本章内容包含python模拟登录中国海洋大学教务系统(青果)- 百度智能云识别验证码 - 进入选课页面。
系列文章目录
第一章 python模拟登录中国海洋大学教务系统(青果)
第二章 爬取学期所有专业课至excel
第三章 课表排课
前言
提示:本人是个菜鸟,没系统学过python、html等,对以下所有知识点只会应用,不懂原理,大家可以去看看这两位大佬的技术文章。
python爬虫模拟登录学校教务系统(青果教务系统)并查询个人成绩——王森ouc
python-scrapy模拟登陆网站–登陆青果教务管理系统(一)——耿子666
本文是借鉴了以上两位大佬的文章,能够跑出结果,但我不是很懂原理,会在网上整理总结,仅供参考。
一、模拟登录
这个前两个大佬都做的很优秀了,我一开始只会f12,查看一下要提交的表单,然后发现提交表单的key(不知道专业术语是啥)会变,我就歇菜了。
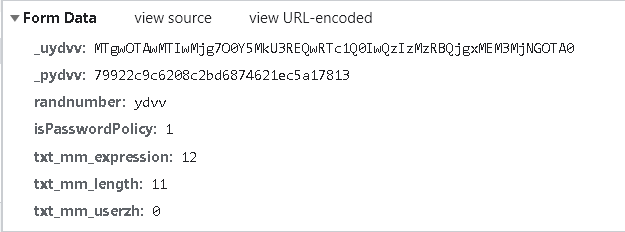
就下面这个⬇ , _uydvv,_pydvv,它们是由_u,_p和你输入的验证码拼接而成的
之后查资料的时候,发现竟然有大佬已经写了我想写的前半部分内容,整挺好,然后踩在大佬的肩膀上,修修改改也写了一天,才基本实现了所有内容。
现在我就带着大家再挨个走一遍所有的路程,出发!
1.分析提交表单
(海大的教务系统需要连校园网或VPN)
1.使用Google Chrome打开教务网站http://jwgl.ouc.edu.cn/cas/login.action
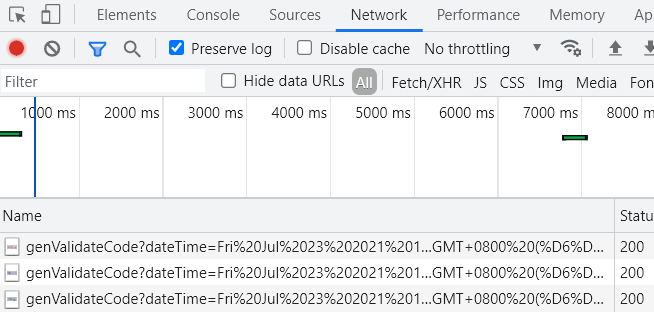
2.按F12 - 进入开发者工具
点击Network - 网络
chrome开发者工具最常用的四个功能模块:元素(ELements)、控制台(Console)、源代码(Sources),网络(Network)。
勾选Preserve log - 保留请求日志
谷歌开发者工具里面这个preserve log :保留请求日志,跳转页面的时候勾选上,可以看到跳转前的请求,也可适用于chrome开发者工具抓包的问。
3.随便输入一些账户密码验证码
可以看到点击验证码框或验证码的时候,会有名为genValidateCode?..的请求来获取新的验证码图片。
点击该请求(查看请求的详细内容)- 点击preview(预览)-可以看到验证码图片
再点击Headers
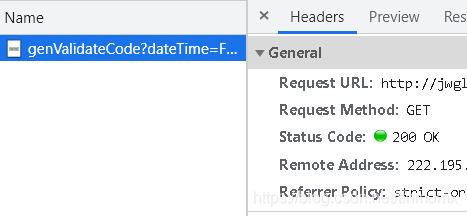
Request Method是Get
Request URL: http://jwgl.ouc.edu.cn/cas/genValidateCode?dateTime=Fri%20Jul%2023%202021%2010:35:41%20GMT+0800%20(%D6%D0%B9%FA%B1%EA%D7%BC%CA%B1%BC%E4)
复制该url进行打开,可以看到并不是原来的验证码图片,每次刷新后验证码都不一样
经过验证,该验证码与dateTime并没有关系,目前我还不知道原理,请大佬指教
通过该url可以获得验证码,暂且不管该验证码是否是我们需要的正确的验证码
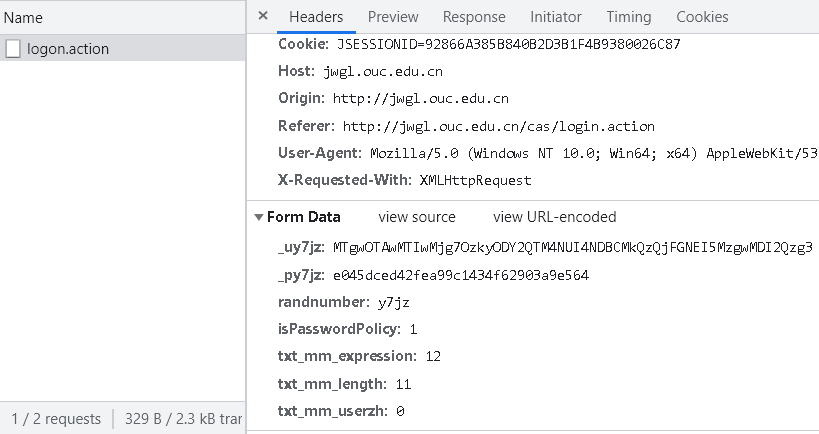
4.点击提交,出现名为logon.action的请求,点击观察其Headers内容
在写请求的时候,一般形式应该是(url,表单数据,请求头):
response = request.post(url, data, headers)
这些在Headers内容里都能找到,然后就是用代码构造这些内容:
import requests
url = 'http://jwgl.ouc.edu.cn/cas/logon.action'
#表单信息不能直接复制,这里就演示一下,并不是实际实现的
data = {
'_u'+randnumber: 'MTgwOTAwMTIwMjg7OzkyODY2QTM4NUI4NDBCMkQzQjFGNEI5MzgwMDI2Qzg3',
'_p'+randnumber: 'e045dced42fea99c1434f62903a9e564',
'randnumber': 'y7jz',
