OpenStack干货分享 | Neutron源码分析之L3
概念
OpenStack Neutron中,Router提供虚拟三层服务,包括租户网络(Tenant Network)之间、租户网络与外部网络(External Network)之间的路由和网络地址转换,原生模式下路由器管理功能以Service Plugin的形式集成在Neutron Server中,路由器实体以Linux网络命名空间的形式存在,由Neutron L3 Agent管理。
本文从Neutron newton版本L3模块源码入手,通过抽象整体架构,对子模块的设计方法和实现细节进行分析,为开发者进行Neutron二次开发、构建大型软件系统提供借鉴。
源码分析
整体架构
先来看看L3的整体架构
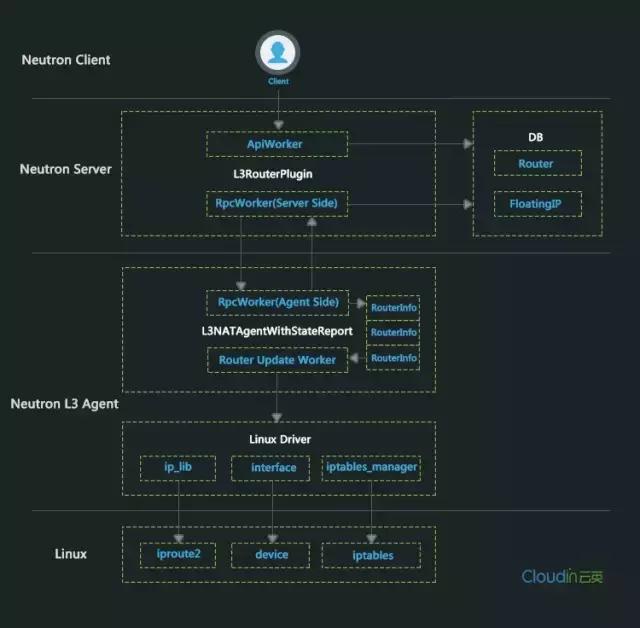
图1 Neutron L3模块结构图
由上图可以看出,Neutron L3模块的功能主要由Server端的L3RouterPlugin和Agent端的L3NATAgentWithStateReport配合实现:
Client通过HTTP向Server发起L3资源Router、Floating IP的管理命令,Server负责处理资源在数据库的增删改查,并通过RPC将资源的更新事件通知到Agent,Agent最终通过Linux下的网络工具栈来实现具体的L3功能。
接下来从上至下,对各个模块的实现进行更仔细的分析。
Server端
Server端的L3RouterPlugin主要有两个职责:处理Client的HTTP请求、处理Agent的RPC请求。这两类请求处理过程的本质都是数据库数据的CRUD。L3的核心资源是Router,大部分L3 API都是围绕着Router的基础属性、扩展属性或附属资源的增删改查,Router也是L3 Plugin与L3 Agent进行同步的数据单元。
方法扩展
在结构上,L3RouterPlugin通过多重继承多个Mixin类获得对多种L3特性的功能支持:
如extraroute_db.ExtraRoute_db_mixin支持额外添加路由,l3_gwmode_db.L3_NAT_db_mixin支持配置多种网关模式,l3_hamode_db.L3_HA_NAT_db_mixin支持路由器HA。
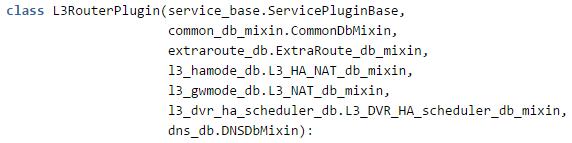
在处理HTTP API请求时,Mixin类通过覆盖接口函数加入自己的处理逻辑,以create_router为例:l3_hamode_db.L3_HA_NAT_db_mixin类覆盖父类的方法,除了调用父类的create_router方法完成基础的Router创建逻辑外,根据params中的ha字段,进行了一系列其它处理:
-
创建用于VRRP协议数据包通信的专用网卡和专用网络(_create_ha_interfaces_and_ensure_network)
-
申请Keepalived实例所需的唯一VR ID(_set_vr_id)
-
调度Router:选取符合要求的L3 Agent与Router绑定(schedule_router)
-
通过RPC通知步骤3选取的L3 Agent进行Router的创建操作(_notify_ha_interfaces_updated)

