第一部分 基础管理
前言
分成了四大块:基础管理、连网、存储、运维。
第一章 入手
P15
判断软件是否已经安装
(1)which gcc
(2)whereis
(3)locate,locate可以查找任何类型的文件,并不仅限于命令或者软件包。
(4)rpm
- rpm -q python
- 找出特定的文件属于哪个软件包:rpm -qf /etc/httpd
curl命令
参数:
-o/--output 把输出写到该文件中
-L 对页面进行重定向,主要用在请求的页面移动到别的站点的情况下。
curl -L 跟随跳转,加上-v 就可以看见详细信息;
第二章 引导与系统管理守护进程
1、引导
现在大多数的Linux发行版都用系统管理守护进程(system manager daemon),systemd替代了UNIX中传统的init。
systemd通过添加依赖管理、并发启动进程支持以及全面的日志记录等特性简化了引导过程。
1、主机加电自检,加载 BIOS 硬件信息,BIOS进行系统检测。
2、读取 MBR 的引导文件(GRUB、LILO)。
3、引导 Linux 内核。
4、由内核启动运行第一个进程 init (进程号永远为 1 )。(会去读取inittab文件,执行rc.sysinit,,rc文件 /etc/rc.d/rc.local等脚本)
5、进入相应的运行级别
6、运行终端,输入用户名和密码。
init需要执行的任务(命令和脚本)例如有:
- 设置计算机名;
- 设置时区;
- 使用fsck检查磁盘;
- 挂载文件系统
- 删除/tmp 目录中的陈旧文件
- 配置网络接口
- 配置分组过滤器
- 启动其他守护进程和网络服务
在传统的init世界中,系统模式(例如单用户或多用户)叫作“运行级”(run level),但init系统缺少一个能够描述服务之间依赖关系的 通用模型,因而所有的启动脚本和卸载脚本只能以串行方式运行。
systemd目标在于实现系统管理方面的标准化,除了以并行方式管理进程,还负责管理网络连接(networkd)、内核日志记录(journald)、用户登录(logind)。
2、systemd
P32
systemd所管理的实体通常称作单元(unit)。具体来说,一个单元可以是“服务、套接字、设备、挂载点、自动挂载点、交换分区或分区等”。
在systemd中,单元的行为由单元文件定义并配置。就服务而言,其单元文件指定了守护进程对应的可执行文件的位置、告诉systemd如何启动和停止该服务、声明该服务所依赖的其他单元。
举例:单元文件名为rsync.service,负责处理启动用于文件系统同步的rsync守护进程。
[Unit]
Description=fast remote file copy program daemon
ConditionPathExists=/etc/rsyncd.conf
[Service]
ExecStart=/usr/bin/rsync --daemon --no-detach
[Install]
WantedBy=multi-user.target
单元文件可以出现在多个位置。软件包在安装过程中将/usr/lib/systemd/system 作为存放其单元文件的主要位置,在有些系统中,这个位置是/lib/systemd/system。你可以把目录中的内容视为库存(stock),不要修改其中的内容。本地单元文件以及自定义配置可以放在/etc/systemd/system。除此之外,/run/systemd/system中的单元目录可以作为过渡单元(transient units)的暂存区。
systemd以一种宏观角度看待这些目录,所以目录之间都是平等的关系。如果有什么冲突,则/etc中的文件拥有最高的优先级。
按照惯例,单元文件在命名时回加上一个后缀,这个后缀会根据所配置的单元类型发生变化。例如,服务单元的后缀是.service,计时器单元的后缀是.timer。在单元文件中,有些区块(section),如[Unit]适用于所有单元,而有些区块,如[Service]仅出现在特定单元类型中。
3、systemctl:管理systemd
运行systemctl时如果不使用任何参数,会默认调用list-units子命令,显示出所有已装载且处于活动状态的服务、套接字、目标、挂载点、设备。如果只想显示服务,使用–type=service限定选项。
systemctl list-units --type=service
有时还需要查看所有已安装的单元文件,不管其是否处于活动状态。
systemctl list-unit-files --type=service

查看单元状态
systemctl status -l cpus
末尾可以看到最近的日志条路,在默认情况下,日志条目会压缩,使得每条日志只占一行。因此使用 -l 选项要求显示完整的条目。
!$:表示上一次使用的路径。
cd !$:就是进入上一次使用的路径如:
#ls /usr/local/src/
#cd !$(也就是进入:cd /usr/local/src目录中)
4、systemd日志
systemd的日志管理机制,由journald守护进程负责。journald将捕获的系统消息保存在目录 /run 中。rsyslog能够处理这些消息并将其存储在传统日志文件或是转发到远程syslog服务器。 同时也可以使用 journalctl 命令直接访问这些日志。
如果不使用参数,journalctl会显示出所有的日志项。
选项-u 可以限制只记录特定单元的日志。
journalctl -u ntp
5、系统无法引导
解决方法基本上有3种
- 不调试,只是将系统恢复到已知的良好状态
- 使系统足以运行一个shell,然后进行交互式调试
- 引导另一个系统镜像,挂载故障系统的文件系统并以此展开检查
“引导到shell(boot to shell)”这种做法通常叫作单用户模式或救援模式。

出现GRUB启动画面时,选中需要的内核并按下e键,编辑引导选项。在已有的Linux内核项末尾加上systemd.unit=rescue.target就可以进入救援模式。与此类似,对于紧急模式则systemd.unit=emergency.target。
单用户模式(在采用了systemd的系统中叫作rescue.target)只启动了最小数量的进程、守护进程和服务。根文件系统会被挂载(大多数情况下还包括 /usr),但并不初始化网络。
如果系统处于运行状态,可以使用systemctl(systemd)命令进入单用户模式:
systemctl isolate rescue.target
这个子命令之所以叫作isolate,是因为它会激活指定的目标及其依赖,同时停止其他单元。
在很多单用户环境中,文件系统的根目录一开始就说以只读模式挂载的。如果/etc 是根文件系统的一部分(通常如此),则无法编辑任何重要的配置文件。要解决这个问题,必须在单用户会话中以 读/写 模式重新挂载。
mount -o rw,remount / 或者 mount -o rw /dev/gpt/rootfs /
第三章 访问控制与超级权限
su 的一般使用方法是:
su <user_name>
或者
su - <user_name>
两种方法只差了一个字符 -,会有比较大的差异:
- 如果加入了 - 参数,那么是一种 login-shell 的方式,意思是说切换到另一个用户 <user_name> 之后,当前的 shell 会加载 <user_name> 对应的环境变量和各种设置;
- 如果没有加入 - 参数,那么是一种 non-login-shell 的方式,意思是说我现在切换到了 <user_name>,但是当前的 shell 还是加载切换之前的那个用户的环境变量以及各种设置。
1.典型设
置
90% sudoers文件类似于下面这样。
User_Alias ADMINS = alice, bob, charles
ADMINS ALL = (ALL) ALL
- 第一个ALL是指网络中的主机
- 第二个括号里的ALL是指目标用户,也就是以谁的身份去执行命令。
- 最后一个ALL当然就是指命令名了。
2.环境管理
sudo的默认行为是只给要运行的命令传递一个净化过的(sanitized)最小环境。如果需要额外的环境变量,可以将其添加到sudoers文件的env_keep列表中,实现白名单的效果。
例如,下面两行配置保留了X Window和SSH密钥转发需要用到的一些环境变量。
Defaults env_keep += "SSH_AUTH_SOCK"
Defaults env_keep += "DISPLAY XAUTHORIZATION XAUTHORITY"
可以为不同的用户或组设置不同的env_keep列表。
3.无须密码的sudo
这种做法仅作为参考,可以将sudo设置成不需要输入密码就能够以root身份执行命令。在sudoers文件中使用NOPASSWD关键字是可以实现这种效果。
ansible ALL = (ALL) NOPASSWD: ALL # Dont't do this
最好是通过时SSH密钥来代替手动输入密码。
4.优先级
一个sudo命令可能会匹配到sudoers文件中的多条规则。考虑下面的配置。
User_Alias ADMINS alice, bob, charles
User_Alias MYSQL_ADMINS = alice, bob
%wheel ALL = (ALL) ALL
MYSQL_ADMINS ALL = (mysql) NOPASSWD: ALL
ADMINS ALL = (ALL) NOPASSWD: /usr/sbin/logrotate
在这里,管理员可以和其他用户一样不用听过密码就可以执行logrotate命令。 MySQL管理员不需要密码就能够以mysql的身份执行所有命令。wheel组的用户可以执行所有用户的命令,但必须先用密码通过认证。
如果用户alice属于wheel组,那么最后3行中的条件她都可以满足。
然而规则就是:sudo的行为总是服从所匹配到的最后一行。是否匹配是由包括用户、主机、目标用户和命令在内的4元组决定的。 配置行中的每个元素都必须匹配,否则直接忽略该行。
第四章 进程控制
1、进程
进程
