Redis是一个开源的内存数据存储框架,可以当作一个缓存数据库来使用,支持strings,hashes,lists,sets,sorted sets等多种数据格式的范围查询,支持bitmaps,hyperloglogs和geospatialindexes 的半径查询。它还内置了replication,Lua scripting,LRU eviction,transactions ,还有不同等级的磁盘持久化存储功能。更重要的是,它还提供了高性能的集群功能。下面,是关于Redis3.0及其以上的版本的集群介绍:
Redis Cluster 101(概述)
RedisCluster提供了这么一种运行Redis的方式:通过多Redis节点自动共享存储数据(集群)
RedisCluster也提供了部分分区的可用性的方案,这指的是在实际运用过程中,当一些节点发生错误或者不能通讯的时候,能够去继续对数据进行操作的一种机制。当然,如果发生了一些比较重大的错误,集群将会停止工作,比如,当集群中的节点发生错误达到一半以上的时候。
那么,在实际应用中,我们应该需要怎样一个Redis Cluster呢?下面是官方给出的说法。
1)拥有在多个节点自动分割数据集的能力
2)拥有当子节点出现错误能够继续正常运行的能力
Redis Cluster TCP ports(端口号)
每个RedisCluster节点都需要两个TCP连接打开。其中一个端口用于服务客户(这个端口被称为normal端口,比如那个默认的6379),另一个端口是第一个端口号的数字加上10000得到一个端口,也就是16379。
第二个高端口用于Cluster bus(集群总线),用于节点与节点之间的通讯(node-to-node),为提高通讯效率,节点与节点之间使用二进制协议通讯。Cluster bus被节点们用来侦听节点是否出现错误、更新配置、故障转移授权等事件的发生。客户端不能使用这个端口进行相关通讯,它们只能通过第一个端口进行相关操作(第一个端口也被称为是命令端口)。所以在使用过程中要确保在防火墙中开启了这两个端口,否则Redis Cluster中的所有节点之间将不能通讯。
命令端口和Clusterbus端口的偏移量是固定的,通常为10000.
注意,为了保证Redis Cluster的正常工作,你需要为每个节点配置以下两个端口:
1)正常的客户端通讯端口(默认6379),开放给所有能够接触到集群的客户端,还有其他的所有集群节点()
2)The cluster bus端口,(the client port + 10000)必须被所有集群内节点能够到达
Redis Cluster data sharding(数据碎片)
Redis Cluster不使用一致性哈希,它引入了hash slot(哈希槽)的概念,在Redis中有16384个hash slot,从概念上来说,每个不同形式的碎片都是hash slot的一部分。至于每个key被放到哪个hash slot,取决于CRC16(key)%16384。
在集群中,每个节点都有能力去处理hash slot的子集,假如你有一个三个节点的集群,那么:
节点A包含hash slot 0 到 5500
节点B包含 5501 到 11000
节点C包含 11001 到 16383
这样,在集群中增加或者移除一个节点就很容易了。例如,如果我想增加一个新的节点D,我需要移动一些hash solt从节点A、B、C到D。同样的,如果我想从集群上移除掉节点A,我仅仅需要将节点A上所服务的hash slot移动到B和C上就可以了。当节点A中没有hashsolt(is empty)的时候,我可以从集群上彻底的移除掉它。
由于从一个节点上移移动hash slot到另一个节点上,不需要停止Redis运作,增加和移除节点,或者改变每个节点上的hash slot的百分比都不需要任何的停机时间。换句话来说,操作节点上的hashslot是不需要停止Redis集群服务的。
Redis支持多键操作,只要这些键处于一个单一的命令执行中(完整的事务、或者脚本执行等)都属于同一个hash slot。通过使用hash tags我们可以强制多个key都是同一个hash slot的一部分。
想要了解hashtags的可以去看Redis的Redis Clusterspecification,在哪里有着所有关于Redis Cluster的详细说明和规范。
关于hashtags指的是拿key的部分子字符串当作逻辑上的key,保证这个key的hash值相同,然后放到同一个hashslot就行了。具体参看官网。
Redis Cluster master-slave model(主人-奴隶模型)
当一个主节点的子集发生了错误或者大多数的节点都不能通讯了的时候,为了保持可用,Redis Cluster 使用了主人-奴隶模型,即每个hash slot都有从1(master自身)到N个备份(N-1表示奴隶节点)。
在上面提到的节点A、B、C的例子中,如果节点B发生错误,集群就没有能力继续了,因为我们没有任何办法去使用在5501到11000范围内的hash slot。
然而,如果是这种模型,我们为每个master增加了一个slave节点,集群组成是:A、B、C这三个仍然是master,A1、B1、C1这三个slave节点分别对应A、B、C三个节点,那么,这个时候,如果master节点B发生了错误,我们仍然可以保证系统是正常运行的,因为在B1中有着B的所有备份。
节点B1备份B,B失效,集群将会提升节点B1作为一个新的master节点,并且保证它能够正常工作。
不过如果B和B1同时都失效了,整个B的服务也就都停止了。
Redis Cluster consistency guarantees(一致性保证)
Redis不能保证数据的强一致性,这意味着在实际使用的过程中一些特定条件下Redis Cluster可能会丢失一些数据。这是因为Redis使用了异步备份的机制,这导致,在数据写入的过程中可能发生:
1)客户端写入节点master B
2)节点master B回复客户端OK指令
3)节点master B将写入的数据传给B1、B2、B3
正如你所看到的在回应客户端的时候节点B不等来自B1、B2、B3的ack,因为等待来自slave节点的ack在Redis看来是不允许的,所以若是你的数据到达B,并且等到了B的ack,但是这个时候,B崩溃了,而且数据还没来得及备份到其他slave节点,这时候Redis Cluster会推选出一个新的master节点B出来,这样的话,你的数据就永远的丢失了。
当然为了保证数据不出问题,你也可以配置Redis每秒钟都将数据保存到硬盘上,但这样做就会让其效率降低,在性能和一致性上,总是要做出一个选择的,这就看业务需要了。
如果真的有必要,Redis Cluster也支持同步写操作,通过WAIT 这个命令可以实现,这减少了数据丢失的可能性,不过请注意,即使使用了同步复制机制Redis Cluster也不实现强一致性:在更复杂的场景中,它总是有可能出现失败的,一个slave不可能和当前的master一模一样的!
还有一个值得注意的可能丢失数据的场景是出现了网络分区,一个客户端和至少一个master中的少数实例被孤立了。比如,我们的集群有6个组成:A、B、C、A1、B1、C1,其中前三个为master节点,后面三个为slave节点;有一个客户端,我们称它为Z1。
Z1仍向B写入数据,并且B将会接收写入的数据,如果网络分区发生的时间很短,集群将会继续正常工作。然而,如果网络分区存在足够长的时间,让B1被提升为了master,在大多数的分区中,Z1写入的数据就丢失了。
请注意,如果在这段足够长的时间内,多数的一边选择了一个slave作为新的master,每个master节点在少数的这边停止接收写入。
对于Redis Cluster来说,这个时间是一个非常重要的配置,被称之为节点超时时间。
当节点超时时间过去后,一个master节点被认为是失效的节点,可以被一个它的备份所替代。同样的,如果节点超时时间过去之后,少数的这一边的master节点仍然没能够检测到多数的master节点,那么它将会进入失败状态,停止接收写入数据。
Redis Cluster configuration parameters(集群配置参数)
下面将会创建一个示例集群,在那之前,先介绍一下一些配置参数,这些参数在redis.conf文件中。
1)cluster-enabled <yes/no>:是否支持集群,yes表示支持
2)cluster-config-file <filename>:注意不用管参数中的filename,这个不是用户可以编辑的配置文件,这个文件自动保存配置变化包括状态和一些基本属性,这是为了每次启动都能够读取上次的配置信息。这个文件会以字符串的形式列举出集群中其他的节点的信息,比如它们的状态、持久化变量等等,由于接收一些消息,通常这个文件会被重写到磁盘上。
3)cluster-node-timeout <milliseconds>:节点的最大超时时间(超过此时间,此节点失效),值得注意的是,任何一个节点在这个时间段内不能够与其他节点沟通,将会停止接收查询。