'isPasswordPolicy': '1',
'txt_mm_expression': '12',
'txt_mm_length': '11',
'txt_mm_userzh': '0',
}
#headers里的内容并没有完全复制,我也不清楚哪些是必须的,哪些是非必须的,建议全部粘贴,以下是拷贝大佬的,我就不做修改了
headers = {
'Host': 'jwgl.ouc.edu.cn',
'Origin': 'http://jwgl.ouc.edu.cn',
'Referer': 'http://jwgl.ouc.edu.cn/cas/login.action',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Upgrade-Insecure-Requests': '1',
}
#这里用session,而不是request
r = session.post(url, data=data, headers=headers)
request对象的生命周期是针对一个客户端(说确切点就是一个浏览器应用程序)的一次请求,当请求完毕之后,request里边的内容也将被释放掉 。
而session的生命周期也是针对一个客户端,但是却是在别人设置的会话周期内(一般是20-30分钟),session里边的内容将一直存在,即便关闭了这个客户端浏览器 session也不一定会马上释放掉的。
——参考request和session的区别
在这里因为在登录后,还要跳转到选课页面,需要保存登录信息,所以用session
另外好像可以#创建cookie,利用cookie实现持久化登录,感兴趣的可以瞅瞅
会话(Session)跟踪是Web程序中常用的技术,用来跟踪用户的整个会话。常用的会话跟踪技术是Cookie与Session。Cookie通过在客户端记录信息确定用户身份,Session通过在服务器端记录信息确定用户身份。
——参考Cookie和Session详解
表单信息不能直接复制,需要先观察一下
_uy7jz: MTgwOTAwMTIwMjg7OzkyODY2QTM4NUI4NDBCMkQzQjFGNEI5MzgwMDI2Qzg3
_py7jz: e045dced42fea99c1434f62903a9e564
randnumber: y7jz #验证码
isPasswordPolicy: 1#密码合法
txt_mm_expression: 12#密码规则
txt_mm_length: 11#输入的密码长度
txt_mm_userzh: 0
观察得到:
1.前两项的key是_u,_p+输入的验证码,value是加密过的,看不出内容
2.根据变量名猜测其含义,见注释
3.账户密码没有直接显示出来
所以要去源代码里找相关信息:
1.定位账号密码代码的位置
2.在控制台里按CTRL+shift+F打开全局搜索,搜索yhmm
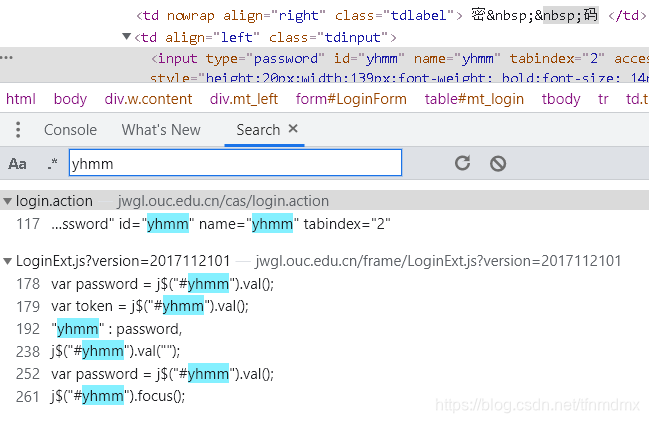
3.点击第二个
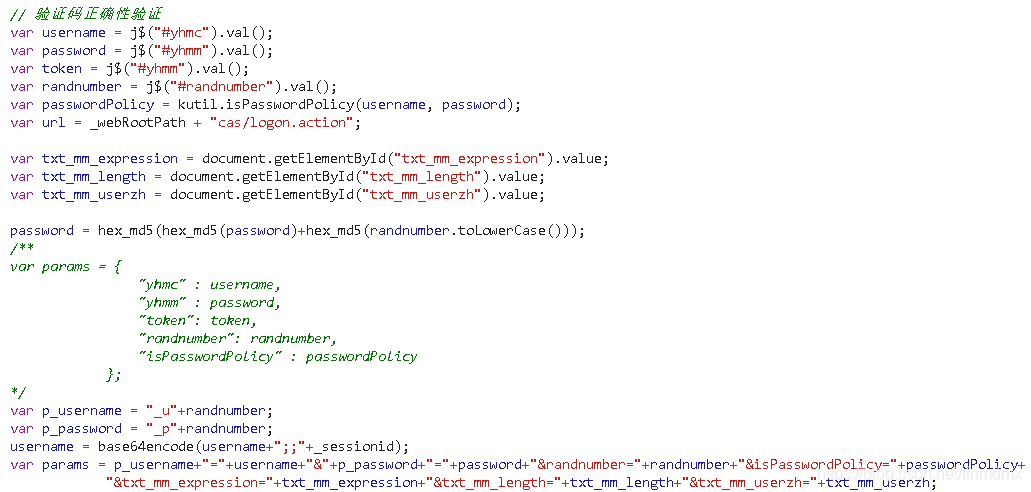
4.观察代码:前几行都是获取输入,后几行就是对这些信息的加密,我们需要在代码里对信息进行同样的加密
password = hex_md5(hex_md5(password)+hex_md5(randnumber.toLowerCase()));
var p_username = "_u"+randnumber;
var p_password = "_p"+randnumber;
username = base64encode(username+";;"+_sessionid);
var params = p_username+"="+username+"&"+p_password+"="+password+"&randnumber="+randnumber+"&isPasswordPolicy="+passwordPolicy+
"&txt_mm_expression="+txt_mm_expression+"&txt_mm_length="+txt_mm_length+"&txt_mm_userzh="+txt_mm_userzh;
加密语句⬆⬇对应
#具体加密原理见王森ouc大佬的文章
password = md5(password.encode('utf-8')).hexdigest()
randnumber = md5(randnumber.lower().encode('utf-8')).hexdigest()
password = md5((password + randnumber).encode('utf-8')).hexdigest()
#randnumber会在之前通过百度智能云文字识别获得
data['randnumber'] = randnumber
p_username = '_u' + randnumber
p_password = '_p' + randnumber
data[p_username] = username
data[p_password] = password
#sessionid是会话的id,一般是存放在cookie中
_sessionid = session.cookies.get_dict()['JSESSIONID']
username = base64.b64encode(username.encode('utf-8') + b';;' + str(_sessionid).encode('utf-8'))
#params不知道是干啥的,这里没用
⬆⬆⬆以上,账号、密码、验证码、url、data、headers都已分析过
2.百度智能云识别验证码
没有用过百度智能云的可以看看:百度智能云-文字识别SDK-识别验证码Demo
import requests
from aip import AipOcr
from bs4 import BeautifulSoup
headers = {
'Host': 'jwgl.ouc.edu.cn',
'Origin': 'http://jwgl.ouc.edu.cn',
'Referer': 'http://jwgl.ouc.edu.cn/cas/login.action',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Upgrade-Insecure-Requests': '1',
}
#百度智能云-文字识别
def randnumber_ocr(image):
APP_ID = '' # 在百度官网的应用列表中查看APP_ID
API_KEY = '' # 在百度官网的应用列表中查看API_KEY
SECRET_KEY = '' # 在百度官网的应用列表中查看SECRET_KEY
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
text = client.basicAccurate(image)
if text['words_result_num'] == 1:
return text['words_result'][0]['words'].strip()
else:
return ''
def logon():
url = 'http://jwgl.ouc.edu.cn/cas/logon.action'
session = requests.Session()
#百度智能云-文字识别-获取验证码
randnumber = ''
while len(randnumber) != 4:
r = session.get('http://jwgl.ouc.edu.cn/cas/genValidateCode', headers=headers)
randnumber = randnumber_ocr(r.content).replace(' ','')#去除空格
if __name__ == '__main__':
logon()
3.代码
import requests
from aip import AipOcr
import base64
from hashlib import md5
import json
import re
from bs4 import BeautifulSoup
headers = {
'Host': 'jwgl.ouc.edu.cn',
'Origin': 'http://jwgl.ouc.edu.cn',
'Referer': 'http://jwgl.ouc.edu.cn/cas/login.action',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Upgrade-Insecure-Requests': '1',
}
#data和headers一样,并没有传全部的项
data = {
'randnumber': 'gqzd'
}
#百度智能云-文字识别
def randnumber_ocr(image):
APP_ID = '' # 在百度官网的应用列表中查看APP_ID
API_KEY = '' # 在百度官网的应用列表中查看API_KEY
SECRET_KEY = '' # 在百度官网的应用列表中查看SECRET_KEY
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
text = client.basicAccurate(image)
if text['words_result_num'] == 1:
return text['words_result'][0]['words'].strip()
else:
return ''
def logon():
url = 'http://jwgl.ouc.edu.cn/cas/logon.action'
username = '' # 输入你的用户名,也就是学号
password = '' # 输入你的密码
session = requests.Session()
#百度智能云-文字识别-获取验证码
randnumber = ''
while len(randnumber) != 4:
r = session.get('http://jwgl.ouc.edu.cn/cas/genValidateCode', headers=headers)
randnumber = randnumber_ocr(r.content).replace(' ','')#去除空格
#构造data-信息加密
password = md5(password.encode('utf-8')).hexdigest()
randnumber = md5(randnumber.lower().encode('utf-8')).hexdigest()
password = md5((password + randnumber).encode('utf-8')).hexdigest()
#randnumber会在之前通过百度智能云文字识别获得
data['randnumber'] = randnumber
p_username = '_u' + randnumber
p_password = '_p' + randnumber
data[p_username] = username
data[p_password] = password
#sessionid是会话的id,一般是存放在cookie中
_sessionid = session.cookies.get_dict()['JSESSIONID']
username = base64.b64encode(username.encode('utf-8') + b';;' + str(_sessionid).encode('utf-8'))
#post
r = session.post(url, data=data, headers=headers)
#response
info = json.loads(r.text)
status = info['status']
if status == '401':
print('验证码错误')
return
elif status == '200':
pass
else:
print(info['message'])
return
print('登录成功')
if __name__ == '__main__':
logon()
二、进入选课页面
登录成功后,就要进入选课页面,此部分与一内容基本相同且更简单,可以自己尝试分析一下
1.选择选课学年学期-年级-专业——点击检索
2.
