对于数据库来说安装,部署几乎是一次性的。后期的管理和优化是持续性的工作。
对于MySQL来说,可以说90%问题都在SQL语句上面。从问题SQL的筛选和优化,在MySQL环境下常用哪些方式。(以下版本是MySQL8.0.23)
MySQL优化前置知识基础
传统关系型数据库里面的优化器分为CBO(Cost_Based Potimizer)和RBO(Rule-Based Optimizer)两种
RBO :
RBO所用的判断规则是一组内置的规则,这些规则是硬编码在数据库的编码中的,RBO会根据这些规则去从SQL诸多的路径中来选择一条作为执行计划
RBO最大问题在于硬编码在数据库里面的一系列固定规则,来决定执行计划。并没有考虑目标SQL中所涉及的对象的实际数量,实际数据的分布情况,这样一旦规则不适用于该SQL,那么很可能选出来的执行计划就不是最优执行计划。
CBO :
CBO在会从目标诸多的执行路径中选择一个成本最小的执行路径来作为执行计划。这里的成本实际代表了MySQL根据相关统计信息计算出来目标SQL对应的步骤的IO,CPU等消耗。也就是意味着执行目标SQL所需要IO,CPU等资源的一个估计值。而成本值是根据索引,表,行的统计信息计算出来的。
MySQL里Cardinality是CBO特有的概念,它是指指定集合包含的记录数,说白了就是指定结果集的行数。Cardinality和成本值的估计息息相关,特别是IO资源消耗,随着该结果集的递增而递增。
通过SHOW INDEX结果中的列Cardinality来观察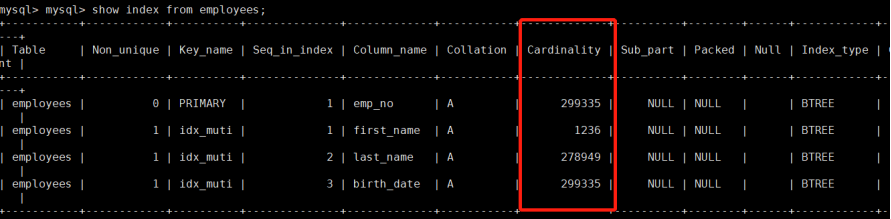
很多技术文章谈到MySQL是索引组织表,必须有主键。
1.索引组织表: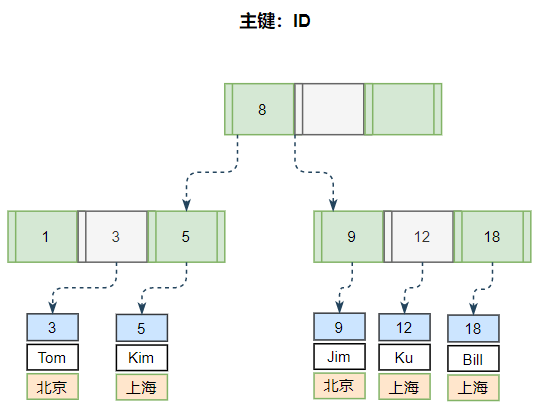
打个比喻,主键就是所有数据的大脑,所有的操作必须通过大脑来获取。所以SQL语句里有效使用索引是重之又重的手段。
2.二级索引-回表操作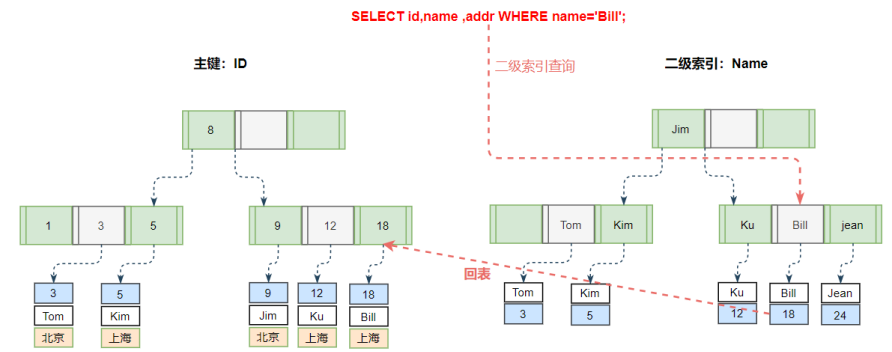
仅对二级索引获取结果是非常有效的,做到隔离的其他数据,但对于不在二级索引范围内的,就是回表操作,这部分需要谨慎考虑。
3.索引-其他注意:
- 结果集返回20%以上数据,不管索引是否存在,都会全表扫描;
- 通过数据集合小的表作为驱动表;
- 多个条件使用,使用组合索引;
- 索引键上不做运算;
备注:上面内容了解到MySQL成本计算方式,还有MySQL里索引组织表。所以应该有效使用索引。如当捕捉到到一个SQL语句的时候通过什么方式优化。
MySQL优化命令行
