文章目录
从Telnet协议理解TCP的全双工
理解TCP的双工
TCP是一个双工协议,因为它连接的两端都可以向对方输出数据。
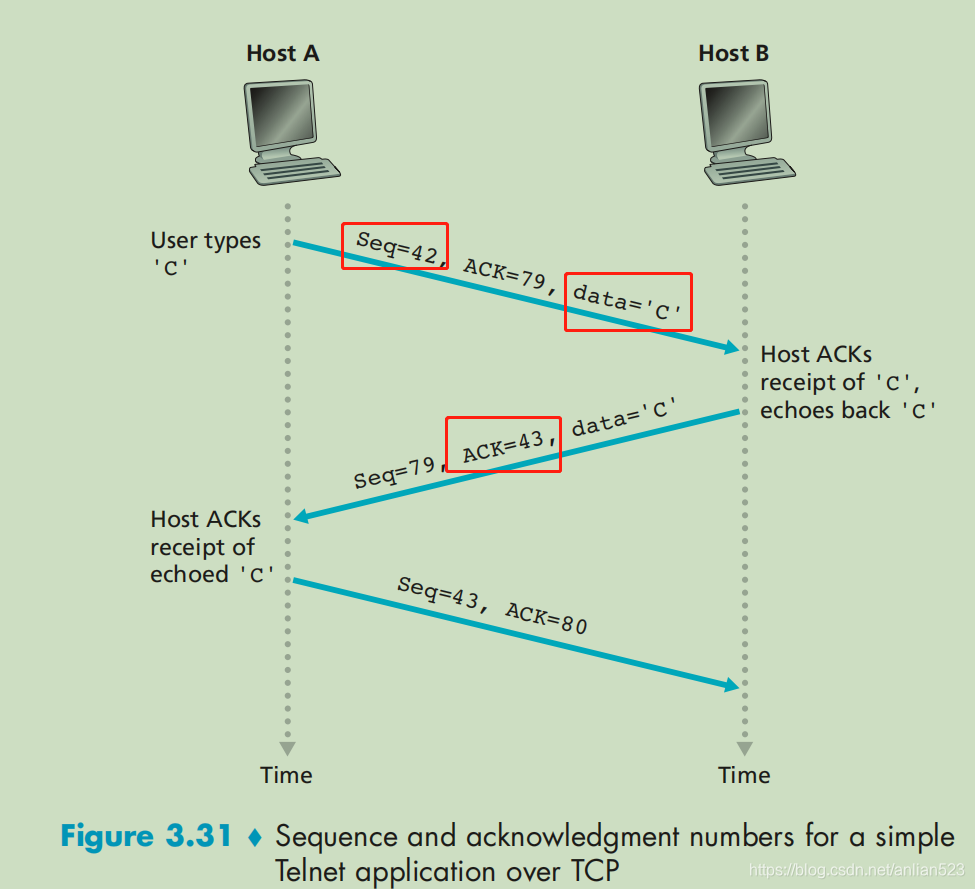
单独拿出上图的红框标记,我们就可以单独将 主机A当作发送方,主机B当作接收方。
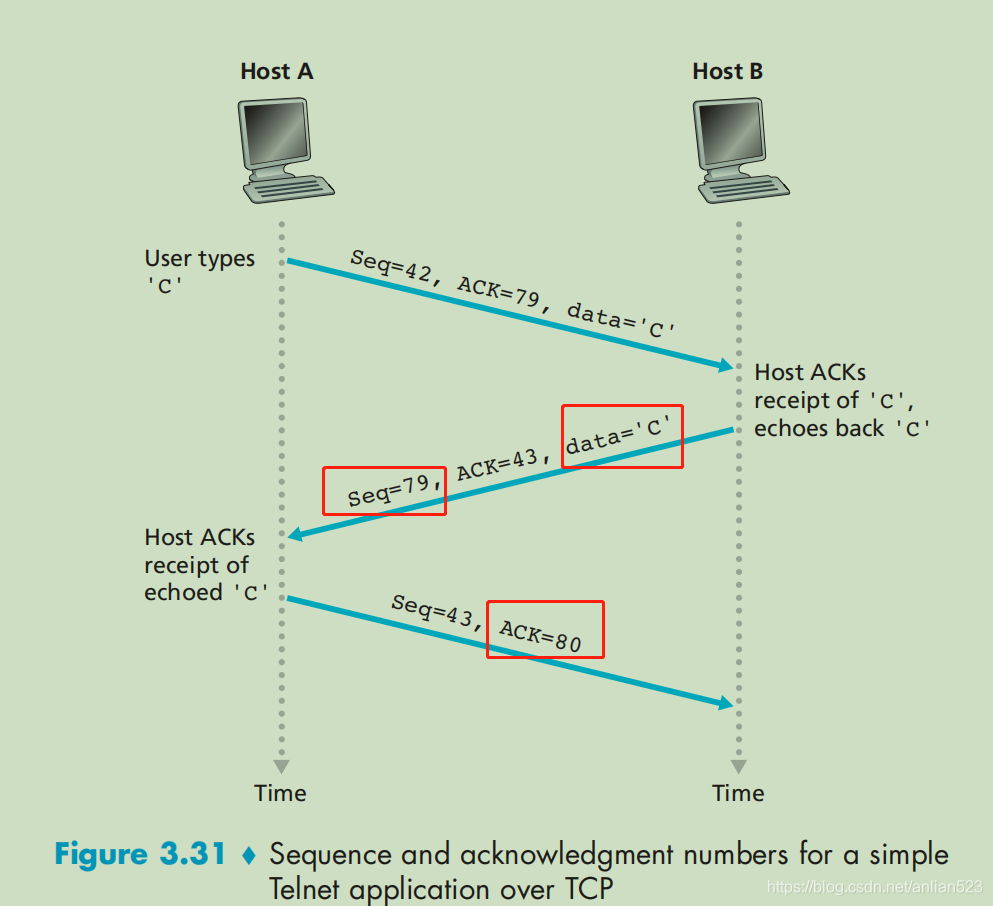
单独拿出上图的红框标记,我们就可以单独将 主机B当作发送方,主机A当作接收方。
理解TCP的全双工
上一节的内容,我们可以得知最起码TCP是一种半双工的协议。
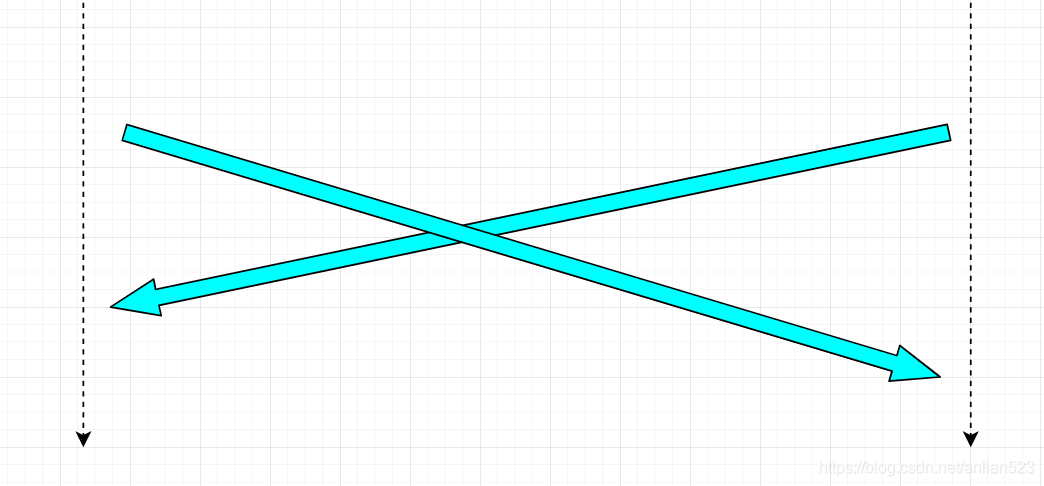
但实际上TCP也是支持上图这样,双方同时向对方发送数据的。所以TCP是全双工的协议。
流量控制
解释
按照上一章的思路,我们固定住一个发送方向,把两个主机分别当作 发送方、接收方。
每一条TCP连接中,接收方会为连接设置一个接收缓存。当接收方收到了正确的、按序的字节后,它就将数据放入接收缓存中。相关联的应用进程会从该缓存中读取数据,但不一定数据刚一到达就马上被读取。事实上,接收方的应用进程也许正忙于其他任务,甚至要过很长的时间后才去读取数据。
如果应用进程读取数据时相对缓慢,而发送方发送得太多、太快,发送的数据就会很容易地使得接收缓存溢出。所以TCP为它的应用进程提供了流量控制服务(flow-control service)以消除接收缓存溢出的可能性。
流量控制实际上是一个速度匹配服务,即发送方的发送速率与接收方应用程序的读取速率相匹配。
示意图
再按照上一章的思路,我们固定住一个发送方向,把两个主机分别当作 发送方、接收方。假设主机A正在向主机B发送一个大文件。
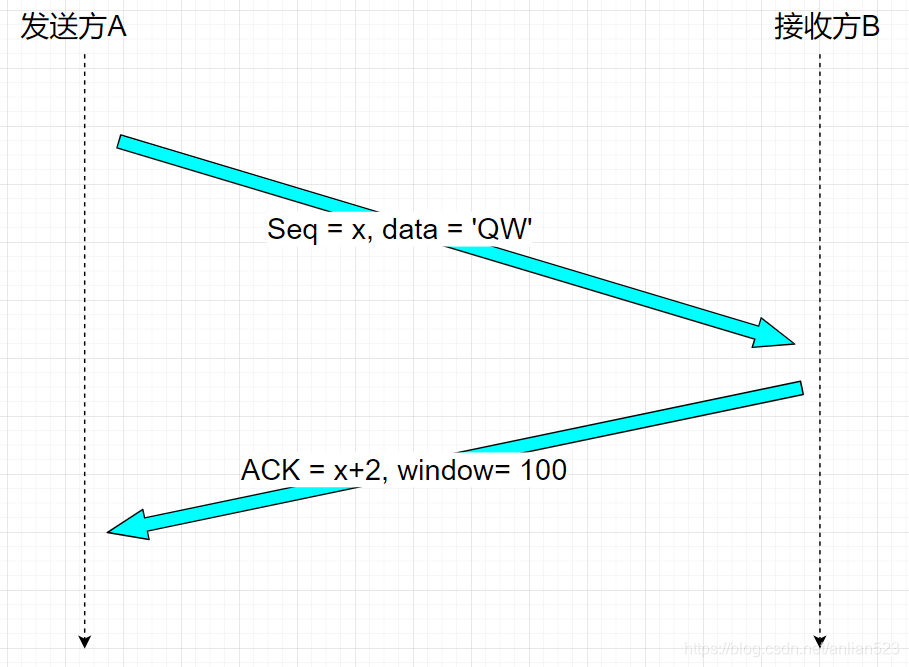
那在TCP报文段携带的数据上我们只需要关心上面的这些东西就可以了:
发送方:
- 发送方的Sequence Number
- 发送方的Payload
接收方:
- 接收方的Acknowledgment Number
- 接收方的Window
接收方的实现