- 进程是资源分配的最小单位,线程是CPU调度的最小单位。(进程是一个可以拥有资源的独立单位、可以独立调度和分派的基本单位。线程是计算机中执行任务的最小单元:线程。 )
- 内存分配:同一进程的线程共享本进程的地址空间和资源,而进程之间的地址空间和资源是相互独立的。
- 执行过程:但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制
- 影响关系:一个进程崩溃后,在保护模式下不会对其他进程产生影响,因为进程有自己独立的地址空间,但是多线程程序只要有一个线程崩溃整个进程都死掉。所以多进程要比多线程健壮。
线程是进程中的执行上下文。进程至少有一个线程,而有些进程可以有多个。每个线程都有自己的栈和CPU上下文,但只能在所属进程的地址空间内操作。
父进程:进程复制完之后,原先的进程叫作父进程,复制出的副本叫作子进程。
进程的生命周期
- 进程可以通过fork系统调用来创建一个新进程。fork会生成一个原进程的父本,该父本基本上和父进程一模一样。新进程拥有自己的PID以及统计信息。
- fork可以返回两个不同的值,这算是一个独特的特性。对于子进程,返回值是0;对于父进程,返回值是新创建的子进程的PID。 除此之外,父子进程没有任何差别,两者必须各自检查返回值,确定自己究竟是什么身份。
- fork调用结束后,子进程一般会使用exec系统调用中的某个调用来执行新程序。这些调用会改变进程当前所执行的程序,将内存布局重置为初始状态。各种exec调用的差别仅在于为新程序指定命令行参数和环境的形式。
- init(或systemd)在进程管理中还扮演着另一个重要角色。当进程完成后会调用名为_exit的例程,提醒内核它已经结束了。该进程会提供一个退出码(整数),表明退出的原因。习惯上用0表示正常或“顺利”终止。
- 在死亡进程(death process)完全消失之前,内核要求该进程的死讯得到其父进程的确认,父进程采用的方法是调用wait。它会接收到子进程退出码的父本(如果子进程并非自愿退出,则接收到的是一个表明其终止原因的提示),如果需要的话,还可以得到子进程所使用资源的汇总信息。
- 如果父进程的生存期在其子进程之前挂了,内核会意识到以后不会再有wait了,因此就会做出相应的调整,让这些孤儿进程成为init或systemd的子进程,后者会在子进程结束后调用wait清理它们。
2、信号
信号
信号是进程级的中断请求。一共大概有30种不同的信号,使用方法各异。如组合键(Control-C和Control-Z),使用kill等。
当接收到信号时,会出现两种情况
- 如果收到信号的进程已经为信号指派了信号处理程序,则使用投递该信号的上下文信息调用信号处理程序。
- 否则,内核会代表进程执行默认操作。每个信号的默认操作各不相同,很多信号会终止进程,有些还会生成内存转储(内存内容以八或十六进制形式记录到磁盘文件)。
指定信号处理程序叫作捕获信号。处理程序执行完毕后,进程会从接收到信号的位置继续往下运行。
如果不想接收信号,程序可以请求忽略或阻塞信号。
- 被忽略的信号会直接丢弃,对进程没有任何影响。
- 被阻塞的信号会排队等待投递,不过内核并不要求对其做出什么反应,直到明确解除信号的阻塞。
- 对于刚解除阻塞的信号,不管其在阻塞期间被接收到了多少次,也只会调用一次相应的信号处理程序。
kill发送信号
kill -l 列出信号
- TERM信号请求完全终止运行。接收到该信号的进程应该清除状态信息并退出。
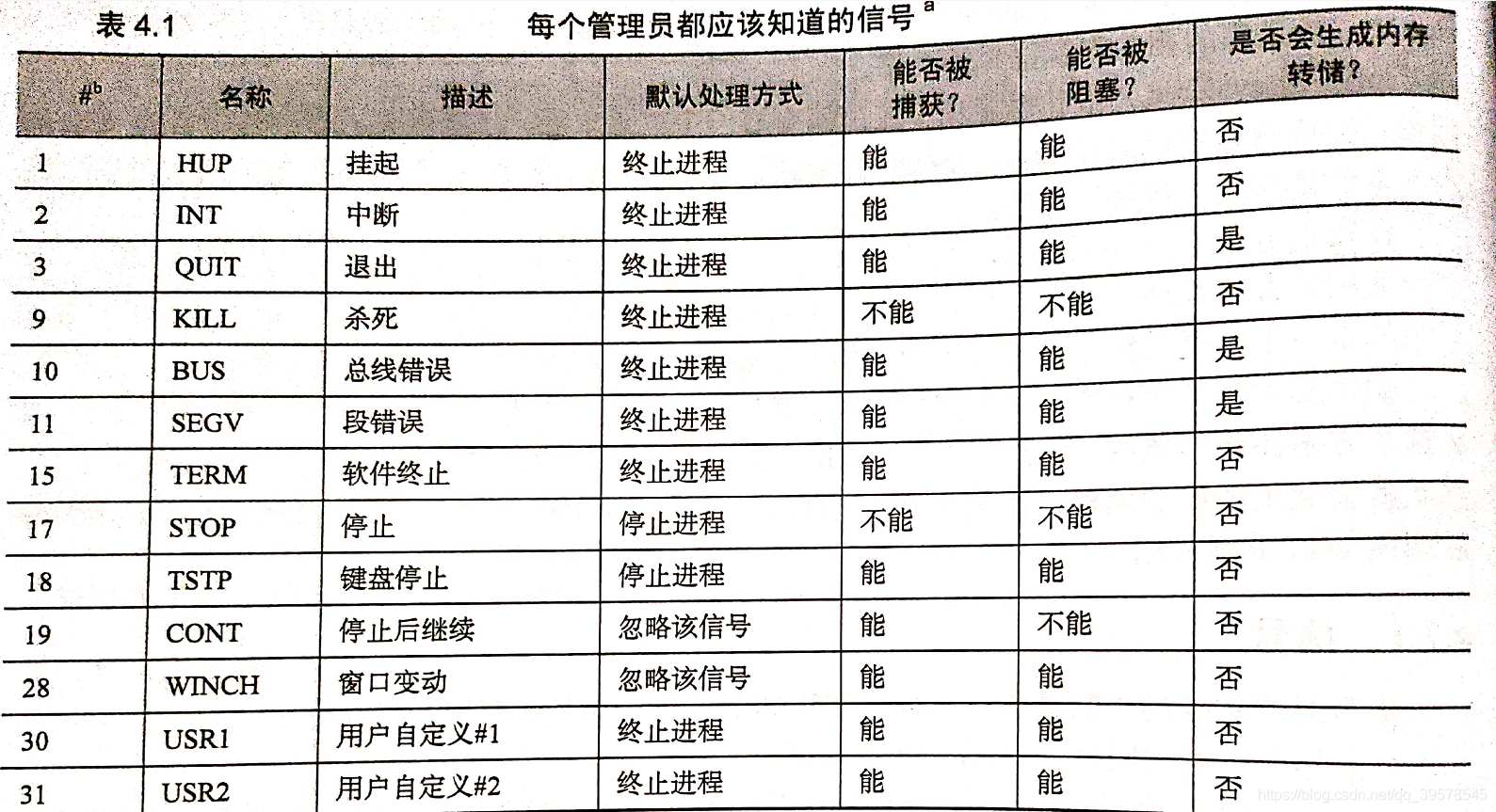
kill可以发送任意信号,如果不指定的话,默认发送的是TERM信号。普通用户可以对自己的进程使用kill,而root用户可以对所有进程使用。
不加信号编号的kill命令未必能够终止进程,因为TERM信号可以被捕获、阻塞或忽略。下列命令:
kill -9 pid
能够“保证”杀死指定进程,因为编号为9的信号KILL无法被捕获。仅在普通请求失败的情况下才使用kill -9,有些因为某些恶化的I/O虚锁,解决此类进程的唯一方法就是重启。
killall命令
按照名字杀死所有进程。如:杀死全部apache服务器进程
killall httpd
pkill命令
根据名字(或其他属性,例如EUID)搜索进程并发送指定信号。例如,下列命令将向用户ben所有进程发送TERM信号。
pkill -u ben
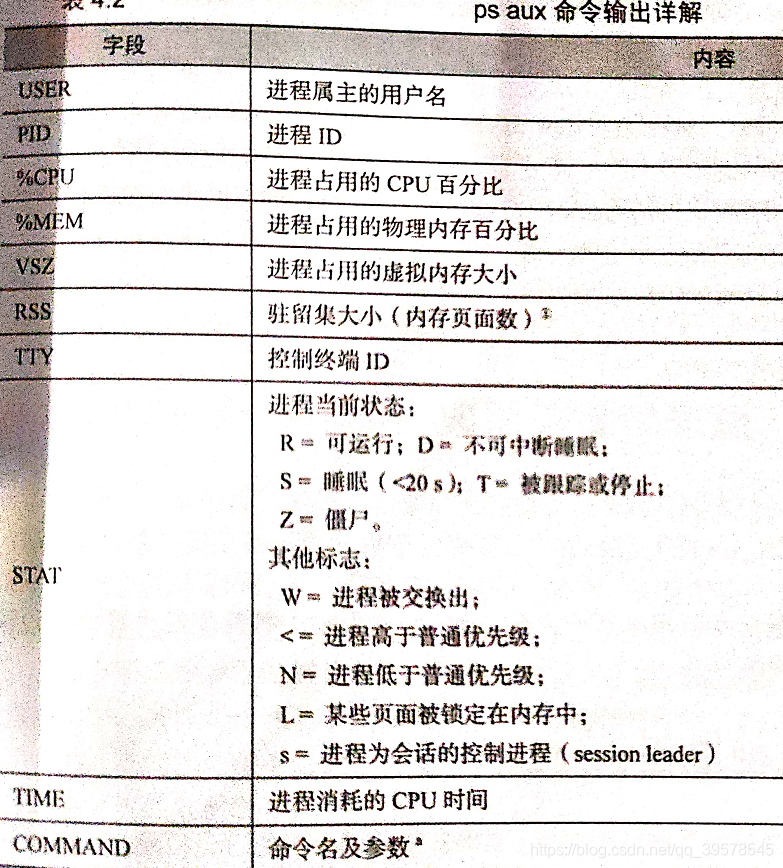
3、ps监视进程
ps能够显示出进程的PID、UID、优先级以及控制终端。它还会告诉你进程占用了多少内存、耗费了多少CPU时间、当前是什么状态(运行、停止、睡眠等)。僵尸进程在ps输出中会以exiting或defunct示人。
ps aux
-a选项,表示显示所有进程
-x选项,表示将没有控制终端的进程也显示出来
-u选项,表示选择 面向用户 的输出格式
-w选项,显示输出更多的内容
-ww选项,不再限制输出列宽,可以看到命令行参数奇长的进程(例如有些java程序)
-lax,在输出中包含了父进程ID,友善度(NI)以及进程等待的资源类型(WCHAN)
4、top动态监视进程
top运行时按下数字键1可以在单个的处理核心之间切换显示。
失控进程:指的是那些明显占用了比正常预期更多的CPU、磁盘、网络资源的进程。
在Linux下,使用top或ps检查总的CPU使用率,确定高平均负载是和CPU负载有关,还是和I/O有关。如果CPU使用率接近100%,这时可能就已经达到了系统瓶颈。
占用系统物理内存过多的进程会引发严重的性能问题。其中,top可以检查进程的内存使用情况。VIRT列显示了分配给每个进程的虚拟内存大小,RES列显示了目前被映射到内存页面中的部分(也就是“驻留集”),这两个数字中都包含了共享资源(例如库),因此有可能会造成误导

测试进程内存占用情况,更直接的方式是查看DATA列,这一列默认并不显示。要想显示出该列,可以在运行top时按下F键,从中选中DATA并按下空格键。DATA值指明了进程的数据段以及栈所占用的内存。
5、nice与renice:修改调度优先级
进程的友善度是一个数字形式的暗示,告诉内核该进程在和其他进程竞争CPU时应该如何处理。
友善度越高,意味着进程的优先级越低(谦让别的进程)。
如今手动设置优先级的情况已经极为罕见了。如今桌面级CPU的处理能力都是供大于求的,调度程序能够出色地管理大部分工作任务。Linux中可允许的友善值范围是 -20 ~ +19。
nice使用命令行作为参数,renice使用PID或(有时候)用户名作为参数。
$ nice -n 5 ~/bin/longtask // 降低5个优先级(提升友善度)
$ sudo renice -5 8829 // 将友善度设置为-5
$ sudo renice 5 -u boggs // 将boggs的进程优先级设置为5
6、/proc 文件系统
Linux版本的ps和top命令都会从 /proc 目录中读取进程的状态信息,该目录是一个伪文件系统,内核将各种系统状态信息都暴露于此。
因为/proc下的文件内容是由内核动态创建的(在读取的时候),在使用ls -l时,所列出的文件大多数显示的都是0字节。你只能使用cat或less命令查看其中到底有些什么。不过要小心,少数文件链接到或包含的是二进制数据,直接浏览的话,会把终端仿真程序给搞乱的。
7、strace:跟踪信号和系统调用。
系统调用跟踪是一件强大的调试工具。如果诸如检查日志、配置进程输出排错信息这类传统方法都用尽时,可以求助于这种手段。别被密密麻麻的跟踪信息吓到了,把注意力放在能读懂的部分通常就足够解决问题了。
strace命令
例如,下面的日志是使用strace跟踪top命令执行(其运行时的PID是5810)所得到的。strace -p 5810

8、周期性进程
cron介绍
cron的配置文件叫作crontab,日志文件是/var/log/cron,其中列出了执行过的命令及其实践。单个用户的crontab保存在/var/spool/cron下,每个用户只能有一个crontab文件。该文件是纯文本类型,以其所属用户的登录名作为文件名。cron使用文件名(以及文件所有权)决定使用哪个UID来运行配置文件中所包含的命令。crontab命令负责在配置文件目录中传递crontab文件。
其他crontab文件:
- /etc/crontab是一个由系统管理员手动维护的文件,/etc/cron.d就像是个仓库,
- Linux发行版还预先安装了一些crontab表项。例如,/etc/cron.hourly、/etc/cron.daily、/etc/cron.weekly。
cron尝试将花在冲洗你解析配置文件和计时方面的时间降低到最少。crontab命令会在crontab文件发生变化时提醒cron,以此提高cron的执行效率。因此,不要直接编辑crontab文件,这会导致cron注意不到你做出的改动。如果发现cron似乎对修改过的crontab文件没有反应,可以向cron进程发送HUP信号,强制其重新载入配置文件。
管理crontab:
- crontab -e 会生成现有crontab文件的副本并调用编辑器(环境变量EDITOR中指定的)打开,然后将其重新提交到crontab目录中。
- crontab -l 会在标准输出中列出crontab文件的当前内容
- crontab -r 会删除现有的crontab文件
root用户可以使用username参数来编辑或浏览其他用户的crontab文件。例如,crontab -r jsmith和crontab -e jsmith会分别删除和编辑用户jsmith的crontab文件。 - Linux允许再命令行中同时出现username和filename参数,为了避免混淆,一定要在用户名前加上-u(例如crontab -u jsmith crontab.new)
| 字段 | 描述 | 取值范围 |
|---|---|---|
| minute | 分钟 | 0~59 |
| hour | 小时 | 0~23 |
| dom | 月份中的天 | 1~31 |
| month | 月份 | 1~12 |
| weekday | 星期中的天 | 0~6 |
cron作业最小的调度粒度是1分钟。
crontab文件中的时间范围可以包含一个步进值。例如,序列0,3,6,9,12,15,18可以写成更简洁形式:0-18/3。