在实际不执行SQL语句的情况下,EXPLAIN可以说dba,开发人员常用的SQL优化命令行,EXPLAIN适用于SELECT、DELETE、INSERT、REPLACE和UPDATE语句,当EXPLAIN语句一起使用时,MySQL会显示优化器关于语句执行计划的信息。也就是说,MySQL解释了它将如何处理这条语句,包括有关表如何连接和以何种顺序连接的信息,EXPLAIN会展示预执行计划信息.
语法如下:
EXPLAIN
EXPLAIN FORMAT=TREE
EXPLAIN FORMAT=JSON
EXPLAIN ANALYZE
EXPLAIN [options] FOR CONNECTION
- EXPLAIN
MYSQL执行计划顺序普遍原则是:在所有组中,id值越大,优先级越高,越先执行,id如果相同,可以认为是一组,从上往下顺序执行
执行之前,要了解下显示字段代表意义: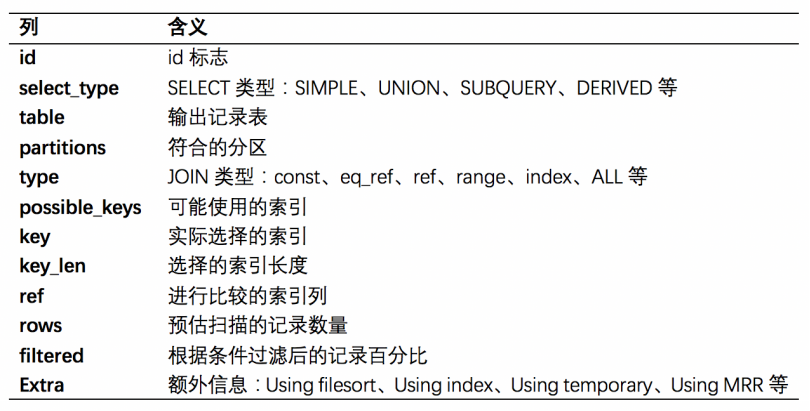
EXPLAIN:
EXPLAIN FORMAT=TREE:
EXPLAIN FORMAT=JSON:
备注:3种方式算是预评估计划,但实际可能按照当时的情况会有所变动。3种方式下多了一些字段:如 cost,read_cost,eval_cost prefix_cost,data_read_per_join都是估计的成本相关信息,所以这些成本信息仅作为参考。毫秒为单位
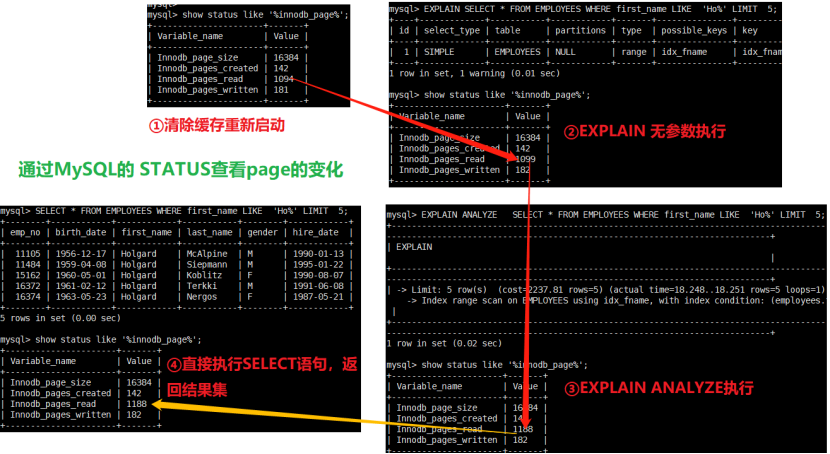
- EXPLAIN ANALYZE
MySQL 8.0.18引入了EXPLAIN ANALYZE,输出的信息是关于优化器估计执行成本和实际成本。
EXPLAIN ANALYZE可以用于SELECT语句,多表UPDATE和DELETE语句。
备注:结果集显示里多了actual time。为了确认这个是否实际成本。通过status观察值,EXPLAIN ANALYZE之后 实际执行SELECT时 page是否也没变化。
- EXPLAIN CONNECTION
EXPLAIN [options] FOR CONNECTION connection_id;
EXPLAIN FOR CONNECTION返回当前用于在给定连接中执行查询的解释信息。 对于长时间正在执行的SQL可以通过这个方式,获取当前执行的执行计划,延迟等原因。
connection_id是连接标识符,从INFORMATION_SCHEMA PROCESSLIST表或SHOW PROCESSLIST语句获得.对于自己是connection id 无效。
##session1
mysql> SELECT CONNECTION_ID();
+-----------------+
| CONNECTION_ID() |
+-----------------+
| 14 |
+-----------------+
