#include<cstdio>
#include<map>
#include<iostream>
#include<fstream>
#include<iomanip>
#include<vector>
#include<set>
#include<string>
#include<algorithm>
using namespace std;
const int wordnumPerLine = 7;
bool writeFile = false,isErr = false;
FILE* grammerFile;
char fname[50], outfname[50], c, reply[50];
string analyzedString;
vector<string> syms;
#define readLine if( fscanf(grammerFile,"%[^\n]%c",theLine,&c)==EOF) return;
struct Production {
string left;
vector<string>right;
bool isEmpty = false;
int dotPos;
string getRight() {
string ans = "";
for (int i = 0; i < right.size() - 1; i++)
ans += right[i] + " ";
if (!right.empty()) {
ans += right.back();
}
return ans;
}
string getProduction() {
return left + "->" + getRight();
}
Production() {
dotPos = 0;
}
string getItem() {
string retStr = left+"->";
if (dotPos == 0) {
retStr += "· ";
}
for (int i = 0; i < right.size(); i++) {
retStr += right[i]+" ";
if (dotPos==i+1){
retStr += "· ";
}
}
return retStr;
}
bool operator == (Production other) {
return getProduction()==other.getProduction()&&dotPos==other.dotPos;
}
};
struct Closure {
vector<Production> items;//项目集集合
int coreLen = 0; //核项目的长度
vector<pair<string, int> >next;//pair< Action或goto的字符串,到达的状态编号>的数组
bool guiYue = false;//记录是否可规约
bool operator ==(Closure other) {
//判断相等只比较核项目
if (coreLen != other.coreLen)//核项目长度不等,return false
return false;
for (int i = 0; i < coreLen; i++) {
//分别比较每一项,此处利用了Production对运算符==的重载
if (!(items[i] == other.items[i])) {
//不确定重载==是否会重载!= 此处保险起见这么写
return false;
}
}
return true;
}
string getClosure() {
string ansStr = "";
for (int i = 0; i < items.size(); i++) {
ansStr += items[i].getItem() + "\n";
}
for (int i = 0; i < next.size(); i++) {
ansStr += next[i].first + "/" + to_string(next[i].second)+" ";
}
return ansStr;
}
};
struct Description
{
vector<int> state; //状态栈
string symbol; //符号
string inputString;//输入串
string action;
string GOTO;
Description() {
}
Description(vector<int> state,string symbol,string inputString, string action,string GOTO) {
this->state = state;
this->symbol = symbol;
this->inputString = inputString;
this->action = action;
this->GOTO = GOTO;
}
};
struct Grammer
{
vector<Production> productions;//文法产生式
vector<string> nonTerminal;//文法非终结符
vector<string> terminal;//文法终结符
string startSymbol = "";//开始符号
map<pair<int, string>, string> predictionMap;//状态i遇到A/a时,Action或Goto为j
vector<Closure>itemSet;//整个DFA
vector<Description> description;//分析过程
friend ostream & operator <<(ostream & os, const Grammer & g);
}grammer;
ostream & operator <<(ostream & os, Grammer & g) {
filebuf fb;
ostream* pos;
if (writeFile) {
fb.open(outfname, ios::out);
pos = new ostream(&fb);
}
else {
pos = &os;
}
*pos << "非终结符:\n";
for (int i = 0; i < g.nonTerminal.size(); i++) {
*pos << g.nonTerminal[i] << "\t" << " ";
if ((i + 1) % wordnumPerLine == 0)
*pos << endl;
}
*pos << endl;
*pos << "终结符:\n";
for (int i = 0; i < g.terminal.size(); i++) {
*pos << g.terminal[i] << "\t" << " ";
if ((i + 1) % wordnumPerLine == 0)
*pos << endl;
}
*pos << endl;
*pos << "文法:\n";
for (int i = 0; i < g.productions.size(); i++) {
*pos << g.productions[i].left << "->";
for (int j = 0; j < g.productions[i].right.size(); j++) {
*pos << " " << g.productions[i].right[j];
}
*pos << endl;
}
*pos << "得到LR(0)项目集规范族:\n";
for (int i = 0; i < g.itemSet.size(); i++) {
*pos << "I" + to_string(i) << ":" << g.itemSet[i].getClosure()<<endl;
}
*pos << "得到LR(0)分析表:\n";
*pos <<left<< setw(6)<< "状态"<<setw(6*(g.terminal.size()+1))<<"|ACTION"<< setw(6 * g.nonTerminal.size()) << "|GOTO"<<endl;
for (int i = 0; i < g.itemSet.size(); i++) {
*pos << setw(6) << i;
for (int j = 0; j < syms.size(); j++) {
if (g.predictionMap.find(pair<int, string>(i, syms[j]))!= g.predictionMap.end()){
if (j==0||j==g.terminal.size()+1){
*pos << setw(6) << "|"+g.predictionMap[pair<int, string>(i, syms[j])];
}
else
*pos << setw(6) << g.predictionMap[pair<int, string>(i, syms[j])];
}
else {
if (j == 0 || j == g.terminal.size() + 1) {
*pos << setw(6) << "|";
}
else
*pos << setw(6) << " ";
}
}
*pos << endl;
}
*pos << "得到"+analyzedString+"LR(0)分析过程:\n";
*pos << left << setw(4) << "状态" << setw(18) << "|状态栈" << setw(18) << "|符号栈"<< setw(18) << "|输入串"<< setw(18) << "|ACTION"<<setw(18) << "|GOTO" << endl;
for (int i = 0; i < g.description.size(); i++) {
*pos << left << setw(4) << i << setw(18);
string symStr;
for (int j = 0; j < g.description[i].state.size(); j++) {
symStr += g.description[i].state[j] > 9 ? "(" + to_string(g.description[i].state[j]) + ")" : to_string(g.description[i].state[j]);
}
*pos<< "|" + symStr<< setw(18) << "|"+g.description[i].symbol << setw(18) << "|"+ g.description[i].inputString << setw(18) << "|"+ g.description[i].action << setw(18) << "|"+ g.description[i].GOTO << endl;
}
if (writeFile)
fb.close();
return *pos;
}
#pragma region 工具函数
template <class T>
inline int isInVector(vector<T> vec, T val) {
//函数功能在vec中查找val,若找到返回下标+1,没找到就返回0
for (int i = 0; i < vec.size(); i++) {
if (val == vec[i])
return i + 1;//为了与0区分,返回编号+1
}
return 0;
}
inline bool isNoneTerminal(string x) {
return x.length() > 0 && x[0] >= 'A'&&x[0] <= 'Z';
}
inline vector<string> splitString(string oriString, char splitChar = ' ') {
vector<string> vec;
oriString += splitChar;
int splitpos;
while ((splitpos = oriString.find(splitChar)) != string::npos) {
vec.push_back(oriString.substr(0, splitpos));
oriString = oriString.substr(splitpos + 1);
}
return vec;
}
inline string vectorToString(vector<string> vec, bool reverse = false) {
string ansStr = "";
if (reverse) {
for (int i = vec.size() - 1; i >= 0; i--) {
ansStr += vec[i] + " ";
}
}
else {
for (int i = 0; i < vec.size(); i++) {
ansStr += vec[i] + " ";
}
}
return ansStr;
}
int getGuiyueIndex(Closure closure) {
Production production = closure.items[0];
production.dotPos = 0;
int index = isInVector<Production>(grammer.productions, production) - 1;
return index;
}
#pragma endregion
Production lineToProduction(string line) {
Production production;
string rightPart = "";//当前产生式右部的一个单词
int leftIndex = line.find_first_of('-');
production.left = line.substr(0, leftIndex);
if (grammer.startSymbol == "")//开始符号为空则将production.left做为开始符号
grammer.startSymbol = production.left;
line = line.substr(leftIndex + 2);//当前line为只剩右部的字符串
line += ' ';
if (line[0] == '#') {
//右部为空
production.isEmpty = true;
//production.right.push_back("#");
return production;
}
for (int i = 0; i < line.length(); i++) {
if (line[i] == ' ') {
if (isNoneTerminal(rightPart)) {
//非终结符以大写字母开头
if (!isInVector<string>(grammer.nonTerminal, rightPart)) {
//此非终结符不在文法非终结符里面
grammer.nonTerminal.push_back(rightPart);
}
}
else {
//终结符以小写字母开头
if (!isInVector<string>(grammer.terminal, rightPart)) {
//此终结符不在文法终结符里面
grammer.terminal.push_back(rightPart);
}
}
production.right.push_back(rightPart);
rightPart = "";
continue;
}
rightPart += line[i];
}
return production;
}
string getErrorInfo(char index) {
switch (index) {
case 'A':
return "错误类型[A]:dotpos超出界限;";
case 'B':
return "错误类型[B]:该文法不是LR(0)文法;";
}
}
void getInput() {
char theLine[100];//这一行产生式
while (true) {
readLine;
Production production = lineToProduction(theLine);
grammer.productions.push_back(production);
if (!isInVector<string>(grammer.nonTerminal, production.left))
grammer.nonTerminal.push_back(production.left);
}
}
void getItemSet() {
Closure nowClosure;
nowClosure.items.push_back(grammer.productions[0]);
grammer.itemSet.push_back(nowClosure);
int tp = 0;//指向In
while (tp< grammer.itemSet.size()){
int np = 0;//当前closureI的第几项的指针
nowClosure = grammer.itemSet[tp];
//判断当前Closure(I)是否含有可规约串
for (int i = 0; i < nowClosure.items.size(); i++) {
if (nowClosure.items[i].dotPos== nowClosure.items[i].right.size()){
//说明可归约
//查看是否有移入规约冲突或规约规约冲突
if (nowClosure.items.size() > 1) {
//LR(0)文法,当有可规约串,而当前closure的大小大于0说明会产生冲突
cout << getErrorInfo('B') << endl;
isErr = true;
return;//下同,发现error直接结束函数
}
else {
//进行规约
grammer.itemSet[tp].guiYue = true;
break;
}
}
else if(nowClosure.items[i].dotPos> nowClosure.items[i].right.size()){
cout << getErrorInfo('A') << endl;
isErr = true;
return;
}
}
if (grammer.itemSet[tp].guiYue) {
++tp;
continue;
}
//扩充当前Closure(I)
while (np< nowClosure.items.size()){
if (isNoneTerminal(nowClosure.items[np].right[nowClosure.items[np].dotPos])){
//点在非终结符前
for (int i = 0; i < grammer.productions.size(); i++) {
if (nowClosure.items[np].right[nowClosure.items[np].dotPos]== grammer.productions[i].left&&!isInVector<Production>(nowClosure.items, grammer.productions[i])){
//如果左部相等且当前ClosureI没有该项目
nowClosure.items.push_back(grammer.productions[i]);//压入当前产生式
}
}
}
++np;
}
grammer.itemSet[tp] = nowClosure;
//根据当前Closure(I)扩展其他Closure
map<string, Closure> nextState;//存储当前Closure能扩展出的Closure
vector<string> alltransSym;//所有能发生动作或跳转的符号
//计算nextState
for (int i = 0; i < nowClosure.items.size(); i++) {
Production production = nowClosure.items[i];
string transSym = nowClosure.items[i].right[nowClosure.items[i].dotPos];
if (!isInVector(alltransSym, transSym)) {
alltransSym.push_back(transSym);
}
++production.dotPos;
if (!isInVector(nextState[transSym].items, production)) {
nextState[transSym].items.push_back(production);
}
}
for (int i = 0; i < alltransSym.size(); i++) {
nextState[alltransSym[i]].coreLen = nextState[alltransSym[i]].items.size();
int index = isInVector(grammer.itemSet, nextState[alltransSym[i]]);
if (index) {
//找到了
grammer.itemSet[tp].next.push_back(pair<string,int>(alltransSym[i],index-1));//直接连上线
}
else {
//没找到
grammer.itemSet.push_back(nextState[alltransSym[i]]);//将此Closeure添加到DFA中
grammer.itemSet[tp].next.push_back(pair<string,int>(alltransSym[i], grammer.itemSet.size()-1));//连上线
}
}
++tp;
}
}
void getPredict() {
syms.assign(grammer.terminal.begin(), grammer.terminal.end());
syms.push_back("#");
for (auto s:grammer.nonTerminal) {
if (s != grammer.startSymbol) {
syms.push_back(s);
}
}
//map<pair<int, string>, string> predictionMap;//状态i遇到A/a时,Action或Goto为...
for (int i = 0; i < grammer.itemSet.size(); i++) {
//该循环将规约填入表中
if (grammer.itemSet[i].guiYue){
//如果能规约
if (grammer.itemSet[i].items[0].left == grammer.startSymbol) {
//左部为开始符号,acc
grammer.predictionMap[pair<int, string>(i, "#")] = "acc";
}
else {
//赋规约的编号
for (auto s : syms) {
if (isNoneTerminal(s))
break;
string val = "r" +to_string(getGuiyueIndex(grammer.itemSet[i]));
grammer.predictionMap[pair<int, string>(i, s)] = val;
}
}
}
}
for (int i = 0; i < grammer.itemSet.size();i++) {
for(int j = 0;j< grammer.itemSet[i].next.size();j++)
grammer.predictionMap[pair<int, string>(i, grammer.itemSet[i].next[j].first)] = (isNoneTerminal(grammer.itemSet[i].next[j].first)? "":"S") +to_string( grammer.itemSet[i].next[j].second);
}
}
/*
1.若Aciton[S,a]=Sj,a->符号栈,j->状态栈
2.若Aciton[S,a]=rj,第j个产生式规约,两者指针减去右部符号串的长度,在GOTO[S,A]
3.GOTO[S,A]=j,A->符号栈,j->状态栈
4.Acion[S,a]为空白,移入出错处理
5.若Aciton[S,a]=acc,接受
*/
void analyzeString() {
vector<int> stateStack;//状态栈
vector<string> symbolStack;//符号栈
vector<string> inputStr = splitString(analyzedString);//输入串
inputStr.push_back("#");
stateStack.push_back(0);
symbolStack.push_back("#");
while (true){
Description description(stateStack,vectorToString(symbolStack), vectorToString(inputStr),"","");
string action = grammer.predictionMap[pair<int, string>(stateStack.back(), inputStr.front())];
if (action[0] == 'S') {
//Action
stateStack.push_back(stoi(action.substr(1)));
symbolStack.push_back(inputStr.front());
inputStr.erase(inputStr.begin());
description.action = action;
grammer.description.push_back(description);
}
else if (action[0] == 'r') {
//规约
int productionIndex = stoi(action.substr(1));
int popNum = grammer.productions[productionIndex].right.size();
if (popNum>stateStack.size()){
cout << "err:此句子不是本文法的句子" << endl;
break;
}
while (popNum--){
stateStack.pop_back();
symbolStack.pop_back();
}
symbolStack.push_back(grammer.productions[productionIndex].left);//
string goTo = grammer.predictionMap[pair<int, string>(stateStack.back(), symbolStack.back())];
if (goTo[0] >= '0'&&goTo[0] <= '9'){
//进行GOTO
description.GOTO = goTo;
stateStack.push_back(stoi(goTo));
}
else {
cout << "err:此句子不是本文法的句子" << endl;
break;
}
description.action = action;//填入该条action
grammer.description.push_back(description);
}
else if (action == "acc") {
//接受
description.action = action;
grammer.description.push_back(description);
break;
}
else {
description.action = action;
grammer.description.push_back(description);
cout << "err:此句子不是本文法的句子" << endl;
break;
}
//grammer.description.back().action = grammer.predictionMap[pair<int, string>(des.state, des.symbol)];
}
}
int main() {
printf("Input grammer file?\n");
scanf("%s", fname);
printf("Write in file?(Y/N)\n");
scanf("%s", reply);
if (reply[0] == 'Y' || reply[0] == 'y') {
printf("Write in file?(Y/N)\n");
scanf("%s", outfname);
writeFile = true;
}
grammerFile = fopen(fname, "r");
if (&grammerFile) {
//文件读取成功
getInput();//读入文法生成grammer
}
getItemSet();//构造DFA
getPredict();
if (isErr)
return 0;
printf("Input the string?\n");
getchar();
getline(cin, analyzedString);
analyzeString();
cout << grammer;
getchar();
getchar();
return 0;
}
//begin d ; s end
//b c c d
测试文法一 t1.txt(以右侧产生式以空格隔开,未终结符以大写字母开头)
S'->E
E->a A
E->b B
A->c A
A->d
B->c B
B->d
句子(空格隔开):b c c d
运行结果:



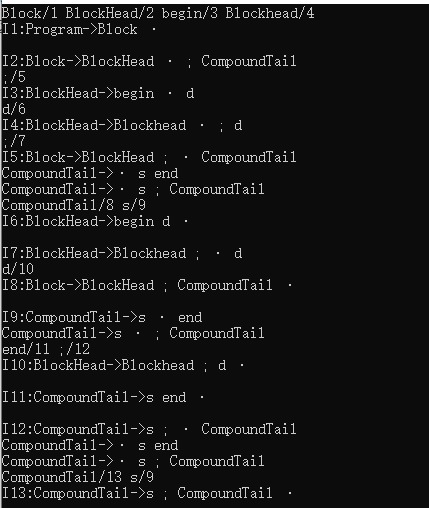
测试文法二 t2.txt(以右侧产生式以空格隔开,未终结符以大写字母开头)
Program->Block
Program->CompoundStatement
Block->BlockHead ; CompoundTail
BlockHead->begin d
BlockHead->Blockhead ; d
CompoundTail->s end
CompoundTail->s ; CompoundTail
CompoundStatement->begin CompoundTail
句子(空格隔开):begin d ; s end
运行结果:
在这里插入图片描述