一、从主成分分析说起
1.主成分分析起源
主成分分析法由Pearson在1901年提出,是一种常用的降维方法,可以将维数高的样本转化成维数低的样本。在金融领域,常用于各种多因子模型中,将原有多个指标转化为互不相关的少量综合指标。从数学角度来说,主成分分析是对原始数据进行线性变化,将原始坐标轴旋转和平移,得到新的坐标轴,使尽可能多的样本点在新坐标轴上分散最开。
2.一个例子
举个例子:假设一个班级里有10个学生,数学成绩和语文成绩分别如下表所示。
| 编号 | 数学 | 语文 |
|---|---|---|
| 1 | 70 | 65 |
| 2 | 75 | 70 |
| 3 | 80 | 75 |
| 4 | 85 | 80 |
| 5 | 90 | 85 |
| 6 | 95 | 90 |
建立一个直角坐标系,横轴和纵轴分别为数学、语文,如下图所示。
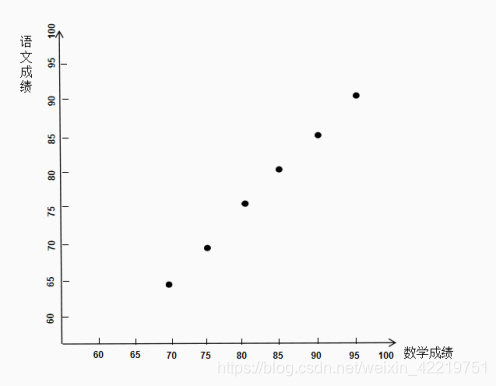 移动平面直角坐标系,让尽可能多的点分布在坐标轴上。
移动平面直角坐标系,让尽可能多的点分布在坐标轴上。

这样一来,只用新建的一个坐标轴即可描述每个学生的成绩,把这个新指标命名为“评价1”。这样只用这一个指标即可实现对成绩的评价,实现了从两个指标变成一个指标。
3.概述
主成分分析就具有这种帮助多个指标“瘦身”的功能。在对海量数据进行分析时,数据之间常常有一定的共线性,主成分分析能够将这些数据提取共性,进行压缩,提取相同的信息得到互不相关的变量,最大程度保留有效信息。
主成分分析从数学角度上来说就是进行线性变换,拓展到空间层面,就是移动坐标轴,使尽可能多的点落在坐标轴上或使尽可能多的点在新坐标轴上最分散。
什么叫最分散?
前例是一种极其特殊的情况。一般来说,原始数据不会刚刚好分布在一条直线上,如下图。
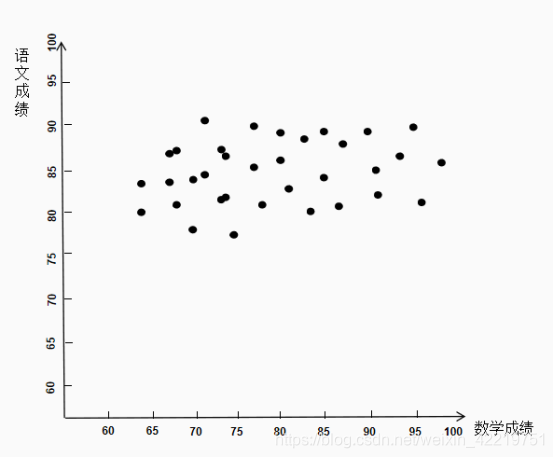
在这种情况下,没有办法找到一个坐标轴使全部点落在坐标轴上。如果仍只用一个指标来描述学生成绩,现在有1、2、3这三条线,哪一个更适合。
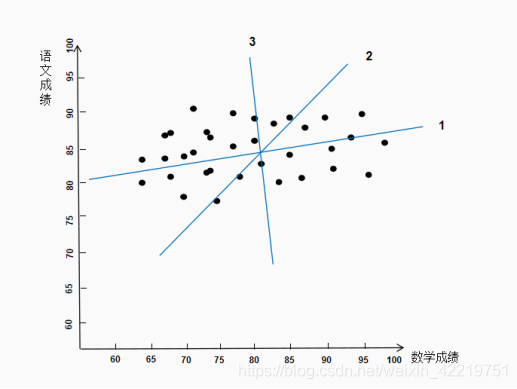
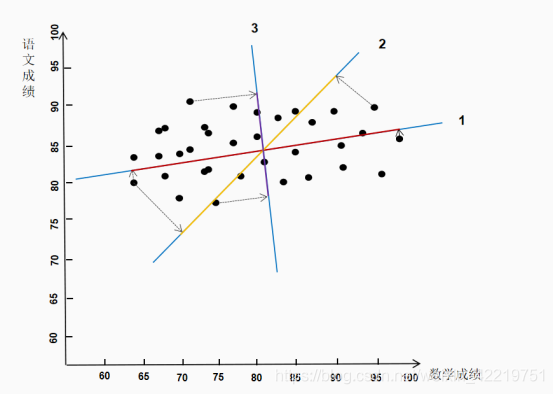
很显然,线1最适合。因为所有原始数据在线1上的投影最长(红色部分),样本总体变异方向最大。如果坐标轴变化为2和3,原始数据的信息损失的更多。既然都会损失,我们要选择损失最少的部分。
4.用途
主成分分析法主要的用途是将原始多维数据在损失最小的情况下降维成低维数据,一般多与其他算法和模型结合使用进行预测或评价。比如:多因子模型、财务状况评价、桥体结构损伤、各省经济状况评价等。
二、主成分分析基本流程
1.原始数据标准化
原始数据往往数量级差异很大,大到100000,小到0.001。量纲的差距使得后续计算时会出现较大的差异,因此在进行主成分分析之前,需要对原始数据进行标准化。
最常用的标准化方法为:Z-score方法。
X s t d = X − X ˉ σ X_{std}=\frac{X-\bar{X}}{\sigma} Xstd=σX−Xˉ
2.计算协方差矩阵
根据上述例子可知,通过旋转坐标轴可以使数据在新的坐标轴上分散最开,即方差最大。能够将数据的方差表示出来的方法就是求协方差矩阵,计算方法如下式。
C = 1 n F T F C=\frac{1}{n}F_TF C=n1FTF
3.求特征值和特征向量
求解特征值和特征向量,用于后续主成分个数选择。
C ζ = Σ ζ C\zeta=\Sigma\zeta Cζ=Σζ
其中C为协方差矩阵, ζ \zeta ζ为特征向量, Σ \Sigma Σ 为特征值。
4.主成分个数选择
分析 C ζ = Σ ζ C\zeta=\Sigma\zeta Cζ=Σζ,其中X为数值, ζ \zeta ζ为向量。这种变化过程体现了原始数据的线性变化过程。特征向量为线性变换的规则和程度,特征值表示各个角度的方差。主成分选取有多重标准,最常用的为累计贡献率准则:当前K个主成分的累计贡献率超过95%,这时主成分的个数为K个。
5.计算主成分得分
将归一化后的原始数据矩阵F右乘特征向量矩阵后能够得到得分矩阵,可表示为下式。
