目录
1.1 Inverted Index and Boolean retrieval model
Avoid linearly scanning: index the documents in advance
Vectorization with TF-IDF weighting
Better scoring functions: BM25
1.1 Inverted Index and Boolean retrieval model
Linearly scanning
例子:Which plays of Shakespeare contain the words Brutus AND Caesar but NOT Calpurnia?
Naïve method:grepping through text, a linear search over all the documents.

缺点:
-
搜索速度很慢
-
对匹配的对象缺乏可扩展性
Avoid linearly scanning: index the documents in advance
即 正排索引。建立一个词表,对莎士比亚的剧目与对应的人名(文档到词语)建立映射关系,方便快速检索。

Brutus AND Caesar but NOT Calpurnia ——》 110100 AND 110111 AND 101111(对应取反) = 100100,即第一篇文档和第四篇文档是满足需求的。
缺点:正排索引的矩阵过大、过稀疏。
Construct Inverted Index
即建立 倒排索引,从词出发,将相关的文档连接起来。 
举个例子:
下面有两个文档 Doc1 和 Doc2。首先分别对他们进行分词、词频统计,做出左边两个表格,接着对这两个表进行整合,可得到右边的表格。

通常我们输入一两个关键词,搜索引擎返回相关的网页。倒排索引更合适搜索引擎的使用场景。但这里有个问题,针对不同词语后面的 文档的排序 是按照什么方式组织的呢?

这里仅仅是按照ID从大到小进行排列,但在搜索引擎中,文档需要按照重要性、发布时间等相关因子综合考量进行排序的。因此这种简单的倒排索引表还需要进一步改进,建立一种 带权重的匹配算法。
1.2 Rank Retrieval
之前我们建立的索引表都是Boolean类型的索引表,非0即1,无法体现出不同单词的权重,但我们希望添加词语的权重,这里便引出了 TF-IDF 算法。
Vectorization with TF-IDF weighting
Word count information within the document:
-
More frequent words be more important.
-
But not endlessly important: appearing 10 times does not mean 10 times more important than appearing 1 time.
TF:term frequency 词频, TF = (某个词在文章中出现的个数) /(文章的总词数)。
IDF:inverse document frequency 逆文档频率,IDF= log (语料库文档总词数 /(包含该词的文档数+1)),包含某词语的文档越少,IDF值越大,说明该 词语具有很强的区分能力。
TF-IDF 同时衡量了词频以及逆文本频率。

可以看出,这里的索引表不是非零即一的布尔型索引表。这里我们就可以把 query 转化成向量形式,把文档也转化为向量形式,通过计算向量之间的余弦相似度来判断词语与文档之间的关系,进一步可以对文档进行排序。
Better scoring functions: BM25
BM: best matching,计算query与文档相似度得分的经典算法。
进一步考虑在输入的 query 中每个词的重要性是不同的,因此 BM 算法需要考虑:
-
query 中每个单词 t 与文档 d 之间的相关性。
-
单词 t 与 query 之间的相似性
-
每个单词的权重

事实上,BM25 确实比 TF-IDF 效果更好。
1.3 PageRank
---Ranking documents using linking information
PageRank,又称网页排名、谷歌左侧排名,是一种由搜索引擎根据网页之间相互的超链接计算的技术,而作为网页排名的要素之一,以Google公司创办人拉里·佩奇(Larry Page)之姓来命名。Google 用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。
其基本假设是:更重要的页面往往更多地被其他页面引用(或称其他页面中会更多地加入通向该页面的超链接)
假设一个由4个网页组成的群体:A,B,C 和 D。如果所有页面都只链接至 A,那么 A 的 PR(PageRank)值将是B,C 及 D 的 Pagerank 总和。
![]()
重新假设 B 链接到 A 和 C,C 只链接到 A,并且 D 链接到全部其他的3个页面。一个页面总共只有一票。所以 B 给A 和 C 每个页面半票。以同样的逻辑,D 投出的票只有三分之一算到了 A 的 PageRank 上。
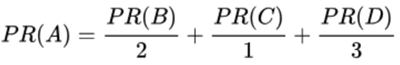
-
PR(A) 是页面A的PR值;
-
PR(Ti)是页面Ti的PR值,在这里,页面Ti是指向A的所有页面中的某个页面;
-
C(Ti)是页面Ti的出度,也就是Ti指向其他页面的边的个数;
-
d 为阻尼系数,其意义是,在任意时刻,用户到达某页面后并继续向后浏览的概率,该数值是根据上网者使用浏览器书签的平均频率估算而得,通常d=0.85
![]()

通过多次迭代计算,直至收敛。

即可算出页面的PR值。