【本文正在参与炫"库"行动-人大金仓有奖征文】
活动链接:
一、k8s基本概念
Kubernetes(简称k8s)是Google在2014年6月开源的一个容器集群管理系统,使用Go语言开发,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效,Kubernetes提供了资源调度、部署管理、服务发现、扩容缩容、监控,维护等一整套功能。,努力成为跨主机集群的自动部署、扩展以及运行应用程序容器的平台。 它支持一系列容器工具, 包括Docker等。
Kubernetes一个核心的特点就是自动化,能够自主的管理容器来保证云平台中的容器按照用户的期望状态运行着(比如用户想让apache一直运行,用户不需要关心怎么去做,Kubernetes会自动去监控,然后去重启,新建,总之,让apache一直提供服务),管理员可以加载一个微型服务,让规划器来找到合适的位置,同时,Kubernetes也系统提升工具以及人性化方面,让用户能够方便的部署自己的应用(就像canary deployments)。
大体执行流程
用户执行kubectl/userClient向apiserver发起一个命令,经过认证授权后,经过scheduler的各种策略,得到一个目标node,然后告诉apiserver,apiserver 会请求相关node的kubelet,通过kubelet把pod运行起来,apiserver还会将pod的信息保存在etcd;
pod运行起来后,controllermanager就会负责管理pod的状态,如,若pod挂了,controllermanager就会重新创建一个一样的pod,或者像扩缩容等;pod有一个独立的ip地址,但pod的IP是易变的,如异常重启,或服务升级的时候,IP都会变,这就有了service;
完成service工作的具体模块是kube-proxy;在每个node上都会有一个kube-proxy,在任何一个节点上访问一个service的虚拟ip,都可以访问到pod;service的IP可以在集群内部访问到,在集群外呢?service可以把服务端口暴露在当前的node上,外面的请求直接访问到node上的端口就可以访问到service了。
架构图:

二、各组件详细介绍:
Master:
k8s的主控组件,对应的对象是node。
k8s的master节点上有三个进程,它们都是以docker的形式存在的。我们在k8s的master节点看docker ps 就可以看到这几个进程:kube-apiserver、kube-controller、kube-scheduler。
其中的 apiserver 是提供 k8s 的 rest api 服务的进程。当然它也包括了 restapi 的权限认证机制。 k8s 的 apiserver 提供了三种权限认证机制:
- https
- http + token
- http + base(username + password)
Pod
在Kubernetes集群中,Pod是所有业务类型的基础,也是K8S管理的最小单位级,它是一个或多个容器的组合。这些容器共享存储、网络和命名空间,以及如何运行的规范。在Pod中,所有容器都被同一安排和调度,并运行在共享的上下文中。对于具体应用而言,Pod是它们的逻辑主机,Pod包含业务相关的多个应用容器。
Kubelet
kubelet处理着master和在其上运行的节点之间的所有通信。它以manifest的形式接收来自主设备的命令,manifest定义着工作负载和操作参数。它与负责创建、启动和监视pod的容器运行时进行接合。
kube-proxy
kube-proxy组件在每个节点上运行,负责代理UDP、TCP和SCTP数据包(它不了解HTTP)。它负责维护主机上的网络规则,并处理pod、主机和外部世界之间的数据包传输。它就像是节点上运行着的pod的网络代理和负载均衡器一样,通过在iptables使用NAT实现东/西负载均衡。
RC
Replication Controller (简称RC),RC是Kubernetes系统中的核心概念之一,简单来说,它定义了一个期望的场景,即声明某种Pod的副本数量在任意时刻都符合某个预期值
Volume
容器和 Pod 是短暂的。其含义是它们的生命周期可能很短,会被频繁地销毁和创建。容器销毁时,保存在容器内部文件系统中的数据都会被清除。为了持久化保存容器的数据,可以使用 Kubernetes Volume。Volume 的生命周期独立于容器,Pod 中的容器可能被销毁和重建,但 Volume 会被保留。本质上,Kubernetes Volume 是一个目录,这一点与 Docker Volume 类似。当 Volume 被 mount 到 Pod,Pod 中的所有容器都可以访问这个 Volume。Kubernetes Volume 也支持多种 backend 类型,包括 emptyDir、hostPath、GCE Persistent Disk、AWS Elastic Block Store、NFS、Ceph 等。Volume 提供了对各种 backend 的抽象,容器在使用 Volume 读写数据的时候不需要关心数据到底是存放在本地节点的文件系统中呢还是云硬盘上。对它来说,所有类型的 Volume 都只是一个目录。
Volume之emptyDir
emptyDir 是最基础的 Volume 类型。正如其名字所示,一个 emptyDir Volume 是 Host 上的一个空目录。
Volume之hostPath
hostPath Volume 的作用是将 Docker Host 文件系统中已经存在的目录 mount 给 Pod 的容器。大部分应用都不会使用 hostPath Volume,因为这实际上增加了 Pod 与节点的耦合,限制了 Pod 的使用。不过那些需要访问 Kubernetes 或 Docker 内部数据(配置文件和二进制库)的应用则需要使用 hostPath。
Etcd
Etcd是一个高可用的键值存储系统,主要用于共享配置和服务发现,它通过Raft一致性算法处理日志复制以保证强一致性,我们可以理解它为一个高可用强一致性的服务发现存储仓库。在kubernetes集群中,etcd主要用于配置共享和服务发现Etcd主要解决的是分布式系统中数据一致性的问题,而分布式系统中的数据分为控制数据和应用数据,etcd处理的数据类型为控制数据,对于很少量的应用数据也可以进行处理。
Etcd集群中的术语
Raft: etcd所采用的保证分布式系统强一致的算法
Node: 一个Raft状态机实例
Member: 一个etcd实例,管理一个Node,可以为客户端请求提供服务
Cluster: 多个Member构成的可以协同工作的etcd集群
Peer: 同一个集群中,其他Member的称呼
Client: 向etcd集群发送HTTP请求的客户端
WAL: 预写日志,是etcd用于持久化存储的日志格式
Snapshot: etcd防止WAL文件过多而设置的快照,存储etcd数据状态
Proxy: etcd的一种模式,可以为etcd提供反向代理服务
Leader: Raft算法中通过竞选而产生的处理所有数据提交的节点
Follower: Raft算法中竞选失败的节点,作为从属节点,为算法提供强一致性保证
Candidate: Follower超过一定时间接收不到Leader节点的心跳的时候,会转变为Candidate(候选者)开始Leader竞选
Term: 某个节点称为Leader到下一次竞选开始的时间周期,称为Term(任界,任期)
Index: 数据项编号, Raft中通过Term和Index来定位数据
Flannel
是一种 CNI 解决方案,也可以为 Dokcer 提供服务,对 k8s 而言,是一个网络插件。实现了 CNI 的网络控制平面软件属于 coreOS 的子项目
通过配置主机路由或者 overlay,避免对物理路由器进行配置VxLANUDPHost-GW和 k8s 集成时,运行在 work node 上面,监听 k8s master 的状态,共用 k8s 的控制节点的 etcd 作为自己的数据库。
三、自动化部署(单节点伪分布式集群)
环境信息
操作系统:CentOS 7(最小化)、内存2G/硬盘30G以上
配置: 基础网络、更新源、SSH登录等
下载文件
开源代码下载链接:https://codeload.github.com/easzlab/kubeasz/zip/refs/heads/master
将两个脚本拷贝到环境上

使用ezdown下载依赖
默认下载最新推荐k8s/docker等版本(更多关于ezdown的参数,运行./ezdown 查看)
./ezdown -D
上述脚本运行成功后,所有文件(kubeasz代码、二进制、离线镜像)均已整理好放入目录/etc/kubeasz

安装集群
容器化运行 kubeasz,详见ezdown 脚本中的 start_kubeasz_docker 函数
./ezdown -S
使用默认配置安装 aio 集群
docker exec -it kubeasz ezctl start-aio

