前言
kubeadm是kubernetes官方提供的一种快速安装k8s集群的工具,在这里分享给大家
一、基础环境
1、配置主机名与解析
hostnamectl set-hostname master
hostnamectl set-hostname node1
hostnamectl set-hostname node2
vim /etc/hosts
172.31.103.123 master
172.31.103.124 node1
172.31.103.125 node2
2、配置SSH无密码登陆(三台服务器都需要免密)
ssh-keygen
ssh-copy-id -i id_rsa.pub [email protected].*
3、时间同步
(1)配置master节点
yum -y install chrony
systemctl start chronyd
timedatectl set-ntp true
vim /etc/chrony.conf
allow 172.31.103.0/24
local stratum 10
#重启时间同步服务
systemctl restart chronyd.service
(2)配置node节点
vim /etc/chrony.conf
#删掉哪些没用的server xxxxxxxxxx iburst
server 172.31.103.123 iburst
#同样需要重启同步服务,关闭防火墙
systemctl restart chronyd.service
#查看同步状态
chronyc sources -v
4、修改iptables相关参数(所有节点)
#RHEL / CentOS 7上的一些用户报告了由于iptables被绕过而导致流量路由不正确的问题。创建/etc/sysctl.d/k8s.conf文件,添加如下内容
vim /etc/sysctl.d/k8s.conf
vm.swappiness = 0
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
# 使配置生效
modprobe br_netfilter
sysctl -p /etc/sysctl.d/k8s.conf
#加载ipvs相关模块
#由于ipvs已经加入到了内核的主干,所以为kube-proxy开启ipvs的前提需要加载以下的内核模块,在所有的Kubernetes节点执行以下脚本
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
#执行脚本
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
#上面脚本创建了/etc/sysconfig/modules/ipvs.modules文件,保证在节点重启后能自动加载所需模块。 使用lsmod | grep -e ip_vs -e nf_conntrack_ipv4命令查看是否已经正确加载所需的内核模块。
#接下来还需要确保各个节点上已经安装了ipset软件包。 为了便于查看ipvs的代理规则,最好安装一下管理工具ipvsadm。
yum install ipset ipvsadm -y
5、安装docker
#配置docker yum源
yum install -y yum-utils
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
#安装docker
yum list docker-ce --showduplicates | sort -r
yum install -y docker-ce
systemctl start docker
systemctl enable docker
二、安装kubeadm、kubelet、kubectl
kubelet 在群集中所有节点上运行的核心组件, 用来执行如启动pods和containers等操作。
kubeadm引导启动k8s集群的命令行工具,用于初始化 Cluster。
kubectl 是 Kubernetes 命令行工具。通过 kubectl可以部署和管理应用,查看各种资源,创建、删除和更新各种组件。
1、配置kubernetes.repo的源,由于官方源国内无法访问,这里使用阿里云yum源(所有节点)
vim /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
#在所有节点上安装指定版本 kubelet、kubeadm 和 kubectl
yum install -y kubelet kubeadm kubectl
#启动kubelet服务
systemctl enable kubelet
systemctl start kubelet
2、部署master节点
(1)master节点执行初始化
#注意这里执行初始化用到了- -image-repository选项,指定初始化需要的镜像源从阿里云镜像仓库拉取。
kubeadm init \
--apiserver-advertise-address=172.31.103.123 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.14.1 \
--pod-network-cidr=10.244.0.0/16
#初始化命令说明
--apiserver-advertise-address
指明用 Master 的哪个 interface 与 Cluster 的其他节点通信。如果 Master 有多个 interface,建议明确指定,如果不指定,kubeadm 会自动选择有默认网关的 interface
--pod-network-cidr
指定 Pod 网络的范围。Kubernetes 支持多种网络方案,而且不同网络方案对 --pod-network-cidr 有自己的要求,这里设置为 10.244.0.0/16 是因为我们将使用 flannel 网络方案,必须设置成这个 CIDR
--image-repository
Kubenetes默认Registries地址是 k8s.gcr.io,在国内并不能访问 gcr.io,在1.13版本中我们可以增加–image-repository参数,默认值是 k8s.gcr.io
--kubernetes-version=v1.14.1
关闭版本探测,因为它的默认值是stable-1,会导致从https://dl.k8s.io/release/stable-1.txt下载最新的版本号
#执行初始化命令:
#注意记录下初始化结果中的kubeadm join命令,部署worker节点时会用到
kubeadm join 172.31.103.123:6443 --token sq57eo.r69ngz2xxsinpy4j --discovery-token-ca-cert-hash sha256:1172ab1462a3a9da22d3f816f1245ee37539b678a39de958a028204ce85a56c1
(2)配置 kubectl
kubectl 是管理 Kubernetes Cluster 的命令行工具,前面我们已经在所有的节点安装了 kubectl。Master初始化完成后需要做一些配置工作,然后 kubectl 就能使用了。 依照 kubeadm init 输出的最后提示,推荐用 Linux普通用户执行 kubectl。
#创建普通用户并设置密码123456
useradd centos && echo "centos:123456" | chpasswd centos
#追加sudo权限,并配置sudo免密
sed -i '/^root/a\centos ALL=(ALL) NOPASSWD:ALL' /etc/sudoers
#保存集群安全配置文件到当前用户.kube目录
su - centos
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
#启用 kubectl 命令自动补全功能(注销重新登录生效)
echo "source <(kubectl completion bash)" >> ~/.bashrc
#需要这些配置命令的原因是:Kubernetes 集群默认需要加密方式访问。所以,这几条命令,就是将刚刚部署生成的 Kubernetes 集群的安全配置文件,保存到当前用户的.kube 目录下,kubectl 默认会使用这个目录下的授权信息访问 Kubernetes 集群。如果不这么做的话,我们每次都需要通过 export KUBECONFIG 环境变量告诉 kubectl 这个安全配置文件的位置。配置完成后centos用户就可以使用 kubectl 命令管理集群了
#查看集群状态
kubectl get cs
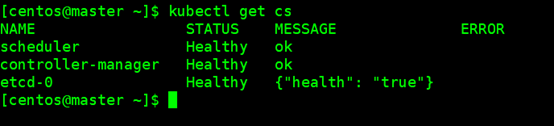
确认各个组件都处于healthy状态
查看节点状态
kubectl get nodes

