一、数据库事务隔离级别
1、事务原则
事务需要满足ACID原则:
- 原子性A
- 一致性C
- 隔离性I
- 持久性D
本文的数据库隔离界别概念就是在讨论隔离性(Isolation),如果保证不同事务在操作数据库的时候能产生良好的隔离性,继而更好的符合对应的原则。
2、4种隔离级别
隔离性就是保证事务在不受外部并发操作的影响,始得每一个事务的运行环境都是独立的。
举一个很简单的例子,事务A首先查询user表数据,然后事务B向user表插入一条数据,事务A再去查询user表,如果查询到了B事务添加的数据,那么我们就可以认为这两个事务没有相互隔离。
这种事务之间的相互影响就分别对应数据库中的4种隔离级别:
- 读未提交:事务B还没有提交的事务都会影响到事务A的数据;
- 读已提交:只要事务B一提交数据,就会影响到事务A的数据;
- 可重复读:在数据展示的时候没有表现出来,其实还是默默的影响了;
- 串行化:串成一串,依次排队进行,事务之间不会影响。
3、会出现的3种问题
针对上面四种隔离级别会3种不同的问题,它们有一个专用的名词:
- 脏读:肮脏的数据,脏数据,太脏了,显然是不符合要求的数据;
- 不可重复读:重复读,多次读,我们反复读取同一个表的数据,数据会动态变化,前后数据不一致;
- 幻读:虚幻,虚假的读取对应的数据,我们读到了,但是读取到的数据貌似没有那么真实
行:会出现的问题
列:不同的隔离界别
| 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|
| 读未提交 | 可能 | 可能 | 可能 |
| 读已提交 | 不可能 | 可能 | 可能 |
| 可重复读 | 不可能 | 不可能 | 可能 |
| 串行化 | 不可能 | 不可能 | 不可能 |
这个表格已经是老生常谈了,我这里只进行一个简单的说明。
1、读已提交 + 不可重复读 = 可能
当数据库隔离界别设置为读已提交,事务A只能读取到事务B提交以后的数据,显然提交以后的数据都是我们需要的数据,即数据不脏,都是干净的、正确的数据。但是当事务A首先对表user进行一次查询操作,紧接着事务B对user表数据进行了修改,然后立马提交了数据,次数事务A再去查询user表数据,此时查询到的数据发生了变化,但就隔离性而言,我们认为这是一个问题,即产生了不可重复读的问题。
2、可重复读 + 不可重读读 = 不可能
可重复读 + 幻读 = 可能
当数据库隔离级别设置为可重读时,还是上面同样的例子。事务A首先发起一次查询,然后事务B修改了数据,再提交数据,此时事务A再去查询对应的数据,我们会发现事务A的读取的数据没有变化,还和之前一样。尽管这个数据和数据库数据不一致,但是在隔离界别的角度而言,该隔离界别是解决了上面的不可重复读的问题。
现在案例变了,事务A还是首先去查询user表,然后B事务在user表中插入了一条数据,然后提交数据,最后事务B再去查询user表的数据,按照刚才的说法,查询出来的数据还和第一次查询的时候一样。但是当我们最后再添加一条update语句,就根据id去修改事务B刚才添加的那一条数据。理论上说,按照刚才查询出来的结果集,我们应该是修改不成功的,但是我们真正在执行update语句的时候,会执行成功,可是查询出来的结果集不是没有这一条数据吗?(数据库肯定是有这条数据)站在数据库隔离级别的角度看,此时就是产生了幻读问题,修改了我们看起来不存在的数据,居然还修改成功了。
这里就使用了MySQL的MVCC(Multi-Version Concurrency Control)机制,后文会继续讲解。
3、串行化 + 幻读 = 不可能
当数据的隔离界别设置为串行化时,事务A在操作的时候,事务B是不能执行的,只能等事务A结束以后才能再执行。有点类似于Java中的悲观锁,只要你进行了操作,我就给你加锁,等你操作结束再释放锁。那这样就必不可能发生并发问题,但是效率十分低下。
二、MVCC概念
MySQL的InnoDB存储引擎,在读已提交和可重复读隔离级别下都实现了MVCC(Multi-Version Concurrency Control)机制。
1、基本结构
undo日志版本链是指一行数据被多个事务依次修改过后的记录。
在每个事务修改完后,MySQL的InnoDB存储引擎会保留修改前的数据到undo回滚日志,并且用两个隐藏字段事务id和回滚指针把这些undo日志串联起来,形成一个历史记录版本链,如下图。
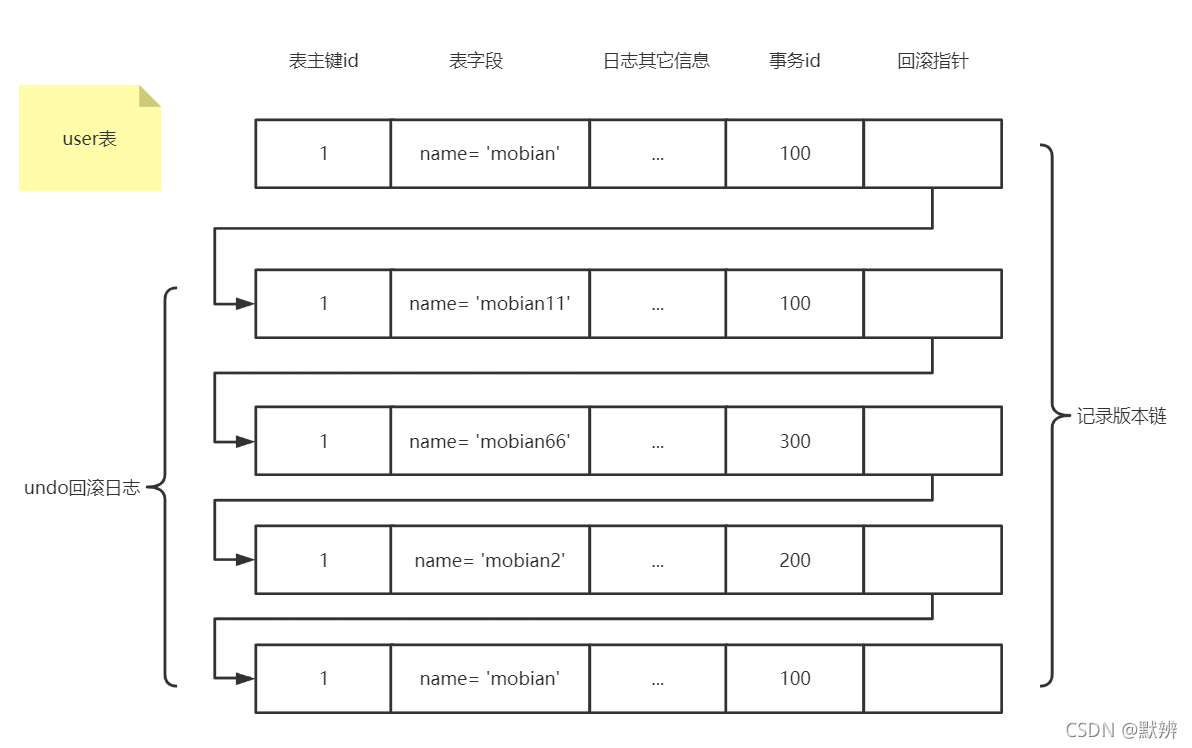
上图就可以解释为:
- 事务id为100的事务修改user表中id为1的数据,将其name修改为mobian;
- 然后事务id为200的事务修改user表中为1的数据,将其name修改为mobian2;
- 然后事务id为300的事务修改user表中为1的数据,将其name修改为mobian66;
- 然后事务id为100的事务再修改user表中为1的数据,将其name修改为mobian11;
- 最后事务id为100的事务修改user表中为1的数据,将其name修改为mobian.
