联合查询与嵌套映射场景
联合查询时指查询语句有left join 或者全表连接等多个表关联的查询,这种查询由于涉及到多个表,且一般都会查出多个表的字段,而相应的resultMap会需要映射成多个对象,如下所示:
<resultMap id="blogComplexMap" type="com.entity.Blog" autoMapping="true">
<id column="id" property="id"></id>
<result column="title" property="title"></result>
<collection property="comments" ofType="com.entity.Comment" autoMapping="true" columnPrefix="comment_">
</collection>
</resultMap>
<!--联合查询-->
<select id="selectBlogByIdWithComplex" resultMap="blogComplexMap">
select b.id,b.title,c.id as comment_id ,c.content as comment_content from blog b left join comment c on b.id=c.blog_id where b.id = #{
id}
</select>
这里需要找blog 和comment两张表的字段,且在结果映射中需要在blog对象里映射出comment集合对象。
映射概念说明
映射是指返回的ResultSet列与Java Bean 属性之间的对应关系。通过ResultMapping进行映射描述,在用ResultMap封装成一个整体。映射分为简单映射与复合嵌套映射。
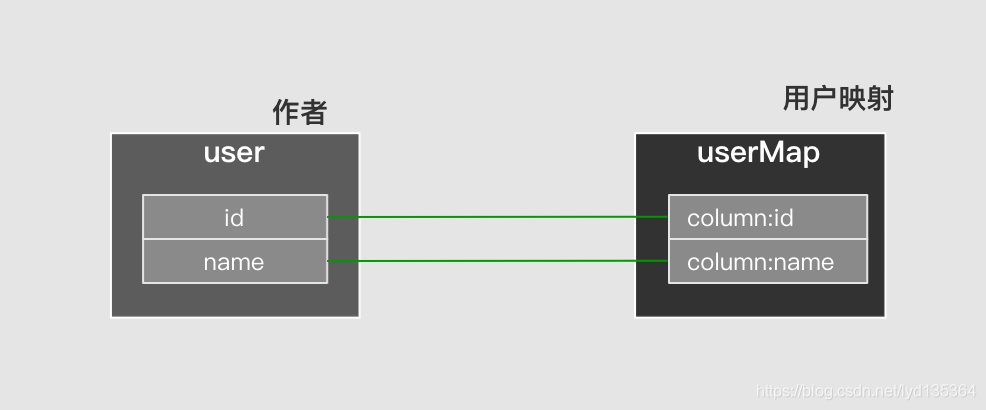
简单映射:即返回的结果集列与对象属性是1对1的关系,这种情况下ResultHandler 会依次遍历结果集中的行,并给每一行创建一个对象,然后在遍历结果集列填充至对象的映射属性,下图表示user对象与user的resultMap中的属性一一对应的情况:
嵌套映射:但很多时候对象结构, 是树级程现的。即对象中包含对象。与之对应映射也是这种嵌套结构。
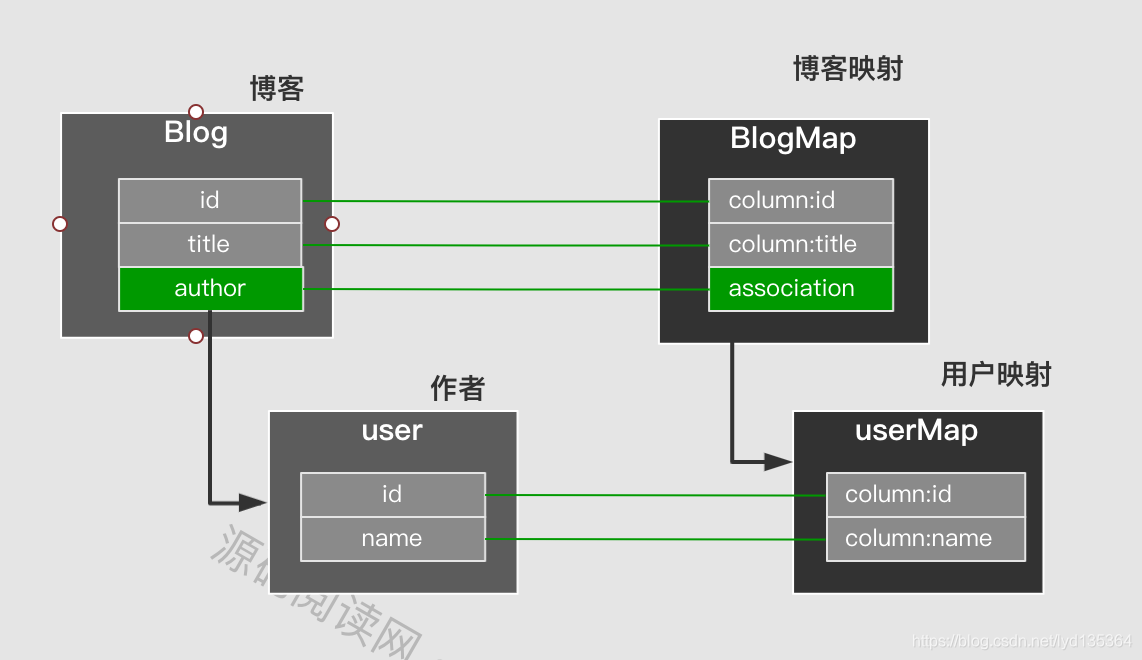
在嵌套映射的配置方式上可以直接配置子映射,也以引入外部映射和自动映射。映射共有两类嵌套结构分别是一对一(association) 与一对多(collection) 。

联合查询概念