然后等待各种自动化配置结束
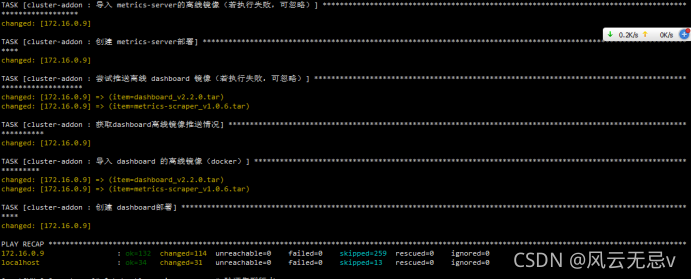
验证安装k8s
kubectl version
# 验证集群版本

kubectl get node
# 验证节点就绪 (Ready) 状态
![]()
kubectl get pod -A
# 验证集群pod状态,默认已安装网络插件、coredns、metrics-server等

kubectl get svc -A
# 验证集群服务状态

集群搭建成功!
helm3安装:
wget https://get.helm.sh/helm-v3.2.4-linux-amd64.tar.gz

tar -zxvf helm-v3.2.4-linux-amd64.tar.gz
mv ./linux-amd64/helm /usr/bin
helm version
![]()
启用阿里云 charts 仓库
helm repo add apphub https://apphub.aliyuncs.com/
![]()
helm安装成功!
三、自动化部署(三节点高可用集群)
节点是poxos算法的实现需要奇数个节点,最小为三个节点。
三个节点的环境准备
操作系统:CentOS 7(最小化)、内存2G/硬盘30G以上
配置: 基础网络、更新源、SSH登录等
使用python2.7安装ansible
yum update

# 安装python
yum install python -y

# 注意pip 21.0以后不再支持python2和python3.5,需要如下安装
# To install pip for Python 2.7 install it from https://bootstrap.pypa.io/2.7/ :
curl -O https://bootstrap.pypa.io/pip/2.7/get-pip.py
python get-pip.py
python -m pip install --upgrade "pip < 21.0"
(网速慢下来不下来用下面这种)
python get-pip.py -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
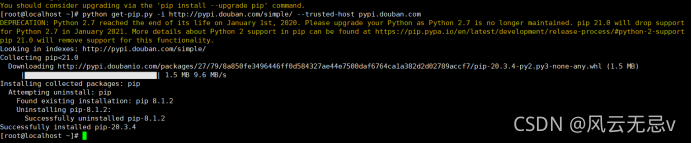
# pip安装ansible(国内如果安装太慢可以直接用pip阿里云加速)
pip install ansible -i Simple Index

ssh免密登录
# 更安全 Ed25519 算法
ssh-keygen -t ed25519 -N '' -f ~/.ssh/id_ed25519
# 或者传统 RSA 算法
ssh-keygen -t rsa -b 2048 -N '' -f ~/.ssh/id_rsa
ssh-copy-id $IPs #$IPs为所有节点地址包括自身,按照提示输入yes 和root密码
下载所需要的依赖:
chmod +x ./ezdown
./ezdown -D
上述脚本运行成功
 后,所有文件(kubeasz代码、二进制、离线镜像)均已整理好放入目录/etc/kubeasz
后,所有文件(kubeasz代码、二进制、离线镜像)均已整理好放入目录/etc/kubeasz

创建集群配置实例:
./ezctl new k8s-01

vi /etc/kubeasz/clusters/k8s-01/hosts
将所有的ip改成自己的集群的ip
/etc/kubeasz/clusters/k8s-01/config.yml
可以使用默认配置不对其进行修改
根据配置进行安装(自动化)
ezctl setup k8s-01 all

自动部署成功!
各节点验证安装:
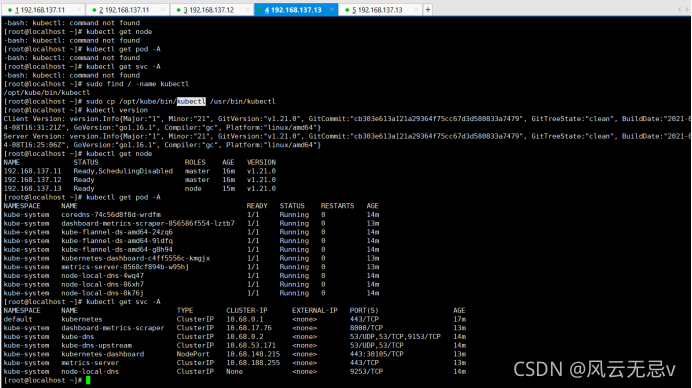
三节点直接搭建成功!
【本文正在参与炫"库"行动-人大金仓有奖征文】
活动链接:CSDN