一、哈希算法
哈希算法(也叫散列算法),任意长度的值通过哈希算法会变得到一个固定的key(地址),之后可以将数据存储在该位置上。简单地说,它通过将关键码值映射到表的一个固定位置上,以加快查询速度!
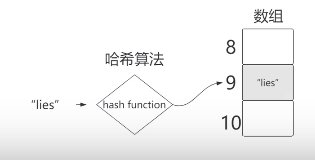
比如说Hashcode就是一个具体的哈希算法,它首先会计算出一个字符串的ascii码,之后进行取模(节省空间并且不会超出哈希表的下标),算出它存储在哈希表中的下标(如下图所示)。

二、哈希表
在JDK1.8之前HashMap的底层实现结构采用的是哈希表。 但是当HashMap存储大量数据的时候哈希表的链表长度会很长,这会严重影响查询速度,所以在JDK1.8使用红黑树+链表解决这一问题。发展过程:数组->哈希冲突->加入链表->查询慢->加入红黑树->插入和删除慢->链表和红黑树并存

三、红黑树
JDK 1.8 对 HashMap 进行了比较大的优化,底层实现由之前的 “数组+链表”(哈希表) 改为 “数组+链表+红黑树”。红黑树的概念如下:
1.节点不是黑色就是红色;
2.根结点是黑色的;
3.叶子节点是黑色的空节点;
4.如果某个节点为红色,那么它的两个子节点应该是黑色的(不能有两个连续的红色节点);
5.从某个节点出发到其子孙叶节点的所有路径应该包含相同数目的黑色节点;
四、JDK7 HashMap
JDK7中HashMap的底层存储结构是Entry数组,key和value首先会被封装成为一个Entry对象,之后获取key的hashCode值并与(哈希表.length-1)进行&操作,再存入Entry数组的对应位置上,HashMap的存储结构图如下:

1.HashMap的重要属性和存储结构
//默认初始化化容量,即16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//最大容量,即2的30次方
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认装载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//HashMap内部的存储结构是一个Entry数组,此处数组为空,即没有初始化之前的状态
static final Entry<?,?>[] EMPTY_TABLE = {
};
//空的存储实体
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
//实际存储的key-value键值对的个数
transient int size;
//阈值,HashMap在进行扩容时需要参考threshold
int threshold;
//负载因子,代表了table的填充度有多少,默认是0.75
final float loadFactor;
//用于快速失败,由于HashMap非线程安全,在对HashMap进行迭代时,如果期间其他线程的参与导致HashMap的结构发生变化了(比如put,remove等操作),需要抛出异常ConcurrentModificationException
transient int modCount;
//默认的threshold值
static final int ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
2.HashMap的构造方法
//通过初始容量和状态因子构造HashMap
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)//参数有效性检查
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)//参数有效性检查
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))//参数有效性检查
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();//init方法在HashMap中没有实际实现,不过在其子类如 linkedHashMap中就会有对应实现
}
//通过扩容因子构造HashMap,容量去默认值,即16
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//装载因子取0.75,容量取16,构造HashMap
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
//通过其他Map来初始化HashMap,容量通过其他Map的size来计算,装载因子取0.75
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1, DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
inflateTable(threshold);//初始化HashMap底层的数组结构
putAllForCreate(m);//添加m中的元素
}
3.HashMap的put方法
public V put(K key, V value) {
//如果table为空数组{},进行数组填充(为table分配实际内存空间),实参为threshold,此时threshold为initialCapacity默认是16
if (table == EMPTY_TABLE) {
inflateTable(threshold);//分配数组空间
}
//如果key为null,存储位置为table[0]或table[0]的冲突链上
if (key == null)
return putForNullKey(value);
int hash = hash(key);//对key的hashcode进一步计算,确保散列均匀
int i = indexFor(hash, table.length);//获取在table中的实际位置
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
//如果该对应数据已存在,执行覆盖操作。用新value替换旧value,并返回旧value
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);//调用value的回调函数,其实这个函数也为空实现
return oldValue;
}
}
modCount++;//保证并发访问时,若HashMap内部结构发生变化,快速响应失败
addEntry(hash, key, value, i);//新增一个entry
return null;
}
private void inflateTable(int toSize) {
int capacity = roundUpToPowerOf2(toSize);//capacity一定是2的次幂
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);//此处为threshold赋值,取capacity*loadFactor和MAXIMUM_CAPACITY+1的最小值,capaticy一定不会超过MAXIMUM_CAPACITY,除非loadFactor大于1
table = new Entry[capacity];//分配空间
initHashSeedAsNeeded(capacity);//选择合适的Hash因子
}
void addEntry(int hash, K key, V value, int bucketIndex) {
//当size(键值对个数)超过临界阈值threshold,并且即将发生哈希冲突时进行扩容,新容量为旧容量的2倍
if ((size >= threshold) && (null != table[bucketIndex])){
resize(2 * table.length);//当size超过临界阈值threshold,并且即将发生哈希冲突时进行扩容,新容量为旧容量的2倍
//key为null的键值对存放在数组下标为0的地方
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);//扩容后重新计算插入的位置下标
}
//把元素放入HashMap的的对应位置
createEntry(hash, key, value, bucketIndex);
}
//创建新的Entry元素
void createEntry(int hash, K key, V value, int bucketIndex){
Entry<K,V> e = table[bucketIndex]; //获取待插入位置元素
table[bucketIndex] = new Entry<>(hash, key, value, e);//采用头插法插入元素
// hashmap存储的键值对个数+1
size++;
}
//按新的容量扩容Hash表
void resize(int newCapacity) {
Entry[] oldTable = table;//老的数据
int oldCapacity = oldTable.length;//获取老的容量值
if (oldCapacity == MAXIMUM_CAPACITY) {
//如果旧的容量值已经到了最大
threshold = Integer.MAX_VALUE;//修改阀值
return;
}
//新的表
Entry[] newTable = new Entry[newCapacity];
//将旧表中的数据拷贝到新表中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
//修改阀值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
//将老的表中的数据拷贝到新的结构中
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//遍历旧表中的每一个元素
for (Entry<K,V> e : table) {
while(null != e) {
//遍历链表中的每一个元素
Entry<K,V> next = e.next;
if (rehash) {
//是否重新计算哈希值
//如果e的key为null,哈希值为0,否则用hash函数计算
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);//定位Entry结点在新表中的位置
e.next = newTable[i];//采用头插法插入
newTable[i] = e;
e = next;//e为旧表链表中的下一个元素
}
}
}
4.HashMap的get方法
//HashMap允许key为null
public V get(Object key) {
if (key == null)//如果Key值为空,则获取对应的值,这里也可以看到,HashMap允许null的key,其内部针对null的key有特殊的逻辑
return getForNullKey();
Entry<K,V> entry = getEntry(key);//获取实体
return null == entry ? null : entry.getValue();//判断是否为空,不为空,则获取对应的值
}
//获取key为null的实体
private V getForNullKey() {
if (size == 0) {
//如果元素个数为0,则直接返回null
return null;
}
//key为null的元素存储在table的第0个位置
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)//判断是否为null
return e.value;//返回其值
}
return null;
}
五、JDK7 ConcurrentHashMap
ConcurrentHashMap底层维护者一个segment数组,该数组中存放的是Segment对象(可加锁),该对象的内部包含一个HashEntry数组:

向ConcurrentHashMap存入数据流程如下:

1.ConcurrentHashMap的重要属性和存储结构
//segments数组中所有segments对象的HashEntry数组长度总和
static final int DEFAULT_INITIAL_CAPACITY = 16;
//默认加载因子,可以类比HashMap中的加载因子,用于扩容,因为segments数组是
//用来并发的,一旦确定就不能扩容,所以这个值会传给每个Segment,Segment对象
//对table数组进行扩容,这个属性代表table数组中已经用的占比标准,默认为0.75,
//如果table数组中非null占比大于0.75,就该扩容了
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//默认并发级别,代表并发的最大数,也就是segments数组的容量的大小
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
//最大容量,ConcurrentHashMap的最大容量,最大扩容为2^30,到这就不再扩容
static final int MAXIMUM_CAPACITY = 1 << 30;
// 最小容量,table数组的最小容量:2
static final int MIN_SEGMENT_TABLE_CAPACITY = 2;
//最大segments容量
static final int MAX_SEGMENTS = 1 << 16;
//表示尝试锁的次数
static final int RETRIES_BEFORE_LOCK = 2;
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
/*
自旋锁的等待次数上限,多处理器时64次,单处理器时1次。
每次等待都会进行查询操作,当等待次数超过上限时,不再自旋,调用lock方法等待获取锁,进入阻塞状态
*/
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
transient volatile HashEntry<K,V>[] table;
//表中元素的个数
transient int count;
/*
记录导致数据发生变化的操作次数。
在统计segment.count前后,都会统计segment.modCount,如果前后两次值发生变化,可以判断在统计count期间有segment发生了修改操作
*/
transient int modCount;
/*
容量阈值,超过这一数值后segment将进行扩容,容量变为原来的两倍。
threshold = loadFactor*table.length
*/
transient int threshold;
final float loadFactor;
Segment(float lf, int threshold, HashEntry<K,V>[] tab) {
this.loadFactor = lf;
this.threshold = threshold;
this.table = tab;
}
2.ConcurrentHashMap的构造方法
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
//initialCapacity:所有segment对象的hashentry数组的总长度;concurrencyLevel:并发等级用于segment数组的长度,默认为16
//每个segment对象的hashentry数组的长度=initialCapacity/concurrencyLevel
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// ssize 必须是 2^n, 即 2, 4, 8, 16 ... 表示了segments 数组的大小
int sshift = 0;
int ssize = 1;
//确保segments数组的大小为2的整数倍
while (ssize < concurrencyLevel) {
//sshift是ssize左移的次数
++sshift;
//ssize是大于concurrencyLevel的最小2的整数倍
//当concurrencyLevel为2的整数时ssize=concurrencyLevel->segment数组长度等于concurrencyLevel
ssize <<= 1;
}
// segmentShift默认是 32 - 4 = 28
this.segmentShift = 32 - sshift;
// segmentMask 默认是 15 即 0000 0000 0000 1111
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//c表示segment数组中每个segment对象的hashentry数组的长度
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
//确保segment对象的hashentry数组的长度也为2的指数
++c;
// MIN_SEGMENT_TABLE_CAPACITY默认为2
int cap = MIN_SEGMENT_TABLE_CAPACITY;
//重新确定segment对象的hashentry数组的长度,确保数组的最小长度为2并且为c的最小的2指数倍
while (cap < c)
cap <<= 1;
// 创建segment对象s0->segments[0]
Segment<K,V> s0 =new Segment<K,V>(loadFactor, (int)(cap * loadFactor),(HashEntry<K,V>[])new HashEntry[cap]);
// 创建segment数组ss
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
//将s0置于ss的下标为0的位置
//创建s0的原因:以后在创建segment对象时可以直接从s0获得相关指标
UNSAFE.putOrderedObject(ss, SBASE, s0);
this.segments = ss;
}
3.ConcurrentHashMap的put方法
public V put(K key, V value) {
Segment<K,V> s;
//向ConcurrentHashMap存入键值对时,值不能为空,否则抛出空指针异常
if (value == null)
throw new NullPointerException();
//计算key的hash值
int hash = hash(key);
//计算出存放键值对的segment数组下标
int j = (hash >>> segmentShift) & segmentMask;
// 判断segment数组中的对应下标处是否有segment对象
if ((s = (Segment<K,V>)UNSAFE.getObject(segments, (j << SSHIFT) + SBASE)) == null) {
// 这时不能确定是否真的为 null, 因为其它线程也可能发现该segment为null并创建
// 因此在 ensureSegment里用cas方式保证该segment安全性
// ensureSegment方法会读取ss[0]的阈值、加载因子等属性并创建新的segment对象返回
s = ensureSegment(j);
}
// 进入segment对象的put 流程
return s.put(key, hash, value, false);
}
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
// 以初始化时创建的第一个坑位的ss[0]作为模版进行创建
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
// 二次检查是否有其它线程创建了这个Segment
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
// recheck
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
//这里通过自旋的CAS方式对segments数组中偏移量为u位置设置值为s,这是一种不加锁的方式,
//万一有多个线程同时执行这一步,那么只会有一个成功,而其它线程在看到第一个执行成功的线程结果后
//会获取到最新的数据从而发现需要更新的坑位已经不为空了,那么就跳出while循环并返回最新的seg
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
4.segment对象的put方法
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//尝试对当前segment对象加锁,如果不成功, 进入scanAndLockForPut流程
//node为null:表示一进来就拿到了锁;node不为null:表示一进来没有拿到锁并指向在scanAndLockForPut流程中创建的HashEntry对象
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
//获取HashEntry数组中对应位置的第一个HashEntry对象
HashEntry<K,V> first = entryAt(tab, index);
//遍历链表
for (HashEntry<K,V> e = first;;) {
//如果e不为空,则比对key,如果相同说明已经有了该key
//将该节点的value修改为新的value,返回旧的oldValue、
//如果不相同,链表指针往后移动,遍历下一个节点
if (e != null) {
K k;
//发现重复关键字
if ((k = e.key) == key ||(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
//用新值替换旧值
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
//如果e为空,则证明已经到了链表的末尾,到了末尾还没找到,则证明没有该key
//创建一个新的节点存储,存储完成后容量加1判断一下是否需要扩容
//如果需要扩容,则需要重哈希(rehash)
else {
// 1) 之前等待锁时, node 已经被创建, next 指向链表头
if (node != null)
//将node节点设置为当前位置的首结点,采用头插法
node.setNext(first);
// 2) 创建新 node
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// 3) 扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
// 将 node 作为链表头
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
}finally {
//解锁segment对象
unlock();
}
//返回旧值
return oldValue;
}
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
//根据this(Segment)和hash确定table中的索引,拿到key所在链表的第一个节点
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
//在等待过程中反正闲着也是闲着,还不如创建出键值对的HashEntry对象,提升效率
HashEntry<K,V> node = null;
//retries表示尝试获取锁的次数
int retries = -1;
//获取锁失败时一直循环,除非tryLock成功或者达到自旋次数,直接Lock,退出
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
//第一阶段(retries < 0):没有找到key相同的节点或者没有遍历完该链表
if (retries < 0) {
//判断当前索引链表是否为空,或者首结点的key是否等于插入key,否则向后遍历
if (e == null) {
//判断node是否被初始化过,如果没有则初始化,置retries为0,进入第二阶段
if (node == null)
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
//key匹配上了,所以就找到了节点,置retries为0,进入第二阶段
else if (key.equals(e.key))
retries = 0;
//指针移动,往后遍历,直至遍历到链表末尾或者与key相等的链表节点
else
e = e.next;
}
//第二阶段(retries >= 0):如果尝试次数大于最大获取锁的次数,则进行Lock操作,退出循环,线程进入阻塞
//MAX_SCAN_RETRIES取决于cpu,在下面有讲解
else if (++retries > MAX_SCAN_RETRIES) {
//tryLock次数太多会极大的耗费cpu的性能,所以采用ock操作阻塞当前线程并跳出循环
lock();
break;
}
//第三阶段(retries >= 0):因为插入元素是头插法,所以这块是为了判断当前链表的首个节点是否等于之前的结点
//如果不等于,则证明其他线程已经插入了元素,retries=-1,进入第一阶段重新开始判断(新插入的结点的key可能等于传入的key)
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
//2倍扩容
int newCapacity = oldCapacity << 1;
//计算阈值
threshold = (int)(newCapacity * loadFactor);
//创建新的table
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
//该值用于后面的hash运算与,保证运算后的值落到数组的范围内
int sizeMask = newCapacity - 1;
//遍历旧表中的每一个头结点
for (int i = 0; i < oldCapacity ; i++) {
HashEntry<K,V> e = oldTable[i];
//判断该位置头结点是否为空,为空就没必要遍历该条链表
if (e != null) {
//第一个数据节点
HashEntry<K,V> next = e.next;
//e节点的新的位置,保证idx落到数组的范围内,这块其实相当于重新hash,sizeMask是newCapacity得来的
int idx = e.hash & sizeMask;
//如果只有一个数据节点,那么直接挪到相应的位置
if (next == null) // Single node on list
newTable[idx] = e;
else {
// Reuse consecutive sequence at same slot
//该条链表rehash后,最后几个节点保持一致的分界点,下面画图举例解释,请细看下面第三点
HashEntry<K,V> lastRun = e;
//记录lastRun节点的位置
int lastIdx = idx;
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
//如果k=lastIdx,就不更新lastIdx和lastRun
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
//将lastRun后面所有链表一同挪过去
newTable[lastIdx] = lastRun;
// Clone remaining nodes
//从头到lastRun一个一个的重新hash,放入该放的位置,方式为头插
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
//把新的节点重哈希,添加到新table中
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
5.ConcurrentHashMap的get方法
public V get(Object key) {
//s为存储键值对的segment对象
Segment<K,V> s;
//tab为segment对象的HashEntry数组
HashEntry<K,V>[] tab;
//h为key的hash值
int h = hash(key);
//u为segment对象在segment数组中的偏移量
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&(tab = s.table) != null) {
//e为HashEntry数组中对应位置上的HashEntry对象
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile(tab, ((long)(((tab.length - 1) & h))
<< TSHIFT) +TBASE);e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
六、JDK8 HashMap
在源码中存在着一个阈值8(static final int TREEIFY_THRESHOLD = 8;),当链表长度大于8会使用红黑树,当链表长度小于8时会继续使用链表,具体的数据结构如下所示:

1.HashMap的重要属性和存储结构
// HashMap
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// 序列号
private static final long serialVersionUID = 362498820763181265L;
// 默认的初始容量是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的填充因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 当桶(bucket)上的结点数大于这个值时会转成红黑树
static final int TREEIFY_THRESHOLD = 8;
// 当桶(bucket)上的结点数小于这个值时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
// 桶中结构转化为红黑树对应的table的最小大小
static final int MIN_TREEIFY_CAPACITY = 64;
// 存储元素的数组,总是2的幂次倍
transient Node<k,v>[] table;
// 存放具体元素的集
transient Set<map.entry<k,v>> entrySet;
// 存放元素的个数,注意这个不等于数组的长度。
transient int size;
// 每次扩容和更改map结构的计数器
transient int modCount;
// 临界值 当实际大小(容量*填充因子)超过临界值时,会进行扩容
int threshold;
// 填充因子
final float loadFactor;
}
// 链表节点, 继承自Entry
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
// 红黑树节点
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
}
2.HashMap的构造方法
// 默认构造函数,加载因子为默认值 0.75f
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
// 包含另一个Map的构造函数
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
// 指定了初始容量
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 指定了初始容量和加载因子,会对参数进行校验
// 初始容量不能为负数,不能大于最大容量 1 << 30
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
3.HashMap的put方法
public V put(K key, V value) {
//实际调用的是putval方法
return putVal(hash(key), key, value, false, true);
}

当 table 长度为 16 时,table.length - 1 = 15 ,用二进制来看,此时低 4 位全是 1,高 28 位全是 0,与 0 进行 & 运算必然为 0,因此哈希值与 “table.length - 1” 的 & 运算结果只取决于哈希值的低 4 位,在这种情况下,哈希值的高 28 位就没有任何作用,并且由于索引位置只取决于哈希值的低 4 位,hash 冲突的概率也会增加。因此,在 JDK 1.8 中,将高位也参与计算,目的是为了降低 hash 冲突的概率。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 1.校验table是否为空或者length等于0,如果是则调用resize方法进行初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 2.通过hash值计算索引位置,将该索引位置的头节点赋值给p,如果p为空则直接在该索引位置新增一个节点即可
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
// table表该索引位置不为空,则进行查找
Node<K,V> e; K k;
// 3.判断p节点(当前索引位置的首结点)的key和hash值是否跟传入的相等,如果相等, 则p为要查找的目标节点,将p节点赋值给e节点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 4.判断p节点是否为TreeNode, 如果是则调用红黑树的putTreeVal方法查找目标节点
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 5.走到这代表p节点为普通链表节点,则调用普通的链表方法进行查找,使用binCount统计链表的节点数
for (int binCount = 0; ; ++binCount) {
// 6.如果p的next节点为空时,则代表找不到目标节点,则新增一个节点并插入链表尾部
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 7.校验节点数是否超过8个,如果超过则调用treeifyBin方法将链表节点转为红黑树节点,