注意,weekday和dom字段有一个潜在的歧义。某一天既可以属于星期,也可以属于月份。如果同时指定了weekday和dom,只要这天能够满足其中一个条件就可以了。例如:
0,30 * 13 * 5
表示 星期五每隔半小时,也可以表示 每个月13号每隔半小时。但不表示 既是13号又是星期五的那天每隔半小时。
百分号(%)表示command字段中的换行。只有第一个百分号之前的内容才被视为命令,行中余下的部分作为命令的标准输入。如果命令中含有特殊含义的百分号(例如:date +%s),可以使用反斜线(\)作为转义字符。
尽管要调用sh来执行command,但该shell并非作为登录的shell,因此不会去读取~/.profile或~/.bash_profile。如果有需要,完全可以把命令放进脚本,在脚本中设置好适合的环境变量。建议使用命令的完整路径,保证作业正常执行。例如,下面的命令 每分钟都会将日期和系统运行时长 写入用户主目录下的文件中。
* * * * * echo $(/bin/date) - $(/usr/bin/uptime) >> ~/uptime.log
另外,也可以在crontab文件的顶部明确地设置环境变量。
PATH=/bin:/usr/bin
* * * * * echo $(date) - $(uptime) >> ~/uptime.log
访问控制cron
有两个配置文件指定了哪些用户可以提交crontab文件。在Linux中,文件是/etc/cron.{allow,deny};每个用户占一行。
systemd计时器
除了crontab之外,还有一个systemd计时器的概念,能够根据定义好的计划激活特定的systemd服务。计时器功能要比crontab条目更强大,但是在设置和管理方面也更复杂。这里不展开说了。
第五章 文件系统
1、文件系统挂载
文件系统的基本用途就是描述和组织系统的存储资源。文件系统是由一些更小的块(chunk)组成的,这些块也叫作文件系统,每个块都包括一个目录及其子目录和文件。
mount会将现有文件树中的某个目录(称为挂载点)映射为新增文件系统的根目录。例如:$ sudo mount /dev/sda4 /users,该命令会将磁盘分区/dev/sda4 中的文件系统挂载到 /users下。可以使用 ls /users查看文件系统的内容。
不加任何参数的mount命令可以查看目前所有已挂载的文件系统。
/etc/fstab 文件中列出了系统正常挂载的文件系统。该文件中的信息使得系统在引导时能够根据指定的选项自动检查(使用fsck命令)和挂载(使用mount命令)文件系统。
umount命令用于卸载文件系统。如果要卸载的文件系统处于使用中,umount会提示错误。该文件系统中不能有打开的文件,也不能有进程的当前目录。如果其中包含有可执行程序,那么这些程序绝不能处于运行状态,这样才能够成功卸载。
Linux有一个“惰性”卸载选项(umount -l),可以先从文件树中删除文件系统,然后等到其中被引用到的文件全部关闭之后才会真正地完成卸载操作。
选项 -l 并不是马上umount,而是在该目录空闲后再umount。还可以先用命令 ps aux 来查看占用设备的程序PID,然后用命令kill来杀死占用设备的进程,这样就umount的非常放心了。
umount -f 可以强制卸载处于繁忙状态的文件系统,但最好别在以非NFS类型挂载的文件系统上使用,而且在某些类型的文件系统上该选项可能无法正常工作(例如像XFS或ext4这种日志文件系统)。
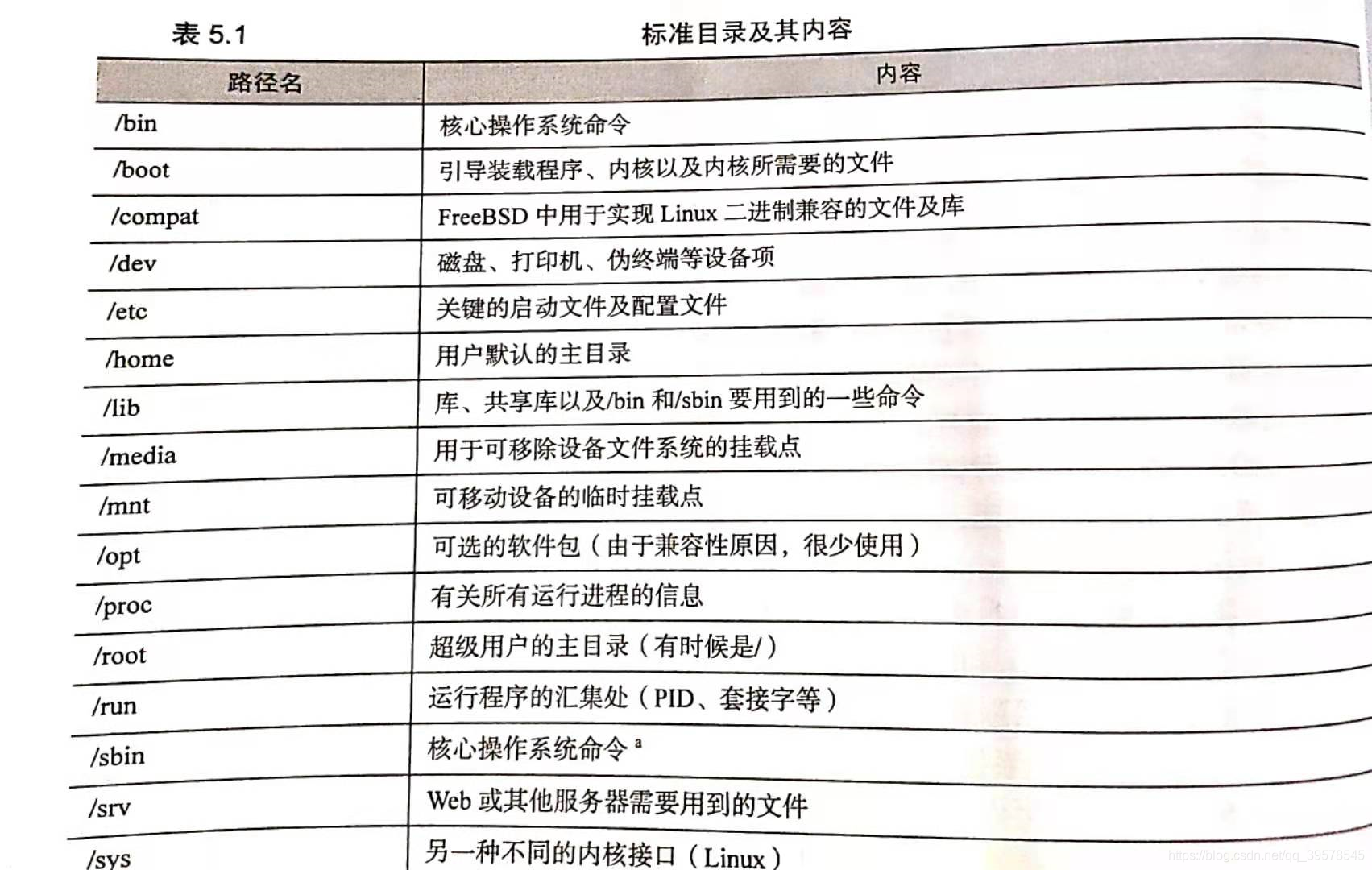
Linux重要的标准目录及其内容:

2、文件类型
大多数的文件系统实现定义了7种文件类型。
- 普通文件。
- 目录。
- 字符设备文件。
- 块设备文件。
- 本地域套接字。
- 具名管道(FIFO)。
- 符号链接。
①可以使用file命令确定文件的类型。
②另一种判断文件类型的方法是ls -ld,选项 -l表示输出详细信息,选项 -d强制ls显示目录信息,而非该目录下的内容
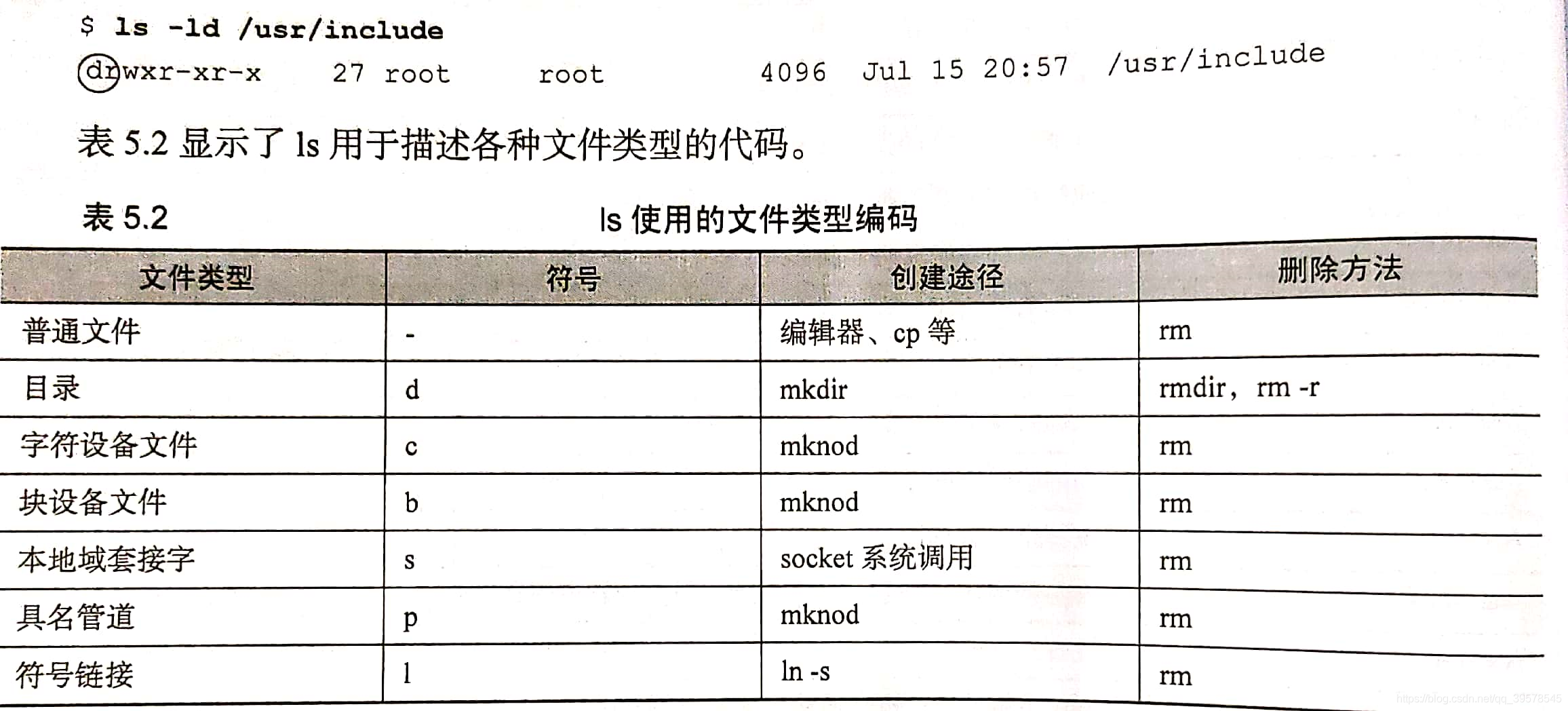
rm是删除文件的通用工具,支持模式匹配,最好养成搭配rm的-i选项的习惯,这样可以让rm确认要删除的每个文件。
硬链接与软链接
实际应用场景:
1、软链接文件可以作为快捷方式,简化繁琐的文件层次
2、硬链接文件可以用于重要文件,防止文件被误删等情况发生
软链接——》快捷方式
硬链接——》复制了一份
ln 3.txt 4.txt 这是硬链接,相当于复制,不可以跨分区,但修改3后,4会跟着变,若删除3后,4不受任何影响。
ln -s 3.txt 4.txt 这是软连接,相当于快捷方式。修改4后,3也会跟着变,若删除3后,4就坏掉了。不可以用了。
软硬链接区别:
- 软链接可以跨文件系统,硬链接不可以跨文件系统
只有在同一文件系统中的文件之间才能创建硬链接。 即不同硬盘分区上的两个文件之间不能够建立硬链接。这是因为硬链接是通过结点指向原始文件的,而文件的inode结点在不同的文件系统中可能会不同。 - 硬链接的 inode 号相同,软链接则不相同
硬链接:与普通文件没什么不同,inode 都指向同一个文件在硬盘中的区块,硬链接的inode和源文件是相同的
软链接:软链接的inode与源文件的inode不同,保存了其代表的文件的绝对路径,是另外一种文件,在硬盘上有独立的区块,访问时替换自身路径。 - 硬链接不能对目录创建(技术上是可以,但是会导致多种恶果,例如文件系统环路、目录出现多个父目录,引发歧义。),软链接则可以对目录创建
- 软链接删除原文件,链接文件失效(红底白字闪烁状)。
- 硬链接删除原文件,链接文件不会失效
- 同时删除原文件其硬链接文件,整个文件才会被真正删除
- 软链接可以对一个不存在的文件名进行链接,硬链接必须要有源文件。
- 硬链接,以文件副本的形式存在。但不占用实际空间。
- 所有目录至少都有两个硬链接:一个来自父目录,另一个来自该目录内部的特殊文件。
3、文件属性
ls -l
- 第一个字段指定了文件的类型和模式。首个字符是连字符,表明这是一个普通文件。
- 字段中接下来的9个字符是3组权限位。次序为 属主-属组-其他人。
- 如果设置了setuid位,原本代表属主执行权限的x会替换成s;如果设置了setgid位,属组的x位也会替换成s。
- 如果文件启用了粘滞位,最后一个权限字符(其他人的执行权限)会显示为t。
- 如果设置了setuid/setgid或粘滞位,但没有设置相应的执行位,那么这些位会显示为S或T。(目录上设置setgid位,那么其中新创建的文件获得的则是该目录的属组权限,而不再是创建该文件的用户的默认属组。)
- 粘滞位:如果粘滞位设置在目录上,除非是该目录、该文件的属主或者是超级用户,否则文件系统不允许删除或重命名其中的文件。
ls选项
-i选项,显示每个文件的“索引节点号”,有助于分析硬链接
-a选项,显示出所有的目录项
-t选项,按照修改时间排列文件 (或者是-tr,按照时间逆序排列)
-F选项,以区分目录和可执行文件的方式显示文件名
-R选项,以递归方式列出文件
-h选项,以方便用户阅读的形式显示文件大小(例如8K或者53M)
chmod命令修改权限

chown
chown命令改变文件的属主,chgrp命令改变文件的属组
chown可以使用下列语法一次性改变文件的属主和属组。
chown user:group file
注意,不能使用下列命令修改点号文件的所有权。
正确设置:chown -R newuser:newgroup ~newuser
错误设置:chown -R newuser:newgroup ~newuser/.*
因为这样的话,newuser不仅会拥有自己的文件,还会拥有父目录“..”。这是一种危险的常见错误。
umask命令可以分配默认权限
umask是以一个3位数的八进制值来指定的,代表了要被剥夺的权限。在创建文件时,最终的权限是由创建该问价你的程序所请求设置的权限减去被umask禁止的权限得到的。umask的默认值通常是022,该值禁用了属组以及其他人的写权限,但允许其拥有读取权限。
如果想知道当前的umask 值,可以使用umask命令:
$umask
如果想要改变umask值,只要使用umask命令设置一个新的值即可:
$ umask 002
Linux的ACL支持
POSIX ACL系统只处理读取、写入和执行权限。ACL能够根据用户和组的任意组合独立地设置rwx权限位。
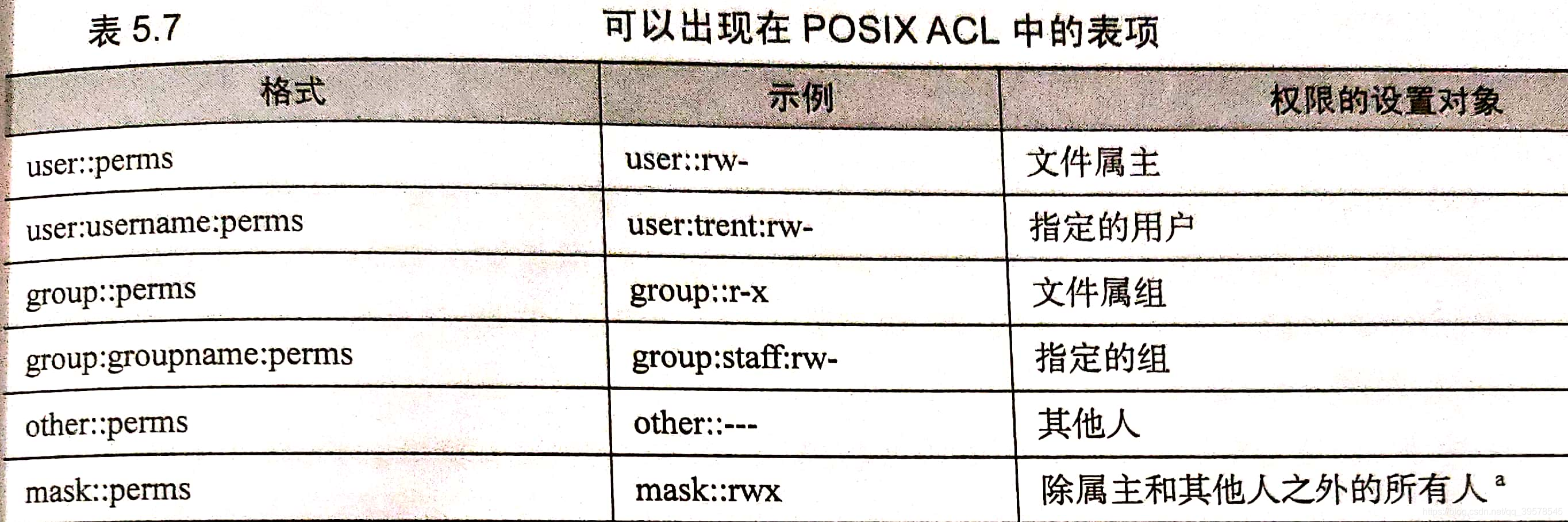
$ getfacl example.txt
$ setfacl -m user::r,user:trent:rw,group:admin:rw example.txt
$ setfacl -n 可以完全删除一个ACL。
-m选项表示修改
在执行过setfacl命令之后,ls -l在文件模式尾部显示了一个+,表示该文件现在已经有一个与之关联的ACL。
之前ls -l没有显示+的原因在于当时的ACL只是 “最小化”的ACL
如果使用传统的chmod命令操作带有ACL的文件,对于“属组”权限所作出的设置只会影响到mask,这点要留意。
通过chmod 770 操作后,尽管表面上看拥有组权限,但实际上组成员也无法执行该文件,要想授权,必须编辑ACL本身。
具体更详细ACL内容就不一一介绍,等工作用到再来看看吧。先了解
第六章 软件安装与管理
1、网络安装
网络安装通过DHCP和TFTP引导系统,然后使用HTTP、NFS或FTP从网络服务器中接收操作系统安装文件。可以利用 预引导执行环境(PXE) 实现完全自动化安装,该方案是Intel指定的一项标准,能够从网络接口引导系统。
PXE就像是网络ROM中的一个微型操作系统。它通过标准API将自身的网络功能提供给系统BIOS使用。在PXE和系统BIOS的配合下,单个引导装载程序不用再为各种网卡提供专门的驱动程序就能够通过网络引导任意一台启用了PXE的PC。

设置PXE:要想从网络引导,PC会从TFTP服务器下载PXE引导装载程序及其配置。在DHCP这边,可以利用Cobbler来提供PXE信息。
kickstart:Red Hat和CentOS的自动化安装程序。
kickstart是由Red Hat开发的一款自动化安装工具。kickstart可以通过光盘、本地硬盘、NFS、FTP或HTTP进行安装。
