义:"\\ ":
phone <- regex("
\\(? # 可选的开括号
(\\d{3}) # 地区编码
[)- ]? # 可选的闭括号、短划线或空格
(\\d{3}) # 另外3个数字
[ -]? # 可选的空格或短划线
(\\d{3}) # 另外3个数字
", comments = TRUE)
> str_match("514-791-8141", phone)
[,1] [,2] [,3] [,4]
[1,] "514-791-814" "514" "791" "814"
-
dotall:为 TRUE 时 . 可以匹配包括 \n(换行符) 在内的所有字符
5.2 fixed() 函数
-
功能:可以按照字符串的字节形式进行精确匹配,它会忽略正则表达式中的所有特殊字符,并在非常低的层次上进行操作。这样可以不用进行那些复杂的转义操作,而且速度比普通正则表达式要快很多。
-
用法:fixed(pattern, ignore_case = FALSE)
microbenchmark::microbenchmark(
fixed = str_detect(sentences, fixed("the")), # 用fixed() 函数精确匹配
regex = str_detect(sentences, "the"), # 用regex()函数匹配
times = 20
)
# 可见,用fixed()函数匹配到的结果要比regex()函数匹配到的少
#> Unit: microseconds
#> expr min lq mean median uq max neval cld
#> fixed 116 117 136 120 125 389 20 a
#> regex 333 337 346 338 342 467 20 b
-
在匹配非英语数据时,要慎用 fixed() 函数。它可能会出现问题,因为此时同一个字符经常有多种表达方式。如,定义 á 的方式有两种:一种是单个字母 a,另一种是 a 加 上重音符号:
> a1 <- "\u00e1"
> a2 <- "a\u0301"
> c(a1, a2) #可见 a1 和 a2 表示的是同一字符
[1] "á" "a"
> a1 == a2 #但比较得到的结果是FALSE
[1] FALSE
# 这两个字母的意义相同,但因为定义方式不同,所以 fixed() 函数找不到匹配。
> str_detect(a1, fixed(a2))
[1] FALSE5.3 coll() 函数
-
功能:使用标准排序规则来比较字符串,这在进行不区分大小写的匹配时是非常有效的。
-
用法:coll(pattern, ignore_case = FALSE, locale = "en", ...)
-
参数:可以通过设置 locale 参数(区域设置,默认"en"(英语)),以确定使用哪种规则来比较字符。
> i <- c("I", "İ", "i", "ı")
> str_subset(i, coll("i", ignore_case = TRUE)) #不区分大小写,默认用英语匹配,i匹配到的是I和i
[1] "I" "i"
> str_subset(i, coll("i", ignore_case = TRUE, locale = "tr")) #不区分大小写,区域设置用土耳其语匹配,i匹配到的是İ和i
[1] "İ" "i"
-
fixed() 和 regex() 函数中都有 ignore_case 参数,但都无法选择区域设置,而coll()函数可以选择区域设置
-
coll()函数的弱点是速度,因为确定哪些是相同字符的规则比较复杂,与 regex() 和 fixed() 函数相比, coll() 确实比较慢。
5.4 boundary() 函数
-
功能:匹配(字母、行、句子和单词)边界
-
用法:boundary(type = c("character", "line_break", "sentence", "word"), skip_word_none = NA, ...)
-
参数:
-
type:要检测的边界类型,可以选c("character", "line_break", "sentence", "word"),即字母、行、句子和单词,前面例子中用到的是匹配单词边界。
> x <- "This is a sentence."
> str_extract_all(x, boundary("word"))
[[1]]
[1] "This" "is" "a" "sentence"
练习
(1) 如何找出包含 \ 的所有字符串?分别使用 regex() 和 fixed() 函数来完成这个任务。
> str_subset(c("a\\b", "ab"), "\\\\")
[1] "a\\b"
> str_subset(c("a\\b", "ab"), fixed("\\")) #尽管fixed()函数可以忽略正则表达式中的所有特殊字符,但书写字符串使还是应该注意特殊字符的特殊含义,比如\表示转义。
[1] "a\\b"
> writeLines("a\\b")
a\b
(2) sentences 数据集中最常见的 5 个单词是什么?
tibble(word = unlist(str_extract_all(sentences, boundary("word")))) %>% # 以单词为边界提取出句子中的所有单词
mutate(word = str_to_lower(word)) %>% # 将单词中的大写转化为小写
count(word, sort = TRUE) %>% # 以单词分组进行计数,并倒序排
head(5) # 选出前5个
# A tibble: 5 x 2
word n
<chr> <int>
1 the 751
2 a 202
3 of 132
4 to 123
5 and 1186. 正则表达式的其他应用
R 基础包中有两个常用函数,它们也可以使用正则表达式。
6.1 apropos() 函数
-
功能:通过(部分)名称查找对象,可以在全局环境空间中搜索所有可用对象。当不能确切想起函数名称时,这个函数特别有用:
-
用法:
> apropos("replace") [1] "%+replace%" ".rs.registerReplaceHook" ".rs.replaceBinding" [4] ".rs.rpc.replace_comment_header" "replace" "replace_na" [7] "replacements" "setReplaceMethod" "str_replace" [10] "str_replace_all" "str_replace_na""theme_replace"
6.2 dir() 函数
-
功能:可以列出一个目录下的所有文件
-
用法:
-
dir() 函数的 patten 参数可以是一个正则表达式,此时它只返回与这个模式相匹配的文件名。
# 返回当前目录中的所有CSV文件
> head(dir(pattern = "\\.csv$"))
[1] "diamonds.csv"7. stirngi
-
stringr 建立于 stringi 的基础之上。
-
stringr 非常容易学习,因为它只提供了非常少的函数(只有42个)
-
与 stringr 不同, stringi 的设计思想是尽量全面,几乎包含了我们可以用到的所有函数(有 234 个函数)。
-
练习
(1) 找出可以完成以下操作的 stringi 函数。
a. 计算单词的数量。 #用stri_count_words()函数
> stri_count_words(head(sentences))
[1] 8 8 9 9 7 7
b. 找出重复字符串。 #用stri_duplicated()函数
> stri_duplicated(c("the", "brown", "cow", "jumped", "over", "the", "lazy", "fox"))
[1] FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE
c. 生成随机文本。
> stri_rand_strings(4, 5) #用stri_rand_strings()生成随机字符串
[1] "BabVd" "ozkiF" "PtBxp" "BRy6A"
> stri_rand_shuffle("The brown fox jumped over the lazy cow.") #用stri_rand_shuffle()打乱顺序
[1] "ojr mty.eTnowveo zo fbwe pulchhxed ar"
(2) 如何控制 stri_sort() 函数用来排序的语言设置?
# 通过区域设置
> string1 <- c("hladny", "chladny")
> stri_sort(string1, locale = "pl_PL")
[1] "chladny" "hladny"
> stri_sort(string1, locale = "sk_SK")
[1] "hladny" "chladny"