2、字段介绍
事务id、回滚指针、隐含主键、删除状态字段、表修改字段、其他…
每一条记录可以分为以下几个部分:
-
事务id:每一个事务都会分配一个事务id,查看事务id的sql语句如下:
select * from INFORMATION_SCHEMA.INNODB_TRX; -
隐含主键:我们的user表如果有主键,那么这个主键id就是我们自己设置的id,如果user表没有主键,那么数据库底层会为我们的表添加一个默认的主键id(InnoDB的B+索引结构中,如果表没有主键id,聚簇索引(主键索引)就是使用的这个默认主键id做为B+树数据结构的节点)
-
表字段:我们对表数据修改后的记录,比如update user set name = “mobian”,就可以将这个字段的内容近似的理解为name = “mobian”。查询时,MVCC机制返回给用户的结果集。
-
删除状态符:对于删除的情况可以认为是update的特殊情况,会将版本链上最新的数据复制一份,然后将事务id修改成删除操作的事务id,同时在该条记录的头信息(record header)里的(deleted_flag)标记位写上true,来表示当前记录已经被删除,在查询数据时,如果检测到对应的记录为true,则表示数据已被删除,不返回数据。
-
回滚指针:用于指向这条记录的上一个版本,依靠这个字段将所有的修改字段串联为一个链表
3、read-view
一致性视图read-view
在可重复读隔离级别,当事务开启,执行任何查询sql时会生成当前事务的一致性视图read-view,该视图在事务结束之前都不会变化(如果是读已提交隔离级别在每次执行查询sql时都会重新生成)。
这个视图由执行查询时所有未提交事务id数组、数组中最小的事务id(min_id)、已创建的最大事务id(max_id)和组成,事务里的任何SQL查询结果需要从对应版本链里的最新数据开始逐条跟read-view做比对从而得到最终的快照结果,即从上往下查找。
- 如下图表示:未提交的事务id为100和200,300为最大的事务id
readview:[未提交的事务id],最大事务id
readview:[100,200],300
版本链比对规则:
- 如果日志中当前行的事务id小于未提交数组中最小的事务id(min_id),表示这个版本是已提交的事务生成的,这个数据是可见的;
- 如果日志中当前行的事务id大于最大事务id(max_id),表示这个版本是由将来启动的事务生成的,是不可见的;
- 如果日志中当前行的事务id落在min_id和max_id之间,那就包括两种情况
- 若日志中当前行的事务id在视图数组中(试图数组由未提交数据组成),表示这个版本是由还没提交的事务生成的,不可见(若 事务id就是当前自己的事务是可见的);
- 若日志中当前行的事务id不在视图数组中,表示这个版本是已经提交了的事务生成的,可见
4、MVCC机制理解
在我看来,MVCC机制就是在结合undo日志与read-view一致性试图的基础上,进行的一种数据访问机制。
案例分析:
事务A(事务id为100)首先查询user表的数据,然后事务B(事务id为200)修改了对应的记录(将id为1的记录中name字段的值修改为mobian2),并且完成事务的提交。事务A再去查询对应的数据,此时查询出来的结果集是什么呢?
可重复读
可重复读隔离级别,当事务开启,执行任何查询sql时会生成当前事务的一致性视图readview,该视图在事务结束之前都不会变化
回到我们最开始的例子,在可重复读的事务隔离级别基础上,我们结合MVCC机制,再来解释对应的结果。
在事务id为100的事务开启之后,会生成对应的readview一致性试图,假设当前事务只有一个一个事务,那么一致性视图可以描述为:readview:[100],100。然后事务id为200的事务进行了数据的修改,此时会在我们的undo日志上追加一条数据记录。最后当我们事务id为100的事务再次查询记录时,我们就会结合当前事务生成的一致性视图(readview:[100],100)去undo日志版本中进行数据访问比对。
- 首先比对第一行,事务id为200,id200大于最大id100,即对id100的事务而言,它是将来启动的版本,不可见;
- 然后去比对第二行,事务id为100,id100落在最大id和最小id之前,由于id100落在数组中,表示可见的,此时返回数据mobian

即,我们最终返回的结果还是之前的结果,不是mobian2。即达到了我们的可重复读的效果
读已提交
读已提交隔离级别在每次执行查询SQL时都会重新生成readview
在可读已提交的事务隔离级别基础上,结合MVCC机制,再来解释对应的结果。
在事务id为100的事务开启之后,会生成对应的readview一致性试图,假设当前事务只有一个一个事务,那么一致性视图可以描述为:readview:[100],100。然后事务id为200的事务进行了数据的修改,此时会在我们的undo日志上追加一条数据记录。最后当我们事务id为100的事务再次查询记录时,又会重新生成我们的readview一致性视图,此时的一致性视图可以描述为:readview:[100],200。我们就会结合当前事务生成的一致性视图(readview:[100],200)去undo日志版本中进行数据访问比对。
- 首先比对第一行,事务id为200,根据版本比对规则,我们发现200,落在最大事务id和最小事务id之间,并且id200不在视图数组中(数组中目前只有100),则数据可见,返回结果
即,我们最终返回的结果为mobian2。即达到了我们的读已提交的效果