【需求】
在压测的过程中遇到了一一些问题:
从数据库拉出来大几十w条数据作为压测的接口参数,如何实现如下的需求?
1.如何实现单个个并发的参数化?
2.如何实现多个并发的参数化?
3.是将所有的并发需要的参数都放在一个文件中?
4.还是将每个并发的参数进行数据隔离,一个并发对应一个参数化文件?
【思考思路】
经过思考后,决定采用一个并发对应一个参数文件的形式进行数据隔离,那么问题又来了?
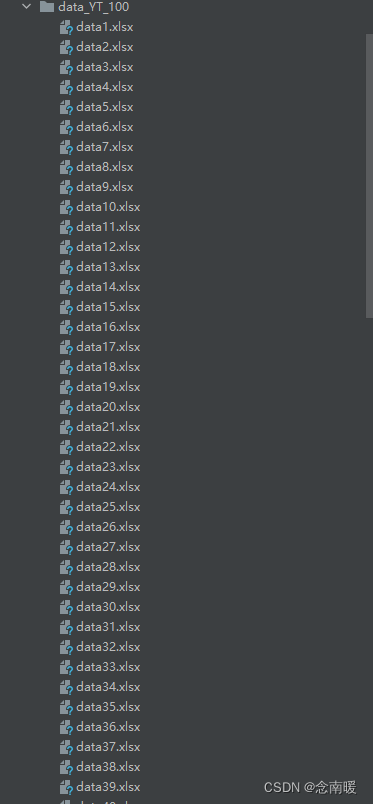
假设有100个并发,我难道需要手动搞100个数据文件吗?
的确,我一开始确实是这么做的,在10个并发每个并发需要5000条数据的场景下,的确是通过人肉去实现的
人肉实现步骤:
第一步:导出数据库原始数据5w条,存到data5w.xls文件中
第二步:新建10数据文件,data1.xls..........data10.xls
第三步:从data5w.xls文件中每一次剪切5000条数据,分别粘贴到这10个文件中
操作下来就特别人肉,如过每个并发需要5w条,有100个并发,人肉去实现,这个过程太痛苦了
能用脚本实现的功能为什么还要人肉去做呢?
于是研究了一下python如何去操作Excel.
总结了一下自己的思路:
python操作Excel思路:
第一步:获取所有的sheet页名称,放到一个列表中,然后循环去操作每个sheet页中的内容
第二步:针对单个sheet页的内容进行操作,需要考虑有多少行数据,每一行有多少列
第三步::设定一个参数,存储拆分后的每个data.xls文件寸的总记录数
第四步:利用分页思想,将当前sheet页的数据进行分页拆解,分页大小就上一步设定的参数值
第五步:将每一页的数据保存到一个data.xls文件中,如果出现整除除不尽的情况,就将这些零散的数据单独存储
到最后一个data.xls文件中
第六步:考虑到需要存储的data.xls文件不能被覆盖的问题,可以用总共的页数,作为动态拼接存储文件的名称
第七步:执行运行程序,得到想要的结果
分页思想:
场景1:假设有1000条数据,需要每个文件存储100条数据,正好可以存储到10个文件
total=1000
page_size=100
total_page=10
场景2:假设有1002条数据,需要每个文件存储100条数据,前10个文件,每个文件100条,第11个文件,只需要存储2条
total=1002
page_size=100
total_page=11
[脚本实现]
实现思路:
第一步:定义一个工具类:def extractExcelUtils(object)
第二步:__init__(self, file_path, row_size, save_path)需要传入三个入参,
file_path:文件路径data/data5w.xls
row_size:希望拆分后每个data.xls文件存储的数据条数
save_path:存储的文件夹路径:target_data/
第三步:封装四个方法
方法1:get_all_sheet_names(),返回sheet名称列表
方法2:work_sheet(sheet_name)返回得到的sheet
方法3:get_current_sheet_total_rows(sheet_name),返回当前sheet页的所有可用行
方法4:get_current_sheet_total_cols(sheet_name),返回当前sheet页每一条记录可用列
第四步:定义读取xls文件的方法read_data(sheet_name),返回当前sheet页所有数据列表,每一行数据一个存储一次
第五步:定义一个数据拼接的方法join_data(sheet_name),将原始数据拼接成自己需要的参数
第六步:定义一个写入方法write_data(sheet,workbook,data_list,file_path),将清洗后的数据写入到xls文件中
"""
:param sheet: 当前sheet页名称
:param workbook: 当前workbook
:param data_list: 需要存储的数据列表
:param file_path: 存储的文件路径
:return:
"""
第七步:定义一个extract_file(sheet_name_list)方法,将上面的所有方法进行组装
第八步:组装完成以后,开始运行程序
[脚本源码]
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# author: 胡浩浩
# datetime: 2021/11/29 15:19
# ide: PyCharm
import xlrd
import time
import random
import xlwt
class excelUtils(object):
"""
如何将一个Excel文件拆分成多个Excel文件
需要处理多个sheet页签的情况
"""
def __init__(self, file_path, row_size, save_path):
"""
:param file_path: 源文件个路径
:param row_size: 拆分以后每个文件的数据量
:param save_path: 存储文件的地址
"""
self.workbook = xlrd.open_workbook(file_path)
self.row_size = row_size
self.save_path = save_path
def work_sheet(self, sheet_name):
"""
:param sheet_name: sheet页名称
:return: 返回sheet_name对应的sheet对象
"""
sheet = self.workbook.sheet_by_name(sheet_name)
return sheet
def get_all_sheet_names(self):
"""
:return: 返回当前Excel中所有sheet_name
"""
name_list = self.workbook.sheet_names()
return name_list
def get_current_sheet_total_rows(self, sheet_name):
"""