-
建立kickstart配置文件
kickstart的行为由一个名为ks.cfg的配置文件控制,该文件的格式很直观。(ks.cfg文件很容易通过编程生成,其中一种选择是使用Python库pykickstart,读写kickstart配置。)
kickstart的配置文件由3个有序部分组成。
在下面的例子中,发行版来源是一台名为installserver的主机。来看一个完整的命令区块示例。

第一个区块:- 命令区块(command section),其中指定了语言、键盘、时区等选项,另外还使用url选项指定了发行版的来源。
- rootpw选项可以设置新机器的root密码。在默认情况下,密码是以明文形式指定的,这会引发严重的安全问题。应该坚持使用–iscrypted选项指定经过散列处理后的密码。可以使用openssl passwd -l 命令对密码进行加密。
- clearpart和part指令给出了一份磁盘分区及其大小的清单。可以加入–grow选项来扩展某个分区,使其能够占据磁盘剩余的所有空间。该特性能够方便地适应硬盘大小不同的系统。kickstart也支持高级分区选项(例如LVM)
第二个区块:
- 安装区块,区块中列出了要安装的软件包,该区块以%package指令开始。安装列表中可以包含单个软件包、软件包合集(例如@GNOME)或者表示全部安装的@Everything。在选择单个软件包时,只需要给出软件包的名字就行了,不用加版本号或.rpm扩展名。例如
%packages @ Networked Workstation @ X Window System @ GNOME mylocalpackage
第三个区块:
- 可以指定由kickstart执行的任意命令。命令分为两类:一类由%pre引入,在安装开始前执行;另一类由%post引入,在安装结束后执行。这两类命令在一定程度上受限于系统解析主机名的能力,如果想要访问网络,最好就是使用IP地址。
-
架设kickstart服务器
kickstart要求安装文件(叫作安装树)的布局与其在发行版介质上一样,软件包需要保存在服务器的RedHat/RPMS目录下。- 首先,如果告诉kickstart要安装所有的软件包(在ks.cfg的%packages区块中使用@everything),那么它会在安装好所有的基础软件包之后按照字母顺序安装附加软件包。如果软件包依赖基础软件包之外的包,那么可能需要将其改成zzmypackage.rpm这样的名字,确保最后再安装。
- 如果不想安装所有的软件包,那么将需要的包单独列在ks.cfg文件的%packages区块内。
-
指定kickstart要使用的配置文件
- 第一种方法是通过外部介质(USB或DVD)引导,在boot:提示符输入linux inst.ks,要求进行kickstart安装。
boot: linux inst.ks=http:server:/path - 第二种是选择PXE引导。
- 第一种方法是通过外部介质(USB或DVD)引导,在boot:提示符输入linux inst.ks,要求进行kickstart安装。
PXE是引导程序,kickstart是应答文件。PXE+kickstart可以做到无人值守安装系统

实验过程:https://www.linuxprobe.com/chapter-19.html
2、Cobbler实现网络引导
目前为网络添加网络引导服务简单的方法就是使用Cobbler,Cobbler对kickstart进行了改进,移除了期中一些非常乏味的、重复性的管理元素。Cobbler拥有包括DHCP、DNS和TFTP在内的所有重要的网络引导特性,能够帮助你管理用于构建物理主机以及虚拟机的操作系统镜像。
模板是Cobbler最为引人瞩目和有用的特性,经常会碰到的一种情况是需要为不同的主机准备不同的kickstart和预设设置。例如,除了网络配置之外,两者的其他配置都一样。可以使用Cobbler的“脚本片段”(snippet)功能在两种主机间共享部分配置。
脚本片段就是一组shell命令而已,例如下面的脚本片段可以将一个公钥添加到root用户已授权的SSH密钥中。
mkdir -p --mode=700 /root/.ssh
cat >> /root/.ssh/authorized_keys << EOF
ssh-rsa xxxxxxxxxxxx
EOF
chmod 600 /root/.ssh/authorized_keys
你需要将该脚本片段保存到Cobbler的相应目录中,然后在kickstart配置模板中引用。例如,如果你将上面的脚本片段保存为roo_pubkey_snippet,那么可以像这样来引用:
%post
SNIPPET::root_pubkey_snippet
$kickstart_done
可以利用Cobbler模板来定制磁盘分区、根据条件安装软件包、定制时区、添加特定的软件仓库、实现其他种类的本地化需求。Cobbler还能够在各种Hypervisor下创建新的虚拟机。当预配置主机引导完毕后,它还能将其与配置管理系统集成在一起。
3、软件包管理
rpm:管理RPM软件包。
常用的选项是-i(instal)、-U(upgrade)、-e(erase)、-q(query)、–force选项能够强制升级。
例如,rpm -qa可以列出系统中已经安装的所有软件包。
rpmbuild构建软件包
https://www.cnblogs.com/jmliao/p/11322680.html
第七章 脚本编程与shell
1、shell基础
管道与重定向
每个进程都至少有3个可用的通道:标准输入(STDIN)、标准输出(STDOUT)、标准错误(STDERR)。在交互式终端窗口里,STDIN通常从键盘读取输入,STDOUT和STDERR把各自的输出写到屏幕上。
2>/dev/null
意思就是把错误输出到“黑洞”
>/dev/null 2>&1
默认情况是1,也就是等同于1>/dev/null 2>&1。意思就是把标准输出重定向到“黑洞”,还把错误输出2重定向到标准输出1,也就是标准输出和错误输出都进了“黑洞”
2>&1 >/dev/null
意思就是把错误输出2重定向到标准输出1,也就是屏幕,标准输出进了“黑洞”,也就是标准输出进了黑洞,错误输出打印到屏幕
Linux系统预留可三个文件描述符:0、1和2。
0——标准输入(stdin)
1——标准输出(stdout)
2——标准错误(stderr)
——————
变量与引用
例如,用${etcdir}代替$etcdir,通常并不需要花括号,但如果想要在双引号引用的字符串里扩展变量,就能派上用场。如echo "Save ${rev}th version of sth."
单引号与双引号:双引号内的字符串支持扩展匹配处理。
反引号:将反引号中字符串内容作为shell命令执行。
——————
环境变量
环境变量名依据约定全部采用大写字母,不过这并非技术上的强制要求。
$ printenv 可以使用printenv命令显示出当前的环境变量。
$ export varname=value 将一个普通的shell变量升级为环境变量。
Linux 中环境变量的文件
当你进入系统的时候,Linux 就会为你读入系统的环境变量,Linux 中有很多记载环境变量的文件,它们被系统读入是按照一定的顺序的。
-
/etc/profile 全局变量文件
此文件为系统的环境变量,它为每个用户设置环境信息,当用户第一次登录时,该文件被执行。并从/etc/profile.d 目录的配置文件中搜集shell 的设置。这个文件,是任何用户登陆操作系统以后都会读取的文件(如果用户的shell 是csh 、tcsh 、zsh ,则不会读取此文件),用于获取系统的环境变量,只在登陆的时候读取一次。 (假设用户使用的是BASH ) -
/etc/bashrc
在执行完/etc/profile 内容之后,如果用户的SHELL 运行的是bash ,那么接着就会执行此文件。另外,当每次一个新的bash shell 被打开时, 该文件被读取。每个使用bash 的用户在登陆以后执行完/etc/profile 中内容以后都会执行此文件,在新开一个bash 的时候也会执行此文件。因此,如果你想让每个使用bash 的用户每新开一个bash 和每次登陆都执行某些操作,或者给他们定义一些新的环境变量,就可以在这个里面设置。 -
~/.bash_profile 用户环境变量文件
每个用户都可使用该文件输入专用于自己使用的shell 信息。当用户登录时,该文件仅仅执行一次,默认情况下,它设置一些环境变量,执行用户的.bashrc 文件。单个用户此文件的修改只会影响到他以后的每一次登陆系统。因此,可以在这里设置单个用户的特殊的环境变量或者特殊的操作,那么它在每次登陆的时候都会去获取这些新的环境变量或者做某些特殊的操作,但是仅仅在登陆时。 -
~/.bashrc
该文件包含专用于单个人的bash shell 的bash 信息,当登录时以及每次打开一个新的shell 时, 该该文件被读取。单个用户此文件的修改会影响到他以后的每一次登陆系统和每一次新开一个bash 。因此,可以在这里设置单个用户的特殊的环境变量或者特殊的操作,那么每次它新登陆系统或者新开一个bash ,都会去获取相应的特殊的环境变量和特殊操作。 -
~/.bash_logout
当每次退出系统( 退出bash shell) 时, 执行该文件。
第一种:
用户登录后加载profile和bashrc的流程如下:
1)/etc/profile-------->/etc/profile.d/*.sh
2)$HOME/.bash_profile-------->$HOME/.bashrc---------->/etc/bashrc
bash首先执行/etc/profile脚本,/etc/profile脚本先依次执行/etc/profile.d/*.sh
随后bash会执行用户主目录下的.bash_profile脚本,.bash_profile脚本会执行用户主目录下的.bashrc脚本,
而.bashrc脚本会执行/etc/bashrc脚本
至此,所有的环境变量和初始化设定都已经加载完成.
bash随后调用terminfo和inputrc,完成终端属性和键盘映射的设定.