既然整个流量控制服务都是为了将就接收方的接收缓存,那就从接收方的接收缓存开始讲起:
现主机B为该TCP连接分配了一个接受缓存,大小为 R c v B u f f e r RcvBuffer RcvBuffer。主机B上的应用程序不时从该缓存中读取数据,那么有以下变量:
- L a s t B y t e R e a d LastByteRead LastByteRead:主机B上的应用程序已从缓存中读取的数据的最后一个字节的编号。
- L a s t B y t e R c v d LastByteRcvd LastByteRcvd:主机B从下层网络里接收到的数据中的最后一个字节的编号。
一个字节要首先从下层网络中接收到,才可能被上层应用读取到,所以肯定有:
L a s t B y t e R e a d ≤ L a s t B y t e R c v d LastByteRead \leq LastByteRcvd LastByteRead≤LastByteRcvd
从 L a s t B y t e R e a d LastByteRead LastByteRead到 L a s t B y t e R c v d LastByteRcvd LastByteRcvd之间的数据就是 应用程序还没来得及读取的数据,这些数据自然会被缓存起来。由于TCP不允许以分配的缓存溢出,所以肯定有:
L a s t B y t e R c v d − L a s t B y t e R e a d ≤ R c v B u f f e r LastByteRcvd - LastByteRead \leq RcvBuffer LastByteRcvd−LastByteRead≤RcvBuffer
总的缓存大小再减去 还没来得及读取的数据大小,就是接收方可以接受的数据量大小,也就是接收窗口。接收窗口用 r w n d rwnd rwnd表示,根据接收缓存可用空间的大小来设置:
r w n d = R c v B u f f e r − ( L a s t B y t e R c v d − L a s t B y t e R e a d ) rwnd = RcvBuffer - (LastByteRcvd - LastByteRead) rwnd=RcvBuffer−(LastByteRcvd−LastByteRead)
