APIJSON(五:AbstractObjectParser源码阅读2)
2021SC@SDUSC
本篇继续对AbstractObjectParser类下的源码进行阅读。
之后是一些很无聊的成员变量的设置、读取——
@Override
public String getParentPath() {
return parentPath;
}
@Override
public AbstractObjectParser setParentPath(String parentPath) {
this.parentPath = parentPath;
return this;
}
protected int position;
public int getPosition() {
return position;
}
public AbstractObjectParser setPosition(int position) {
this.position = position;
return this;
}
isBreakParse
下面这段稍稍有点有趣——
private boolean invalidate = false;
public void invalidate() {
invalidate = true;
}
public boolean isInvalidate() {
return invalidate;
}
private boolean breakParse = false;
public void breakParse() {
breakParse = true;
}
public boolean isBreakParse() {
return breakParse || isInvalidate();
}
invalidate是无效的意思
breakparse是中断解析
这两个成员变量都默认为false,可以通过对应的函数对其进行修改。(由于只有一个修改方法,可以看出至少在这里设计时,修改是不可逆的)在最后的返回isBreakParse时,上述两个只要有一个为true——即被修改过——就会返回true
Map
/**
* 自定义关键词
*/
protected Map<String, Object> customMap;
/**
* 远程函数
* {"-":{ "key-()":value }, "0":{ "key()":value }, "+":{ "key+()":value } }
* - : 在executeSQL前解析
* 0 : 在executeSQL后、onChildParse前解析
* + : 在onChildParse后解析
*/
protected Map<String, Map<String, String>> functionMap;
/**
* 子对象
*/
protected Map<String, JSONObject> childMap;
上面出现了一些抽象函数
首先是权限关键字protected
protected:
(1)父类的被protected修饰的类成员包内可见,并且对其子类可见。
(2)父类与子类不在同一个包里,子类只可以访问从父类继承的protected成员,不能访问父类实例化的成员。
之后是java中的map集合类
Map
Map中的集合,元素是成对存在的(理解为夫妻)。每个元素由键与值两部分组成,通过键可以找对所对应的值。
parse
下面是一个parse函数,在ObjectParser的接口中,对这个函数的描述是——解析成员
我们一点一点往下看吧
@Override
public AbstractObjectParser parse(String name, boolean isReuse) throws Exception
传入了一个string变量和bool变量(是否再次使用)
isInvalidate() == false
if (isInvalidate() == false) {
this.isReuse = isReuse;
this.name = name;
this.path = AbstractParser.getAbsPath(parentPath, name);
apijson.orm.Entry<String, String> tentry = Pair.parseEntry(name, true);
this.table = tentry.getKey();
this.alias = tentry.getValue();
Log.d(TAG, "AbstractObjectParser parentPath = " + parentPath + "; name = " + name + "; table = " + table + "; alias = " + alias);