第二种:
比如说:手动在终端执行“bash”命令,又或者不需要输入密码的登录以及远程SSH连接情况
⭐️这样的方式,只会加载$HOME/.bashrc(用户个人的环境变量文件),紧接着去加载/etc/bashrc(全局环境变量文件)
因此,如果希望在非登录Shell下也可以读取到设置的环境变量,
就需要把变量设定在$HOME/.bashrc(如果想仅仅个人生效,设定在这个文件)
或者/etc/bashrc(如果想全部的用户都能生效,设定在这个文件)
——————
cut:把行划分成字段
sotrt:排序行
| 选项 | 含义 |
|---|---|
| -b | 忽略前导空白字符 |
| -f | 不区分大小写排序 |
| -h | 依据“用户可读”的数字(例如,2MB)排序 |
| -k | 指定作为排序键的列 |
| -n | 按照整体比较字段 |
| -r | 按照逆序排序 |
| -t | 设置字段分隔符(默认是空白字符) |
| -u | 只输出不重复的记录 |
$ sort -t: -k3,3 -n /etc/group
root:x:0:
bin:x:1:daemon
daemon:x:2:
$ sort -t: -k3,3 /etc/group
root:x:0:
bin:x:1:daemon
users:x:100:
按照由冒号分割的第三个字段(组ID)进行排序。第一条命令按照数值排序,第二条按照字母。
也可以使用k3来指定关键字,而不是-k3,3。
如果没有指出终止字段编号,那么排序关键字会一直延续到行尾。
-h选项,不仅可以实现数值排序,还能保证结果易读性。
$ du -sh /usr/* | sort -h
16K /usr/locale
128K /usr/local
15M /usr/sbin
uniq:打印出不重复的行
uniq命令在思路上和sort -u类似,但它功能更强大:
-c选项,累计每行出现的次数。
-d选项,只显示重复行。
-u选项,只显示不重复行,
该命令的输入必须先排好序,因此通常把它放在sort命令之后运行。
$ cut -d: -f7 /etc/passwd | sort | uniq -c
wc:统计行数、单词数和字符数
-l选项,行数
-w选项,单词数
-c选项,字符数
tee:将输入复制到到两个地方
标准输入发送到两个地方
- 标准输出到屏幕
- 命令行上指定的文件
一种常见的习惯用法是把tee命令作为需要耗时很长的命令管道的最后一环。 这样一来,管道的输出既能保存到文件中,又能够显示在终端窗口以供查看。你可以先预览一部分最终结果,确定一切按预期工作,然后让命令继续运行,执行结果自然会被保存下来。
使用指令"tee"将用户输入的数据同时保存到文件"file1"和"file2"中,输入如下命令:
$ tee file1 file2 #在两个文件中复制内容
[root@localhost ~]# who | tee who.out
root pts/0 2020-02-17 07:47 (123.123.123.123)
[root@localhost ~]# cat who.out
root pts/0 2020-02-17 07:47 (123.123.123.123)
[root@localhost ~]# pwd | tee -a who.out
/root
[root@localhost ~]# cat who.out
root pts/0 2020-02-17 07:47 (123.123.123.123)
/root
head和tail:读取文件的起始和结尾部分。
这两条命令默认显示10行内容,使用选项-n指定具体要显示的行数。
对于交互式的应用场合,head命令已经或多或少地被less命令所取代,后者能够分页显示文件内容,但是head命令仍然大量应用于脚本中。
tail -f,打印后并不会立即退出,等待新行被追加到文件末尾再打印。
grep:搜索文本
-c选项,打印匹配行数
-i选项,忽略大小写
-v选项,打印非匹配行
-l(小写字母L)选项,只打印出进行匹配的文件名,而不是匹配到每一行。如
$ grep -l mdadm /var/log/*
该命令表名mdadm日志项出现在两个不同的日志文件中。
$ tail -f /var/log/messages | grep --line-buffered ZFS
确保能够在第一时间看到所匹配的每一行
2、shell编程
反斜线转义换行符
分号分隔语句
$ sh helloworld
$ source helloworld
第一条命令会在shell的新实例中运行helloworld脚本
第二条命令则使用现有的登录shell读取并执行文件内容。(即脚本设置环境变量或者只对当前shell进行定制时。)
输入与输出
read输入,echo和printf输出,echo命令的-n选项可以取消通常的换行符。
#! /bin/sh
echo -n "输入你的名字:"
read user_name
if [ -n "$user_name" ]; then
echo "Hello $user_name!"
exit 0
else
echo "Bye"
exit 1
fi
结果:
$ sh readexample
请输入你名字:Kolor
Hello Kolor!
if [ str1 = str2 ] 当两个串有相同内容、长度时为真
if [ str1 != str2 ] 当串str1和str2不等时为真
if [ -n str1 ] 当串的长度大于0时为真(串非空)
if [ -z str1 ] 当串的长度为0时为真(空串)
if [ str1 ] 当串str1为非空时为真
错误用法:
ARGS=$*
if [ -n $ARGS ]
then
print "with argument"
fi
print " without argument"
不管传不传参数,总会进入if里面。
原因:因为不加“”时该if语句等效于if [ -n ],shell 会把它当成if [ str1 ]来处理,
-n自然不为空,所以为正。
正确用法:需要在$ARGS上加入双引号,即"$ARGS".
ARGS=$*
if [ -n "$ARGS" ]
then
print "with argument"
fi
print " without argument"
文件名中的空格
以长格式打印出/home目录下大小超过1MB的所有文件
$ find /home -type f -size +1M -print0 | xargs -0 ls -l
通过find命令的-print0选项,与xargs -0搭配使用,使得find/xargs在面对包含空白字符的文件时也能正常工作。
- find -print0表示在find的每一个结果之后加一个NULL字符,而不是默认加一个换行符。find的默认在每一个结果后加一个’\n’,所以输出结果是一行一行的。当使用了-print0之后,就变成只有一行了。
- xargs 默认是以空白字符 (空格, TAB, 换行符) 来分割记录的,xargs -0表示xargs用NULL来作为分隔符。这样前后搭配就不会出现空格和换行符的错误了。选择NULL做分隔符,是因为一般编程语言把NULL作为字符串结束的标志,所以文件名不可能以NULL结尾,这样确保万无一失。
命令行参数
$0 Shell本身的文件名,相当于C语言main函数的argv[0]
$1、$2... 这些称为位置参数,$1是第一个命令行参数
$# 传递给脚本或函数的参数个数
$@ 传递给脚本或函数的所有参数
$* 表示参数列表"$1" "$2"。包含了全部的参数
$? 上一条命令的Exit Status
$$ 当前进程号
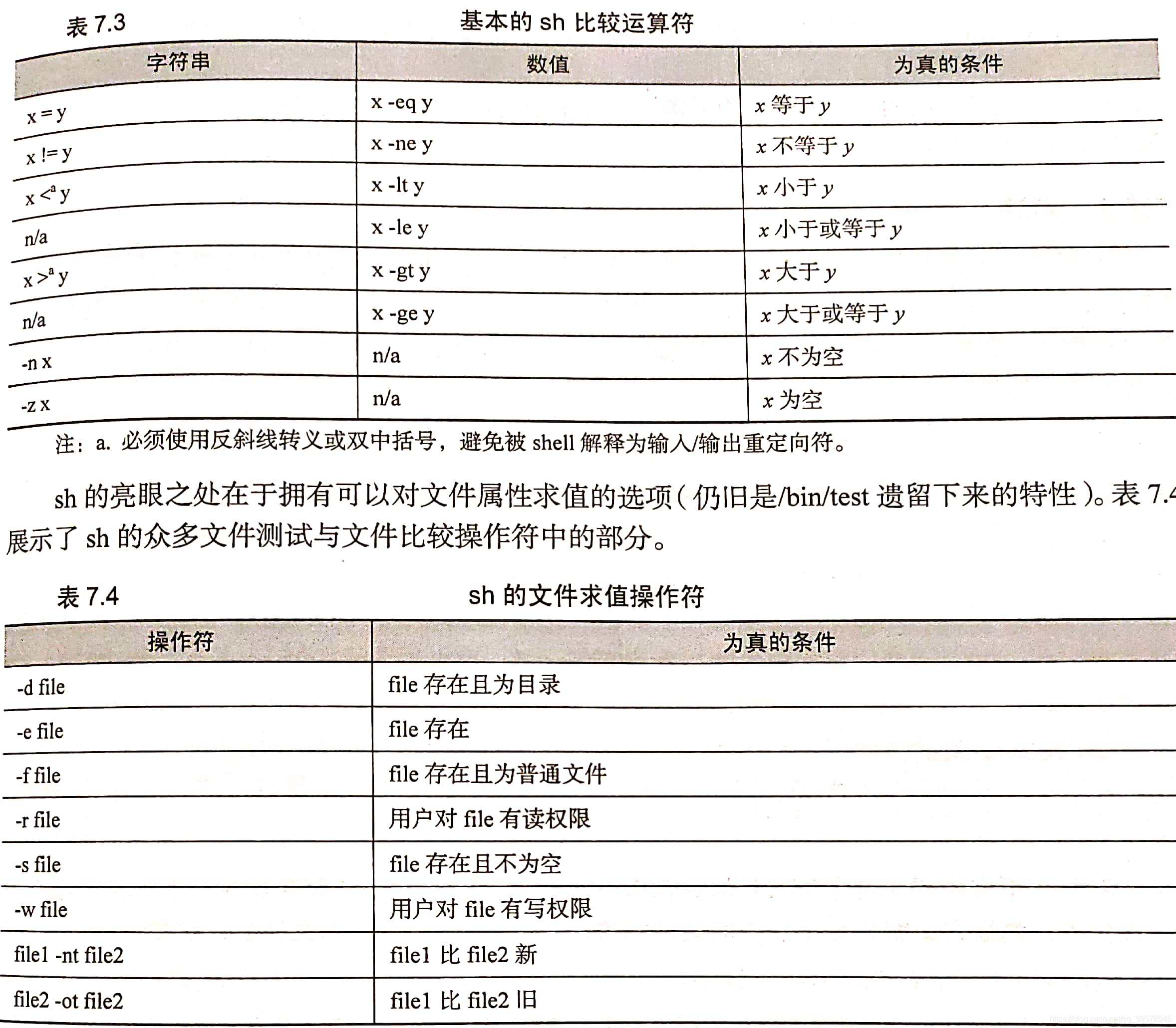
双方括号
双方括号为字符串比较提供高级功能,模式匹配。如使用*作通配符。
if [[ $USER == r* ]]
then
echo "Hello $USER"
else
echo "Sorry, I don't know you"
fi
是关键字,可以直接支持&&, ||, <, 和> 等符号,不用转义(只有字符串才可以用这些符号比较,数字还是要用-gt/-lt等比较)
单中括号
[ ]是内置条件判断符号。字串比较符号> < 要加转义符号’’,多条件用 -a(and,表示&&) -o(or,表示||)连接;
$ [ 'a' \> 'c' -a 'a' \> 'b' ] && echo 'left' || echo 'right';
算术运算
$((...)),强制进行数值计算
用于算术代换,$ (())中的Shell变量取值将转换成整数,同样含义的$[]等价例如:
$ VAR=45
$ echo $(($VAR+3))
$(())中只能用+-*/和()运算符,并且只能整数运算。
$ [base#n],其中base表示进制,n按照base进制解释,后面再有运算数,按十进制解释
echo $[2#10+11]
echo $[8#10+11]
echo $[10#10+11]
3、正则匹配
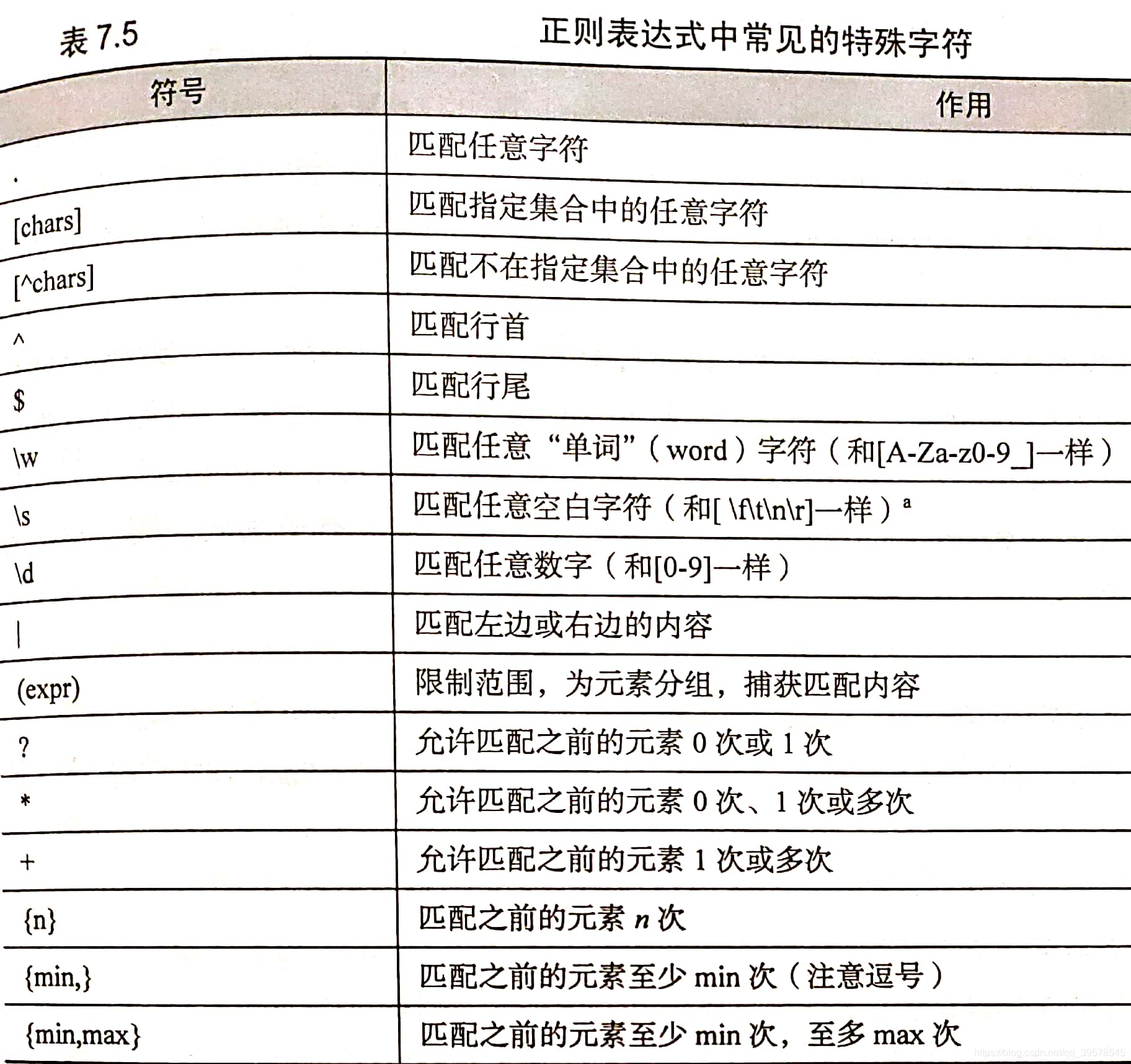
捕获:匹配成功之后,每一对括号都编程了一个“捕获组”,记录下了其所匹配的实际文本。匹配的顺序和左括号的顺序一样,有多少个左括号,就有多少次捕获。
如果一个捕获组匹配了不止一次,那么只返回最后一次匹配的内容。例如
(I am the (walrus|egg man)\. ?){
1,2}
对下列文本进行匹配的话:
I am the egg man. I am the walrus.
可以得到两个结果,分别对应每对括号。
I am the walrus.
walrus
这两个捕获分组实际上都匹配了两次,但是,实际被捕获到的只有最后一次匹配的文本。
贪婪、惰性以及灾难性回溯
贪婪匹配:正则表达式从左到右进行匹配,模式中的每一部分都要匹配尽可能长的字符串,然后再由下一部分接着匹配。
如果正则表达式引擎发现无法完成匹配,那么它就从候选的匹配结果那里退回一点儿,让某个贪心的子模式放弃部分已匹配的文本。例如,考虑用正则表达式a*aa是如何匹配输入文本“aaaaaa”的。
- 首先,正则表达式引擎把整个输入都分配给其中的a部分,因为a是贪婪的。在没有更多的可匹配的a之后,引擎会继续尝试匹配正则表达式接下来的部分。但是,接下来的是一个a,已经没有输入文本能匹配它了,这就到了该回溯的时候。a*不得不放弃一个它已经匹配过的a。
- 引擎现在能够匹配aa了,但它仍然不能匹配模式中最后那个a,所以还得回溯,让a再次腾出一个a,现在该模式里的第二个和第三个都有对应的匹配了,整个匹配过程也就结束了。
贪婪匹配加上回溯会让如<img.*></tr>这种看起来很简单的模式产生巨大的开销。正则表达式中.*的部分一开始就匹配了从起始的<img到结尾的所有输入内容,只有通过反复回溯它才能收缩到与局部标签相匹配。该模式所匹配的></tr>是输入中出现的最后一处,这也许并不是想要的结果。
想要匹配紧跟<img>的</tr>标签。这种模式更好的解法是<img[^>]*></tr>,让一开始的子模式只匹配到当前标签的结尾,因为它不能超过右尖括号形成的边界。
惰性(和贪婪正好相反):用*?来代替*,用+?来代替+,这两种量词会尽可能少地匹配输入字符。
4、Python编程
(1)入门
import sys
a = sys.argv[1]
if a == "1":
print('a is one')
else:
print('a is ',a)
print('test')
第一行导入sys模块,该模块包含数组argv
$ python3 blockexample 1
a is one
len(sys.argv)
——————
Pyhon的print函数能够接受任意数量的参数。它会在每对参数之间插入空格,自动提供换行符。可以在参数列表末尾加入end=或sep=选项来消除或修改这些字符。
例如:
print("one","two","three",sep="-",end="!\n")
该语句会生成:
one-two-three!
在/etc/vimrc文件内设置
set tabstop=4 末尾不加引号。
set nu 自动显示行号
(2)对象、字符串、数字、列表、字典、元组与文件。
列表切片:左闭右开
元组不可修改,只包含单个元素的元组,需要用一个额外的逗号来消除歧义。(thing,)
字典:ordinal = {1:'first',2:'second'}
for key,value in ordinal.items():
得到“键/值”对的迭代器。
如果只想通过键进行迭代,把代码改成 for key in ordinal就行了
Python通过re模块实现对正则表达式的处理,替换字符串里的\1是一个反向引用,引用的是第一个捕获分组匹配到的内容。替换字符串前面那个看起来挺奇怪的前缀r(r"_\1_")冰皮了字符串常量中的正常的转义序列替换操作。(r代表“raw”),如果没有这个前缀,替换模式就会变成两个下划线包围着的字符串l。
5、使用Git实现版本控制
在使用Git之前,先设置你的名字和电子邮件地址。
$ git config --global user.name "Kolor"
$ git config --global user.email "[email protected]"
上述命令会创建初始的Git配置文件~/.gitconfig(如果该文件尚不存在)。git命令随后会查看该文件中的配置信息。
下面创建一个新的Git仓库并生成基础配置。

现在来做一次变更,然后将其放入仓库。
$ vi super-script.sh
$ git commit super-script.sh -m "xxxxxx"
在git commit命令行中给被修改的文件命名会绕过Git正常使用的索引,创建出一个修订版本,其中只包括对该命名文件做出的改动。现有的索引保持不变,Git会忽略任何其他可能已经被修改的文件。
通过git commit -a,让Git在提交之前将所有被改动过的文件加入索引。(只针对目前处于版本控制管理下的文件所做出的的更改,在工作目录下创建的新文件是不会管的,新文件需要通过 git add .)
通过git status,可以概览Git的状态,该命令可以一次性显示出新文件、修改过的文件以及暂存文件。
通过git diff super-script.sh,查看对脚本所做的变更。
通过.gitgnore,然后git add .,然后commit。可以使git忽略文件。
第八章 用户管理
1、/etc/passwd文件
系统在登陆时查询/etc/passwd来确定用户的UID和主目录。该文件中的每一行都描述了一个用户,包含了由冒号分隔的7个字段。
- 登录名。
- 加密密码的预留位置。
- UID(user ID,用户ID)数字。
- 默认的GID数字。
- 可选的“GECOS”信息:全名、办公室、分机号、家庭电话。
- 主目录
- 登陆shell。
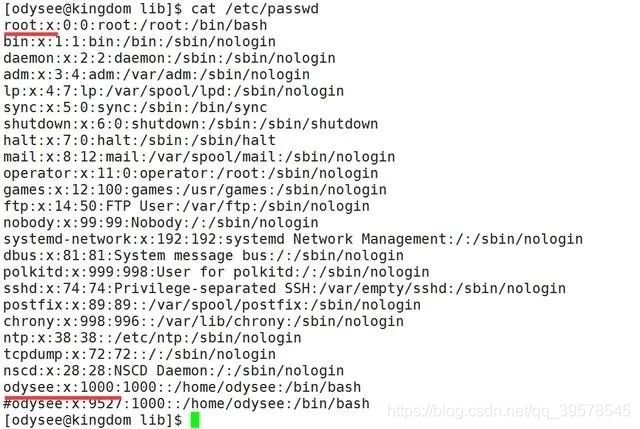
如下图各个字段含义:
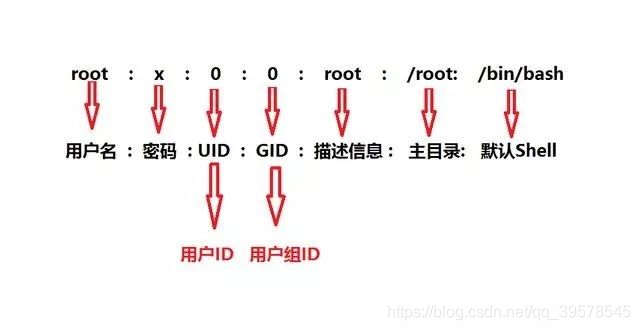
- “x”:表示此用户设有密码,但不是真正的密码,真正的密码保存在/etc/shadow文件。
注意!!!,虽然"x"并不表示真正的密码,但也不能删除,如果删除了 “x”,那么系统会认为这个用户没有密码,从而导致只输入用户名而不用输入密码就可以登陆(只能在使用无密码登录,远程是不可以)。 - UID:用户ID。每个用户都有唯一UID,Linux 系统通过UID来识别不同的用户。实际上,UID 就是一个 0~65535 之间的数,不同范围的数字表示不同的用户身份。
0:超级用户。UID为0就代表这个账号是管理员账号。
1~499:系统用户。此范围的UID保留给系统使用。
500~65535:普通用户。 - GID:简称"组ID",表示用户初始组组ID号。
(1) 初始组
指用户登陆时就拥有这个用户组的相关权限。每个用户的初始组只能有一个,通常就是将和此用户的用户名相同的组名作为该用户的初始组。比如说,我们手动创建用户 odysee,在建立用户odysee同时,就会建立odysee组作为odysee用户的初始组。
(2) 附加组
用户可以加入多个其他的用户组,并拥有这些组的权限。
每个用户只能有一个初始组,除初始组外,用户再加入其他的用户组,这些用户组就是这个用户的附加组。附加组可以有多个,而且用户可以有这些附加组的权限。 - 主目录:通常称为用户的主(家)目录,是用户登录期间的默认目录。
2、/etc/shadow文件
和/etc/passwd一样,/etc/shadowwe文件中每行都对应着一个用户,包含了由冒号分隔的九个字段:其中只有登录名和密码字段必须指定值。
- 登录名
- 加密密码
- 最后一次更改密码的日期
- 密码更改的最小间隔天数
- 密码更改的最大间隔天数
- 提前多少天通知用户密码将要过期
- 密码过期后多少天禁用该账户
- 账户过期日期
- 备用的保留字段,目前值为空
[root@localhost ~]#vim /etc/shadow
root: $6$9w5Td6lg
$bgpsy3olsq9WwWvS5Sst2W3ZiJpuCGDY.4w4MRk3ob/i85fl38RH15wzVoom ff9isV1 PzdcXmixzhnMVhMxbvO:15775:0:99999:7:::
bin:*:15513:0:99999:7:::
daemon:*:15513:0:99999:7:::
…省略部分输出…
3、/etc/group文件
/etc/group文件中包含了各个组的名称以及每个组的成员列表。
每一行都描述了一个组,其中包含了4个字段:
- 组名
- 加密后的密码或占位符
- GID数值
- 组成员列表,彼此之间以逗号分隔(千万别添加空格)
如果用户默认属于/etc/passwd中的某个组,但是在/etc/group中用户却没有出现在这个组中,则以/etc/passwd为准。在登陆时所授权的组成员关系是在passwd和group文件中查找结果的合集(union)。
Linux提供了groupadd、groupmod、groupdel命令来创建、修改、删除组。
useradd默认会禁用新账户,必须为新账户设置真正的密码才能够使用。
参数选项:
-c<备注> 加上备注文字。备注文字会保存在passwd的备注栏位中。
-d<登入目录> 指定用户登入时的起始目录。
-D 变更预设值.
-e<有效期限> 指定帐号的有效期限。
-f<缓冲天数> 指定在密码过期后多少天即关闭该帐号。
-g<群组> 指定用户所属的群组。
-G<群组> 指定用户所属的附加群组。
-m 自动建立用户的登入目录。
-M 不要自动建立用户的登入目录。
-n 取消建立以用户名称为名的群组.