4)cluster-slave-validity-factor <factor>:如果设置为0,一个slave总是试图切换为master,不管master与slave保持断开的时间是多少。如果这个值大于0,最大的断开连接时间为node-timeout乘以factor的值,如果这个节点是slave,在指定的时间内,master的连接断开它不会尝试开始一个故障转移。例如,如果node-timeout设置为5秒,factor设置为10,salve从master断开连接超过50秒都不会尝试故障转移。请注意,只要是值不等于0,如果没有一个slave能够故障转移,在master发生错误后将导致Redis Cluster无效。在这种情况下,只有当原来的master重新加入集群,Redis Cluster才会返回可用状态。
5)cluster-migration-barrier <count>:一个master节点保留的最小slave连接数量,Redis Cluster会尽可能的保证每个master节点都拥有至少一个slave节点,当某个master没有slave节点时,Redis会通过一种算法让其他master节点的多余salve节点进行迁移,而这个配置就控制master的slave的最小个数,比如如果这个值设置为2,那么当master大于2的时候,slave才会进行迁移。
6)cluster-require-full-coverage <yes/no>:默认为yes,表示如果有slot没有被节点覆盖,则整个集群不可用,如果为no,即便有slot没有被覆盖,集群也可用。
Creating and using a Redis Cluster(创建/使用一个redis集群)
创建一个集群,第一件需要做的事情就是在集群模式下拥有一些Redis的空实例。这基本上意味着,集群不是使用正常的Redis实例创建的,需要去配置一些指定的模式,以此来让Redis实例激活Cluster指定的一些特征和命令。
下面是最小的RedisCluster配置文件:
port 7000
cluster-enableyes
cluster-config-filenodes.conf
cluster-node-timeout5000
appendonly yes
这种最小的集群,要拥有至少3个master节点,第一次测试,官方建议开6个节点,三个master三个slave。
首先创建一个目录,然后按照端口号创建文件夹,如下命令:
mkdir cluster-test cd cluster-test mkdir 7000 7001 7002 7003 7004 7005 在每个文件夹中创建redis.conf文件,直接用上面的那个最小集群配置就可以了。
按照下面的命令开起来6个实例,注意是7000-7005:
cd 7000../redis-server ./redis.conf这个时候,每个redis实例的日志都会显示

这里有一个39位的唯一标识,这个标识将作为节点间的通讯标志,Redis Cluster不会依赖IP或者端口号来区分彼此。这个唯一标识,被称之为node ID
上面只是开启了六个redis空实例,下面开始创建集群,这里需要添加一些有意义的配置,通过redis-trib就可以很容易的完成这些( reshard是rediscluster另一核心功能,它通过迁移哈希槽来达到负载匀衡和可扩展目的。)。
Redis-trib是一个ruby脚本,需要安装rubygems
安装命令:yum install rubygems
安装完成后运行命令:geminstall redis

下面是创建集群的命令:
./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 \127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
下面这个直接yes
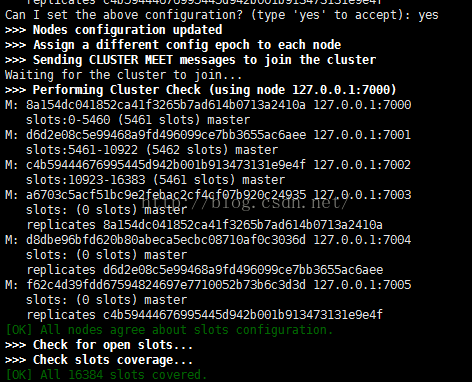
这里的命令用的是create,是因为我们想要创建一个全新的集群,--replicas 1 表示创建一个有1个备份的六个节点的Redis Cluster。其他的参数是一系列的想要加入集群的redis实例ip地址。
当我们看到All 16384slots covered就表示集群成功了。
另外,如果你不想用这种手动集成的方法,也可以去使用redis安装包里面utils目录下的create-cluster脚本,具体用法查看README文件,使用这个脚本可以很轻松的创建集群。