#可以看到,当前只存在1个master节点,并且这个节点的状态是 NotReady。使用 kubectl describe 命令来查看这个节点(Node)对象的详细信息、状态和事件。
kubectl describe node master

#通过 kubectl describe 指令的输出,我们可以看到 NodeNotReady 的原因在于,我们尚未部署任何网络插件,kube-proxy等组件还处于starting状态。
kubectl get pod -n kube-system -o wide

可以看到,CoreDNS依赖于网络的 Pod 都处于 Pending 状态,即调度失败。这当然是符合预期的:因为这个 Master 节点的网络尚未就绪。
(3)部署网络插件
#要让 Kubernetes Cluster 能够工作,必须安装 Pod 网络,否则 Pod 之间无法通信。Kubernetes 支持多种网络方案,这里我们使用 flannel
#执行如下命令部署 flannel:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml

#部署完成后,我们可以通过 kubectl get 重新检查 Pod 的状态:
kubectl get pod -n kube-system -o wide

#可以看到,所有的系统 Pod 都成功启动了,而刚刚部署的flannel网络插件则在 kube-system 下面新建了一个名叫kube-flannel-ds-amd64-bp948的 Pod,一般来说,这些 Pod 就是容器网络插件在每个节点上的控制组件。
#Kubernetes 支持容器网络插件,使用的是一个名叫 CNI 的通用接口,它也是当前容器网络的事实标准,市面上的所有容器网络开源项目都可以通过 CNI 接入 Kubernetes,比如 Flannel、Calico、Canal、Romana 等等,它们的部署方式也都是类似的“一键部署”。
#再次查看master节点状态已经为ready状态:
kubectl get nodes

至此,Kubernetes 的 Master 节点就部署完成了。如果你只需要一个单节点的Kubernetes,现在你就可以使用了。不过,在默认情况下,Kubernetes 的 Master 节点是不能运行用户 Pod 的。
3、部署worker节点
#Kubernetes 的 Worker 节点跟 Master 节点几乎是相同的,它们运行着的都是一个 kubelet 组件。唯一的区别在于,在 kubeadm init 的过程中,kubelet 启动后,Master 节点上还会自动运行 kube-apiserver、kube-scheduler、kube-controller-manger 这三个系统 Pod。
#在 node1 和 node2 上分别执行如下命令,将其注册到 Cluster 中:
kubeadm join 172.31.103.123:6443 --token sq57eo.r69ngz2xxsinpy4j --discovery-token-ca-cert-hash sha256:1172ab1462a3a9da22d3f816f1245ee37539b678a39de958a028204ce85a56c1
#如果执行kubeadm init时没有记录下加入集群的命令,可以通过以下命令重新创建
kubeadm token create --print-join-command
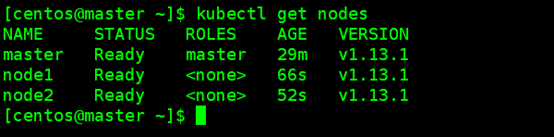
#重复执行以上操作将node2也加进去,然后根据提示,我们可以通过 kubectl get nodes 查看节点的状态:
kubectl get nodes
查看所有pod状态
kubectl get pod --all-namespaces -o wide
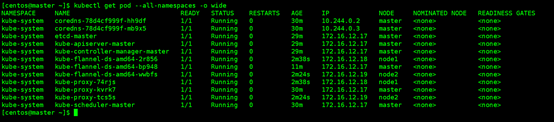
这时,所有的节点都已经 Ready,Kubernetes Cluster 创建成功,一切准备就绪。如果pod状态为Pending、ContainerCreating、ImagePullBackOff 都表明 Pod没有就绪,Running 才是就绪状态。
4、测试集群各个组件
#首先验证kube-apiserver, kube-controller-manager, kube-scheduler, pod network 是否正常
#部署一个 Nginx Deployment,包含2个Pod
kubectl create deployment nginx --image=nginx:alpine
kubectl scale deployment nginx --replicas=2
#查看状态
kubectl get pods -l app=nginx -o wide