-r 建立系统帐号。
-s<shell> 指定用户登入后所使用的shell。
-u<uid> 指定用户ID。
第九章 云计算
“云”实质上就是一个网络,狭义上讲,云计算就是一种提供资源的网络,使用者可以随时获取“云”上的资源,按需求量使用,并且可以看成是无限扩展的,只要按使用量付费就可以,,“云”就像自来水厂一样,我们可以随时接水,并且不限量,按照自己家的用水量,付费给自来水厂就可以。
云计算的特点:
- 大规模、分布式
“云”一般具有相当的规模,一些知名的云供应商如Google云计算、Amazon、IBM、微软、阿里等也都拥能拥有上百万级的服务器规模。而依靠这些分布式的服务器所构建起来的“云”能够为使用者提供前所未有的计算能力。 - 虚拟化
云计算都会采用虚拟化技术,用户并不需要关注具体的硬件实体,只需要选择一家云服务提供商,注册一个账号,登陆到它们的云控制台,去购买和配置你需要的服务(比如 云服务器,云存储,CDN等等),再为你的应用做一些简单的配置之后,你就可以让你的应用对外服务了,这比传统的在企业的数据中心去部署一套应用要简单方便得多。而且你可以随时随地通过你的PC或移动设备来控制你的资源,这就好像是云服务商为每一个用户都提供了一个IDC(Internet Data Center)一样。 - 高可用性和扩展性
那些知名的云计算供应商一般都会采用数据多副本容错、计算节点同构可互换等措施来保障服务的高可靠性。基于云服务的应用可以持续对外提供服务(7*24小时),另外“云”的规模可以动态伸缩,来满足应用和用户规模增长的需要。 - 按需服务
用户可以根据自己的需要来购买服务,甚至可以按使用量来进行精确计费。这能大大节省IT成本,而资源的整体利用率也将得到明显的改善。 - 安全
网络安全已经成为所有企业或个人创业者必须面对的问题,企业的IT团队或个人很难应对那些来自网络的恶意攻击,而使用云服务则可以借助更专业的安全团队来有效降低安全风险。
云计算分类
(1)从服务的方式上来看分为公有云、私有云和混合云。
许多企业和个人用户共同使用的云环境叫作公有云,在这种模式中用户无须拥有和管理基础设施,它提供的是广泛的外部用户的资源共享模式。在公有云中所有用户共享一个公共资源,由第三方提供。亚马孙、谷歌是主流的公有云模式的服务机构。
确保用户数据安全所形成的服务模式就是私有云,把企业的有效数据存放在云计算的供应商里,那这就关系到了数据安全和管理能力的可靠性和安全性的问题。所以私有云重点要求的不只是计算能力方面的提高,更加侧重于其关键的安全性和可靠性。
混合云是包括私有云与公有云的完善的云环境。用户可以根据自己的需求选择适合自己的规则和策略的不同模式。因为混合云主要适合金融机构、政府机构、大型企业等,所以对混合云的技术和功能的要求相对完备。
(2)从服务类型分类包括基础设施即服务、平台即服务和软件即服务
SaaS(目前应用最为广泛):这一模式主要是为客户提供应用软件类的服务。有关供应商将其应用软件全部共享在其“云端”服务器上,在互联网作用下,使用户享受其服务,并依据需求进行订购,费用计算以时间、数量为主,用户只要通过Web浏览器就可以获取服务。SaaS与PaaS的区别在于,使用SaaS的不是软件的开发人员,而是软件的最终用户。
IaaS:在互联网的作用下,供应商将不同服务器集群后所形成的“云端”等基础设施作为基本量来为客户提供服务,其服务种类包括服务的虚拟化以及资源存储等,该服务类型属于硬件托管式,用户对供应商提供的硬件采取服务使用的方式进行。
PaaS:这种方式主要是为用户提供开发软件平台以及相关研发环境为主,通过其提供的开发平台,客户能自行研发各种程序,并在互联网的作用下得到使用。用户使用PasS的模式与SaaS具有相同之处,不同之处在于前者是开发软件的平台,而后者是应用软件的平台。
第十章 日志
Linux的systemd journal试图为混乱的日志记录理清思路。journal收集消息,将其以索引过的压缩二进制格式保存,并提供了用于日志浏览及过滤的命令行接口。journal可以独立存在,也可以与syslog守护进程并存。
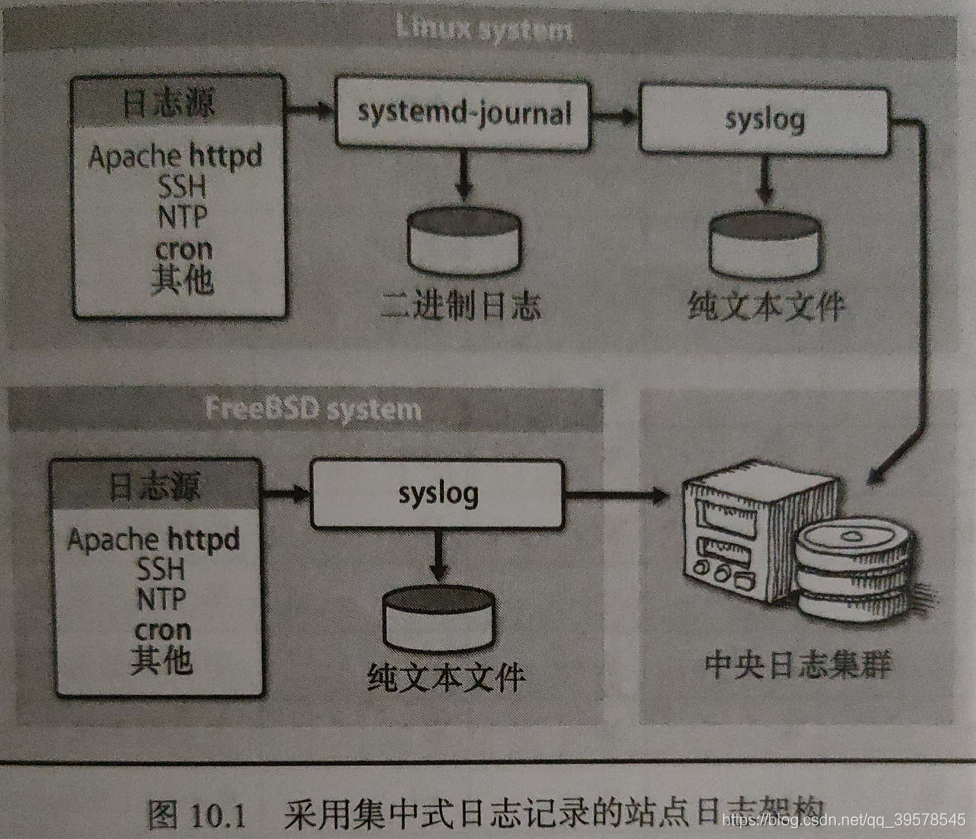
1、日志journal
日志文件会迅速增长,尤其是像Web、数据库、DNS服务器这种繁忙的服务。失控的日志文件会填满磁盘,造成系统超载。有鉴于此,最好是把/var/log挂载到单独的磁盘分区。如需系统间转发日志消息,坚持使用syslog
如何查看systemd journal中的日志?
使用journalctl命令,该命令会打印出systemd journal中的消息。你可以查看所有的消息,或是用-u选项选择查看特定服务单元的日志。也可以按照时间段、进程ID,甚至是可执行文件的路径等条件进行过滤。
例如:显示SSH守护进程的日志
$ journalctl -u ssh
journalctl -f 会在出现新消息将其打印出来。该功能和tail -f一样,都可以用于跟踪有新内容出现的纯文本文件。
————————
systemd journal
systemd包含了一个叫作systemd-journald的日志记录守护进程。它复制了syslog的大部分功能,syslog通常会将日志消息保存为纯文本文件,而systemd journal的做法是将消息保存为二进制格式。所有的消息属性都会被自动索引,这使得日志搜索起来更容易、更快。可以使用journalctl命令查看保存在journal中的消息。
journal从以下几处地方收集并索引消息。
- 通过套接字/dev/log,从那些按照syslog规范提交消息的软件处获取。
- 通过设备文件/dev/kmsg,收集由kernel产生的消息。systemd journal守护进程取代了传统的klogd进程,后者之前负责侦听/dev/kmsg,将内核消息转发给syslog。
- 套接字 /run/systemd/journal/stdout为通过标准输出写入日志消息的软件服务。
- 套接字 /run/systemd/journal/socket为通过systemd journal API提交日志消息的软件服务
- 内核守护进程auditd的审计消息。
————————
配置systemd journal
systemd journal默认的配置文件是/etc/systemd/journald.conf,但此文件并不能直接编辑。你能做的是将定制好的配置放入目录/etc/systemd/journald.conf.d。其下所有以扩展名.conf结尾的文件内容都会被自动并入journal的配置。要想加入自己的配置,只用在该目录下创建新的.conf文件并在文件中写入所需的配置即可。
默认的journald.conf中包含的所有选项都处于注释状态,而且都已经设置好了默认值,因此能一眼就看出来哪些选项可用。其中包括日志的最大容量、消息的留存期以及各种速率限制设置。
Storage选项控制着是否将日志保存到磁盘。
- volatile:只将日志保存在内存中
- persistent:将日志保存在/var/log/journal/,如果该目录不存在则自动创建
- auto:将日志保存在/var/log/journal,但并不会自动创建目录。这也是默认的选项值。
- none:丢弃所有的日志数据。
示例:建立定制配置目录journald.conf.d,然后生成配置文件,将Storage选项设置为persistent,接着重启journal服务,使新设置生效。systemd-journald会在所创建的目录中保存日志。
# mkdir /etc/systemd/journald.conf.d/
# cat << END > /etc/systemd/journald.conf.d/storage.conf
[Journal[
Storage=persistent
END
# systemctl restart systemd-journald
————————
journalctl的过滤选项 journalctl --help
要想让普通用户无需sudo权限就能够读取日志,那可以将其添加到systemd-journal组。
-dmesg选项,可以查看内核与引导期间的日志记录。
--disk-usage选项,可以显示日志所占用的磁盘空间
--list-boots选项,可以显示出一个带有数字标识符的系统引导顺序表,最近的引导总是0。行尾的日期分别显示了在引导期间,第一条消息和最后一条消息产生的时间戳。
-b选项,限制仅显示特定的引导会话。例如,查看当前会话期间由SSH产生的日志。
# journalctl-b 0 -u ssh
显示自昨日午夜开始,直至现在的所有信息。
# journalctl --since=yesterday --until=now
显示特定程序最近的100条日志。
# journalctl -n 100 /usr/sbin/sshd
journal与syslog是共存的。syslog可以检索来自journal服务的日志消息。
2、syslog
syslog是一套全面的日志记录系统。在Linux系统中,最初的syslog守护进程(syslogd)已经被更新的实现rsyslog(rsyslogd)所替代。rsyslog是一个开源项目,在扩展了原先的syslog功能的同时保持了API的向后兼容性。

rsyslog架构
把日志消息和rsyslog分别想象成事件流和处理事件流的引擎。提交的日志消息“事件”作为输入,由过滤器处理,然后被转发到输出目标。在rsyslog中,每个阶段都是一个模块,可以独立配置。rsyslog默认的配置文件是/etc/rsyslog.conf。
如果修改了/etc/rsyslog.conf或者其中包含的文件,那么必须重启rsyslogd守护进程才能使改动生效。TERM信号会终止该守护进程。HUP信号会使rsyslogd关闭所有打开的日志文件,HUP信号有助于日志轮替。
rsyslogd进程通常从引导时就开始持续运行。知晓syslog的程序会将日志记录写入特殊文件/dev/log,这是一个UNIX域套接字。在没有使用systemd系统的常用配置中,rsyslogd直接从该套接字读取消息,查询其配置文件。
rsyslog配置
/etc/ryslog.conf中的设置控制着rsyslogd的行为。rsyslog配置文件中的各行按照出现的先后顺序,自上而下处理,顺序在这里非常重要。在配置目录中的额外文件(通常是/etc/rsyslog.d/*.conf),为了考虑到顺序,可以通过在文件名前放置数字来组织文件。例如
20-ufw.conf
21-cloudinit.conf
50-default.conf
rsyslog按照字典顺序将这些文件的内容插入到/etc/rsyslog.conf,从而形成最终的配置。
-
模块
rsyslog模块拓展了核心处理引擎的能力。所有的输入(源)和输出(目标)都可以通过模块配置,模板甚至可以解析并修改消息。模块名前缀,以im开头的是输入模块,om开头的是输出模块,mm开头的。 -
sysklogd语法
Rsyslog详解:https://blog.csdn.net/qq_39578545/article/details/105030690该格式主要是为了将特定类型的消息引向指定的目标或网络地址,其基本形式为: selector action selector(选择器)与action(操作)之间由一到多个空格或制表符分隔,例如: auth.* /var/log/auth.log 该行可以将与认证相关的消息保存到文件/var/log/auth.log中。 选择器采用以下语法标识发送日志消息的源程序(“设施”)以及消息的优先级(“严重性”)。 facility.severity 设施名和严重级别必须从一组已定义好的值中选择,程序不能自己去定义。 选择器可以包含特殊关键字*和none。 选择器出现多个设施,用逗号分隔。 多个选择器用分号进行组合。一般而言,选择器之间是“或”的关系,匹配某个选择器的消息交由action处理。但是,严重级别为none的选择器会排除所列出的所有设施,无论同行中的其他选择器如何定义。
下列是一些选择器的写法及组合的例子。facility.level action facility1,facility2.level action #意思是facility1.level 和 facility2.level facility1.level;facility2.level2 action *.level action *.level;badfacility.none action #意思是排除列出的所有设施,除了badfacility 日志定义相关符号 . 用来分隔服务和级别 * 任何服务,或者任何级别 = 有等号表示等于某一级别,没有等号表示大于或者等于某一级别 ! 排除操作,前面有相同服务的表达式,这个操作才有意义 代表从前面表达式所包含的内容中排除某些内容 ; 用于分隔不同的 服务,级别,组合 , 用于分隔不同服务 - 用于指定目标文件时,代表异步写入 //不着急实时,等待一下再一起加。 同步写入操作有助于在出现系统崩溃时尽可能多地保留日志信息,但对于繁忙的日志文件,这种行为会急剧降低I/O性能。
级别从严重到轻微——》01234567,7是debug最低级。级别允许字符=和!出现,分别表明“仅适用于该级别”以及除此级别以及更高级别。如下是级别限定符示例。
| 选择器 | 含义 |
|---|---|
| auth.info | 与授权相关的消息,级别为info以上(包括info) |
| auth.=info | 仅限级别为info的消息 |
| auth.info;auth.!err | info级别以上的信息,不包括err级别信息 |
| auth.debug;auth.!=warning | 除warning之外的所有级别 |
# 所有info级别以上的信息,不包括mail类型所有级别和authpriv类型的err级别信息,
# 记录到/var/log/messages文件,-表示不立即写入
*.info;mail.none;authpriv.!err -/var/log/messages
如下是action字段处理消息的操作
| 操作 | 含义 |
|---|---|
| filename | 将消息追加到本地主机上的文件 |
| @hostname | 将消息转发到hostname上的rsyslogd |
| @ipaddress | 将消息转发到ipaddress上的UDP端口514 |
| @@ipaddress | 将消息转发到ipaddress上的TDP端口514 |
|fifoname |
将消息写入命名管道fifoname |
| user1,user2,… | 将消息写在指定user的屏幕上(如果已登录) |
| * | 将消息写在所有已登录用户的屏幕上 |
| ~ | 丢弃消息 |
| ^program;template | 根据template指定的规格改格式化消息,将其作为首个参数发送给program |
如果action字段指定的是filename,名称应该采用绝对路径。如果指定的文件名不存在,当消息首次被导向该文件时,rsyslogd会自动创建文件。文件的所有权和权限由全局配置指令来指定。
-
遗留指令:这指令多用于配置模块和rsyslogd守护进程本身
在实际的消息过滤和处理中,应该坚持采用sysklogd或RainerScipt格式。
守护进程本身和模块配置都很简单,例如,下面的选项在标准的syslog端口(TCP/UDP 514)上启用了日志记录,另外还允许向客户端发送保活分组(keep-live packets),避免TCP连接关闭,这样降低了重建超时连接所带来的的成本$ModLoad imudp $UDPServerRun 514 $ModLoad imtcp $InputTCPServerRun 514 $InputTCPServerKeepAlive on 要想让这些选项生效,可以将其放入一个新文件中,然后将该文件包含在主配置文件中(如/etc/rsyslog.d/10-network-inputs.conf),然后重启rsyslogdrsyslog遗留配置选项