除了上述覆盖接口方法的方式,Neutron还会用另一种方法来实现Router的功能扩展:观察者(订阅/发布)模式。
这种设计上,增加处理逻辑不再需要覆盖父类方法,而是通过将处理函数挂在所关注事件的回调函数列表上,等待处理流程回调,如DVR Router需要额外创建一些snat interfaces,就通过订阅Router的create/update事件,一旦发生就触发_create_snat_interfaces_after_change处理。

DVR特性的实现现在已经完全重构为这种callback的方式,这种重构的目的是渐渐消除DVR功能通过继承DB类来实现这种重耦合的设计,便于将DVR特性独立出来,放在轻耦合的driver类中,以支持多种不同的driver来实现DVR特性。
通过对比HA和DVR这两种特性的实现方式,可以看出,DVR的实现方式对基础逻辑的侵入性更小,更符合软件工程轻耦合的设计。
属性扩展
除此之外,为了便于给核心资源Router添加新的属性,L3RouterPlugin的父类之一CommonDbMinxin提供了一组通用接口来扩展Router数据对象,也是一个观察者模式的典型应用:
观察目标:Router
观察者:Mixin类对Router的扩展方法
订阅方法:register_dict_extend_funcs
发布方法:_apply_dict_extend_functions
当Client或Agent向Server查询Router时,_make_router_dict通过_apply_dict_extend_functions方法依次回调各个Mixin的扩展函数,完成数据的封装。
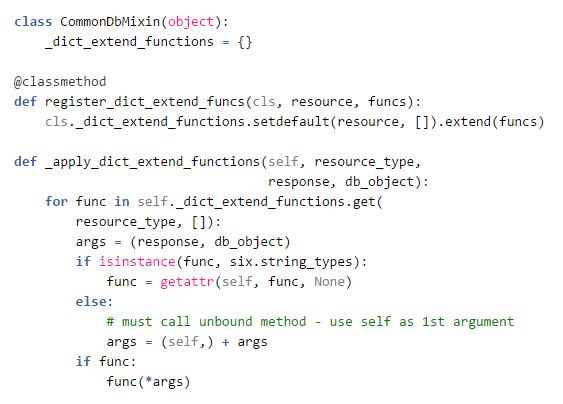
以extraroute_db.ExtraRoute_db_mixin类为例,它注册了一个callback方法_extend_router_dict_extraroute,当构造Router字典时,这个callback为字典增加一个名为routes的key,value为从数据库Router表联合查询出的route_list记录列表。

基于这种设计,易于在不影响原生逻辑的前提下为L3 Router增加新的属性。
Agent端
Server端完成资源在DB的CRUD后通过RPC调用Agent端L3NATAgentWithStateReport的router_update/delete接口,这些update/delete接口都是异步设计,仅负责将router_id及相关的优先级、action封装为一个RouterUpdate对象投入Agent内部一个优先级任务队列。

优先级任务队列的消费者是Agent启动时spawn的多个工作协程,协程的主体函数是_process_router_update,执行逻辑为:
按优先级从任务队列取出RouterUpdate对象,逐一进行_process_router_if_compatible处理。
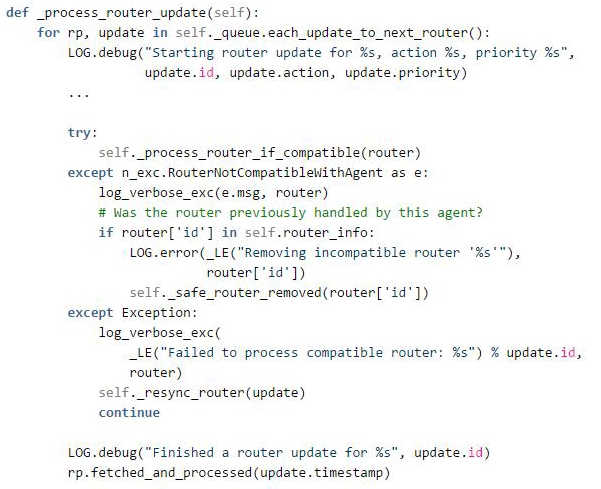
_process_router_if_compatible函数顾名思义,首先进行兼容性判断,再根据Router在本地是否已存在进行新增_process_added_router或更新处理_process_updated_router。
新增处理函数_process_added_router调用_create_router函数构造RouterInfo对象,这里是一个简单工厂,RouterInfo类根据Router的distributed、ha属性及Agent自身的agent_mode,有多个具体的实现类,包括LegacyRouter、HaRouter、DvrLocalRouter、DvrEdgeRouter和DvrEdgeHaRouter。

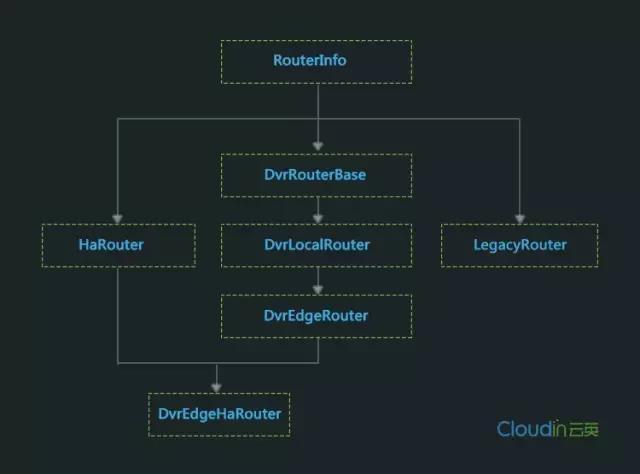
图2 RouterInfo派生关系示意图
RouterInfo和其各个子类采用模板方法模式,不变的处理过程框架和公共的行为定义在基类RouterInfo中,各个子类覆盖子过程中可变的行为部分,RouterInfo最主要的两个公共接口是initialize和process:
initialize负责Router初始化行为,仅在新增过程中被调用,这里的初始化跟__init__方法的区别是:__init__负责构造内存对象,而initialize会在节点上进行创建命名空间、启动进程之类的系统操作;
process负责将Router对象的更新反应在路由器“实体”上,它定义了路由器更新的通用处理流程,RouterInfo的派生类实现自己特有的部分逻辑:如子过程process_external中,LegacyRouter进行外部网关设备的插入、网关设备IP地址配置和SNAT/DNAT的规则配置;DvrLocalRouter还会创建一个fip网络命名空间、连接fip和qrouter两个命名空间;而DvrEdgeRouter还会创建一个snat命名空间。

要了解DVR Router、HA Router、DVR HA Router在底层是如何实现的,可以以initialize和process方法为入口,跟进对应实现类中子过程的处理函数。
另外,neutron.agent.linux提供了Linux下网络相关系统工具的封装,如iptables、ovs、iproute2等,process的大多数子过程都是通过这些工具函数实现的。
总结
在设计实现一个大型软件系统时,常会遇到几个问题:扩展性、耦合性、去状态、同异步等,OpenStack在计算开源领域独树一帜,在设计和实现上集结了大量优秀工程师的智慧,从Neutron源码入手,通过抽象整体架构,对各个子模块进行实现和设计方法的分析,来学习OpenStack在解决这些问题时采用的设计哲学和编码技巧,有非常重要的借鉴意义。