Log.d(TAG, "AbstractObjectParser type = " + type + "; isTable = " + isTable + "; isArrayMainTable = " + isArrayMainTable);
Log.d(TAG, "AbstractObjectParser isEmpty = " + request.isEmpty() + "; tri = " + tri + "; drop = " + drop);
breakParse = false;
response = new JSONObject(true);//must init
sqlReponse = null;//must init
然后如果不是无效的话,就对该类中的成员变量进行一些赋值。
其中AbstractParser.getAbsPath(parentPath, name)是用来获取绝对路径的一个函数。
然后在后面用到了一个Entry,Entry其实就是一个用了通项的map,其主要的结构就一个键和一个值。具体代码如下
public class Entry<K, V> {
public K key;
public V value;
public Entry() {
//default
}
public Entry(K key) {
this(key, null);
}
public Entry(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public void setKey(K key) {
this.key = key;
}
public V getValue() {
return value;
}
public void setValue(V value) {
this.value = value;
}
public boolean isEmpty() {
return key == null && value == null;
}
}
而其使用的Pair.parseEntry
public static Entry<String, String> parseEntry(String pair) {
return parseEntry(pair, false);
}
这里的pair是一个leftKey:rightValue的字符串型式,然后后面的false的意思是右边的value值不缺省
之后就是使用了log.d对上述获得的信息进行打印
对于log的代码段这里不进行详细分析,详情可以移步,这篇文章的末尾
之后继续是对response、sqlReponse进行一个变量的设置。
isReuse == false
之后就是使用了log.d对上述获得的信息进行打印
对于log的代码段这里不进行详细分析,详情可以移步,这篇文章的末尾
之后继续是对response、sqlReponse进行一个变量的设置。
isReuse == false
照例是一些参数设置——
if (isReuse == false) {
sqlRequest = new JSONObject(true);//must init
customMap = null;//must init
functionMap = null;//must init
childMap = null;//must init
然后是对set进行了初始化
Set<Entry<String, Object>> set = request.isEmpty() ? null : new LinkedHashSet<Entry<String, Object>>(request.entrySet());
首先会对request进行判断,如果为空,set就会被写入null;如果不为空,就会被写入一个LinkedHashSet结构的request数据
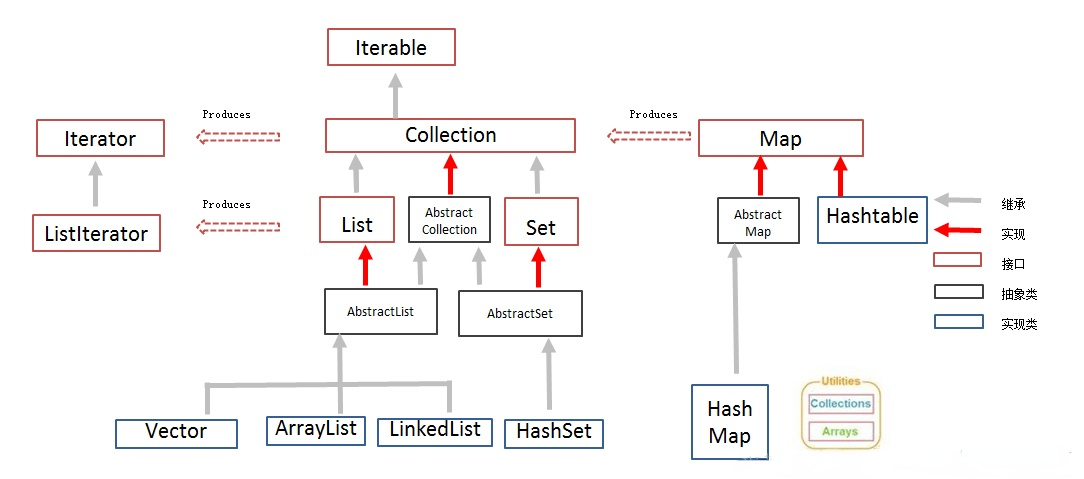
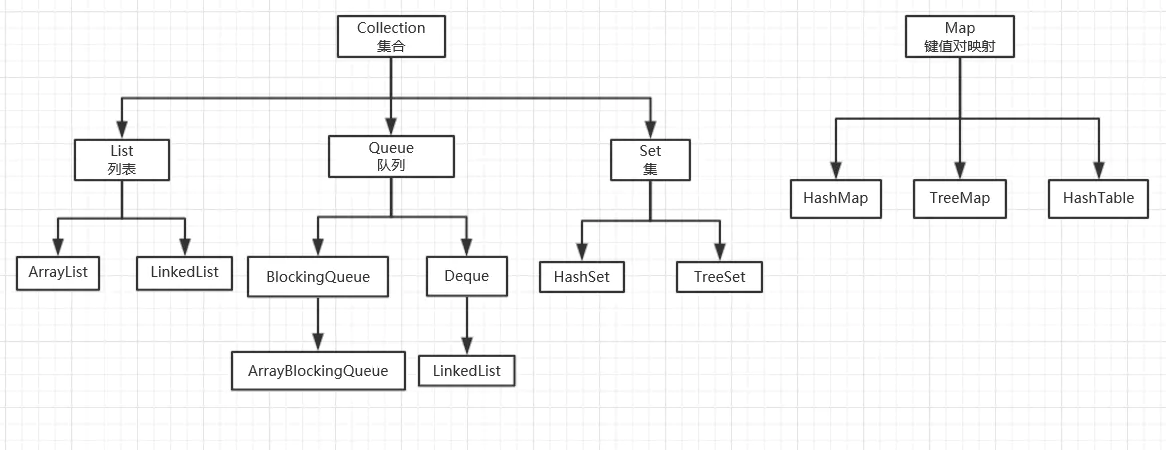
Java集合主要由2大体系构成,分别是Collection体系和Map体系,其中Collection和Map分别是2大体系中的顶层接口。
Collection主要有三个子接口,分别为List(列表)、Set(集)、Queue(队列)。其中,List、Queue中的元素有序可重复,而Set中的元素无序不可重复;
HashSet继承AbstractSet类,实现Set、Cloneable、Serializable接口。其中AbstractSet提供 Set 接口的骨干实现,从而最大限度地减少了实现此接口所需的工作。
