前言:
目标检测是计算机视觉一个重要的领域。物体检测(object detection)是计算机视觉中一个重要的分支,其大致功能是识别一组预定义的对象类,比如说人、汽车、自行车、动物。
并使用边界框(矩形框/bounding box)描述图像中每个检测到的图像位置。
通常我们会使用最小边界框(矩形框/bounding box)框出目标物体位置,并进行分类。
但是通常对象的形状往往是不规则的,所以另一种代替的方法是图像分割技术,图像分割技术一般会精确到像素级。(后话)
为了有效地给图片贴上标签,下面的文章介绍了一些策略,以确保你的数据集尽可能是高质量的。
虽然下面的最佳实践通常是正确的,但重要的是要注意,标签说明高度依赖于手头任务的性质。
此外,为一项任务标记的图像。可能不适合另一项任务——为了防止重新标记,我们应该考虑到这一点,下面让我们演练一些技巧。
不确定首先要标记哪些图像? 考虑如何在计算机视觉中使用主动学习。
最好把数据集及其标签看作是有生命的东西:不断地改变和改进,以适应手头的任务。
1. 在每张图片上标记每一个感兴趣的物体
计算机视觉模型的建立是为了,了解像素的哪些图案,对应一个感兴趣的对象。
正因为如此,如果我们训练一个模型,来识别一个对象,我们需要在我们的图像中,标记该对象的每一个外观。
如果我们在一些图像中,不给对象贴上标签,我们将会给我们的模型,引入错误的数据。
例如,在国际象棋棋子数据集中,我们需要标记棋盘上每个棋子的外观,我们不仅仅会标注其中的一部分,我们会给标记的对象添加一个名字比如说是白色的棋子。

2.标记对象的整体
我们的边界框应该包含感兴趣的对象的全部内容。只标注对象的一部分,会混淆我们对完整对象构成的模型。
例如,在我们的国际象棋数据集中,请注意如何将每个棋子完全包围在边界框中。
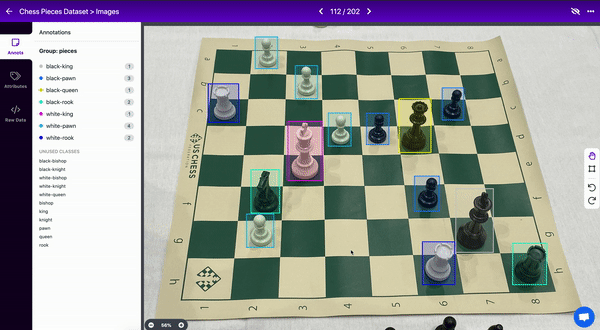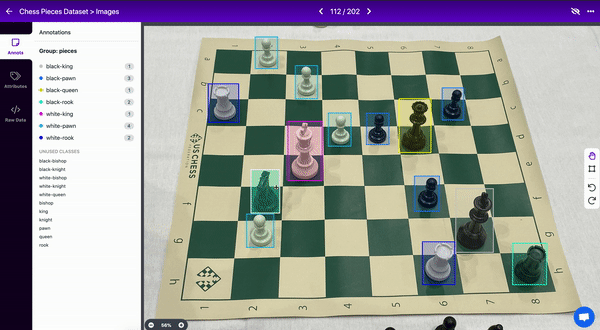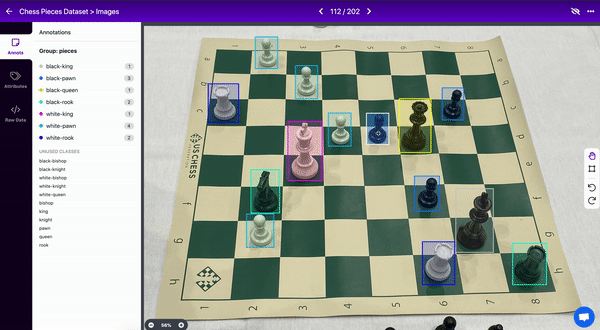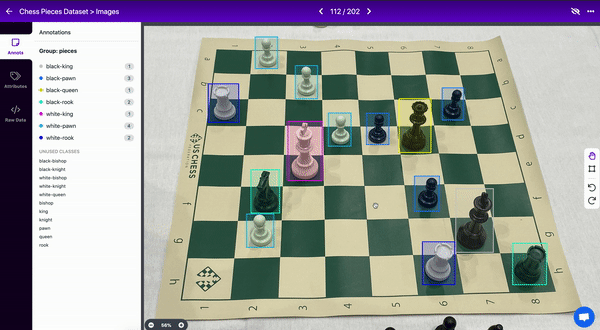
