发现一博主文章比较全面,细致,可参考
weixin_55609814的博客_吾妻雪乃_CSDN博客
*
1. 数据库的事务可由 一组 DML语句(增删改),一条DDL语句(船建表,索引,视图...),一条DCL语句(授权...)组成
DDL,DCL 语句最多有一条,该语句会导致事务立即提交
2.自动提交和开启事务正好相反。
3.自己感觉,有事物的时候,语句也会在(比如executeUpdate,excute后立即)执行,只不过不提交就不生效。也就是说在自己得小缓存里'模拟', 提交才会把改动更新到'真实库'里
4.关于jdbc 的。
4.1,PreparedStatement 不知道参数类型时,可用setObject()方法传入。preparedstatement会自动转换。
4.2,PreparedStatement 占位符只可替代普通值,不可替代表名,列名,select,insert等关键词。
4.3, Blob二进制文件,图片,音乐等等 只能用PreparedStatement 占位符传入二进制流,普通的Statement不行。
text与blob的区别在于:text不能存储图片。blob是二进制流,text是非二进制。
4.4, 结果集,RowSet之类的 可以更新,修改数据表
4.5,ResultSetMetaData 在获得返回结果ResultSet后,用方法对其进行解析元数据。
4.6, 使用excute()执行sql语句后,返回true, 可用getResultSet()获得结果集。
返回false,可用getUpdateCount()获得更新行数。
4.7 更新量大的话,要用executeLargeUpdate()方法。(mysql暂不支持)
5. left join ... on
on 后面可以跟多个条件,用and连接。
也可以跟 > ,<
不是必须 = ,一个条件
6. 视图其实就是一条加了名字的sql语句, 子查询就是一个临时视图
7.
这VARCHAR(100)与VARCHAR(200)真的相同吗?
结果是否定的。虽然他们用来存储90个字符的数据,其存储空间相同。但是对于内存的消耗是不同的。对于VARCHAR数据类型来说,硬盘上的存储空间虽然都是根据实际字符长度来分配存储空间的,但是对于内存来说,则不是。其时使用固定大小的内存块来保存值。简单的说,就是使用字符类型中定义的长度,即200个字符空间。显然,这对于排序或者临时表(这些内容都需要通过内存来实现)作业会产生比较大的不利影响。解释可以参见这里。如果不想看解释,我这里大概说下:假设VARCHAR(100)与VARCHAR(200)类型,实际存90个字符,它不会对存储端产生影响(就是实际占用硬盘是一样的)。但是,它确实会对查询产生影响,因为当MySql创建临时表(SORT,ORDER等)时,VARCHAR会转换为CHAR,转换后的CHAR的长度就是varchar的长度,在内存中的空间就变大了,在排序、统计时候需要扫描的就越多,时间就越久
8.
8.1
Mysql记录行数据是有限的。大小为64k,即65535个字节,
而varchar要用1-2字节来存储字段长度,小于255的1字节,大于255的2字节。
当编码方式为utf-8时,varchar存到21845就存不下了.也就是最大长度是21844.根据上面信息可以推算出
( 65535-2 )/3=21844余1
8.2
言归正传那为什么我们会经常性设置成varchar(255)呢?
首先我们要知道一个概念:InnoDB存储引擎的表索引的前缀长度最长是767字节(bytes)
你如果需要建索引,就不能超过 767 bytes;utf8编码时 255*3=765bytes ,恰恰是能建索引情况下的最大值。
如果像lavavel5.3往后 使用的是utf8mb4编码,默认字符长度则应该是 767除以4向下取整,也就是191。
9.
select a=b 结果true ,会返回1 false返回0
null=null是错的 ,不可用=比较 只能null<=>null
a=null错的 , 可写为 a<=>null 或者 a is null
当你把一个字段默认值设为null时候,查询是要考虑null的特殊性

10.
mysql 有严格模式 和 非严格模式
举例: 比如你varchar(4), ‘abcde’ 严格模式下不保存,并报错
而非严格模式下会保存为‘abcd’
11. TEXT,BLOB用来存储大文本。 在删除时,会留下很大的‘空洞’,有多用OPTIMIZE TABLE功能对这类表进行碎片整理。
防止空洞引发性能问题。
12. 分析索引。
explain这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描
可参考 【MySQL优化】——看懂explain_漫漫长途,终有回转;余味苦涩,终有回甘-CSDN博客_explain

13. 背景:
一个字段类型为varchar, 你查询的时候值是需要加单引号的。
但你存储的是数字,你查询是需要写成 name = ‘1’ ,
如果 你写成 name =1 ,发现也可以查询到。
但假如你写成0, 会发生奇特的事。
问题是隐匿转换造成的

13.2
以上说的是varchar类型,
int类型也有一些问题
它会截取前面的数字部分

14. mysql索引,在查询时候,你觉得他的执行计划不妥,可以自己指定
使用索引:use index
忽略索引:ignore index
强制使用:force index
例如: select * from student ignore index(se) where sex='a';
********************************************************************************************************************
2020-08-18 新补充
1. 简单数据类型的操作通常需要更少的CPU周期。例如,整型比字符操作代价更低,因为字符集和校对规则(排序规则)使字符比较比整型比较更复杂
2. 因为需要额外的空间和计算开销,所以应该尽量只在对小数进行精确计算时才使用DECIMAL——例如存储财务数据。
但在数据量比较大的时候,可以考虑使用BIGINT代替DECIMAL,将需要存储的货币单位根据小数的位数乘以相应的倍数即可。
假设要存储财务数据精确到万分之一分,则可以把所有金额乘以一百万,然后将结果存储在BIGINT里,这样可以同时避免浮点存储计算不精确和DECIMAL精确计算代价高的问题。
3. VARCHAR需要使用1或2个额外字节记录字符串的长度:如果列的最大长度小于或等于255字节,则只使用1个字节表示,否则使用2个字节。
5. 前缀索引是一种能使索引更小、更快的有效办法,但另一方面也有其缺点:MySQL无法使用前缀索引做ORDERBY和GROUPBY,也无法使用前缀索引做覆盖扫描。
6. 顺序的主键什么时候会造成更坏的结果?
对于高并发工作负载,在InnoDB中按主键顺序插入可能会造成明显的争用。主键的上界会成为“热点”。因为所有的插入都发生在这里,所以并发插入可能导致间隙锁竞争。
另一个热点可能是AUTOINCREMENT锁机制;如果遇到这个问题,则可能需要考虑重新设计表或者应用,或者更改innodb autoinc_lock mode配置。
如果你的服务器版本还不支持innodb_autoinc_lock_mode参数,可以升级到新版本的InnoDB,可能对这种场景会工作得更好。
7. 如果用一个大的语句一次性完成的话,则可能需要一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
将一个大的DELETE语句切分成多个较小的查询可以尽可能小地影响MySQL性能,同时还可以减少MySQL复制的延迟。
8. 列表IN()的比较
在很多数据库系统中,IN()完全等同于多个0R条件的子句,因为这两者是完全等价的。在MySQL中这点是不成立的,MySQL将IN()列表中的数据先进行排序,然后通过二分查找的方式来确定列表中的值是否满足条件,
这是一个O(logn)复杂度的操作,等价地转换成OR查询的复杂度为O(n),对于IN()列表中有大量取值的时候,MySQL的处理速度将会更快。
9. MySQL是如何选择合适的关联顺序来让查询执行的成本尽可能低的。重新定义关联的顺序是优化器非常重要的一部分功能。
不过,糟糕的是,如果有超过n个表的关联,那么需要检查n的阶乘种关联顺序。我们称之为所有可能的执行计划的“搜索空间”,搜索空间的增长速度非常快!
当搜索空间非常大的时候,优化器不可能逐一评估每一种关联顺序的成本。这时,优化器选择使用“贪婪”搜索的方式查找“最优”的关联顺序。
实际上,当需要关联的表超过optimizer_search_depth的限制的时候,就会选择“贪婪”搜索模式了(optimizer_search_depth 参数可以根据需要指定大小)。
10. 分页的优化,第一种,可以先查询出id,在回表查询具体的数据行。
第二种,条件每次返回id之类的,先过滤一下。 例如;select * from xx where id >10000 limit 10
11. 本地试了下,null列是可以用到索引的,不管是单列索引还是联合索引,但is null,is not null是不走索引的。
12. 对字符串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的 列,如果在前10 个或20 个字符 内,多数值是惟一的,那么就不要对整个列进行索引。
短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
13. text
text的最大限制也是64k个字节,但是本质是溢出存储,innodb默认只会存放前768字节在数据页中,而剩余的数据则会存储在溢出段中。text类型的数据,将被存储在元数据表之外地方,但是varchar/char将和其他列一起存储在表数据文件中,值得注意的是,varchar列在溢出的时候会自动转换为text类型。text数据类型实际上将会大幅度增加数据库表文件尺寸。
除此之外,二者还有以下的区别
1、当text作为索引的时候,必须 制定索引的长度,而当varchar充当索引的时候,可以不用指明。
2、text列不允许拥有默认值
3、当text列的内容很多的时候,text列的内容会保留一个指针在记录中,这个指针指向了磁盘中的一块区域,当对这个表进行select *的时候,会从磁盘中读取text的值,影响查询的性能,而varchar不会存在这个问题。
***********************************************************************************************************************************
以下几条来源于本人测试,所以请以此为准
索引
1. 范围情况下的索引
1.1 in, or 是可以走索引的
1.2 > < != 也不走索引,这时候加上强制索引,它就会使用索引。
1.3 like '%aa' %在前面不会走索引
2. 即使使用强制索引, force index(`aa`) aa是索引的名字,不是字段
如果你where后面没有索引的字段,他也不走索引 ,它会智能分析用不用,所以一般你也用不到强制。 ( > < != 也不走索引,这时候加上强制索引,它就会使用索引。 )
即使连表查询 on连接条件后面有索引字段,也不走索引的
3. 一个有趣的问题 where userId =33 和 where userId = ‘33’ 是不一样的 如果你是varchar类型,前者不会走索引,因为他是int类型。
换句话:值的类型不一致,也不走索引
奇怪的是 类型如果是int型 也就是说你应该写where userId =33 你写成 where userId = ‘33’ 也可以走索引,私下认为可能是因为mysql里面'' 可以包住任何类型吧
4. 这里必须说明一点,注意字符集,注意字符集, 有一次我两表关联字段(varchar)为索引,但却总不走,才发现,一边为utf8, 一边为utf8mb4
(如果你要修改Utf8为utf8mb4,改了表后,去看看字段的有没有变过来,还有就是你原先存储的数据是改不字符集了)
如果你不想改变表,还想用一下
可以这样 转编码, 转字符类型 如下:


13. 建立索引的原则
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录
4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
5.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可
6. 索引不会包含有NULL值的列
只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL
1.MyISAM和InnoDB的区别

1.1 所有引擎中,只有innoDB和BDB事务安全,其他表都不是事务安全的。
1.2 innoDB自增列如果插入0或者null,则实际插入值为正常增长后的值。
1.3 InnoDB自增列必须是索引(系统会提示你,要不就报错)。 如果是组合索引,必须是第一个。
但MyISAM 组合索引不是第一个也可以创建成功。 只是会发生如下现象。
此时,设置的ige自增,ids为索引第一个


1.4 InnoDB下char和varchar 在行存储格式上没有区分,都是用头指针。
所以不太确定时候, 建议多用varchar, 因为char平均占用空间多于varchar。
而MyISAM下却建议多用char。
1.5 InnoDB存储,存储时顺序是按 主键——> 唯一索引—>自动生成内部列
按内部列并不快,索引尽量自己指定主键。
当有多个唯一列时,选择最常用的
另外 InnoDB 的普通索引会存储主键的值。所以主键值越短越好
可参考 主键索引和非主键索引的区别 - しちさくら - 博客园 主键索引和非主键索引的区别
更多请参见:MyISAM和InnoDB的区别 - 瞬间永恒成功 - 博客园
2.

千万级数据优化: 如何优化MySQL千万级大表,我写了6000字的解读_杨建荣的学习笔记-CSDN博客
3. 时间格式化
可用注解 @DateTimeFormat 和 @JsonFormat
也可以 在sql语句直接进行


4. mysql 底层数据结构

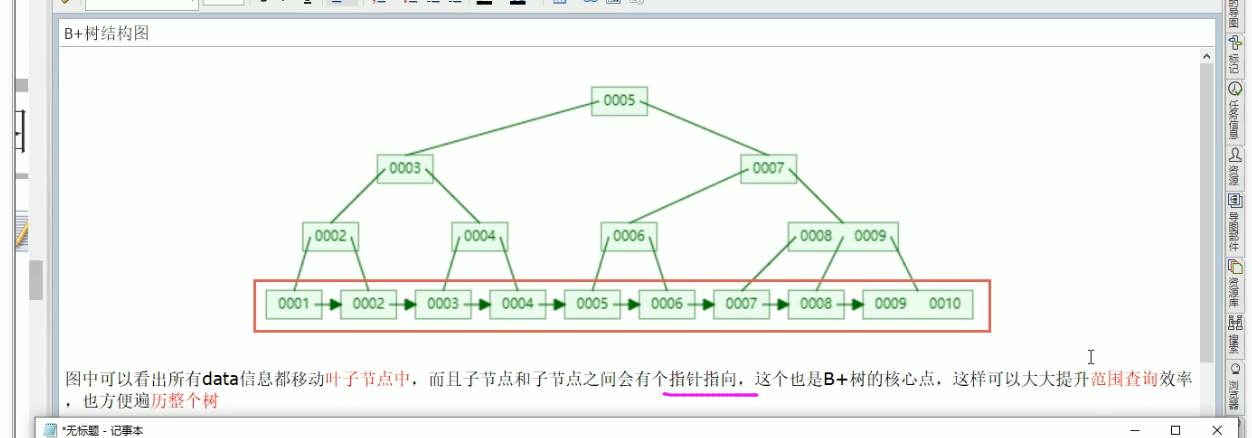
之间有指针指向,也就是链表,不再需要中序遍历(中序遍历相当于迭代遍历)
复合索引
联合索引在B+树上的结构介绍_zgjdzwhy的博客-CSDN博客_联合索引数据结构

5.

6. order by

7. 事务
7.1 mysql的隔离级别有
读未提交(Read Uncommitted):什么也解决不了
读已提交(Read Committed):解决了脏读问题。
可重复读取(Repeatable Read):禁止不可重复读取和脏读取,但是有时可能出现幻读数据。
串行化(Serializable):解决了幻读的问题的。
7.2 故障有:
脏读:读取到别人 未提交的 数据
不可重复读:首先这不是问题-------因为假如你存了100, 你爸爸在另一台取款机上可查出多了100,这其实不是问题
但是现在是要保证每次读取数据都不变, 那么不可重复读是说, 你开了一个事务,存了100,提交。 你爸爸在他开启的事务 里怎么查询都不会多100, 除非提交了他的事务,然后查询,就会发现多了100
幻读: 最简单的解释他读到了别人 新插入的数据。 要实现你的这样子操作
首先咱们默认事务级别是可重复读。
开启一个事务A, 一个事务B.
然后A插入数据, 提交。 你知道这时候B里面你查询是查询不到的。
接着你B里面 修改所有数据,比如 update user set age =8;
这时候,你会发现 他把新插入的数据也改了
得出一个预期之外的结论:解决了读数据情况下的幻读问题。而对于修改的操作依旧存在幻读问题,就是说MVCC对于幻读的解决时不彻底的。
或者另一方面也说明了结论,确实可重复读可能产生幻读,因为在修改时候,修改了新加进来的记录。
另外这也说明了他没有做到隔离性。
该部分可参考: MySQL的可重复读级别能解决幻读吗 - 宁愿呢 - 博客园 https://www.cnblogs.com/liyus/p/10556563.html
序列化: 这里做的测试结论就是:如果一个事务正在进行,直接另一个事务的所有操作都进入阻塞状态,直接那个事务完结。

8. 锁
参考来源
https://zhuanlan.zhihu.com/p/29150809?utm_source=wechat_session&utm_medium=social&utm_oi=601725475492597760
https://www.cnblogs.com/mr-wuxiansheng/p/7044733.html
-------------------
1.排它锁(X锁),自己可读写, 他人(有锁的)不可读写 ---自己啥也可以
共享锁(S锁), 自己可以读,不可写。 他人可读, 不可写 ---只可读
tip: 经过实验发现,给某数据加了排它锁之后, 你其他事务如果也是用加锁的方式,是无法读写。
但是! 如果你不加任何锁(比如SELECT * from hero where id = 1 ),单纯查询是可以查询出来的,但你要修改也不行, 会进入堵塞。
某天,找到了答案: 如下

2. 排它锁,只能在数据上加一次
共享锁,大家可以都对这个数据块加锁。
3. mysql InnoDB引擎默认的修改数据语句,
update,delete,insert都会自动给涉及到的数据加上排他锁,
select语句默认不会加任 何锁类型
4. 手动加锁: 如果加排他锁可以使用select ...for update语句,
加共享锁可以使用select ... lock in share mode语句
1. mysql如果写的时候,有索引的话, 会直接走行锁,如果你是等于,就锁一行,
如果是大于小于之类的范围,估计就是范围 加行锁。
没有索引,可能会直接锁表。
oracle据说永远是锁数据行。
2. MyISAM表锁是deadlock free的,这是因为MyISAM总是一次获得所需的全部锁,要么全部满足,要么等待,因此不会出现死 锁。
但在InnoDB中,除单个SQL组成的事务外,锁是逐步获得的,这就决定了在InnoDB中发生死锁是可能的。

9. 查询
9.1 查询可用正则,图来源于
(4条消息) MySQL事务_吾妻雪乃的博客-CSDN博客 https://blog.csdn.net/weixin_55609814/article/details/118188359?spm=1001.2014.3001.5501
