按时日更
一、存储器结构
内存的数据会被加载到 CPU 的寄存器和 Cache 中
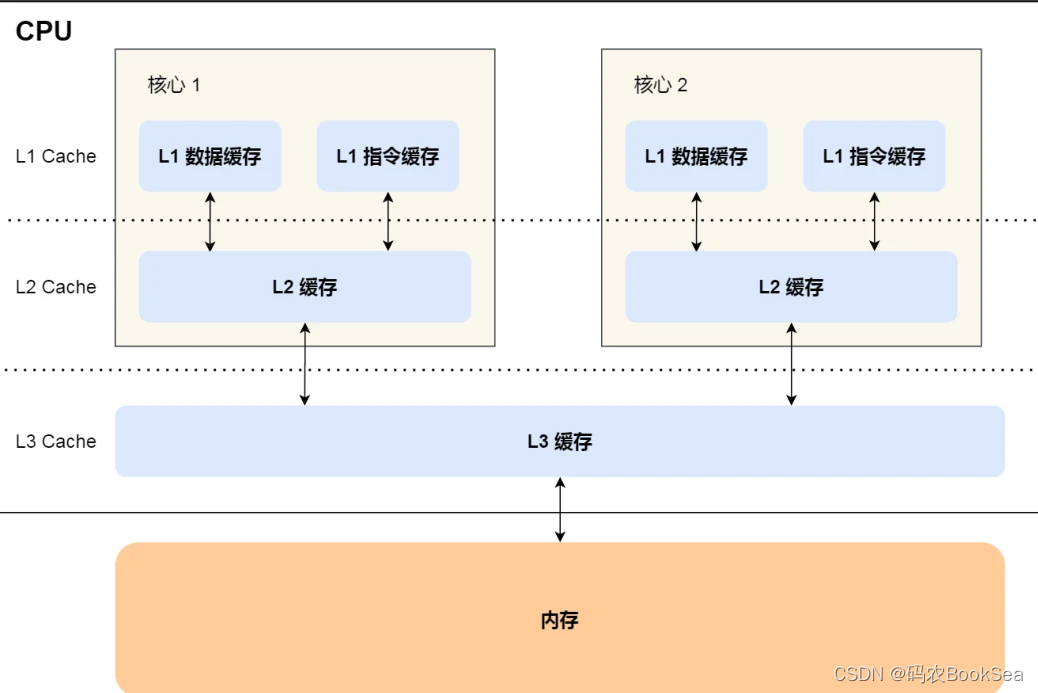
CPU Cache也在CPU里,称为CPU高速缓存,分L1,L2和L3。L1体积最小,离的最近。L1可分为数据缓存和指令缓存
CPU Cache ⽤的是⼀种叫 SRAM(Static Random-Access Memory,静态随机存储器)的芯⽚。SRAM 之所以叫「静态」存储器,是因为只要有电,数据就可以保持存在,⽽⼀旦断电,数据就会丢失了。
CPU存储速度排行: 寄存器>L1>L2>L3>内存。
CPU的多个核共用L3,多个CPU共用内存,L1和L2是每个核心都有的。
牢记下面这幅图:
牢记住这句话,非常重要:
CPU 并不会直接和每⼀种存储器设备直接打交道,⽽是每⼀种存储器设备只和它相邻的存储器设备打交道
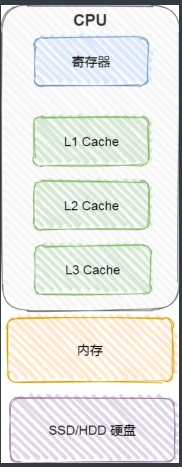
⽐如,CPU Cache 的数据是从内存加载过来的,写回数据的时候也只写回到内存,CPUCache 不会直接把数据写到硬盘,也不会直接从硬盘加载数据,⽽是先加载到内存,再从内存加载到 CPU Cache 中。
内存中的数据加载到共享的 L3 Cache 中,再加载到每个核⼼独有的 L2,Cache,最后进⼊到最快的 L1 Cache,之后才会被 CPU 读取。
当 CPU 需要访问内存中某个数据的时候,如果寄存器有这个数据,CPU 就直接从寄存器取数据即可,如果寄存器没有这个数据,CPU 就会查询 L1 ⾼速缓存,如果 L1 没有,则查询 L2 ⾼速缓存,L2 还是没有的话就查询 L3 ⾼速缓存,L3 依然没有的话,才去内存中取
数据。
可以发现层次是具有结构性的,加载的时候从下到上,读取的时候从上到下,说白了跟我上篇讲的一样还是就近原则,每个存储器跟距离它最近的存储器打交道。
二、如何提高缓存命中率
CPU Cache 的数据是从内存中读取过来的,它是以⼀⼩块⼀⼩块读取数据的,⽽不是按照单个数组元素来读取数据的,在 CPU Cache 中的,这样⼀⼩块⼀⼩块的数据,称为 Cache Line(缓存块),一般是64字节。
而这一块的数据在内存中被称为内存块
⽐如,有⼀个 int array[100] 的数组,当载⼊ array[0] 时,由于这个数组元素的⼤⼩在内存只占 4 字节,不⾜ 64 字节,CPU 就会顺序加载数组元素到 array[15] ,意味着array[0]~array[15] 数组元素都会被缓存在 CPU Cache 中了,因此当下次访问这些数组元素时,会直接从 CPU Cache 读取,⽽不⽤再从内存中读取,⼤⼤提⾼了 CPU 读取数据的性能。注意:不是说一定要64字节,从前往后加载,有多少加载多少,最多64字节
那 CPU 怎么知道要访问的内存数据,是否在 Cache ⾥?如果在的话,如何找到 Cache 对应的数据呢?说白了内存块如何和缓存块联系到一起?
内存地址映射到 CPU Cache 地址⾥的策略有很多种,其中最简单的是直接映射 Cache (Direct Mapped Cache)
举个例⼦,内存共被划分为 32 个内存块,CPU Cache 共有 8 个 CPU Line,假设 CPU 想要
访问第 15 号内存块,如果 15 号内存块中的数据已经缓存在 CPU Line 中的话,则是⼀定映
射在 7 号 CPU Line 中,因为 15 % 8 的值是 7。
这样就将内存块和缓存块绑定到了一起
额外拓展一个点:
CPU里有个分⽀预测器,会动态地根据历史命中数据对未来进⾏预测,从而提前把数据缓存到Cache中,这样可以提高Cache的命中率。
所以CPU是“非常聪明”的。
三、多核CPU下的缓存命中率
我们都知道现代CPU是多核的,线程可能在不同 CPU 核⼼来回切换执⾏,虽然 L3 Cache 是多核⼼之间共享的,但是 L1 和 L2 Cache 都是每个核⼼独有的,如果⼀个进程在不同核⼼来回切换,各个核⼼的缓存命中率就会受到影响。
所以,可以试着把线程绑定在某⼀个 CPU 核⼼上,这样性能可以得到⾮常可观的提升,这是可以实现的,在Linux上可以通过命令将线程绑定到某个核心。