根据每次接收的数据的多少,和上层应用的读取数据的多少,这个可用空间也在随之变化,所以 r w n d rwnd rwnd是动态变化的。当然也需要接收方每次接收到数据后,把 r w n d rwnd rwnd的值告知给发送方。 r w n d rwnd rwnd也就是上图中的window = 100了。
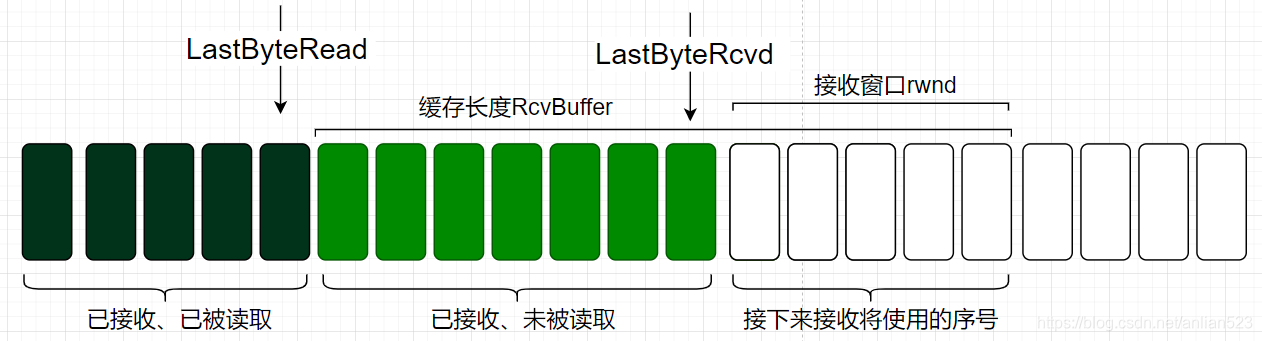
接收方的示意图如上。
发送方的实现
我们知道整个流量控制都是在将就接收方的接收缓存,所以每次发送方从接收方那里收到ACK = y和window = 100时,都会根据这两个参数来调整自己的提供窗口。
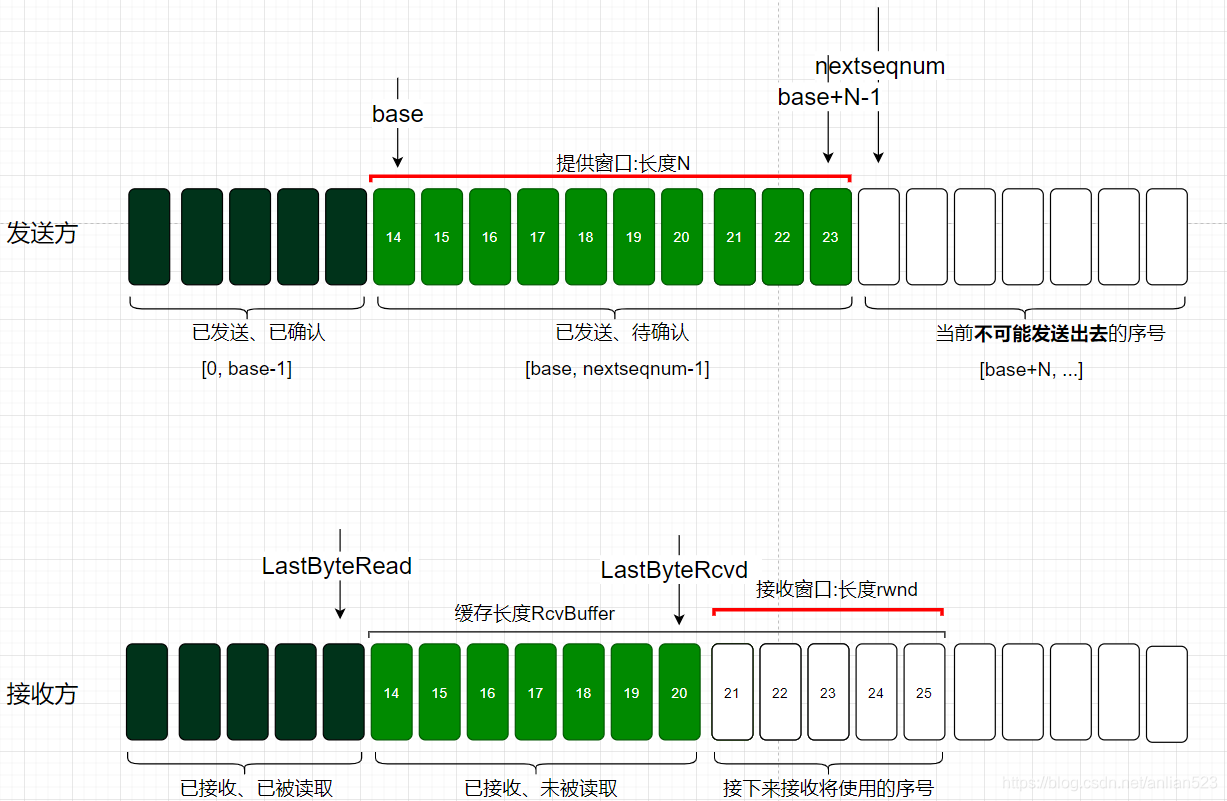
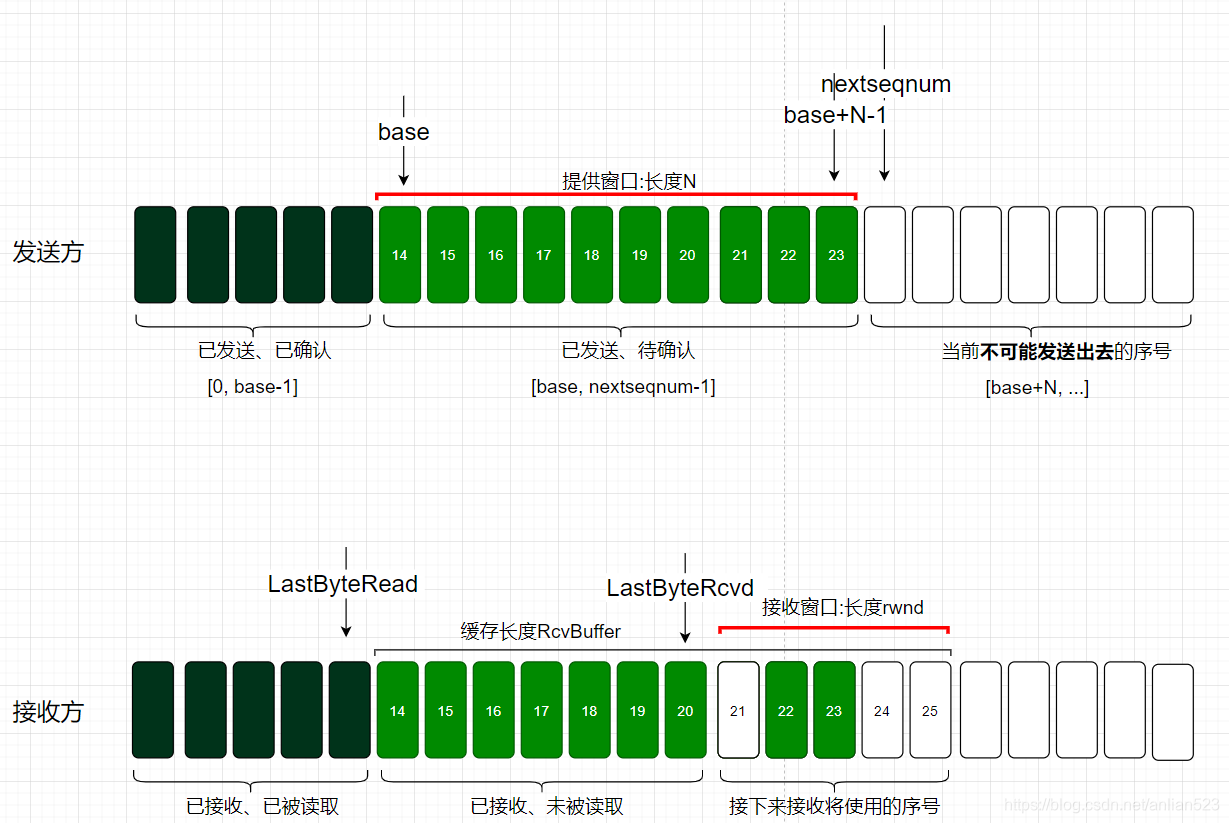
如上图,现假设某一时刻下:
- 发送方的提供窗口长度为N,发送方刚发送了14-20,和21-23的两个数据包。
- 21-23这个数据包丢失了。
- 接收方只收到了14-20,刚反馈了信息
ACK = 21、window = 5。(因为接收方已经收到了序号20,所以期待的是21;将rwnd的值传给window)
此时,发送方的窗口内的序号已经都被使用了,不能再发送数据了,除非接收方反馈ACK和window的信息给发送方,让发送方窗口滑动。

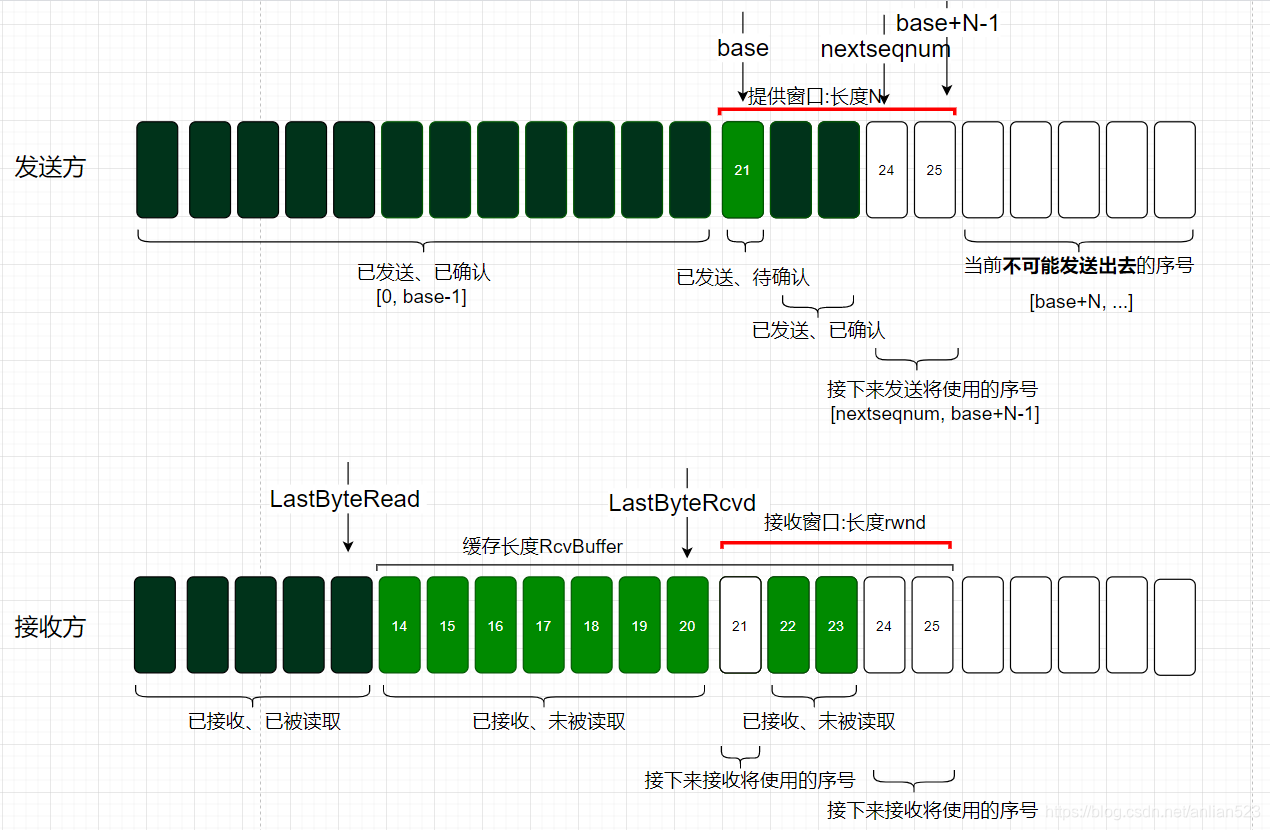
如上图,当发送方收到ACK = 21和window = 5后,它立即对自己的窗口进行调整:
- 根据
ACK = 21将窗口的左边界设定为ACK的值,因为从ACK开始后的这些序号都是没有被确认过的。即窗口左边界右移。 - 根据
window = 5,重新设定5为窗口的新长度。即窗口可能会伸或缩。
综上我们可以看出,流量控制总是在让发送方来同步接收方的窗口信息。同步后,双方的窗口会处于同一个位置。