在配置了映射之后如何获取结果?普通的单表查询是无法获取复合映射所需结果,这就必须用到联合查询。然后在将联合查询返回的数据列,拆分给不同的对象属性。1对1与1对多拆分和创建的方式是一样的。
1对1查询映射
select a.id,
a.title,
b.id as user_id,
b.name as user_name
from blog a
left join users b on a.author_id=b.id
where a.id = 1;
通过上述语句联合查询语句,可以得出下表中结果。结果中前两字段对应Blog,后两个字段对应User。然后在将User作为author属性填充至Blog对象。


在上述两个例子中,每一行都会产生两个对象,一个Blog父对象,一个User子对象。
1对多查询
select a.id,a.title,
c.id as comment_id,
c.body as comment_body
from blog a
left join comment c on a.id=c.blog_id
where a.id = 1;
上述语句可得出三条结果,前两个字段对应Blog,后两个字段对应Comment(评论)。与1对1不同的是,三行指向的是同一Blog。因为它ID都是一样的。


上述结果中,相同的三行Blog将会创建一个Blog,同时分别创建三个不同的Comment组成一个集合,并填充至comments对象。那么如何判断数据是否相同需不需要合并呢,实际上mybatis是基于RowKey来断定两行数据是否相同的 。RowKey一般基于的配置来指定,但实际上有时并不会指定,这时将会采用其它映射字段创建RowKey具体规则如下:
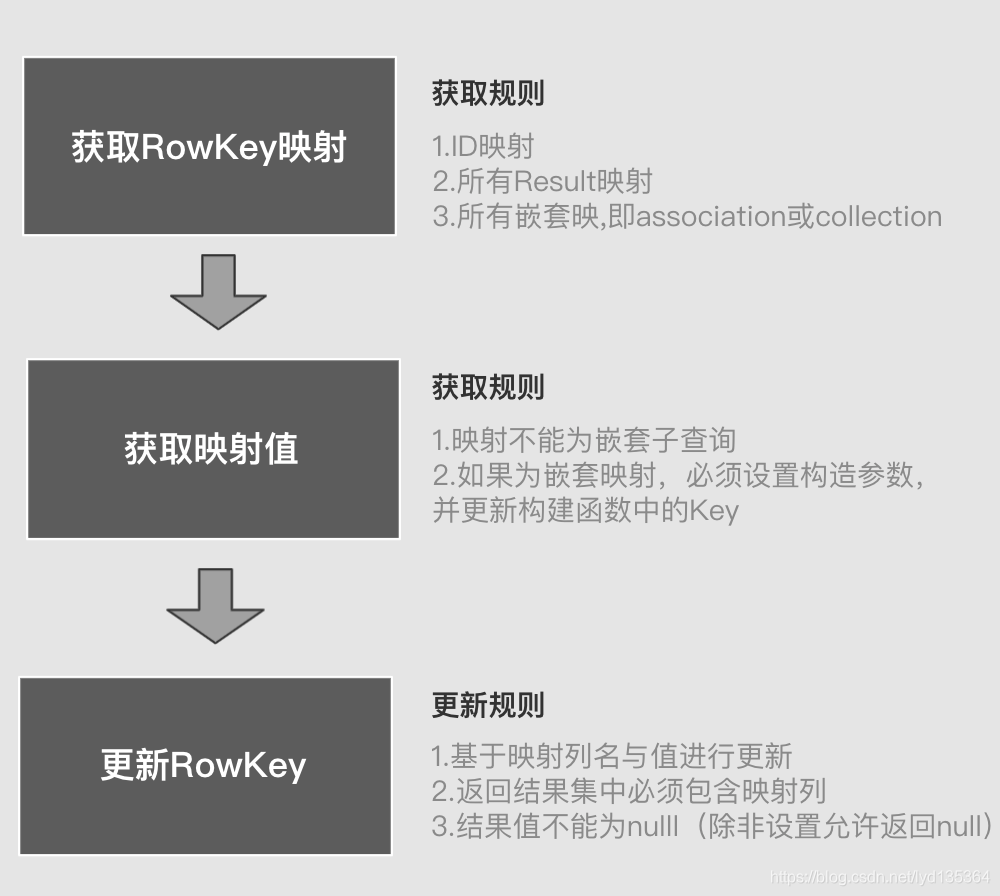
相应的源码:
private CacheKey createRowKey(ResultMap resultMap, ResultSetWrapper rsw, String columnPrefix) throws SQLException {
CacheKey cacheKey = new CacheKey();
cacheKey.update(resultMap.getId());
List<ResultMapping> resultMappings = this.getResultMappingsForRowKey(resultMap);
if (resultMappings.isEmpty()) {
if (Map.class.isAssignableFrom(resultMap.getType())) {
this.createRowKeyForMap(rsw, cacheKey);
} else {
this.createRowKeyForUnmappedProperties(resultMap, rsw, cacheKey, columnPrefix);
}
} else {
this.createRowKeyForMappedProperties(resultMap, rsw, cacheKey, resultMappings, columnPrefix);
}
return cacheKey.getUpdateCount() < 2 ? CacheKey.NULL_CACHE_KEY : cacheKey;
}
结果集解析流程
这里直接采用1对多的情况进行解析,因为1对1就是1对多的简化版。查询的结果如下表:

其整个解析流程如下图:
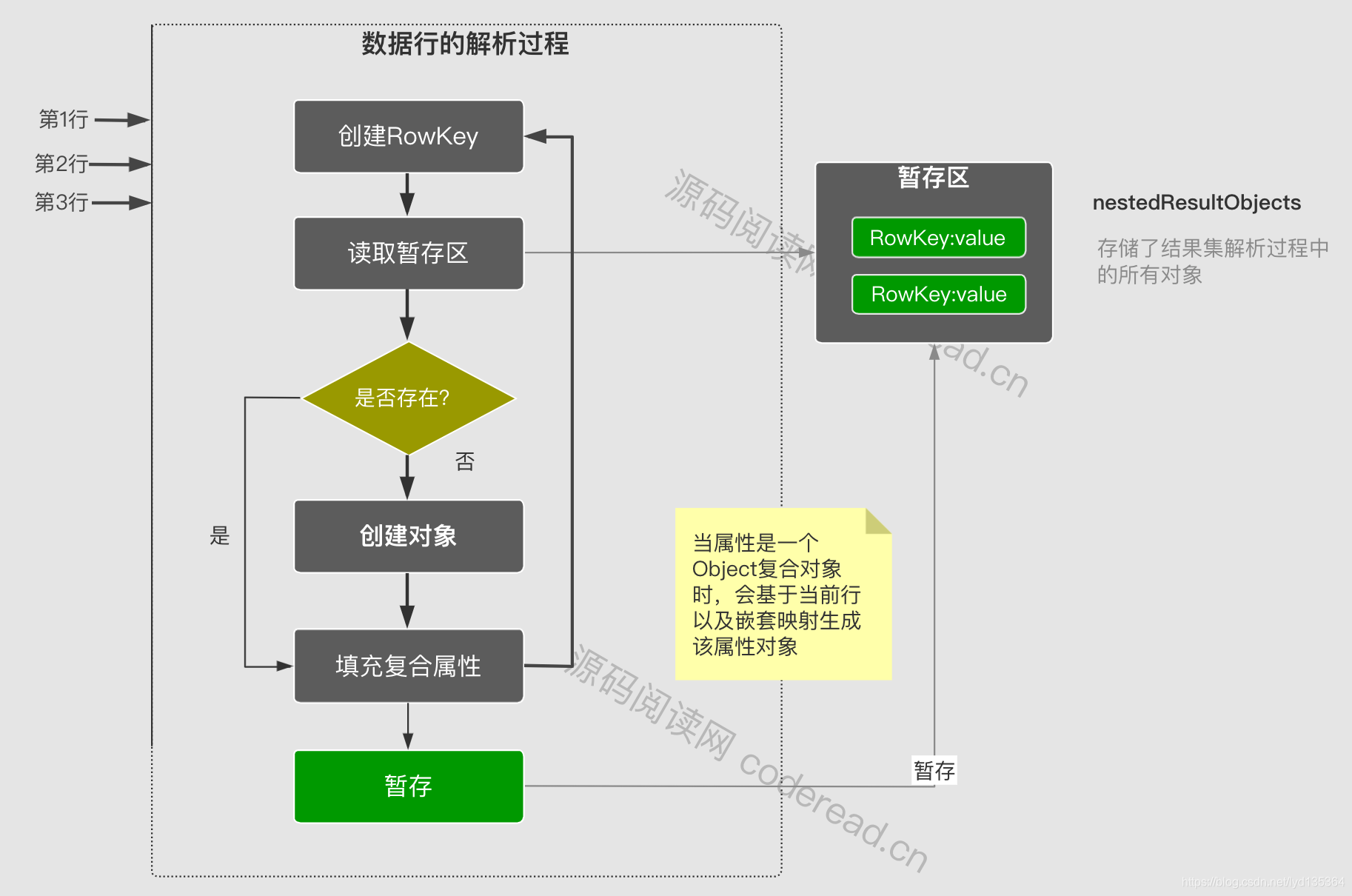
所有映射流程的解析都是在DefaultResultSetHandler当中完成。主要方法如下:
handleRowValuesForNestedResultMap()
嵌套结果集解析入口,在这里会遍历结果集中所有行。并为每一行创建一个RowKey对象。然后调用getRowValue()获取解析结果对象。最后保存至ResultHandler中,对应的源码如下:
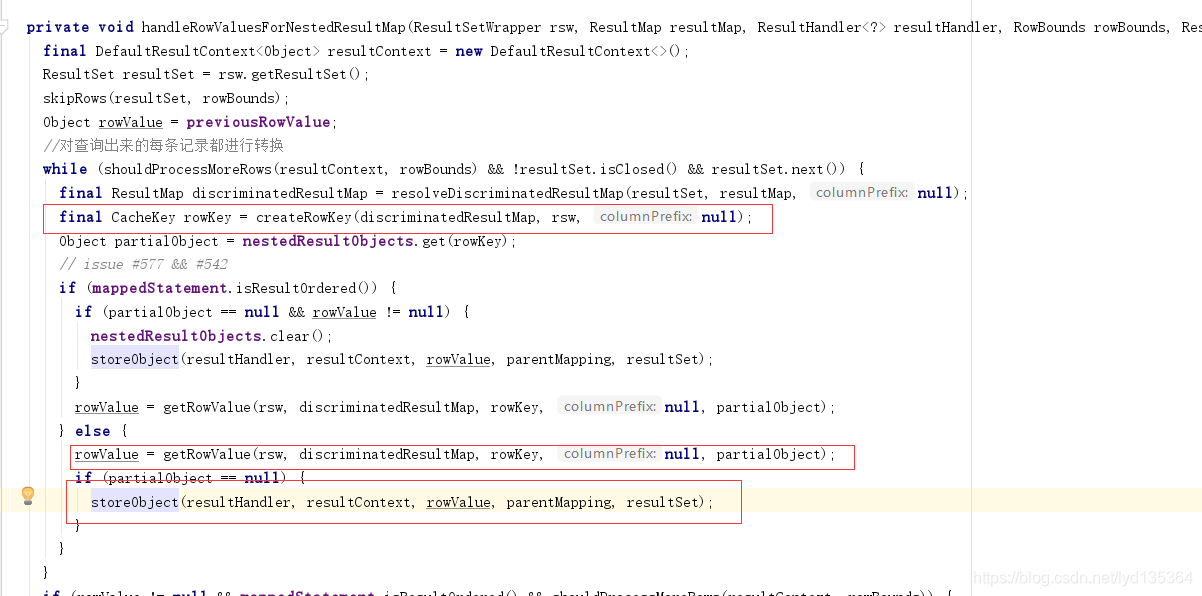
注:调用getRowValue前会基于RowKey获取已解析的对象,然后作为partialObject参数发给getRowValue
getRowValue()
该方法最终会基于当前行生成一个解析好的对象。具体职责包括
1.创建对象、
2.填充普通属性
3.填充嵌套属性。
在解析嵌套属性时会以递归的方式在调用getRowValue获取子对象。
4.最后基于RowKey 暂存当前解析对象。
如果partialObject参数不为空 只会执行 第3步。因为1、2已经执行过了。
相应的源码如下:
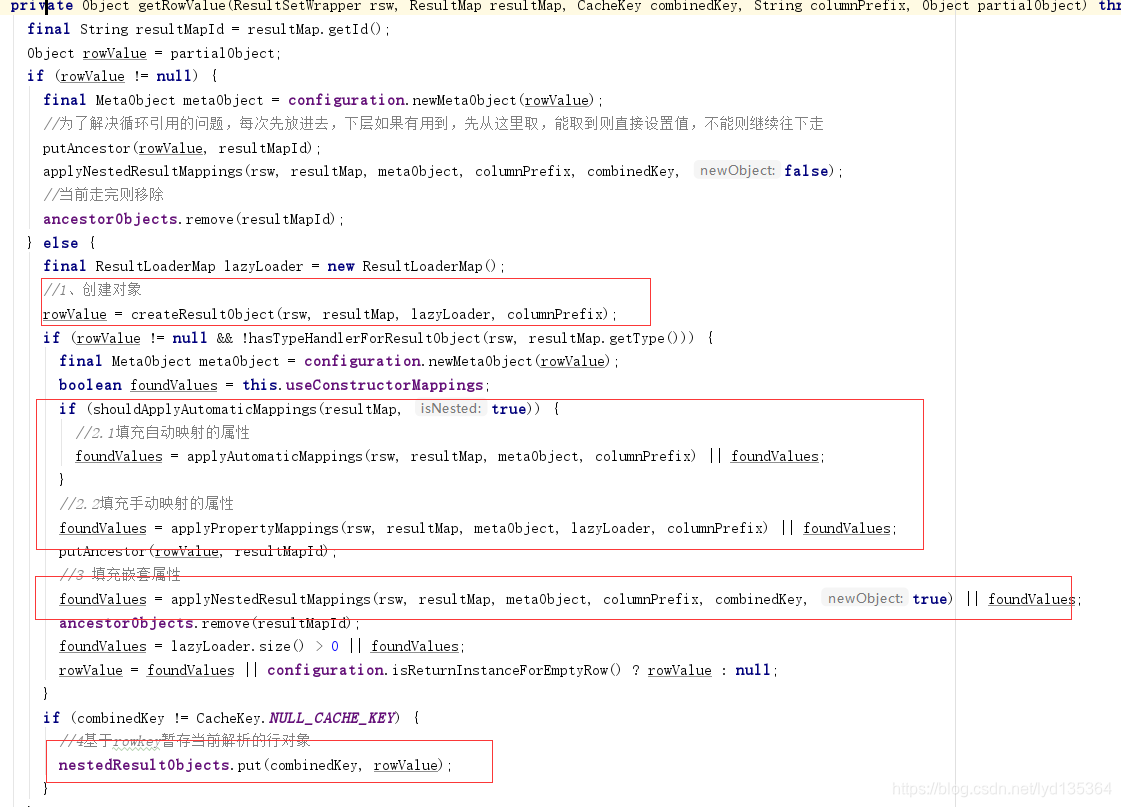
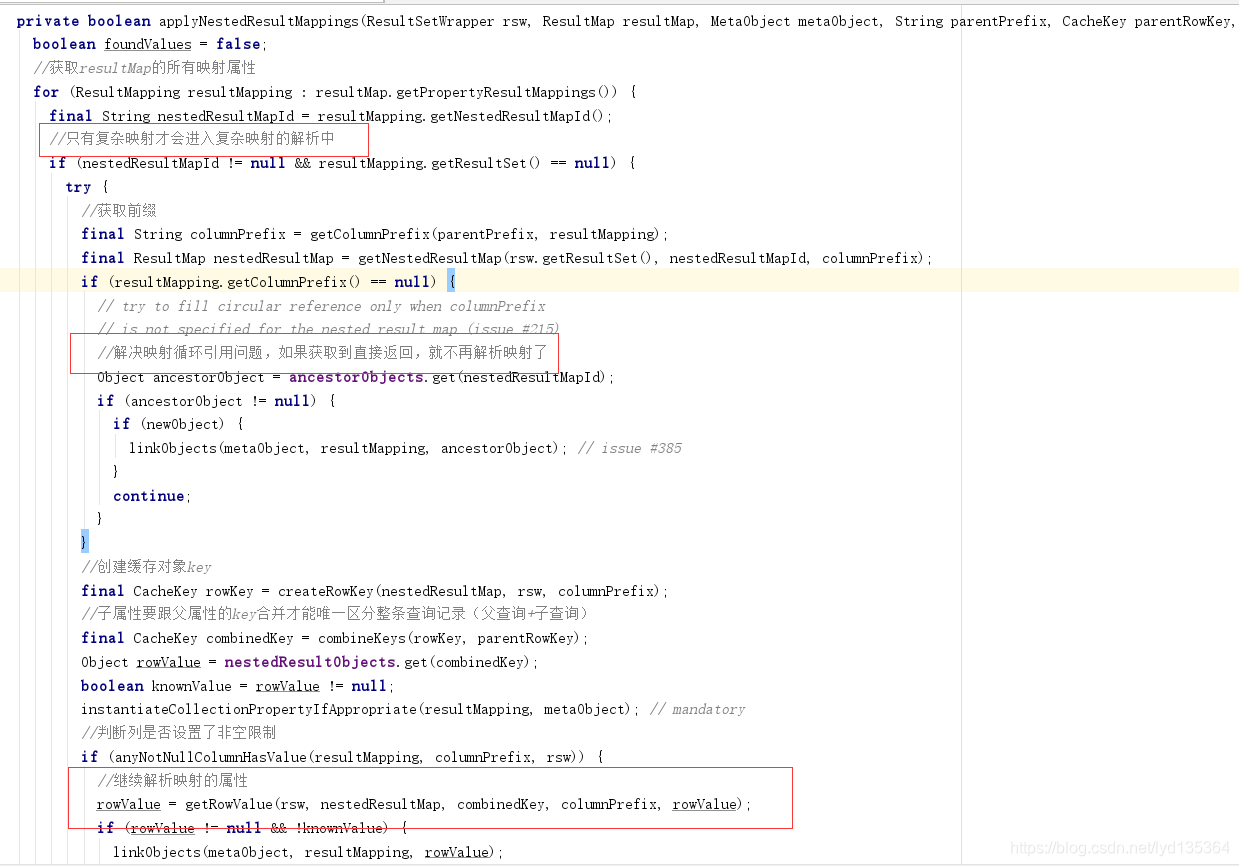
applyNestedResultMappings()
解析并填充嵌套结果集映射,遍历所有嵌套映射,然后获取其嵌套ResultMap。接着创建RowKey 去获取暂存区的值。然后调用getRowValue 获取属性对象。最后填充至父对象。
如果通过RowKey能获取到属性对象,它还是会去调用getRowsValue,因为有可能属下还存在未解析的属性。
相应的源码如下:
本文参考的文档为:www.coderead.cn