出现新请求,一般我们需要的都是document类型的,点击查看其详细信息

3.
Request URL: http://jwgl.ouc.edu.cn/taglib/DataTable.jsp?tableId=6146
Request Method: POST
Referer: http://jwgl.ouc.edu.cn/student/wsxk.kcbcx.html?menucode=JW130414
FormData
initQry: 0
xktype: 2 #选课类型
xh: 1*********8 #你的学号
xn: 2021 #学年
xq: 1 #学期-夏0-秋1-春2
nj: 20** #你的年级
zydm: 0**0 #你的专业代码
items:
xnxq: 2021-1 #学年-学期
kcfw: Specialty #课程范围
sel_nj: 2019 #选择的年级2018-2020
sel_zydm: 0011 #选择的专业代码
sel_schoolarea:
sel_cddwdm:
sel_kc:
kcmc:
经过观察,表单信息都很简单,构造data,headers需要有Referer
Referer 是 HTTP 请求header 的一部分,当浏览器(或者模拟浏览器行为)向web 服务器发送请求的时候,头信息里有包含 Referer 。它就是表示该请求的来源。
——参考什么是HTTP Referer?
def get_score(session, sel_nj):
url = 'http://jwgl.ouc.edu.cn/taglib/DataTable.jsp?tableId=6146'
#这个data包含了所有项,但有些其实的非必须的
formdata={
'initQry': '0',
'xktype': '2',#选课类型
'xh': '1**********',#修改为你的学号
'xn': '2021',#学年
'xq': '1',#学期-夏0-秋1-春2
'nj': '20**',#修改为你的年级
'zydm': '0**0',#修改为你的专业代码
'items': '',
'xnxq': '2021-1',#学年-学期
'kcfw': 'Specialty',#课程范围
'sel_nj': sel_nj,#修改为你想选择的年级2018-2020
'sel_zydm': '0011',#修改为你想选择的专业代码
'sel_schoolarea': '',
'sel_cddwdm': '',
'sel_kc': '',
'kcmc': ''
}
#这个headers必须包含Referer
headers['Referer'] = 'http://jwgl.ouc.edu.cn/student/wsxk.kcbcx.html?menucode=JW130414'
#使用session
r = session.post(url,data=formdata, headers=headers)
#解析一下网页,打印一下表格内容看看
soup = BeautifulSoup(r.text, 'html.parser')
table_node = soup.find_all('td')
for table in table_node:
print (table.text)
session.close()
三、完整代码及代码效果
import requests
from aip import AipOcr
import base64
from hashlib import md5
import json
import re
from bs4 import BeautifulSoup
headers = {
'Host': 'jwgl.ouc.edu.cn',
'Origin': 'http://jwgl.ouc.edu.cn',
'Referer': 'http://jwgl.ouc.edu.cn/cas/login.action',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Upgrade-Insecure-Requests': '1',
}
#data和headers一样,并没有传全部的项
data = {
'randnumber': 'gqzd'
}
#百度智能云-文字识别
def randnumber_ocr(image):
APP_ID = '' # 在百度官网的应用列表中查看APP_ID
API_KEY = '' # 在百度官网的应用列表中查看API_KEY
SECRET_KEY = '' # 在百度官网的应用列表中查看SECRET_KEY
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
text = client.basicAccurate(image)
if text['words_result_num'] == 1:
return text['words_result'][0]['words'].strip()
else:
return ''
def get_score(session):
url = 'http://jwgl.ouc.edu.cn/taglib/DataTable.jsp?tableId=6146'
#这个data包含了所有项,但有些其实的非必须的
formdata={
'initQry': '0',
'xktype': '2',#选课类型
'xh': '1**********',#修改为你的学号
'xn': '2021',#学年
'xq': '1',#学期-夏0-秋1-春2
'nj': '20**',#修改为你的年级
'zydm': '0**0',#修改为你的专业代码
'items': '',
'xnxq': '2021-1',#学年-学期
'kcfw': 'Specialty',#课程范围
