大家好,我是涛哥。
今天来聊一种重要的数据结构:trie树。大家经常使用google, 当输入搜索内容后,有自动提示的功能,节省了时间。那么,这个自动提示功能是怎样实现的呢?
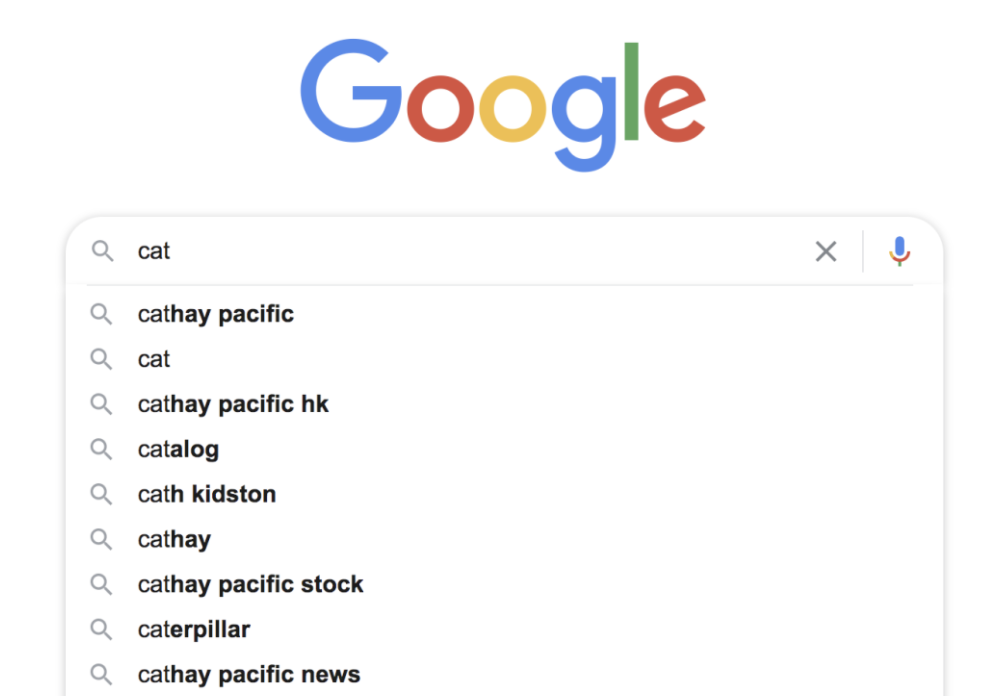
trie树之初见
关于搜索的匹配,可以用哈希表,也可以用红黑树,其实,今天要说的trie树更适合这种场景,因为trie树能实现前缀匹配,具有天然的优势。
trie树,就是retrieval树,也即检索,名如其实,我们先来看看trie树的数据结构。以"cat", "dog", "cattle", "bag"为例,trie树结构如下:
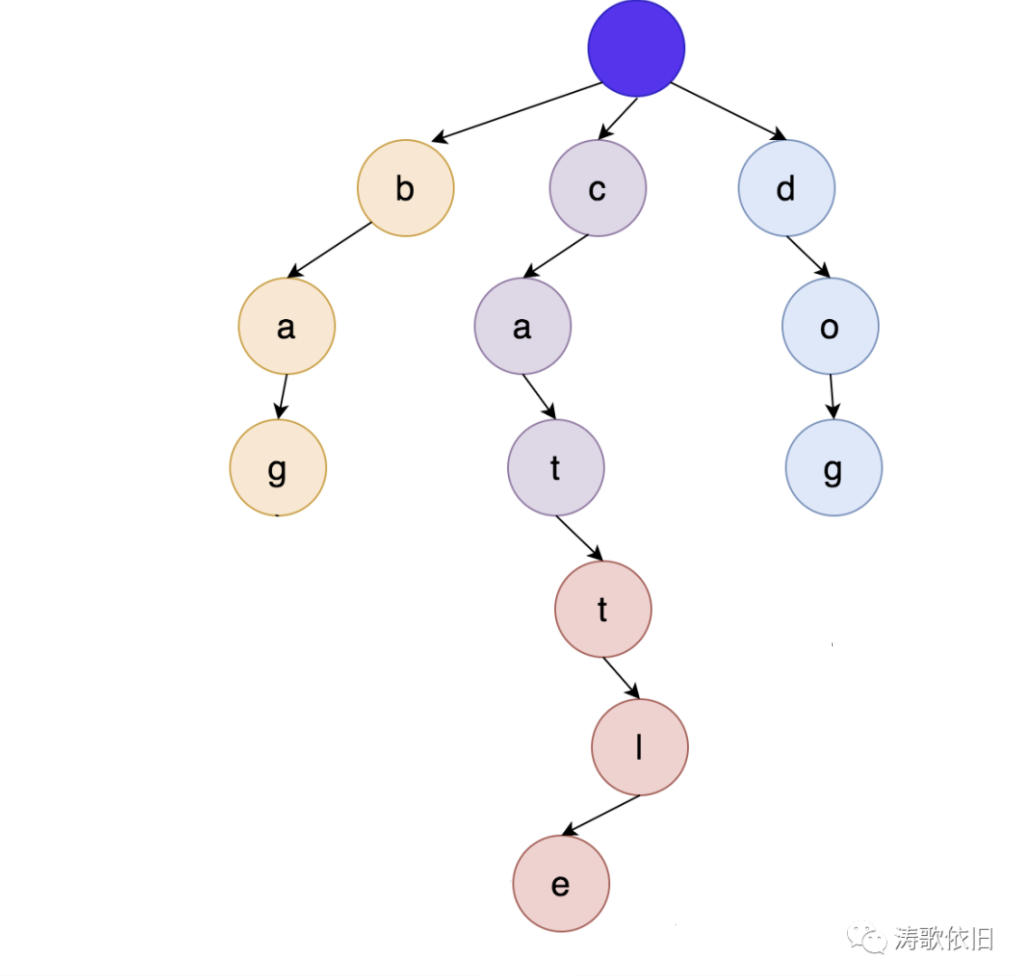
可以看到,根结点不存储字母,其它每个结点,存储的是字母。如果用户输入"cat", 就能帮助用户联想到"cat"和"cattle", 实现了提示功能。
trie树的实现
很显然,对于每一个结点而言,它要存储一个字母(根结点除外),而且还可能有26个孩子结点,所以需要26个指针。
除此之外,在结点中,还需要标注该结点是否为终结结点,如使用isComplete标识,所以,每个结点的数据结构是:
// trie结点
class TrieNode
{
public:
char ch; // 存储字母
TrieNode *child[26]; // 指向26个可能的孩子结点
bool isComplete; // 该结点是否为终结结点
TrieNode() // 构造函数
{
for(int i = 0; i < 26; i++)
{
child[i] = NULL;
isComplete = false;
}
}
};trie树的常规操作是:
-
插入一个单词,即insert方法
-
查找一个单词,即search方法
-
查找一个前缀,即startWith方法
整个程序如下:
#include <iostream>
using namespace std;
// trie结点
class TrieNode
{
public:
char ch; // 存储字母
TrieNode *child[26]; // 指向26个可能的孩子结点
bool isComplete; // 该结点是否为终结结点
TrieNode() // 构造函数
{
for(int i = 0; i < 26; i++)
{
child[i] = NULL;
isComplete = false;
}
}
};
// trie树, 为简便起见,不考虑结点堆内存的释放
class Trie
{
private:
TrieNode *t;
public:
Trie()
{
t = new TrieNode();
}
// 插入一个单词
void insert(const string &str)
{
int len = str.size();
if(len > 0)
{
TrieNode *p = t;
for(int i = 0; i < len; i++)
{
int j = str[i] - 'a';
if(p->child[j] == NULL)
{
p->child[j] = new TrieNode();
p->child[j]->ch = str[i];
}
p = p->child[j];
}
p->isComplete = true;
}
}
// 查找一个单词
bool search(const string &str)
{
int len = str.size();
TrieNode *p = t;
for(int i = 0; i < len; i++)
{
int j = str[i] - 'a';
if(p->child[j] == NULL)
{
return false;
}
p = p->child[j];
}
if(p->isComplete)
{
return true;
}
return false;
}
// 查找前缀
bool startsWith(const string &str)
{
int len = str.size();
if (len <= 0)
{
return false;
}
TrieNode *p = t;
for(int i = 0; i < len; i++)
{
int j = str[i] - 'a';
if(p->child[j] == NULL)
{
return false;
}
p = p->child[j];
}
return true;
}
};
int main()
{
Trie *t = new(Trie);
t->insert("cat");
t->insert("dog");
t->insert("cattle");
t->insert("bag");
cout << t->search("cat") << endl;
cout << t->search("bag") << endl;
cout << t->startsWith("ca") << endl;
cout << t->search("catt") << endl;
cout << t->search("pig") << endl;
cout << t->search("") << endl;
cout << t->startsWith("") << endl;
cout << t->startsWith("cab") << endl;
}结果如下:
1
1
1
0
0
0
0
0
从上面的程序中,很容易分析出trie树的时间复杂度。而且,不可否认,trie树是比较耗费空间的,因为要存储很多指针信息。
trie树在前缀查找方面有独特的优势,速度非常快。实际上,大家经常使用的IDE的自动提示功能,也能够使用trie树来实现。
最近立冬了,大家要注意保暖。南方的艳阳里,大雪纷飞,北方的寒夜里,四季如春。《南山南》里的优美歌词,懂的自然懂。