文章目录
本系列文章:
Redis进阶之路(一)5种数据类型、Redis常用命令
Redis学习之路(二)Jedis、持久化、事务
Redis学习之路(三)主从复制、键过期删除策略、内存溢出策略、慢查询
Redis学习之路(四)哨兵、集群、读写分离
Redis学习之路(五)缓存、分布式锁
一、Redis缓存
缓存能够有效地加速应用的读写速度,同时也可以降低后端负载。
1.1 使用缓存的好处和坏处
使用缓存图示:

使用缓存的优点:1、提升读写速度;2、降低数据库压力。
使用缓存的缺点:1、数据不一致性;2、代码维护成本和运维成本增加。
1.2 缓存更新策略
- 1、LRU/LFU/FIFO算法删除
使用场景。剔除算法通常用于缓存使用量超过了预设的最大值时候,如何对现有的数据进行剔除。
一致性。要清理哪些数据是由具体算法决定,开发人员只能决定使用哪种算法,所以数据的一致性是最差的。
维护成本。算法不需要开发人员自己来实现,通常只需要配置最大maxmemory和对应的策略即可。开发人员只需要知道每种算法的含义,选择适合自己的算法即可。 - 2、超时删除
使用场景。超时剔除通过给缓存数据设置过期时间,让其在过期时间后自动删除,例如Redis提供的expire命令。
一致性。存在一致性问题。
维护成本。维护成本不是很高,只需设置expire过期时间即可。 - 3、主动更新
使用场景。应用方对于数据的一致性要求高,需要在真实数据更新后,立即更新缓存数据。
一致性。一致性最高,但如果主动更新发生了问题,那么这条数据很可能很长时间不会更新,所以建议结合超时剔除一起使用效果会更好。
维护成本。维护成本会比较高,开发者需要自己来完成更新,并保证更新操作的正确性。
三种常见更新策略的对比:
| 策略 | 一致性 | 维护成本 |
|---|---|---|
| LRU/LFU/FIFO算法删除 | 最差 | 低 |
| 超时删除 | 较差 | 较低 |
| 主动更新 | 强 | 高 |
- 4、最佳实践
低一致性业务建议配置最大内存和淘汰策略的方式使用。
高一致性业务可以结合使用超时剔除和主动更新,这样即使主动更新出了问题,也能保证数据过期时间后删除脏数据。
1.3 缓存穿透及优化
缓存穿透是指缓存和数据库中都没有的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
缓存穿透问题可能会使数据库负载加大,由于很多数据库不具备高并发性,甚至可能造成数据库宕掉。
通常可以在程序中分别统计总调用数、缓存层命中数、存储层命中数,如果发现大量存储层空命中,可能就是出现了缓存穿透问题。
造成缓存穿透的基本原因有两个。第一,自身业务代码或者数据出现问题,第二,一些恶意攻击、爬虫等造成大量空命中。
解决这个问题的方法有两个:
- 1、缓存空对象
存储层不命中后,仍然将空对象保留到缓存层中,之后再访问这个数据将会从缓存中获取,这样就保护了后端数据源。
缓存空对象会有两个问题:第一,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间(如果是攻击,问题更严重),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
缓存空对象的代码示例:
String get(String key) {
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果存储数据为空,需要设置一个过期时间 (300 秒 )
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}
- 2、布隆过滤器拦截

在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截。如果布隆过滤器认为该用户id不存在,那么就不会访问存储层,在一定程度保护了存储层。
这种方法适用于数据命中不高、数据相对固定、实时性低(通常是数据集较大)的应用场景,代码维护较为复杂,但是缓存空间占用少。
布隆过滤器其实就是引入了k(k>1)个相互独立的哈希函数,保证在给定的空间、误判率下,完成元素判重的过程。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
Bloom-Filter算法的核心思想就是利用多个不同的Hash函数来解决“冲突”。
Hash存在一个冲突(碰撞)的问题,用同一个Hash得到的两个URL的值有可能相同。为了减少冲突,我们可以多引入几个Hash,
如果通过其中的一个Hash值我们得出某元素不在集合中,那么该元素肯定不在集合中。只有在所有的Hash函数告诉我们该元素在集合中时,才能确定该元素存在于集合中。这便是Bloom-Filter的基本思想。
Bloom-Filter一般用于在大数据量的集合中判定某元素是否存在。