'sel_nj': '2019',#修改为你想选择的年级2018-2020
'sel_zydm': '0011',#修改为你想选择的专业代码
'sel_schoolarea': '',
'sel_cddwdm': '',
'sel_kc': '',
'kcmc': ''
}
#这个headers必须包含Referer
headers['Referer'] = 'http://jwgl.ouc.edu.cn/student/wsxk.kcbcx.html?menucode=JW130414'
#使用session
r = session.post(url,data=formdata, headers=headers)
#解析一下网页,打印一下表格内容看看
soup = BeautifulSoup(r.text, 'html.parser')
table_node = soup.find_all('td')
for table in table_node:
#if table.style != 'none':#有隐藏的列表格,没必要输出
print (table.text)
session.close()
def logon():
url = 'http://jwgl.ouc.edu.cn/cas/logon.action'
username = '' # 输入你的用户名,也就是学号
password = '' # 输入你的密码
session = requests.Session()
#百度智能云-文字识别-获取验证码
randnumber = ''
while len(randnumber) != 4:
r = session.get('http://jwgl.ouc.edu.cn/cas/genValidateCode', headers=headers)
randnumber = randnumber_ocr(r.content).replace(' ','')#去除空格
#randnumber会在之前通过百度智能云文字识别获得
data['randnumber'] = randnumber
p_username = '_u' + randnumber
p_password = '_p' + randnumber
#构造data-信息加密
password = md5(password.encode('utf-8')).hexdigest()
randnumber = md5(randnumber.lower().encode('utf-8')).hexdigest()
password = md5((password + randnumber).encode('utf-8')).hexdigest()
#sessionid是会话的id,一般是存放在cookie中
_sessionid = session.cookies.get_dict()['JSESSIONID']
username = base64.b64encode(username.encode('utf-8') + b';;' + str(_sessionid).encode('utf-8'))
#构造data
data[p_username] = username
data[p_password] = password
#post
r = session.post(url, data=data, headers=headers)
#response
info = json.loads(r.text)
status = info['status']
if status == '401':
print('验证码错误')
return
elif status == '200':
pass
else:
print(info['message'])
return
print('登录成功')
get_score(session)
if __name__ == '__main__':
logon()
运行效果:

四、遇到的问题
KeyError: 'words_result_num'
没有填写APP_ID、API_KEY 、SECRET_KEY
print(tds[1].string + ": " + tds[16].string)
TypeError: can only concatenate str (not "NoneType") to str
爬取错误,tds里没有内容
if table.attrs['style'] != "display:none;":
KeyError: 'style'
TypeError: 'NoneType' object is not subscriptable
table = soup.find('td')
print (table)#<td id="head_curent_skbjdm" width="6%">选课号</td>
print (table['id'])#head_curent_skbjdm
print (table['style'])#KeyError: 'style'
print (table.id)#None
print (table.style)#None
#print (table.style['display'])#TypeError: 'NoneType' object is not subscriptable
#print (table.attrs['style'])#KeyError: 'style'
<td id=“tr2_cddw” name=“cddw” style=“display:none;”>计算机科学与技术系</td>
这样一个table,其style=“display:none;”,说明其是隐藏的,没有必要爬取,但是有的table有style,有的没有
所以要怎么添加判断呢 TT 感谢指教
总结
知识点十分多啊,整理了两天,收获也很多 \OoO/
码字不易,感谢点赞评论收藏关注~