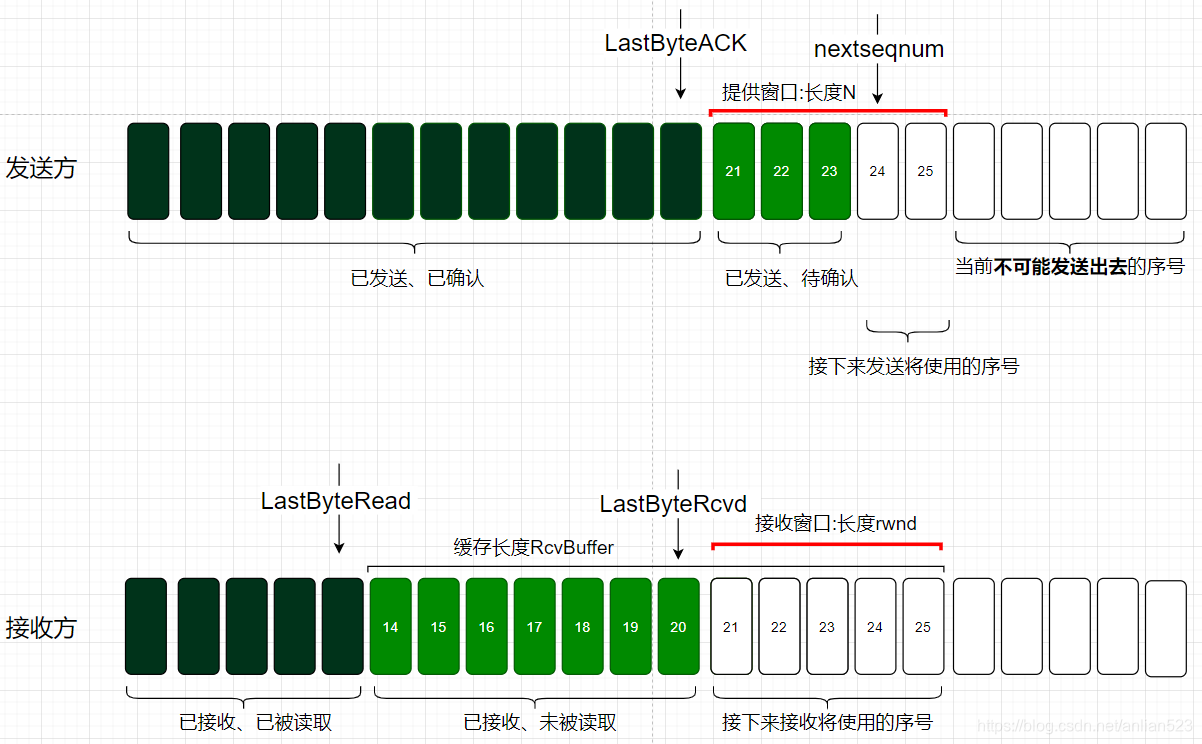
如上图,体现了发送方同步了窗口后的状态(只保留了一些重要信息),此时,窗口是完全一致的,但发送方窗口里可能会有 已发送、待确认 的数据(21-23)。
- 这些数据如果丢失了没有到达接收方,那么之后发送方会重新发送这些数据。
- 这些数据如果顺利到达接收方但接收方的ACK却丢失了,那么接收方窗口向前移动,之后发送方也会重新发送这些数据。
- 这些数据如果顺利到达接收方且接收方的ACK也顺利到达了,那么接收方窗口先向前移动,之后发送方窗口也向前移动。
三次握手时的窗口信息

这个本机与百度之间的三次握手。192.168.0.103为本机ip,39.156.66.14为百度ip。

首先将本机当作发送方,百度当作接收方。从Ack = 1和Win = 8192可以得知,初始时,百度作为接收方的接收窗口从序号1开始,长度为8192。

然后将百度当作发送方,本机当作接收方。从Ack = 1和Win = 131072可以得知,初始时,本机作为接收方的接收窗口从序号1开始,长度为131072。
Window size scaling factor
本节将百度当作发送方,本机当作接收方。
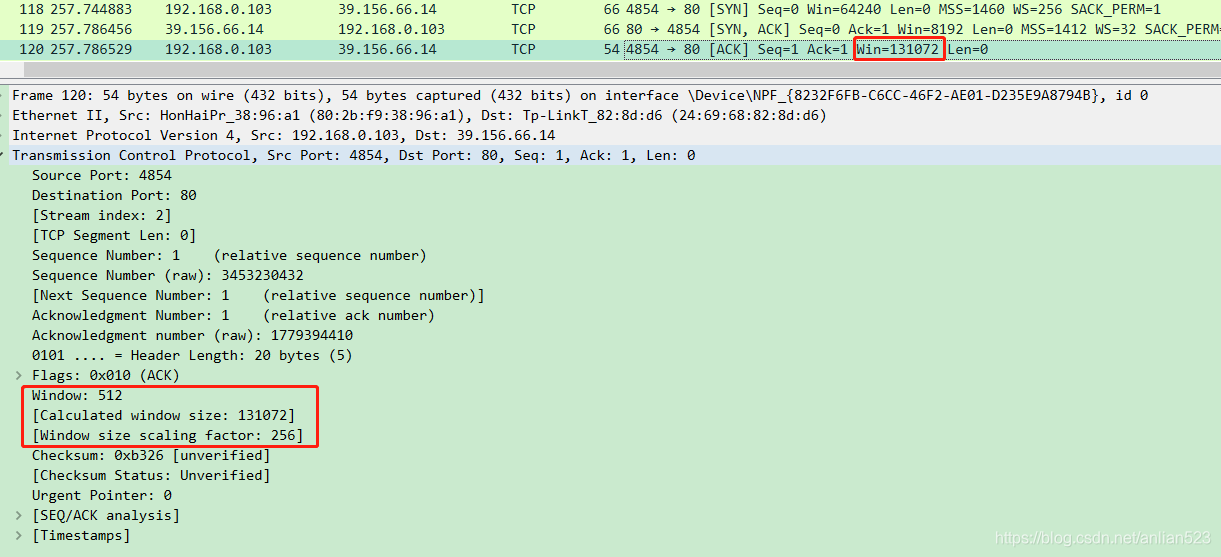
如上图,在第三次握手时,本机给出了window = 131072,这是通过512 * 256算出来的。即:
C a l c u l a t e d _ w i n d o w _ s i z e = W i n d o w ∗ W i n d o w _ s i z e _ s c a l i n g _ f a c t o r Calculated\_window\_size = Window * Window\_size\_scaling\_factor Calculated_window_size=Window∗Window_size_scaling_factor
但实际上你在这个包里面找不到Window size scaling factor。
其实这个Window size scaling factor在本机的第一次握手给出了:
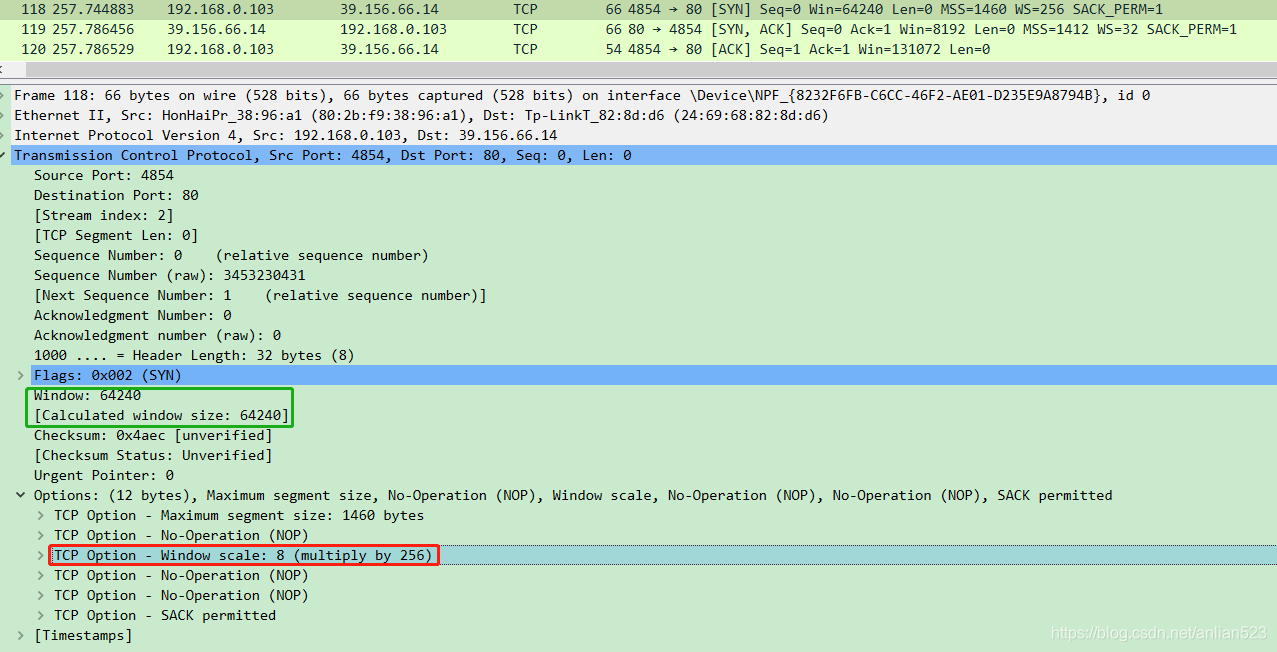
如上图,在Options中设置了Window scale为8,也就是2的8次方。另外,第一次握手时,虽然也给了Window的值,但实际不会使用它,因为肯定要以最新的第三次握手的值为准。在第一次握手的简述中(上图第一行里面),也没有出现Win = xxx的描述。
可以这么理解,Window size scaling factor和ACK、window一样,都是接收方给发送方以同步窗口的信息,只是这个Window size scaling factor如果没有改变的话,那么就只需要发送一次就行了,发送方自己会负责记住这个Window size scaling factor的。
SACK
我们知道Acknowledgment Number是累积确认的含义,如果有Acknowledgment Number = x,那么(... , x-1]这个区间内的数据都已经被接收方接收到了。根据SR协议我们知道TCP也可以支持选择确认,即接收方允许数据失序到达。
总之,SACK信息不是单独存在的。接收方反馈SACK信息时,既会反馈ACK信息(累积确认),也会反馈SACK信息(选择确认)。
示意图
如上图,现假设某一时刻下:
- 发送方的提供窗口长度为N,发送方刚发送了14-20、21、22-23的三个数据包。
- 21这个数据包丢失了。
- 接收方只收到了14-20和22-23,刚反馈了信息
ACK = 21、SACK = [22-23]、window = 5。(因为接收方在连续已收到的分组上的最大序号是20,所以期待的是21;将rwnd的值传给window)
如上图,因为SACK的存在:
- 在发送方的窗口里,可能存在 已发送、已确认 的分组。
- 在接收方的窗口里,可能存在 已接收、未被读取 的分组。
三次握手时确认SACK能力
这个本机与百度之间的三次握手。192.168.0.103为本机ip,39.156.66.14为百度ip。

在第一次握手和第二次握手时,本机和百度都分别表示自己有SACK的能力。