缓存空对象和布隆过滤器方案对比:
| 解决缓存穿透方式 | 适用场景 | 维护成本 |
|---|---|---|
| 缓存空对象 | 数据命中不高 数据频繁变化实时性高 |
代码维护简单 需要过多的缓存空间 数据不一致 |
| 布隆过滤器 | 数据命中不高 数据相对固定,实时性低 |
代码维护复杂 缓存空间占用少 |
- 3、接口层增加校验
如用户鉴权校验,id做基础校验,id<=0的直接拦截。
1.4 缓存雪崩及优化
当缓存重启或者大量的缓存在某一时间段失效,这样就导致大批流量直接访问数据库,对 DB 造成压力, 从而引起 DB 故障,系统崩溃。
缓存雪崩是指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
缓存失效的几种情况:
- 缓存服务器挂了
- 高峰期缓存局部失效
- 热点缓存失效
解决方案:
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。增加互斥锁,控制数据库请求,重建缓存。- 提高缓存的高可用性,如Redis集群。
给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。
1.5 缓存击穿及优化
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。和缓存雪崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
设置热点数据永远不过期。加互斥锁,互斥锁。
1.6 无底洞优化
由于数据量和访问量的持续增长,造成需要添加大量节点做水平扩容,导致键值分布到更多的节点上,所以无论是Memcache还是Redis的分布式,批量操作通常需要从不同节点上获取,相比于单机批量操作只涉及一次网络操作,分布式批量操作会涉及多次网络时间。
无底洞问题分析:
- 客户端一次批量操作会涉及多次网络操作,也就意味着批量操作会随着节点的增多,耗时会不断增大。
- 网络连接数变多,对节点的性能也有一定影响。
常见的优化思路:
- 命令本身的优化,例如优化SQL语句等。
- 减少网络通信次数。
- 降低接入成本,例如客户端使用长连/连接池、NIO等。
假设命令、客户端连接已经为最优,重点讨论减少网络操作次数。以Redis批量获取n个字符串为例,有三种实现方法:
客户端n次get:n次网络+n次get命令本身。
客户端1次pipeline get:1次网络+n次get命令本身。
客户端1次mget:1次网络+1次mget命令本身。

- 1、串行命令
逐次执行n个get命令,这种操作时间复杂度较高,它的操作时间=n次网络通信时间+n次命令执行时间。
Java代码示例:
List<String> serialMGet(List<String> keys) {
List<String> values = new ArrayList<String>();
for (String key : keys) {
String value = jedisCluster.get(key);
values.add(value);
}
return values;
}
- 2、串行IO
获取每个节点的key子列表,之后对每个节点执行mget或者Pipeline操作,它的操作时间=node次网络时间+n次命令时间,网络次数是node的个数。

这种方案比第一种要好很多,但是如果节点数太多,还是有一定的性能问题。
Java代码示例:
Map<String, String> serialIOMget(List<String> keys) {
// 结果集
Map<String, String> keyValueMap = new HashMap<String, String>();
// 属于各个节点的 key 列表 ,JedisPool 要提供基于 ip 和 port 的 hashcode 方法
Map<JedisPool, List<String>> nodeKeyListMap =
new HashMap<JedisPool, List<String>>();
// 遍历所有的 key
for (String key : keys) {
// 使用 CRC16 本地计算每个 key 的 slot
int slot = JedisClusterCRC16.getSlot(key);
// 通过 jedisCluster 本地 slot->node 映射获取 slot 对应的 node
JedisPool jedisPool =
jedisCluster.getConnectionHandler().getJedisPoolFrom
Slot(slot);
// 归档
if (nodeKeyListMap.containsKey(jedisPool)) {
nodeKeyListMap.get(jedisPool).add(key);
} else {
List<String> list = new ArrayList<String>();
list.add(key);
nodeKeyListMap.put(jedisPool, list);
}
}
// 从每个节点上批量获取,这里使用 mget 也可以使用 pipeline
for (Entry<JedisPool, List<String>> entry : nodeKeyListMap.entrySet()) {
JedisPool jedisPool = entry.getKey();
List<String> nodeKeyList = entry.getValue();
// 列表变为数组
String[] nodeKeyArray =
nodeKeyList.toArray(new String[nodeKeyList.size()]);
// 批量获取,可以使用 mget 或者 Pipeline
List<String> nodeValueList = jedisPool.getResource().mget(nodeKeyArray);
// 归档
for (int i = 0; i < nodeKeyList.size(); i++) {
keyValueMap.put(nodeKeyList.get(i), nodeValueList.get(i));
}
}
return keyValueMap;
}
- 3、并行IO
此方案是将方案2中的最后一步改为多线程执行,它的复杂度是:max_slow(node 网络时间 )+n 次命令时间。

Java代码示例:
Map<String, String> parallelIOMget(List<String> keys) {
// 结果集
Map<String, String> keyValueMap = new HashMap<String, String>();
// 属于各个节点的 key 列表
Map<JedisPool, List<String>> nodeKeyListMap =
new HashMap<JedisPool, List<String>>();
//和前面一样
// 多线程 mget ,最终汇总结果
for (Entry<JedisPool, List<String>> entry : nodeKeyListMap.entrySet()) {
// 多线程实现
}
return keyValueMap;
}
- 4、hash_tag实现
hash_tag功能,它可以将多个key强制分配到一个节点上,它的操作时间=1次网络时间+n次命令时间。将多个key分配到一个节点:

执行key操作图示:

Java代码示例:
List<String> hashTagMget(String[] hashTagKeys) {
return jedisCluster.mget(hashTagKeys);
}
四种批量操作解决方案对比:
| 方案 | 优点 | 缺点 |
|---|---|---|
| 串行命令 | 编程简单 如果键较少,性能可以满足要求 |
键较多时,请求延迟严重 |
| 串行IO | 编程简单 节点少时,性能满足要求 |
节点多时,延迟严重 |
| 并行IO | 利用并行特性,延迟取决于最慢的节点 | 编程复杂 多线程,定位问题可能较难 |
| hash_tag | 性能最高 | 业务维护成本较高 容易出现数据倾斜 |
1.7 热点key重建优化
开发人员使用“缓存+过期时间”的策略既可以加速数据读写,又保证数据的定期更新,这种模式基本能够满足绝大部分需求。但是有两个问题如果同时出现,可能就会对应用造成致命的危害:
- 当前key是一个热点key(例如一个热门的娱乐新闻),并发量非常大。
- 重建缓存不能在短时间完成,可能是一个复杂计算,例如复杂的SQL、多次IO、多个依赖等。
在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大,甚至可能会让应用崩溃。
需要制定如下目标:要解决这个问题,需要制定以下目标:
- 减少重建缓存的次数。
- 数据尽可能一致。
- 较少的潜在危险。
- 1、互斥锁
此方法只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可。
使用Redis的setnx命令实现互斥锁示例:
String get(String key) {
// 从 Redis 中获取数据
String value = redis.get(key);
// 如果 value 为空,则开始重构缓存
if (value == null) {
// 只允许一个线程重构缓存,使用 nx ,并设置过期时间 ex
String mutexKey = "mutext:key:" + key;
if (redis.set(mutexKey, "1", "ex 180", "nx")) {
// 从数据源获取数据
value = db.get(key);
// 回写 Redis ,并设置过期时间
redis.setex(key, timeout, value);
// 删除 key_mutex
redis.delete(mutexKey);
}
// 其他线程休息 50 毫秒后重试
else {
Thread.sleep(50);
get(key);
}
}
return value;
}
- 2、永远不过期
“永远不过期”包含两层意思:
1、从缓存层面来看,确实没有设置过期时间,所以不会出现热点key过期后产生的问题,也就是“物理”不过期。
2、从功能层面来看,为每个value设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去构建缓存。
此方法有效杜绝了热点key产生的问题,但唯一不足的就是重构缓存期间,会出现数据不一致的情况。
Java代码示例:
String get(final String key) {
V v = redis.get(key);
String value = v.getValue();
// 逻辑过期时间
long logicTimeout = v.getLogicTimeout();
// 如果逻辑过期时间小于当前时间,开始后台构建
if (v.logicTimeout <= System.currentTimeMillis()) {
String mutexKey = "mutex:key:" + key;
if (redis.set(mutexKey, "1", "ex 180", "nx")) {
// 重构缓存
threadPool.execute(new Runnable() {
public void run() {
String dbValue = db.get(key);
redis.set(key, (dbvalue,newLogicTimeout));
redis.delete(mutexKey);
}
});
}
}
return value;
}
作为一个并发量较大的应用,在使用缓存时有三个目标:第一,加快用户访问速度,提高用户体验。第二,降低后端负载,减少潜在的风险,保证系统平稳。第三,保证数据“尽可能”及时更新。
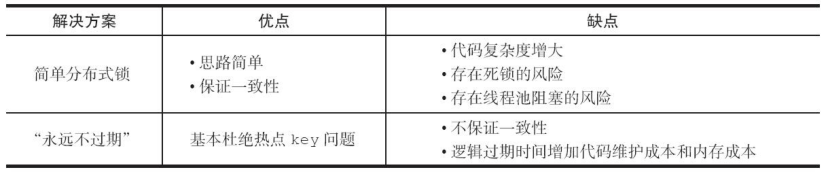
互斥锁:这种方案思路比较简单,但是存在一定的隐患,如果构建缓存过程出现问题或者时间较长,可能会存在死锁和线程池阻塞的风险,但是这种方法能够较好地降低后端存储负载,并在一致性上做得比较好。永远不过期:这种方案由于没有设置真正的过期时间,实际上已经不存在热点key产生的一系列危害,但是会存在数据不一致的情况,同时代码复杂度会增大。
两种热点key的解决方法对比:
1.8 缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。
解决方案
- 直接写个缓存刷新页面,上线时手工操作一下;
- 数据量不大,可以在项目启动的时候自动进行加载;
- 定时刷新缓存;
解决方案:
- 数据量不大的时候,工程启动的时候进行加载缓存动作;
- 数据量大的时候,设置一个定时任务脚本,进行缓存的刷新;
- 数据量太大的时候,优先保证热点数据进行提前加载到缓存。
1.9 缓存降级
降级的情况,就是缓存失效或者缓存服务挂掉的情况下,我们也不去访问数据库。我们直接访问内存部分数据缓存或者直接返回默认数据。
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。
缓存降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓死保护,哪些可降级;比如可以参考日志级别设置预案:
- 1、一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
- 2、警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
- 3、错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;
- 4、严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
服务降级的目的,是为了防止Redis服务故障,导致数据库跟着一起发生雪崩问题。因此,对于不重要的缓存数据,可以采取服务降级策略,例如一个比较常见的做法就是,Redis出现问题,不去数据库查询,而是直接返回默认值给用户。
二、分布式
2.1 Redis实现分布式锁原理
Redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对Redis的连接并不存在竞争关系,因此Redis中可以使用setnx命令实现分布式锁。
setnx(set if not exists)命令的作用:当且仅当 key 不存在,将 key 的值设为 value。;若制定的 key 已经存在,则不做任何操作。
setnx命令的返回值:设置成功,返回 1 。设置失败,返回 0 。
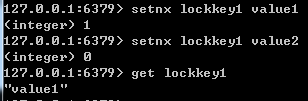
使用setnx完成同步锁的流程及事项如下:
- 使用
setnx命令获取锁,若返回0(key已存在,锁已存在)则获取失败,反之获取成功。- 为了防止获取锁后程序出现异常,导致其他线程/进程调用SETNX命令总是返回0而进入死锁状态,需要为该key设置一个“合理”的过期时间。
- 释放锁,使用
del命令将锁数据删除。
2.2 如何解决 Redis 的并发竞争 Key 问题
并发竞争key这个问题简单讲就是:同时有多个客户端去set一个key。
解决方法常见的有四种:
- 1、乐观锁
乐观锁适用于大家一起抢着改同一个key,对修改顺序没有要求的场景。watch 命令可以方便的实现乐观锁。watch 命令会监视给定的每一个key,当 exec 时如果监视的任一个key自从调用watch后发生过变化,则整个事务会回滚,不执行任何动作。
需要注意的是,如果Redis使用了数据分片的方式,那么这个方法就不再适用。
- 2、分布式锁
适合分布式环境,不用关心Redis是否为分片集群模式。在业务层进行控制,操作Redis之前,先去申请一个分布式锁,拿到锁的才能操作。分布式锁的实现方式很多,比如 ZooKeeper、Redis 等。
如果不存在 Redis的并发竞争 Key 问题,不要使用分布式锁,这样会影响性能。
基于zookeeper临时有序节点可以实现的分布式锁。大致思想为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。完成业务流程后,删除对应的子节点释放锁。在实践中,从以可靠性为主,所以首推Zookeeper。 - 3、时间戳
适合有序需求场景。 - 4、消息队列
在并发量很大的情况下,可以通过消息队列进行串行化处理。这在高并发场景中是一种很常见的解决方案。
总结这几种方案的话,适用场景:
| 实现方式 | 适用场景 |
|---|---|
| 乐观锁 | 不要在分片集群中使用 |
| 分布式锁 | 适合分布式系统环境 |
| 时间戳 | 适合有序场景 |
| 消息队列 | 串行化处理 |
2.3 分布式环境下常见的应用场景
2.3.1 分布式锁
分布式锁可以避免不同进程重复相同的工作,减少资源浪费。 同时分布式锁可以避免破坏数据正确性的发生, 例如多个进程对同一个订单操作,可能导致订单状态错误覆盖。应用场景如下:
- 1、定时任务重复执行
随着业务的发展,业务系统势必发展为集群分布式模式。如果我们需要一个定时任务来进行订单状态的统计。比如每 15 分钟统计一下所有未支付的订单数量。那么我们启动定时任务的时候,肯定不能同一时刻多个业务后台服务都去执行定时任务, 这样就会带来重复计算以及业务逻辑混乱的问题。
这时候,就需要使用分布式锁,进行资源的锁定。那么在执行定时任务的函数中,首先进行分布式锁的获取,如果可以获取的到,那么这台机器就执行正常的业务数据统计逻辑计算。如果获取不到则证明目前已有其他的服务进程执行这个定时任务,就不用自己操作执行了,只需要返回就行了。如下图所示:

- 2、避免用户重复下单
分布式实现方式有很多种:
- 数据库乐观锁方式
- 基于 Redis 的分布式锁
- 基于 ZK 的分布式锁
分布式锁实现要保证几个基本点:
互斥性:任意时刻,只有一个资源能够获取到锁。容灾性:能够在未成功释放锁的的情况下,一定时限内能够恢复锁的正常功能。统一性:加锁和解锁保证同一资源来进行操作。
2.3.2 分布式自增ID
以电商为例,随着用户以及交易量的增加, 可能会针对用户数据,商品数据,以及订单数据进行分库分表的操作。这时候由于进行了分库分表的行为,所以 MySQL 自增 ID 的形式来唯一表示一行数据的方案不可行了。 因此需要一个分布式 ID 生成器,来提供唯一 ID 的信息。
通常对于分布式自增 ID 的实现方式有下面几种:
- 利用数据库自增 ID 的属性
- 通过 UUID 来实现唯一 ID 生成
- Twitter 的 SnowFlake 算法
- 利用 Redis 生成唯一 ID
Redis 是单进程单线程架构,不会因为多个客户端的 INCR 命令导致取号重复。因此,基于 Redis的 INCR 命令实现序列号的生成基本能满足全局唯一与单调递增的特性。
2.4 使用Redis如何设计分布式锁?使用ZK可以吗?这两种有什么区别?
- 1、Redis
- 线程A setnx(上锁的对象,超时时的时间戳 t1),如果返回 true,获得锁。
- 线程 B 用 get 获取 t1,与当前时间戳比较,判断是是否超时,没超时 false,若超时执行第 3步;
- 计算新的超时时间 t2,使用 getset 命令返回 t3(该值可能其他线程已经修改过),如果t1==t3,获得锁,如果 t1!=t3 说明锁被其他线程获取了。
- 获取锁后,处理完业务逻辑,再去判断锁是否超时,如果没超时删除锁,如果已超时,不用处理(防止删除其他线程的锁)。
- 2、ZK
- 客户端对某个方法加锁时,在 zk 上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点 node1;
- 客户端获取该路径下所有已经创建的子节点,如果发现自己创建的 node1 的序号是最小的,就认为这个客户端获得了锁。
- 如果发现 node1 不是最小的,则监听比自己创建节点序号小的最大的节点,进入等待。
- 获取锁后,处理完逻辑,删除自己创建的 node1 即可。
区别:ZK性能差一些,开销大,实现简单。
三、一些问题
3.1 Redis常见性能问题和解决方案?
- 1、Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化。
- 2、如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
- 3、为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内。
- 4、尽量避免在压力较大的主库上增加从库
- 5、为了Master的稳定性,主从复制不要用图状结构,用单向链表结构更稳定,即主从关系为:Master<–Slave1<–Slave2<–Slave3…,这样的结构也方便解决单点故障问题,实现Slave对Master的替换,也即,如果Master挂了,可以立马启用Slave1做Master,其他不变。
3.2 Redis如何做大量数据插入?
Redis2.6开始,redis-cli支持一种新的被称之为pipe mode的新模式用于执行大量数据插入工作。
使用pipe mode模式的执行命令如下:
cat data.txt | redis-cli --pipe
pipe mode的工作原理:
- redis-cli –pipe试着尽可能快的发送数据到服务器
- 读取数据的同时,解析它
- 一旦没有更多的数据输入,它就会发送一个特殊的echo命令,后面跟着20个随机的字符。我们相信可以通过匹配回复相同的20个字符是同一个命令的行为
- 一旦这个特殊命令发出,收到的答复就开始匹配这20个字符,当匹配时,就可以成功退出了
四、分布式锁的具体实现
分布式锁一般有三种实现方式:1、数据库乐观锁;2、基于Redis的分布式锁;3、基于ZooKeeper的分布式锁。接下来介绍第二种的具体实现。
使用分布式锁的四个条件:
互斥性。在任意时刻,只有一个客户端能持有锁。不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。容错性。只要大部分的Redis节点正常运行,客户端就可以加锁和解锁。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
4.1 Jedis实现分布式锁
要使用Jedis,可以引入Maven依赖:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
- 1、加锁
示例:
public class RedisTool {
private static final String LOCK_SUCCESS = "OK";
private static final String SET_IF_NOT_EXIST = "NX";
private static final String SET_WITH_EXPIRE_TIME = "PX";
/**
* 尝试获取分布式锁
* @param jedis Redis客户端
* @param lockKey 锁
* @param requestId 请求标识
* @param expireTime 超期时间
* @return 是否获取成功
*/
public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) {
String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime);
if (LOCK_SUCCESS.equals(result)) {
return true;
}
return false;
}
}
加锁的代码:
jedis.set(String key, String value, String nxxx, String expx, int time)
- 1、key:使用key来当锁,因为key是唯一的。
- 2、为value:不同的请求可以传不同的value,这样就可以用value来标识不同的请求。value可以用UUID.randomUUID().toString()方法生成。
- 3、nxxx:这个参数可以有两个值:
nx :SET IF NOT EXIST, 只有key 不存在时,才把key value set 到redis。若key已经存在,则不做任何操作。
xx : is exists ,只有 key 存在时,才把key value set 到redis。
- 4、expx:这个参数也可以有两个值:
ex : seconds 秒。
px : milliseconds 毫秒
- 5、time:代表key的过期时间。
总的来说,执行上面的set()方法就只会导致两种结果:1. 当前没有锁(key不存在),那么就进行加锁操作,并对锁设置个有效期,同时value表示加锁的客户端。2. 已有锁存在,不做任何操作。
- 2、解锁
示例:
public class RedisTool {
private static final Long RELEASE_SUCCESS = 1L;
/**
* 释放分布式锁
* @param jedis Redis客户端
* @param lockKey 锁
* @param requestId 请求标识
* @return 是否释放成功
*/
public static boolean releaseDistributedLock(Jedis jedis, String lockKey, String requestId) {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
Object result = jedis.eval(script, Collections.singletonList(lockKey),
Collections.singletonList(requestId));
if (RELEASE_SUCCESS.equals(result)) {
return true;
}
return false;
}
}
上面的代码:将Lua代码传到jedis.eval()方法里,并使参数KEYS[1]赋值为lockKey,ARGV[1]赋值为requestId。eval()方法是将Lua代码交给Redis服务端执行。
这段Lua代码的功能:首先获取锁对应的value值,检查是否与requestId相等,如果相等则删除锁(解锁)。那么为什么要使用Lua语言来实现呢?因为要确保上述操作是原子性的。
简单来说,就是在eval命令执行Lua代码的时候,Lua代码将被当成一个命令去执行,并且直到eval命令执行完成,Redis才会执行其他命令。
- 3、测试代码
示例:
public class RedisDistributedLockCase {
public static void main(String[] args) {
Thread1 thread1 = new Thread1();
Thread2 thread2 = new Thread2();
thread1.start();
thread2.start();
}
public static void lockTest(final Jedis jedis,final String key,final String threadName) {
if (RedisTool.tryGetDistributedLock(jedis,key,threadName,5)) {
System.out.println(threadName + "已获得锁");
String result = jedis.set("lock",threadName);
System.out.println(threadName +"共享资源执行结果: "+result);
// try {
// Thread.currentThread().sleep(5);//模拟持有锁的线程崩溃,考察锁失效时间有效性
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
boolean b = RedisTool.releaseDistributedLock(jedis,key,threadName);
System.out.println(threadName +"解锁情况:"+b);
}else {
System.out.println(threadName + "获取锁失败...");
//失败了递归执行,直到成功为止
lockTest(jedis,key,threadName);
}
}
}
class Thread1 extends Thread{
@SuppressWarnings("static-access")
@Override
public void run() {
String KEY = "SYNC_LOCK";
Jedis jedis = new Jedis("localhost");
new RedisDistributedLockCase().lockTest(jedis,KEY,"Thread1");
jedis.close();
}
}
class Thread2 extends Thread{
@SuppressWarnings("static-access")
@Override
public void run() {
String KEY = "SYNC_LOCK";
Jedis jedis = new Jedis("localhost");
new RedisDistributedLockCase().lockTest(jedis,KEY,"Thread2");
jedis.close();
}
}
正常情况下的结果:
Thread2已获得锁
Thread1获取锁失败…
Thread2共享资源执行结果: OK
Thread1获取锁失败…
Thread1获取锁失败…
Thread2解锁情况:true
Thread1已获得锁
Thread1共享资源执行结果: OK
Thread1解锁情况:true
使用线程休眠阻塞的形式模拟其中一个线程解锁失败的情况下的结果:
Thread1已获得锁
Thread2获取锁失败…
Thread1共享资源执行结果: OK
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2获取锁失败…
Thread2已获得锁
Thread2共享资源执行结果: OK
Thread1解锁情况:false
Thread2解锁情况:true
4.2 RedisTemplate实现分布式锁
相比于Jedis,RedisTemplate更常用,用RedisTemplate实现分布式锁的方式示例:
/**
* 加锁
* @param key
* @param value
* @param timeout 过期时间
*/
public static boolean lock(String key, String value, Integer timeout){
stringRedisTemplate.opsForValue().setIfAbsent(key, value,timeout, TimeUnit.SECONDS);
}
/**
* 释放锁
*/
public static void releaseLock(String key){
redisTemplate.delete(key);
}