:param sheet_name: sheet页名称
:return: 返回当前sheet页可用的最大行数
"""
ws = self.work_sheet(sheet_name=sheet_name)
total_rows = ws.nrows
return total_rows
def get_current_sheet_total_cols(self, sheet_name):
"""
:param sheet_name: sheet页名称
:return: 返回当前sheet页可用最大列
"""
ws = self.work_sheet(sheet_name=sheet_name)
total_cols = ws.ncols
return total_cols
def join_data(self, sheet_name):
"""
清洗数据,将清洗后的数据数据返回
:param sheet_name: 当前sheet页名称
:param file_path: 文件路径
:return: 返回当前sheet页清洗后的数据
"""
data = self.read_data(sheet_name)
for item in data:
index = "".join(random.sample(
'zFyVxwTvutRsrqpPonFmlkjLihSgfedcHbaABCvDEFGHIJKLMNOPQRSJHSADSWQWDewteyeydhgASsadavvfsvdDHSAJHQasdsadxzsdWEW2d323dfwefew4msadacodvuwivbyw8133289TUVWXYZ',
7))
item[2] = "YT" + time.strftime('%H%M%S') + index
item[3] = time.strftime('%Y-%m-%d %H:%M:%S')
# print(data)
return data
def read_data(self, sheet_name):
"""
读取数据文件
:param sheet_name: sheet页名称
:param file_path: 文件路径
:return:
"""
sheet = self.work_sheet(sheet_name=sheet_name)
data_list = []
total_rows = self.get_current_sheet_total_rows(sheet_name)
total_cols = self.get_current_sheet_total_cols(sheet_name)
for row in range(total_rows):
data_detail = []
for col in range(total_cols):
data_detail.append(sheet.cell_value(row, col))
data_list.append(data_detail)
return data_list
def write_data(self, sheet, workbook, data_list, file_path):
"""
:param sheet: 当前sheet页名称
:param workbook: 当前workbook
:param data_list: 需要存储的数据列表
:param file_path: 存储的文件路径
:return:
"""
for i in range(len(data_list)):
for j in range(len(data_list[0])):
sheet.write(i, j, data_list[i][j])
workbook.save(file_path)
def extract_file(self, sheet_name_list):
"""
:param sheet_name_list: sheet页名称列表
:return: 无返回值
"""
num = 1
for sheet_name in sheet_name_list:
data = self.join_data(sheet_name=sheet_name)
# print(data)
total_rows = self.get_current_sheet_total_rows(sheet_name)
print(total_rows)
if total_rows // self.row_size == total_rows / self.row_size:
file_size = total_rows // self.row_size
print(file_size)
else:
file_size = total_rows // self.row_size + 1
print(file_size)
for i in range(file_size):
file_path = "../data_YT_100/data%s.xlsx" % (str(num))
print(file_path)
current_workbook = xlwt.Workbook(encoding="utf-8")
current_sheet = current_workbook.add_sheet("Sheet1")
data_list = data[self.row_size * (i):self.row_size * (i + 1)]
self.write_data(current_sheet, current_workbook, data_list, file_path)
num += 1
return "拆解成功"
if __name__ == '__main__':
eu = excelUtils("../data/71w.xls", 10000, "../data_YT_100")
sheet_name_list = eu.get_all_sheet_names()
print(sheet_name_list)
data = eu.extract_file(sheet_name_list)
print(data)
脚本执行结果
总结
经过自己的努力,终觉解决的这个参数化文件的拆解的工作,一劳永逸。
等下次再遇到类似的需求,完全可以复用,只需要改动少量脚本逻辑,即可实现新的业务需求。