Options的构成
因为SACK permitted和SACK都是属于TCP header里的Options,所以这里还是讲一下Options的构成。
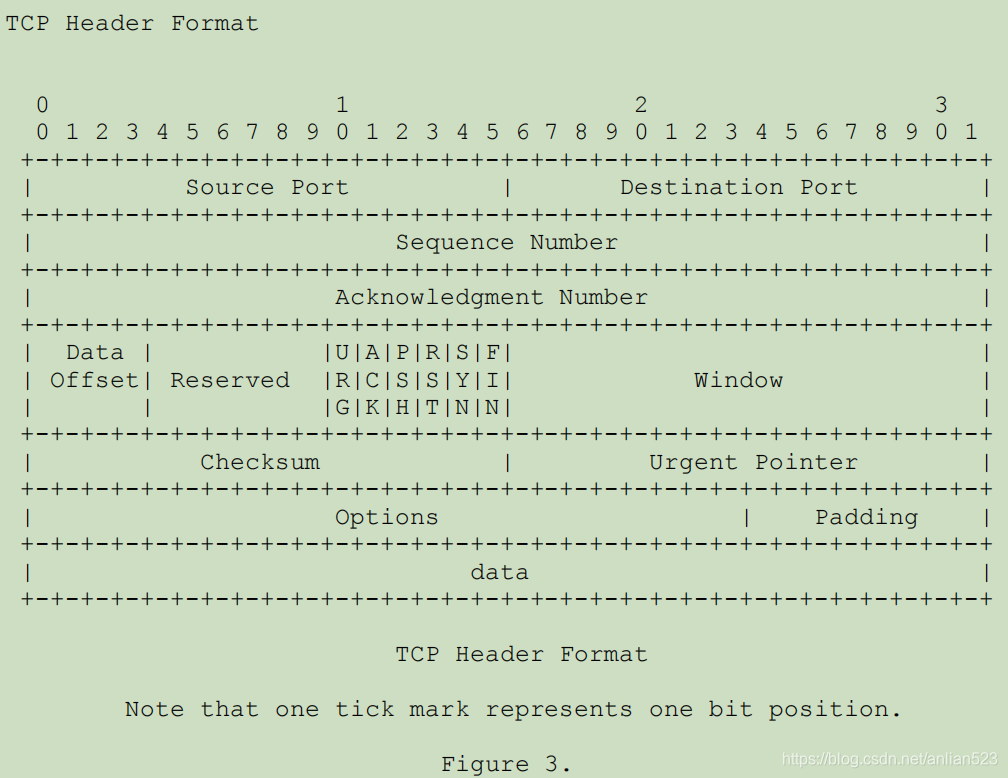
- 如上图为TCP的header的构成,每排是32bit,4byte。
- 前5排是固定的,所以TCP的header至少会占20byte。
Options和Padding那一排不是固定的。Options和Padding加起来最多可以占40byte。Padding是填充的意思。每排都是4byte的,如果Options的哪排没有填满4byte数据,那么就填充0(只可能在整个选项的最后面填充)。
- 综上,TCP的header最多可以60byte。
列举可能的Options

如上图,Options只可能是上图两种形式。
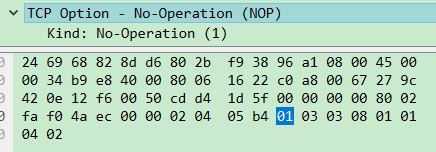
No-Operation这种Option,总共1字节,只带Kind,即Kind=1代表为No-Operation。
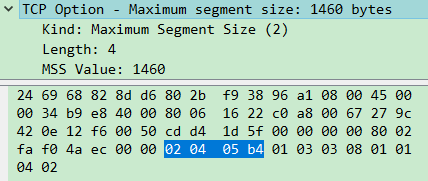
Maximum segment size这种Option,总共4字节,带有Kind、Length和Data,即Kind=2代表为Maximum segment size。注意Length总是处于第二个字节,Length的值又为4,那么Data部分只可能是剩余的那两个字节,即图上的05 b4。
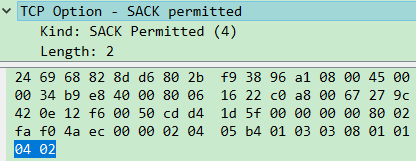
SACK permitted这种Option,总共2字节,只带有Kind、Length,因为Length的值为2,而Length又处于第二个字节,所以这个option到Length为止。
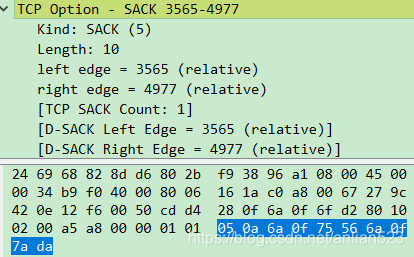
SACK这种Option,总共10字节,带有Kind、Length和Data。Data有8字节,包括左边界和右边界,各占4字节(这很自然,因为Sequence Number和Acknowledgment Number也都是占的4字节,既然都是4字节,所以他们的范围才能是一样的)。
利用No-Operation来填充其他Options
由于每一排占的是4字节,但有的选项是不足4字节的,那么那一排的前面部分就要由No-Operation来填充。No-Operation相当于是一种特殊的Options,可以用来填充。

如上图,是一个TCP的header的选项们。
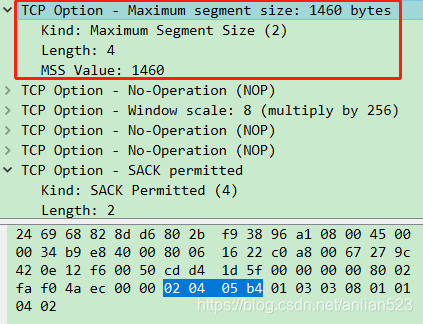
Maximum segment size由于刚好是4字节,那么不需要No-Operation来填充。
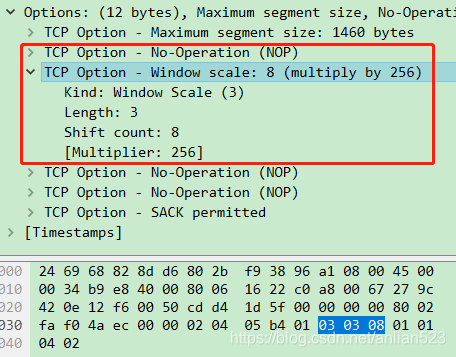
Window scale由于是3字节,所以前面需要1个No-Operation来填充。
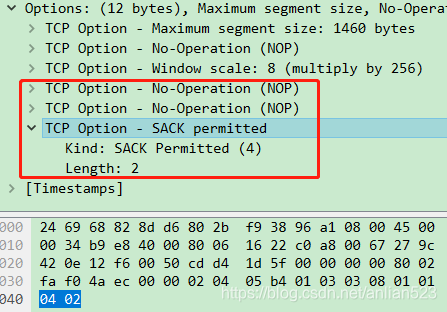
SACK permitted由于是2字节,所以前面需要2个No-Operation来填充。
wireshark抓包到的SACK
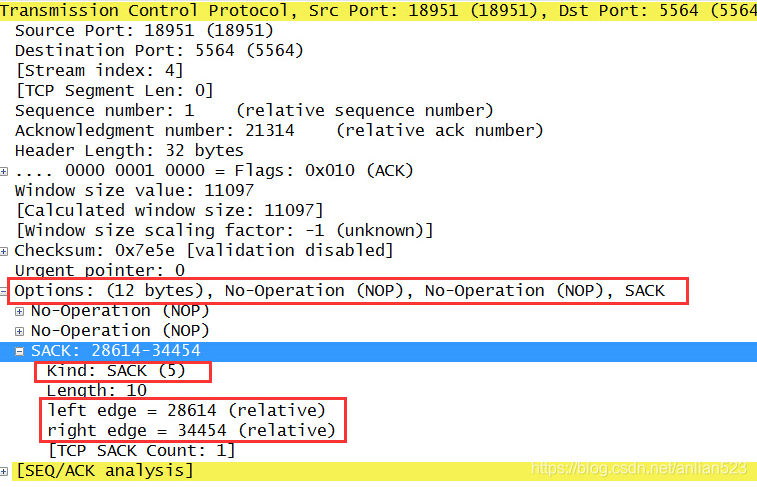
- Acknowledgment Number为21314,这意味着
(... , 21313]区间已经都被接收到了。 - 一个SACK块为
[28614, 34454],这意味着[28614, 34454]区间也被接收到了。注意,这个区间是超过了21314的。
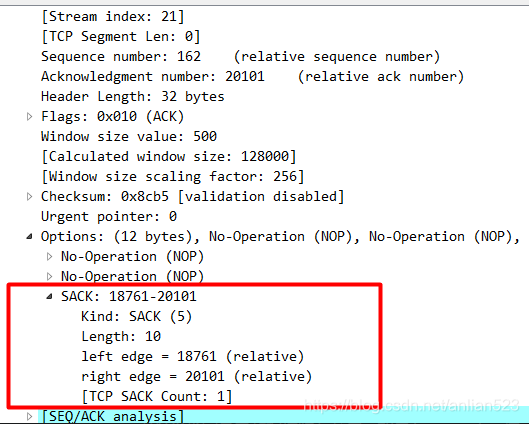
- Acknowledgment Number为20101,这意味着
(... , 20100]区间已经都被接收到了。 - 一个SACK块为
[18761, 20101],但这个块是小于等于20101的,这种SACK信息被称为DSACK。这好像不符合SACK的本意,但DSACK的作用是方便发送方判断何时的重传是没有必要的,比如发送方可以推断是否发生了包失序、ACK丢失、包重复或伪重传。- 发送方过早判定超时,被称为伪超时。而伪超时就会造成伪重传。
实例分析

这个本机与百度之间的通信。192.168.0.103为本机ip,39.156.66.14为百度ip。为了方便查看方向,我们记住7715为本机应用端口,443为百度应用端口。

第一条数据,本机告诉百度,本机作为接收方,已经接收的区间为(... , 32660)。

第二条数据,百度作为发送方发数据给本机。但本机期待的是32660及以后的数据包,这次百度发来的数据却是[34072, 34072 + 1412),属于是失序到达,wireshark认为(... , 32660)和[34072, 34072 + 1412)中间的那个segment还没有收到,所以显示TCP Previous segment not captured。

在第四条数据中:
- 本机根据第二条数据反馈了ACK。因为从第二条数据中,我们收到了
[34072, 34072 + 1412),所以带有了SACK块为SLE=34072 SRE=35484。 - 因为这条数据的
Ack=32660和第一条数据一样,所以显示TCP Dup ACK 266#1,266为第一条数据的标号。

第三条数据,也是百度作为发送方发数据给本机。但由于相对于第二条数据来说,第三条数据的顺序乱了,所以显示TCP Out-Of-Order。这条数据百度发送了[32660, 32660 + 1412)区间的数据给本机。

第五条数据,本机根据第二、三条数据反馈了ACK。
- 第二条数据中,百度发送了
[34072, 34072 + 1412)即[34072, 35484)。 - 第三条数据中,百度发送了
[32660, 32660 + 1412)即[32660, 34072)。 - 这两个区间合起来就是
[32660, 35484)。 - 之前本机的接收窗口的左边界就是32660(即
ACK = 32660),现在遇到了[32660, 35484),那么接收窗口就会右移了,移动到35484。
总结
SACK总的来说只是一种锦上添花的东西。一个ACK包,里面必须存在一个Ack序号,这个Ack序号起到了累积确认的效果。而SACK则是一种可能存在的东西,它在累积确认的范围之外,增加了选择确认的效果。