// 减一是因为循环是从p节点的下一个节点开始的
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
// 8.如果e节点存在hash值和key值都与传入的相同,则e节点即为目标节点,跳出循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e; // 将p指向下一个节点
}
}
// 9.如果e节点不为空,则代表目标节点存在,使用传入的value覆盖该节点的value,并返回oldValue
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); // 用于LinkedHashMap
return oldValue;
}
}
++modCount;
// 10.如果插入节点后节点数超过阈值,则调用resize方法进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict); // 用于LinkedHashMap
return null;
}
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length; // table如果为空,oldCap长度设置为0
int oldThr = threshold;
int newCap, newThr = 0;
// 1.0 旧数组中有元素,说明已初始化过,调用resize()是进行扩容的
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
// 1.1 旧数组长度大于最大容量2^30,则将阈值设置为Integer的最大值
threshold = Integer.MAX_VALUE;
// 容量已经达到最大值,无法在进行扩容
return oldTab;
}
// 1.2 旧数组双倍扩容后小于最大容量 并且 旧数组大于默认的初始容量16
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 将阈值threshold*2得到新的阈值
newThr = oldThr << 1;
}
// 2.0
// 旧阈值=threshold大于0
// 说明使用的构造方法是HashMap(int initialCapacity, float loadFactor)
// 该方法中 this.threshold = tableSizeFor(initialCapacity);
// tableSizeFor方法返回的是数组的容量(2^N),例如initialCapacity是1000,那么得到的threshold就是1024,这里threshold就等于数组的容量
else if (oldThr > 0)
// 容量设置为阈值threshold
newCap = oldThr;
else {
// 3.0 阈值为初始化时的0,oldCap为空,即创建数组时无参,调用resize()是为了初始化为默认值
// 将新的长度设置为默认的初始化长度,即16
newCap = DEFAULT_INITIAL_CAPACITY;
// 负载因子0.75*数组长度16=12 新阈值为12
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 4.0 如果新阈值为0,根据负载因子设置新阈值
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr; // 扩容的阈值(可能是以上几种情况之一得到的)
@SuppressWarnings({
"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; // 创建一个长度为newCap的新的Node数组
table = newTab;
// 如果旧的数组中有数据,则将数组复制到新的数组中
if (oldTab != null) {
// 循环遍历旧数组,将有元素的节点进行复制
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
// 旧数组有元素的节点
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 数组
if (e.next == null)
// 重新计算hash值确定元素的位置
newTab[e.hash & (newCap - 1)] = e;
// 红黑树
else if (e instanceof TreeNode)
// 将原本的二叉树结构拆分组成新的红黑树
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
// 链表
else {
// preserve order
// jdk1.8中 旧链表迁移新链表 链表元素相对位置没有变化; 实际是对对象的内存地址进行操作
// jdk1.7中 旧链表迁移新链表 如果在新表的数组索引位置相同,则链表元素会倒置
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// hash值与旧的长度做与运算用于判断元素的在数组中的位置是否需要移动
/**
* 举例:
* (e.hash & oldCap) == 1
* e.hash & (oldCap - 1) e.hash & (newCap - 1) e.hash & oldCap
* ...0101 0010 ...0101 0010 ...0101 0010
* & 0 1111 1 1111 1 0000
* 0 0010 1 0010 1 0000
*
* (e.hash & oldCap) == 0
* e.hash & (oldCap - 1) e.hash & (newCap - 1) e.hash & oldCap
* ...0100 0010 ...0100 0010 ...0100 0010
* & 0 1111 1 1111 1 0000
* 0 0010 0 0010 0 0000
*/
// 总结:
// 数组的长度为2^N,即高位为1,其余为0,计算e.hash & oldCap只需看oldCap最高位1所对应的hash位
// 因为newCap进行了双倍扩容,即将oldCap左移一位,那么oldCap-1相当于newCap-1右移一位,右移后高位补0,与运算只能得到0。
// 如果(e.hash & oldCap) == 0,hash值需要与运算的那一位为0,那么oldCap - 1与newCap - 1的高位都是0,其余位又是相同的,表明旧元素与新元素计算出的位置相同。
// 同理,当其 == 1 时,oldCap-1高位为0,newCap-1高位为1,其余位相同,计算出的新元素的位置比旧元素位置多了2^N,即得出新元素的下标=旧下标+oldCap
// 如果为0,元素位置在扩容后数组中的位置没有发生改变
if ((e.hash & oldCap) == 0) {
if (loTail == null)
// 首位
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 不为0,元素位置在扩容后数组中的位置发生了改变,新的下标位置是原下标位置+原数组长
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
3.HashMap的get方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 数组元素相等
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 桶中不止一个节点
if ((e = first.next) != null) {
// 在树中get
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 在链表中get
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
七、JDK8 ConcurrentHashMap
1.ConcurrentHashMap的重要属性和存储结构
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
private static final long serialVersionUID = 7249069246763182397L;
private static final int MAXIMUM_CAPACITY = 1 << 30;
private static final int DEFAULT_CAPACITY = 16;
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
private static final float LOAD_FACTOR = 0.75f;
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
static final int MIN_TREEIFY_CAPACITY = 64;
private static final int MIN_TRANSFER_STRIDE = 16;
private static int RESIZE_STAMP_BITS = 16;
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
static final int MOVED = -1; // hash for forwarding nodes
static final int TREEBIN = -2; // hash for roots of trees
static final int RESERVED = -3; // hash for transient reservations
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
static final int NCPU = Runtime.getRuntime().availableProcessors();
/**
* The array of bins. Lazily initialized upon first insertion.
* Size is always a power of two. Accessed directly by iterators.
*/
transient volatile Node<K,V>[] table;
/**
* The next table to use; non-null only while resizing.
*/
private transient volatile Node<K,V>[] nextTable;
/**
* Base counter value, used mainly when there is no contention,
* but also as a fallback during table initialization
* races. Updated via CAS.
*/
private transient volatile long baseCount;
/**
* Table initialization and resizing control. When negative, the
* table is being initialized or resized: -1 for initialization,
* else -(1 + the number of active resizing threads). Otherwise,
* when table is null, holds the initial table size to use upon
* creation, or 0 for default. After initialization, holds the
* next element count value upon which to resize the table.
*/
private transient volatile int sizeCtl;
/**
* The next table index (plus one) to split while resizing.
*/
private transient volatile int transferIndex;
/**
* Spinlock (locked via CAS) used when resizing and/or creating CounterCells.
*/
private transient volatile int cellsBusy;
/**
* Table of counter cells. When non-null, size is a power of 2.
*/
private transient volatile CounterCell[] counterCells;
// views
private transient KeySetView<K,V> keySet;
private transient ValuesView<K,V> values;
private transient EntrySetView<K,V> entrySet;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
2.ConcurrentHashMap的构造方法
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
八、总结
1.HashMap不是线程安全的
当有多个线程同时向哈希表的同一位置插入数据时,会导致前一个线程的插入会被后一个线程的插入覆盖
2.HashTable是线程安全的
HashTable在put方法上加了Synchronized关键字进行修饰,可以保证线程安全。但缺点是锁粒度较大,如果多个线程在不同位置上进行插入,在不产生线程安全问题的情况下会导致并发度降低
3.ConcurrentHashMap是线程安全的