3.标注遮挡的对象
遮挡是指由于某些物体在照片中将物体挡住而导致图像中部分物体看不见的情况。 最好的方式是标记被遮挡的对象。
此外,通常最好的做法是将被遮挡的对象标记为完全可见,而不是为对象的部分可见部分绘制边框。
意思是如果你标记被遮挡的对象的话,最好是自己人为预测一下,自己通过尝试判断一下位置在哪里,然后去画那个边界框。
例如,在国际象棋数据集中,一个棋子会遮挡另一个棋子的视线。两个对象都应该被标记,即使盒子重叠。(认为框不能重叠是一种常见的误解)
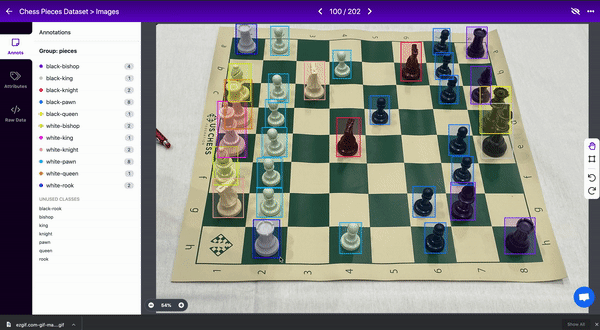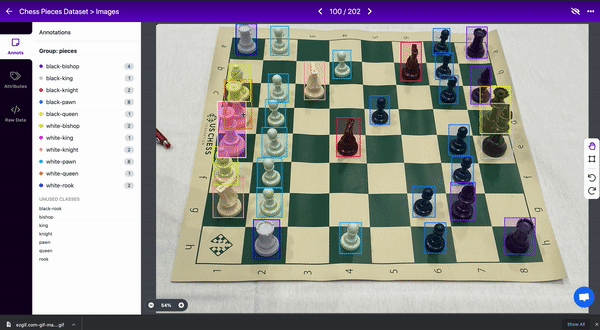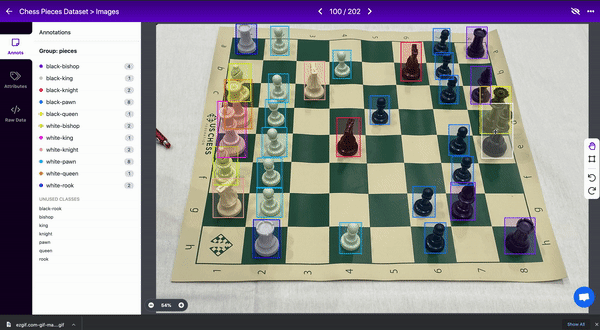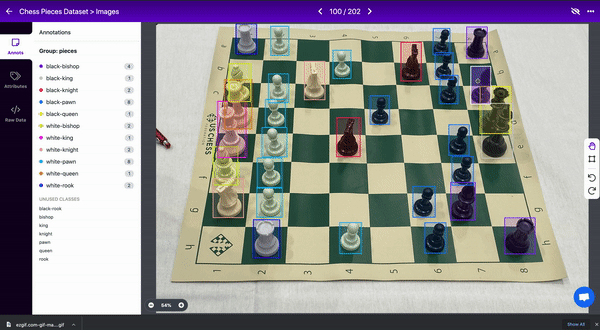
4.创建紧密边界框
边界框应该紧密地围绕感兴趣的对象。(但是,你不应该把盒子放得太紧,以至于它会切断物体的一部分。)
紧密的边框对于帮助我们的模型准确地了解哪些像素构成感兴趣的对象和图像的不相关部分是至关重要的。
这句话的意思就是标注的时候框的大小最好是合适的,不要太大也不要太小。
5.创建特定的标签名称
就比如说你在做数据集的时候,你想检测车,最好标注的时候对车进行分类,简单的说一张图像里面有大货车、小火车、轿车、跑车等等,不要图省事,直接一次性的标注为车,还是提前做一下分类比较好,方便后期调整。
6.保持清晰的标签说明
不可避免地,我们将需要向数据集中添加更多数据–这是模型改进的关键要素。
主动学习之类的策略可确保我们明智地花费时间进行标记。
因此,拥有清晰,可共享和可重复的标签说明对于我们未来的自我和同事创建和维护高质量数据集都是必不可少的。
7. 使用这些标签工具
labelimg
References: