分析
userMapper.selectPage(page, queryWrapper);
上面这个分页查询方法,只能针对当前自己的实体,他很好的支持与解决,但是关联查询就不行了。
- 上面代码的底层,会通过拦截器PageInterceptor会进行拦截处理,会把执行的sql和count同时发生执行!
- 同时会根据返回的总数,字段换算出来给Page对象的pages、total、current等属性赋值。
- 数据放在Page对象的records属性中,用一个Page对象整个包裹一层再进行返回。
规律
- 基础的sql(单表通过反射去生成) 多表自己去定制sql语句(mapper.xml)
- 分页条件 用mp
- 求count(1) 用mp
多表关联查询并且分页实现步骤
1、先建一个UserMapper接口
@Repository
public interface UserMapper extends BaseMapper<User> {
// 多表关联sql语句自己写;分页以及条件用mp,返回值是Map
IPage<Map<String, Object>> selectUserPageMap(Page page, @Param(Constants.WRAPPER) Wrapper<User> queryWrapper);
}
2、定义UserMapper.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.kuangstudy.mapper.UserMapper">
<select id="selectUserPageMap" resultType="java.util.Map">
SELECT
ku.id,
ku.nickname,
ku.password,
ku.telephone,
ku.email,
ku.avatar,
ku.sign,
ku.create_time as createTime,
ku.update_time as updateTime,
ku.active,
ku.role,
count( 1 ) AS num
FROM
kss_blog kb
LEFT JOIN kss_user ku ON ku.id = kb.user_id
${ew.customSqlSegment}
</select>
</mapper>
说明:上面的${ew.customSqlSegment}相当于一个占位符,后续当你在mp的条件构造器中加入条件,mp的底层就会根据条件自动的在这个占位符处进行条件的拼接
3、定义测试用例来验证是否正确
//使用MP的QueryWrapper来完成连表查询并分页
@Test
public void findUsersByPageMap(){
// 0为pageNo,2为pageSize
Page<User> page = new Page<>(0,2);
UserParamsVo userParamsVo = new UserParamsVo();
userParamsVo.setActive(1);
userParamsVo.setRole("admin");
// 条件
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.like(!StringUtils.isEmpty(userParamsVo.getUsername()),"ku.nickname",userParamsVo.getUsername());
queryWrapper.eq(Optional.ofNullable(userParamsVo.getActive()).isPresent(),"ku.active",userParamsVo.getActive());
queryWrapper.eq(Optional.ofNullable(userParamsVo.getRole()).isPresent(),"ku.role",userParamsVo.getRole());
queryWrapper.groupBy("kb.user_id");
queryWrapper.orderByDesc("num");
IPage<Map<String, Object>> mapIPage = userMapper.selectUserPageMap(page, queryWrapper);
List<Map<String, Object>> records = mapIPage.getRecords();
records.forEach(System.out::println);
System.out.println("总数是:"+mapIPage.getTotal());
System.out.println("共有"+mapIPage.getPages()+"页");
System.out.println("当前是第"+mapIPage.getCurrent()+"页");
}
4、查看结果
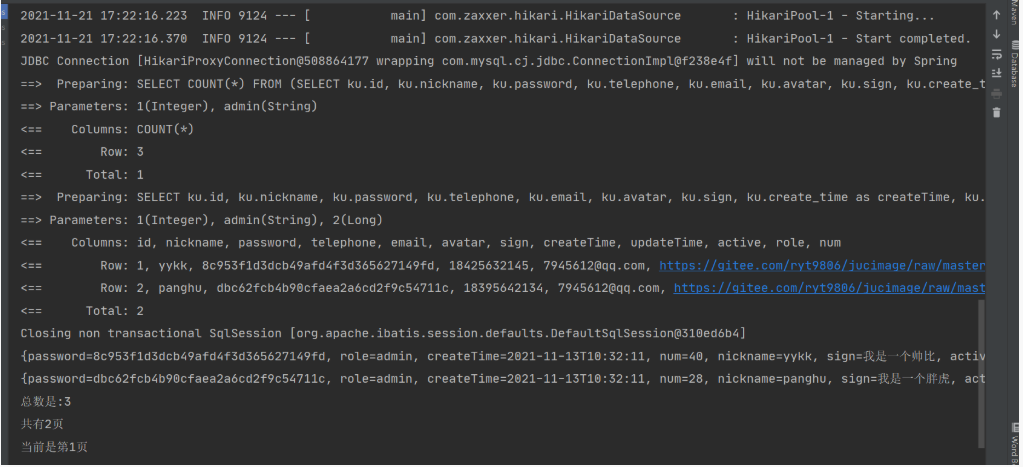
5、对结果的分析
1、我们为什么不能使用LambdaQueryWrapper进行条件的筛选和过滤呢?
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.like(!StringUtils.isEmpty(userParamsVo.getUsername()),User::getNickname,userParamsVo.getUsername());
queryWrapper.eq(Optional.ofNullable(userParamsVo.getActive()).isPresent(), User::getActive,userParamsVo.getActive());
queryWrapper.eq(Optional.ofNullable(userParamsVo.getRole()).isPresent(),User::getRole,userParamsVo.getRole());
queryWrapper.orderByDesc(User::getCreateTime);
上面的代码有一个问题,无法给表的字段设置别名,而开发中一般情况下表的字段,有可能重叠,所以,他就不适合多表关联的情况下使用了!
上面的queryWrapper.orderByDesc(User::getCreateTime),mp底层会通过反射机制拿到User.class,拿到类中的属性,拿到类上的@TableName("kss_user")注解,会自动的将User::getCreateTime映射为表kss_user的create_time字段。
orderByDesc()方法会自动转变为sql语句的order by 字段(create_time) desc,同理,里面的所有方法都是如此。
2、我们为什么要指定别名呢?
如果我们将上面代码中的一部分进行替换,在运行查看结果,如:
queryWrapper.orderByDesc("createtime");
查看结果:

报错的原因是:order子句中的“创建时间”列不明确,也就是上面两个表中都有create_time字段,mp底层通过反射拿到了两个表的
create_time字段,mp凌乱了,不知道要用哪一个就报错了!!!
所以,当我们使用QueryWrapper时就可以自定义传入的字段了,就可以起别名了!
3、查看底层源码
/**
* 根据 entity 条件,查询全部记录(并翻页)
*
* @param page 分页查询条件(可以为 RowBounds.DEFAULT)
* @param queryWrapper 实体对象封装操作类(可以为 null)
*/
<E extends IPage<T>> E selectPage(E page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
/**
* 根据 Wrapper 条件,查询全部记录(并翻页)
*
* @param page 分页查询条件
* @param queryWrapper 实体对象封装操作类
*/
<E extends IPage<Map<String, Object>>> E selectMapsPage(E page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
-
我们可以看到,当我们单表进行分页操作时,指定泛型为User时,他就会通过第一个方法进行封装返回
-
而当我们自定义连表查询基础sql的时候,我们就可以模仿它的这种机制,只需改变对应的泛型,在xml对应的方法中用占位符,再用mp机制后期再进行方法的注入条件,就可以完美的解决 连表 + 分页了!
-
我们查看控制台,发现在使用mp分页查询的方法是:mp会发起两条sql。
-
第一条就是对当前的sql发起执行返回结果
-
第二条是
select count(*) from (当前执行的sql) as TOTAL