1 row in set (0.00 sec)
mysql> select * from employees;
#session2
mysql> EXPLAIN FOR CONNECTION 14;
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------+
| 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 299556 | 100.00 | NULL |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------+

备注:第一次执行有效,后面执行多次无效,目前来看不完善的功能。也是一个便利的功能
2.PROFILE
PROFILE语句显示当前会话过程中执行的语句的资源使用情况。
SHOW PROFILE [type [, type] ... ] [FOR QUERY n] [LIMIT row_count [OFFSET offset]] type: { ALL | BLOCK IO | CONTEXT SWITCHES | CPU | IPC | MEMORY | PAGE FAULTS | SOURCE | SWAPS }
- ALL 显示所有性能信息
- BLOCK IO 显示块IO操作的次数
- CONTEXT SWITCHES 显示上下文切换次数,不管是主动还是被动
- CPU 显示用户CPU时间、系统CPU时间
- IPC 显示发送和接收的消息数量
- MEMORY [当前没有实现]
- PAGE FAULTS 显示页错误数量
- SOURCE 显示源码中的函数名称与位置
- SWAPS 显示SWAP的次数
mysql> show variables like '%profiling%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| have_profiling | YES |
| profiling | OFF |
| profiling_history_size | 15 |
+------------------------+-------+
mysql> SET profiling = 1;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> SELECT * FROM employees WHERE first_name like 'Ho%' limit 5;
+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+