Set接口是一种不包括重复元素的Collection,它维持它自己的内部排序,所以随机访问没有任何意义。LinkedHashSet是HashSet的一个“扩展版本”,HashSet并不管什么顺序,不同的是LinkedHashSet会维护“插入顺序”。HashSet内部使用HashMap对象来存储它的元素,而LinkedHashSet内部使用LinkedHashMap对象来存储和处理它的元素。
HashSet,TreeSet与LinkedHashSet详解
if (set != null && set.isEmpty() == false) {//判断换取少几个变量的初始化是否值得?
if (isTable) {//非Table下必须保证原有顺序!否则 count,page 会丢, total@:"/[]/total" 会在[]:{}前执行!
customMap = new LinkedHashMap<String, Object>();
childMap = new LinkedHashMap<String, JSONObject>();
}
functionMap = new LinkedHashMap<String, Map<String, String>>();//必须执行
这里继续进行了一番初始化。
去除 &,|,! 前缀
List<String> whereList = null;
if (method == PUT) { //这里只有PUTArray需要处理 || method == DELETE) {
String[] combine = StringUtil.split(request.getString(KEY_COMBINE));
if (combine != null) {
String w;
for (int i = 0; i < combine.length; i++) {
w = combine[i];
if (w != null && (w.startsWith("&") || w.startsWith("|") || w.startsWith("!"))) {
combine[i] = w.substring(1);
}
}
}
//Arrays.asList()返回值不支持add方法!
whereList = new ArrayList<String>(Arrays.asList(combine != null ? combine : new String[]{}));
whereList.add(apijson.JSONRequest.KEY_ID);
whereList.add(apijson.JSONRequest.KEY_ID_IN);
// whereList.add(apijson.JSONRequest.KEY_USER_ID);
// whereList.add(apijson.JSONRequest.KEY_USER_ID_IN);
}
这里首先创建了一个List类的wherelist
在Collection中,List集合是有序的,Developer可对其中每个元素的插入位置进行精确地控制,可以通过索引来访问元素,遍历元素。
在List集合中,我们常用到ArrayList和LinkedList这两个类。
boolean add(E e):向集合中添加一个元素
这里首先是判断了method是否为PUT,是的话就会进行去除 &,|,! 前缀的操作——
具体就是先使用JsonObject的getString的方法,取得对应key的value值。相关源码如下
public String getString(String key) {
Object value = this.get(key);
return value == null ? null : value.toString();
}
public Object get(Object key) {
Object val = this.map.get(key);
if (val == null && (key instanceof Number || key instanceof Character || key instanceof Boolean || key instanceof UUID)) {
val = this.map.get(key.toString());
}
return val;
}
然后就是逐个判断combine的开始首字母,如果是&,|,! 开头的就用substring方法跳过w[0]从w[1]开始截取。
最后再将修改好的值通过add方法返回到whereList中。