Y i = F 1 u 1 m + F 2 u 2 m + . . . + F n u n m Y_i=F_1u_{1m}+F_2u_{2m}+...+F_nu_{nm} Yi=F1u1m+F2u2m+...+Fnunm
Y i Y_i Yi表示第i个主成分,得到的主成分可依次命名为“主成分1”、“主成分2”,代替原有数据。
三、基于主成分分析法的上市公司财务评价
1. 样本选取
本文选取证监会二级行业为:汽车制造业的上市公司进行分析,共计158个上市公司,去掉B股共141支股票。
2. 指标选取
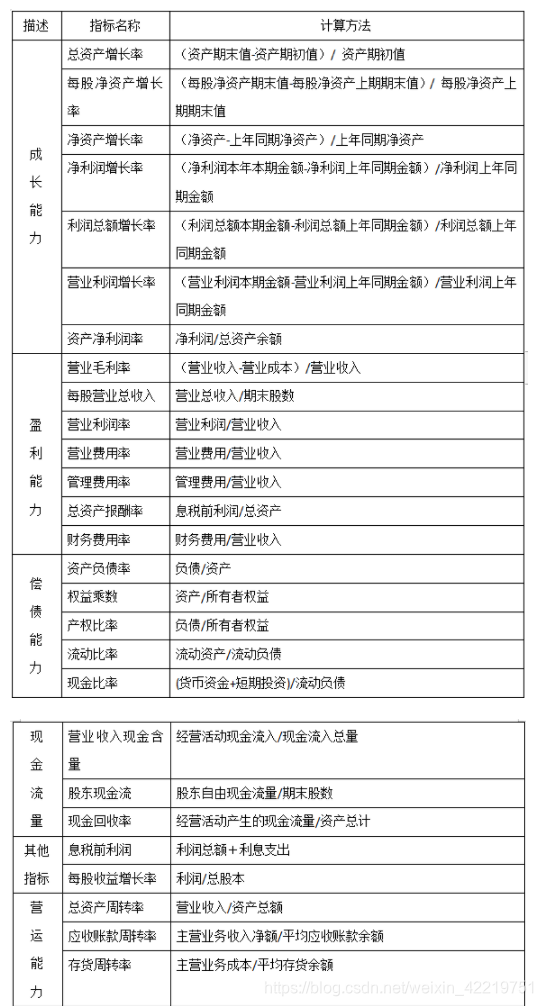
3.构建策略
第一步:获取原始数据(共27个因子)
第二步:进行主成分分析并降维(降维后共有15个主成分)
第三步:设定因子权重,计算个股得分
第四步:选取得分排名前20的股票买入
4.回测结果
回测期:2019年11月1日-2020年11月10日
初始资金:100万
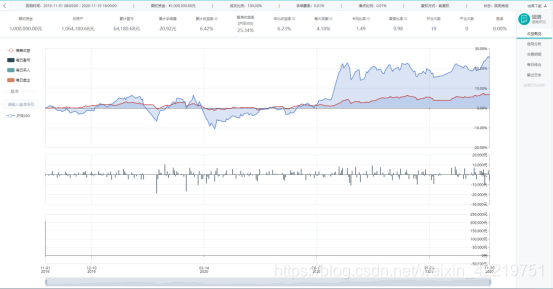
回测期收益率为6.42%,年化收益率为6.23%,沪深300收益率为25.34%。策略最大回撤为4.18%。
四、回测代码
注:本策略编写基于掘金量化平台,网址为:掘金量化社区
# coding=utf-8
from __future__ import print_function, absolute_import
from gm.api import *
import pandas as pd
import numpy as np
from sklearn.decomposition import PCA
# 策略中必须有init方法
def init(context):
# 获取成分股
context.symbol = list(set(get_industry(code='C36')))
# 特征值置信度
context.prob = 0.95
# 股票池个数
context.num = 20
# 每月第一个交易日运行一次
schedule(schedule_func=algo, date_rule='1d', time_rule='09:50:00')
def algo(context):
# 获取数据
original_data = get_original_data(context.now.date(),context)
# 数据初始化
factors = original_data.iloc[:,3:]
factors = (factors - factors.mean(axis=0))/factors.std(axis=0)
factors = factors.fillna(0)
# 进行主成分分析
pca = PCA(n_components=20) # 先保留20个主成分,按照方差贡献度进行裁剪
pca.fit(factors)
explain = list(pca.explained_variance_ratio_) # 方差解释
# 选择主成分
attr = 0
for i in range(len(explain)):
attr += explain[i]
if attr >= context.prob:
print('选取%s个主成分,贡献度为%s' %(i+1, attr))
# 对原始数据降维
pca = PCA(n_components=i+1)
pca.fit(factors)
data = pca.fit_transform(factors) # 降维后数据
# 计算个股得分:默认权重为1
score = np.sum(data,axis=1)
score = pd.DataFrame({
'symbol':original_data['symbol'].tolist(),'score':score})
score.sort_values('score',ascending=False)
choose = score['symbol'][0:context.num].tolist()
break
# 获取当前所有仓位
positions = context.account().positions()
# 平不在标的池内仓位
for position in positions:
symbol = position['symbol']
if symbol not in choose:
# 买入选出的股票
order_target_volume(symbol=symbol, volume=0, order_type=OrderType_Market,
position_side=PositionSide_Long)
print('平不在标的池内标的')
# 买入选中标的
for symbol in choose:
order_target_volume(symbol=symbol, volume=1000, position_side=PositionSide_Long, order_type=OrderType_Market)
print('买入选中标的')
def get_original_data(time,context):
# 获取原始数据
# 直接有的比率
data1 = get_fundamentals_n(table='deriv_finance_indicator', symbols=context.symbol, count=1,
end_date=time,
fields='ASSLIABRT,ACCRECGTURNRT,CASHRT,CURRENTRT,EBIT,EM,EQURT,FCFEPS,INVTURNRT,MGTEXPRT,OPICFTOTICF,OPPRORT,ROA,TATURNRT,OPPRORT,NAPSNEWP,FINLEXPRT,OPEXPRT,TOPREVPS',
df=True)
data1.sort_values(by='symbol', ascending=True)
# 计算总资产增长率、净资产增长率
data2 = get_fundamentals_n(table='balance_sheet', symbols=context.symbol, count=5,
end_date=time, fields='TOTASSET,TOTLIABSHAREQUI', df=True)
data2.sort_values(by=['symbol', 'end_date'])
asset_growth = (data2.groupby('symbol').first()['TOTASSET'] - data2.groupby('symbol').last()['TOTASSET']) /
data2.groupby('symbol').last()['TOTASSET']
net_asset_growth = (data2.groupby('symbol').first()['TOTLIABSHAREQUI'] - data2.groupby('symbol').last()[
'TOTLIABSHAREQUI']) / data2.groupby('symbol').last()['TOTLIABSHAREQUI']
# 计算净利润增长率、利润总额增长率、营业利润增长率
data3 = get_fundamentals_n(table='income_statement', symbols=context.symbol, count=5,
end_date=time,
fields='NETPROFIT,TOTPROFIT,PERPROFIT', df=True)
data3.sort_values(by=['symbol', 'end_date'])
net_profit_growth = (data3.groupby('symbol').first()['NETPROFIT'] - data3.groupby('symbol').last()['NETPROFIT']) /
data3.groupby('symbol').last()['NETPROFIT']
profit_total = (data3.groupby('symbol').first()['TOTPROFIT'] - data3.groupby('symbol').last()['TOTPROFIT']) /
data3.groupby('symbol').last()['TOTPROFIT']