| 11105 | 1956-12-17 | Holgard | McAlpine | M | 1990-01-13 |
| 11484 | 1959-04-08 | Holgard | Siepmann | M | 1995-01-22 |
| 15162 | 1960-05-01 | Holgard | Koblitz | F | 1990-08-07 |
| 16372 | 1961-02-12 | Holgard | Terkki | M | 1991-06-08 |
| 16374 | 1963-05-23 | Holgard | Nergos | F | 1987-05-21 |
+--------+------------+------------+-----------+--------+------------+
5 rows in set (0.00 sec)
mysql> SHOW PROFILES;
+----------+------------+-------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+-------------------------------------------------------------+
| 1 | 0.00568950 | SELECT * FROM employees WHERE first_name like 'Ho%' limit 5 |
+----------+------------+-------------------------------------------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> SHOW PROFILE FOR QUERY 1;
+--------------------------------+----------+
| Status | Duration |
+--------------------------------+----------+
| starting | 0.004549 |
| Executing hook on transaction | 0.000030 |
| starting | 0.000016 |
| checking permissions | 0.000319 |
| Opening tables | 0.000055 |
| init | 0.000008 |
| System lock | 0.000009 |
| optimizing | 0.000011 |
| statistics | 0.000071 |
| preparing | 0.000205 |
| executing | 0.000357 |