项 目的 $MainMsgQueueSize 消息队列大小(对于速度缓慢的输入,如数据库插入操作) $MaxMessageSize 默认为8KB;必须出现在任何输入模块载入之前 $LocalHostName 覆盖本地主机名 $WorkDirectory 指定将rsyslog的工作文件保存到哪里 $ModLoad 载入模块 $MaxOpenFiles 修改rsyslogd默认的系统nofile限制 $IncludeConfig 包括额外的配置文件 $UMASK 设置由rsyslogd创建的新文件的umask -
RainerScript
RainerScript是一种带有过滤和控制流功能的事件流处理语言。理论上,可以通过RainerScript设置基本的rsyslogd选项。
(1)可以使用global()配置对象设置守护进程全局参数。global ( workDirectory="/var/spool/rsyslog" maxMessageSize="8192" ) 大多数遗留指令在RainerScript中有同名的对应。如上面的workDirectory和maxMessageSize。 该配置等价的遗留语法如下。 $WorkDirectory /var/spool/rsyslog $MaxMessageSize 8192(2)载入UDP和TCP模块
module(load="imudp") input(tpe="imudp" port="514") module(load="imtcp" KeepAlive="on") input(tpe="imtcp" port="514")在RainerScript中,每个模块都有
模块参数和输入参数。模块只载入一次,输入参数可以多次应用于同一个模块。如下:让rsyslog同时侦听TCP端口514和1514。module(load="imtcp" KeepAlive="on") input(type="imtcp" port="514") input(type="imtcp" port="1514")(3)认证相关的消息写入/var/log/auth.log
if $syslogfacility-text == 'auth' then { action(type="omfile" file="/var/log/auth.log") }在这个例子中,
$syslogfacility-text是一个消息属性,也就是消息元数据的一部分。在属性之前加上$符号表名此为变量。在这个例子中,处理方法是使用输出模块omfile将匹配的消息写入文件auth.log。
常用的ryslog消息属性
| 属性 | 含义 |
|---|---|
| $msg | 消息的文本内容,不包括元数据 |
| $rawmsg | 所接收到的完整消息,包括元数据 |
| $hostname | 消息中的主机名 |
| $syslogfacility | 设施(数字形式) |
| $syslogfacility-text | 设施(文本形式) |
| $syslogseverity | 严重性(数字形式) |
| $syslogseverity-text | 严重性(文本形式) |
| $timegenerated | rsyslogd接收到消息的时间 |
| $timereported | 消息自身的时间戳 |

3、syslog配置文件示例
在本节中,展示3个rsyslog配置文件示例。第一个配置虽然简单,但功能完备,可用于将日志消息写入文件。第二个配置是一个日志记录客户端,能够将syslog消息和httpd访问及错误日志转发到中央日志服务器。第三个配置是一个可以从各种日志记录客户端接收日志消息的日志服务器。
1.rsylog基础配置
下面的文件可作为一个通用的RainerScript rsyslog.conf文件,用于所有的Linux系统。
module(load="imuxsock") # Local system logging
module(load="imklog") # Kernel logging
module(load="immark" interval="3600") # Hourly mark messages
# Set global rsyslogd parameters
global (
workDirectory = "/var/spool/rsyslog"
maxMessageSize = "8192"
)
# The output file module does not need to be explicitly loaded,
# but we can load it ourselves to override default parameter values.
module(load="builtin:omfile"
# Use traditional timestamp format
template="RSYSLOG_TraditionalFileFormat"
# Set the default permissions for all log files.
fileOwner="root"
fileGroup="adm"
dirOwner="root"
dirGroup="adm"
fileCreateMode="0640"
dirCreateMode="0755"
)
$IncludeConfig /etc/rsyslog.d/*.conf
例子开头是rsyslogd的几个默认的日志收集选项。新日志文件默认的权限0640要比omfile默认的权限0644更为严格。
2.网络日志记录客户端
该日志记录客户端会将系统日志和Apache访问及错误日志通过TCP转发到远程服务器。
# Send all syslog messages to the server; this is sysklogd syntax
*.* @@logs.admin.com
# imfile reads messages from a file
# inotify is more efficient than polling
# It's the default,but note here for illustration
module(load="imfile" mode="inotify")
# Import Apache logs through the imfile module
input(type="imfile"
Tag="apache-access"
File="/var/log/apache2/access.log"
Serverity="info"
)
input(type="imfile"
Tag="apache-error"
File="/var/log/apache2/error.log"
Serverity="info"
)
# Send Apache logs to the central log host
if $programname contains 'apache' then {
action(type="omfwd"
Target="logs.admin.com"
Port="514"
Protocol="tcp"
)
}
Apache httpd默认不会将消息写入syslog,因此访问及错误日志是使用imfile从文本文件读取的。httpd可以利用mod_syyslog直接写入syslog,在这使用imfile只是为了演示。
文件末尾的if语句是一个用于搜索Apache消息的过滤器表达式,然后搜索到的消息转发给中央日志服务器logs.admin.com。
3.中央日志记录服务器
对应的中央日志记录服务器的配置很简单:在TCP端口514上侦听传入的日志,依据日志类型过滤,然后将其写入站点日志目录内的文件。
# Load the TCP input module and listen on port 514
# Do not accept more than 500 simultaneous clients
module(load="imtcp" MaxSessions="500")
input(type="imtcp" port="514")
# Save to dirfferenet files based on the type of message
if $programname == 'apache-access' then {
action(type="omfile" file="/var/log/site/apache/access.log")
} else if $programname == 'apache-error' then {
action(type="omfile" file="/var/log/site/apache/error.log")
} else {
action(type="omfile" file="/var/log/site/syslog")
}
中央日志记录服务器在写出消息时回味每个消息生成时间戳。Apache消息包含着另一个时间戳,这是httpd在记录该消息时生成的。
4、日志轮转logrotate
https://blog.csdn.net/qq_39578545/article/details/105030690
/etc/cron.daily/logrotate 周期性计划任务
/etc/logrotate.conf 配置文件
/etc/logrotate.d 子配置文件存放路径
★/etc/logrotate.conf 配置文件
#cat /etc/logrotate.conf
# see "man logrotate" for details
# rotate log files weekly
weekly
# keep 4 weeks worth of backlogs 保留4周备份日志
rotate 4
# create new (empty) log files after rotating old ones
create
# use date as a suffix of the rotated file 日期作为后缀给旧文件重命名
dateext
# uncomment this if you want your log files compressed
#compress
# RPM packages drop log rotation information into this directory
include /etc/logrotate.d 加载外部目录
# no packages own wtmp and btmp -- we'll rotate them here
/var/log/wtmp {
monthly
create 0664 root utmp
minsize 1M
rotate 1 保留1份日志文件,每一个月备份一次日志文件
}
/var/log/btmp {
missingok
monthly
create 0600 root utmp
rotate 1
}
# system-specific logs may be also be configured here.
常见的一些参数:
daily 指定转储周期为每天
monthly 指定转储周期为每月
weekly 每周轮转一次
rotate 4 同一个文件最多轮转4次,4次之后就删除该文件
create 0664 root uttmp 轮转之后创建新文件,权限是0664,属于root用户和utmp组
dateext 用日期来做轮转之后的文件的后缀名
compress 用gzip对轮转后的日志进行压缩
minsize 30K 文件必须大于30k,且周期到了,才会轮转
size 30K 文件大于30k才会轮转,不论周期是否已到
missingok 如果日志文件不存在,不报错
notifempty 如果日志文件是空的,不轮转
delaycompress 下一次轮转的时候才压缩,推迟一个轮替周期。该选项会导致出现3种类型的日志文件:活跃的、之前已经被轮替但尚未被压缩的、已经被压缩并轮替的。
sharedscripts 不管有多少个文件待轮转,prerotate和postrotate代码只执行一次
prerotate 如果符合轮转的条件,则在轮转之前执行prerotate和endscript之间的shell代码
postrotate 轮转完成后执行postrotate和e
★/etc/logrotate.d
[root@server~]# cat /etc/logrotate.d/syslog
这个子配置文件,没有指定的参数都会以默认方式轮转
/var/log/cron
/var/log/maillog
/var/log/messages
/var/log/secure
/var/log/spooler
{
sharedscripts 不管有多少个文件待轮转,prerotate和postrotate代码只执行一次
postrotate 转换完后执行postrotate和endscirpt之间的shell代码
/bin/kill -HUP `cat /var/run/syslogd.pid 2> /dev/null` 2> /dev/null || true
轮转后对rsyslog的pid进行刷新(但pid其实不变) || 或关系
endscript
}
TERM信号会终止该守护进程。HUP信号会使rsyslogd关闭所有打开的日志文件,这有助于日志轮替(更名并重启)。rsyslogd会将自己的进程ID写入/var/run/syslogd.pid,
第十一章 驱动程序与内核
内核提供的接口包括以下种基本功能:
- 硬件设备的管理与抽象
- 进程和线程(以及之前的通信方式)
- 内存管理(虚拟内存和内存空间保护)
- I/O设施(文件系统、网络接口、串口等)
- 内务管理功能(启动、关机、定时器、多任务等)
内存管理系统为每个进程定义了地址空间,创建一种假象:进程拥有一块无限的连续内存区域。实际上,不同进程的内存页面全都混乱地堆放在系统的物理内存中。只有内核的记账和内存保护机制才能分清它们。
1、设备管理
设备文件
主设备号标识了与该文件关联的驱动程序(也就是设备类型)。次设备号通常标识了指定设备类型的某个实例。次设备号有时也叫作单元号。
ls -l命令可以查看设备文件的主设备号和次设备号
$ ls -l /dev/sda
brw-rw---- 1 root disk 8,0 Jul 13 01:39 /dev/sda
其主设备号为8,次设备号为0.
设备文件实际上有两种类型
- 块设备文件
- 字符设备文件
设备管理
udevd的工作方式里是通过sysfs这个设备信息仓库中获取原始数据的。
udevadm:探究设备
udevadm命令可以查询设备信息、触发事件、控制udevd守护进程、监视udev和内核事件。
udevadm要求使用以下6个命令中的其中一个作为其首个参数:info、trigger、settle、control、monitor、test。
其中info可以输出设备特定的信息,control可以启动/停止udev守护进程或是强制重新载入规则文件,monitor可以显示出发生过的事件。
$ udevadm info -a -n sdb
udevadm输出的所有路径(例如?devices/pci0000:00/..),即使看起来是绝对路径的形式,也都是相对于/sys的。
udevd依赖于一套规则来指定设备管理。默认规则位于目录/lib/udev/rules.d,本地规则位于目录/etc/udev/rules.d。你不用去编辑或删除默认规则,只需要在本地规则目录中创建一个同名的新文件就可以忽略或覆盖掉默认规则了。规则文件的名称后缀.rules是强制性的,没有该后缀的文件会被忽略。
udevd的主配置文件是/etc/udev/udev.conf
具体用到再详细看。
2、内核配置
调整内核参数
(1)修改系统一次性能够打开的文件最大数量(系统重启后,做出的改动会失效)
echo 32768 > /proc/sys/fs/file-max
(2)关闭IP转发功能 —— 通过命令行或配置文件的一系列variable=value来设置变量。sysctl(一劳永逸),默认情况在引导期间/etc/sysctl.conf会被读取。
sysctl net.ipv4.ip_forward=0
可装载内核模块(LVM)
使用lsmod命令检查当前装载的模板
$ lsmod
手动装载内核模块
插入一个模块,实现向USB设备输出声音
$ modprobe snd-usb-audio