#再验证一下kube-proxy是否正常:
#以 NodePort 方式对外提供服务
kubectl expose deployment nginx --port=80 --type=NodePort
kubectl get services nginx
#可以通过任意 NodeIP:Port 在集群外部访问这个服务
访问master
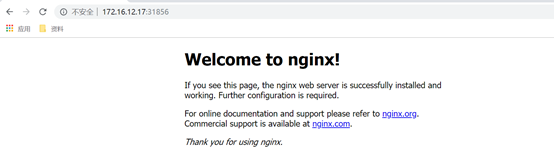
访问node1
访问node2
#最后验证一下dns, pod network是否正常:
#运行Busybox并进入交互模式
kubectl run -it curl --image=radial/busyboxplus:curl

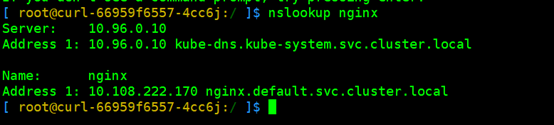
查看是否可以正确解析出集群内的IP,以验证DNS是否正常
nslookup nginx
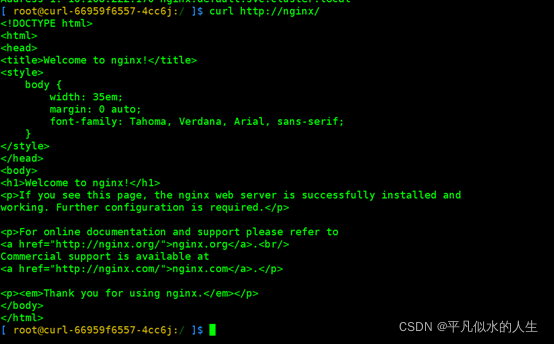
通过服务名进行访问,验证kube-proxy是否正常:
curl http://nginx/
分别访问一下2个Pod的内网IP,验证跨Node的网络通信是否正常
5、Pod调度到Master节点
#出于安全考虑,默认配置下Kubernetes不会将Pod调度到Master节点。查看Taints字段默认配置
kubectl describe node master | grep Tain
#如果希望将master也当作Node节点使用,可以执行如下命令,其中master是主机节点hostname
kubectl taint node master node-role.kubernetes.io/master-
#修改后Taints字段状态

#如果要恢复Master Only状态,执行如下命令
kubectl taint node master node-role.kubernetes.io/master=:NoSchedule
6、kube-proxy开启ipvs
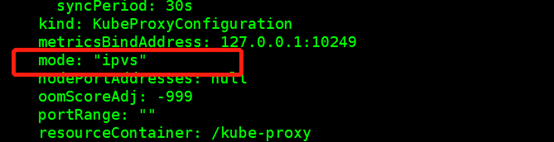
#修改ConfigMap的kube-system/kube-proxy中的config.conf,mode: “ipvs”
kubectl edit cm kube-proxy -n kube-system
#之后重启各个节点上的kube-proxy pod:
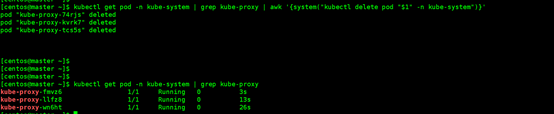
kubectl get pod -n kube-system | grep kube-proxy | awk '{system("kubectl delete pod "$1" -n kube-system")}'
#查看状态
kubectl get pod -n kube-system | grep kube-proxy
#查看日志
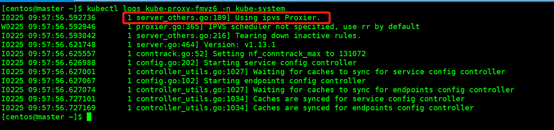
kubectl logs kube-proxy-fmvz6 -n kube-system
#日志中打印出了Using ipvs Proxier,说明ipvs模式已经开启。
7、移除节点和集群
#以移除node2节点为例,在Master节点上运行:
kubectl drain node2 --delete-local-data --force --ignore-daemonsets
kubectl delete node node2
#上面两条命令执行完成后,在node2节点执行清理命令,重置kubeadm的安装状态:
kubeadm reset
#在master上删除node并不会清理k8s-node2运行的容器,需要在删除节点上面手动运行清理命令。如果你想重新配置集群,使用新的参数重新运行kubeadm init或者kubeadm join即可。
结语
至此kubeadm安装k8s集群就到这里了,这篇是我几年前写的,版本已经很落后了,之后会为大家写一篇二进制安装的高可用k8s集群安装方法,希望大家多多支持哈