| end | 0.000007 |
| query end | 0.000005 |
| waiting for handler commit | 0.000011 |
| closing tables | 0.000008 |
| freeing items | 0.000022 |
| cleaning up | 0.000010 |
+--------------------------------+----------+
17 rows in set, 1 warning (0.00 sec)
mysql> SHOW PROFILE CPU FOR QUERY 1;
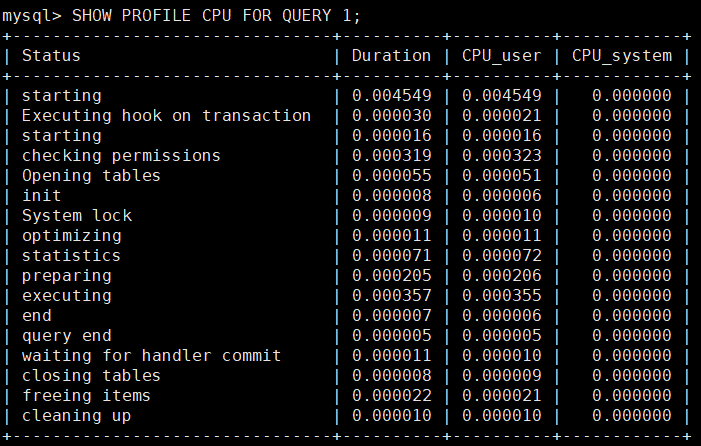
备注:资源方面影响SQL语句执行效率的时候,可通过这个方式获取信息,特别是IO,CPU,网络等方面的问题,能有效的定位。
3.OPTIMIZER_TRACE
优化器跟踪实际执行的过程,以帮助理解MySQL优化器所采取的决策和行动。
- optimizer_trace: enabled:启用/禁用optimizer_trace功能 , one_line:决定了跟踪信息的存储方式,为on表示使用单行存储,否则以JSON树的标准展示形式存储。
- optimizer_trace_features:该变量中存储了跟踪信息中可控的打印项,可以通过调整该变量,greedy_search,range_optimizerdynamic_range,repeated_subselect
- optimizer_trace_max_mem_size :optimizer_trace内存的大小,如果跟踪信息超过这个大小,信息将会被截断
- optimizer_trace_offset:则是约束偏移量。和 LIMIT 一样,optimizer_trace_offset 从0开始计算
使用方式:
1.SET OPTIMIZER_TRACE="enabled=on";
2.执行 sql 语句
3. SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE limit 30 \G;
4.关闭 SET OPTIMIZER_TRACE="enabled=off";
TRACE:过程
备注:3个大步骤 ,9个子步骤把每个过程都列出来。
在主从架构下(所有条件相等下)碰到SQL执行得到不一样的执行时间,可通过这个方式查找原因。
注意:
上述方法中,必须真正的执行语句才能得到结果如下:
- EXPLAIN ANALYZE;
- PROFILE;
- OPTIMIZER_TRACE;
所以合理使用
问题SQL语句抓取