profit_growth = (data3.groupby('symbol').first()['PERPROFIT'] - data3.groupby('symbol').last()['PERPROFIT']) /
data3.groupby('symbol').last()['PERPROFIT']
# 计算资产净利润
net_profit_asset = data3.groupby('symbol').first()['TOTPROFIT'] / data2.groupby('symbol').first()['TOTASSET']
# 计算每股净资产增长率
data4 = get_fundamentals_n(table='deriv_finance_indicator', symbols=context.symbol, count=2,
end_date=time, fields='NAPSNEWP', df=True)
nps_growth = (data4.groupby('symbol').first()['NAPSNEWP'] - data4.groupby('symbol').last()['NAPSNEWP']) /
data4.groupby('symbol').last()['NAPSNEWP']
# 计算每股收益增长率
data5 = get_fundamentals_n(table='prim_finance_indicator', symbols=context.symbol, count=1,
end_date=time, fields='EPSBASIC', df=True)
# 将计算好的数据汇总,合并到总表中
cal = pd.DataFrame({
'symbol': asset_growth.index,
'asset_growth': asset_growth.values,
'net_asset_growth': net_asset_growth.values,
'net_profit_growth': net_profit_growth.values,
'profit_total': profit_total.values,
'profit_growth': profit_growth.values,
'net_profit_asset': net_profit_asset.values,
'nps_growth': nps_growth.values,
'eps': data5['EPSBASIC']})
# 合并到主表中
data = pd.merge(data1, cal, on='symbol', how='left')
return data
if __name__ == '__main__':
'''
strategy_id策略ID, 由系统生成
filename文件名, 请与本文件名保持一致
mode运行模式, 实时模式:MODE_LIVE回测模式:MODE_BACKTEST
token绑定计算机的ID, 可在系统设置-密钥管理中生成
backtest_start_time回测开始时间
backtest_end_time回测结束时间
backtest_adjust股票复权方式, 不复权:ADJUST_NONE前复权:ADJUST_PREV后复权:ADJUST_POST
backtest_initial_cash回测初始资金
backtest_commission_ratio回测佣金比例
backtest_slippage_ratio回测滑点比例
'''
run(strategy_id='strategy_id',
filename='main.py',
mode=MODE_BACKTEST,
token='token',
backtest_start_time='2019-01-01 08:00:00',
backtest_end_time='2020-11-01 16:00:00',
backtest_adjust=ADJUST_PREV,
backtest_initial_cash=1000000,
backtest_commission_ratio=0.0001,
backtest_slippage_ratio=0.0001)