MySQL怎样抓有问题的sql 语句。目前接触的经验,可以归纳为3个方面:
- 慢日志;
- performance_schema系统性能表;
- 业务的一些反馈, 死锁检查,jdbc探针,网络流量镜像 等方式;
下面只普遍的前2种方式说明。
最普遍常用的方式,当语句执行时间较长时,通过日志的方式进行记录,这种方式就是慢查询的日志。
开启慢查询日志,可以让MySQL记录下查询超过指定时间的语句,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能。
参数说明: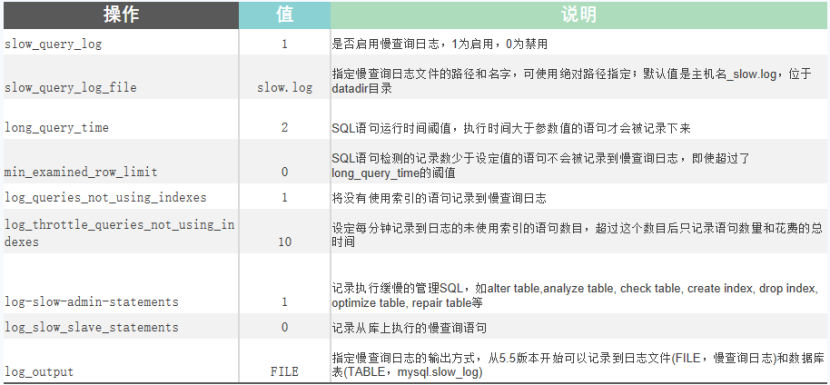
慢日志分析方式:
1)使用MySQL官方提供的开源工具mysqldumpslow进行分析
mysqldumpslow -t 10 /data/mysql/mysql-slow.log #显示出慢查询日志中最慢的10条sql
2)percona提供的pt-query-digest工具进行分析
pt-query-digest /data/mysql/mysql-slow.log
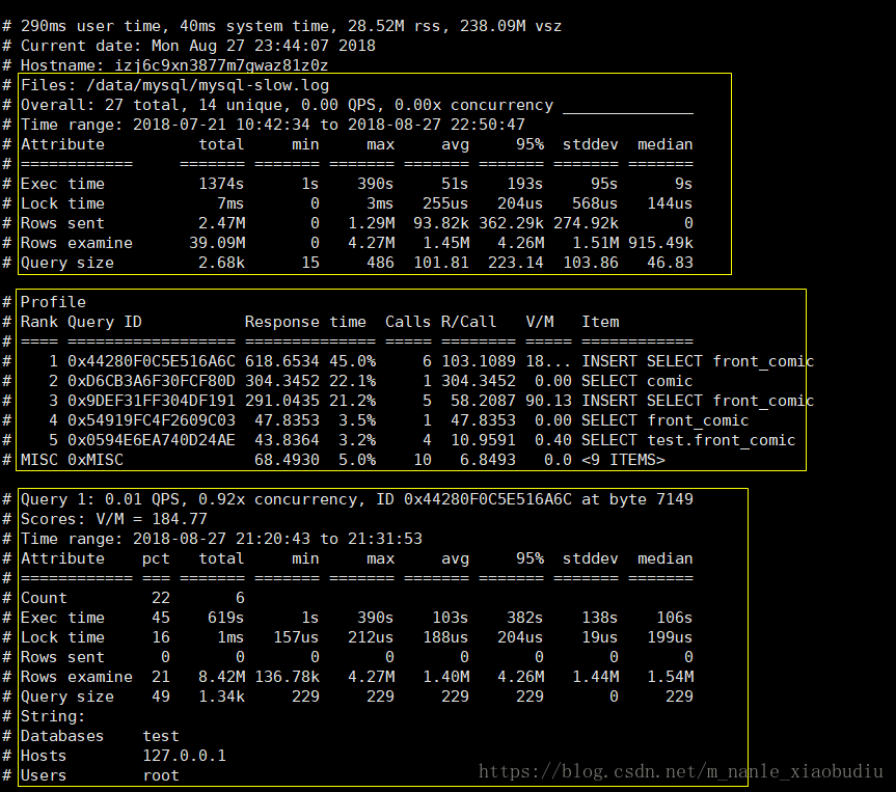
备注:
第一部分:显示出了日志的时间范围,以及总的sql数量和不同的sql数量。
第二部分:显示出统计信息。
第三部分:每一个sql具体的分析
如何通过pt-query-digest 慢查询日志发现有问题的sql
- 查询次数多且每次查询占用时间长的sql
通常为pt-query-digest分析的前几个查询 - IO消耗大的sql
注意pt-query-digest分析中的Rows examine项 - 索引命中统计
注意pt-query-digest分析中Rows examine(扫描行数) 和 Rows sent (发送行数)的对比 ,如果扫描行数远远大于发送行数,则说明索引命中率并不高。
2.events_statements_summary_by_digest统计的SQL语句
性能监控performance_schema下记录SQL执行情况:
events_statements_summary_by_digest:sql语句汇总统计数据,表结构说明如下: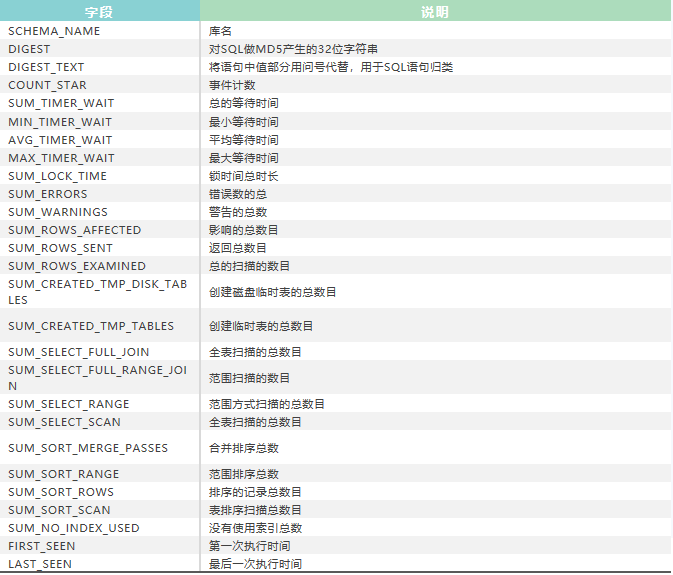
备注:数据行数performance_schema_digests_size控制,默认是10000,如果超过这个最大值,新的sql语句无法插入。
4.总结
SQL语句优化的需要了解MySQL的基础架构和一些体系架构方面的知识,再结合提供的命令行进行优化,也少不了问题SQL抓取方法。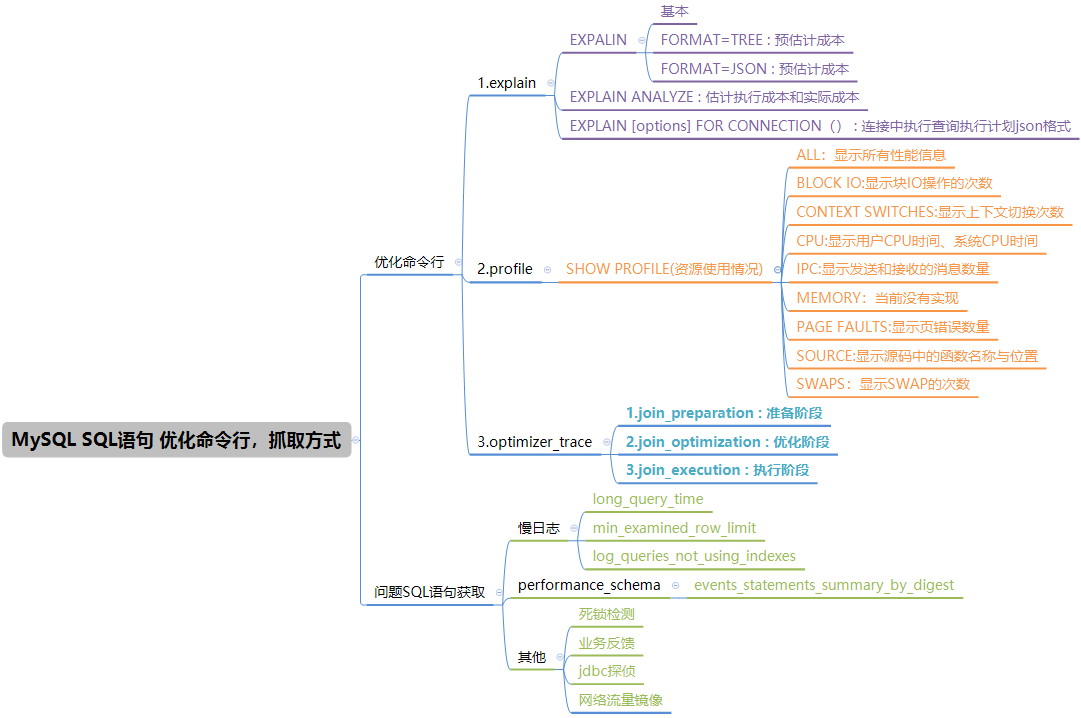
从小的细节开始关注。