图片转文字的两种处理方法:
一种是文字识别工作都需要在网络侧完成的方式,我们称为在线识别;
另一种是不需要互联网功能的,我们称作离线识别。
在线识别方式
先看第一种,在线识别的方式。在线识别方式最大的优点就是,它在初次进行文字识别的时候,准确率非常高。比如对聊天截图中的识别准确率就高达 99%。因为在线识别使用了人工智能领域的深度学习算法和文字识别相结合的技术,能够把图片转换成文字后,还能在语义上把相近的字进行二次纠正。
比如说,被识别的内容包含英文单词“Hello”,一旦它的字母“o”被识别成数字“0”,在线识别软件就会根据上下文语境把这类错误纠正回来,而这种二次纠正的功能在离线识别软件中是没有的。
不过在线识别软件也有它的缺点,那就是识别文字的过程需要在公有云的服务器上完成。也就是说需要通过互联网把图片上传到服务器,那么一旦图片过大,或者图片数量比较多,就会导致上传时间过长。我们知道,一张高清图片至少有 3MB 大小,根据个人的网络情况至少要达到秒级上传才行。这就意味着在大批量文字识别的场景中,或对实时性要求很高的场景下,在线识别是不能满足要求的。另外,图片需要经过互联网传输,识别以后的图片该怎么保存,怎么销毁,是不是会被其他人得到,这些都是安全风险。
总之,信息泄露的风险比较大。所以像公司的合同、财务资料等涉密程度比较高的扫描件,很少使用在线识别。
实现案例
举个例子,百度云的 AI 产品,你可以在终端下执行这样一个命令来进行安装。
pip install baidu-aip
在这里我使用了百度云提供的在线文字识别产品,它提供了一个 baidu-aip 的安装包,安装之后提供了 AipOcr 函数实现用户验证、client.basicGeneral 函数实现文字识别功能。代码如下:
from aip import AipOcr
""" 你的 APPID AK SK """
# APP_ID = '你的 App ID'
# API_KEY = '你的 Api Key'
# SECRET_KEY = '你的 Secret Key'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('example.png')
""" 调用通用文字识别, 图片参数为本地图片 """
result = client.basicGeneral(image)
print(result)
在代码的第一行,我使用了一个 AipOcr 库。AipOcr 是百度云提供给用户的 OCR Python SDK 客户端,能够让你用 Python 语言和百度云进行交互。一般情况下,我们进行用户认证、图片上传至服务器功能,都需要自己编写很多代码,但是使用 AipOcr 库之后,这些基础功能都被封装好了。
你只需要填写三个变量,就能正式进入文字识别的环节了:
第一个变量是 APP_ID,它用来识别应用;
第二个变量是 API_KEY,用于识别用户;
第三个变量是 SECRET_KEY ,用来加密密钥。
当把这三个变量传入 AipOcr 函数,使用 AipOcr 函数通过互联网交互后,就可以用来识别用户是不是被授权使用相应的产品,之后就可以把图片加密发送到 AI 产品的服务器上了。
第一步, 安装 SDK。代码是:pip install baidu-aip
第二步,注册用户。以百度云为例,你需要登录 https://ai.baidu.com/ 网址,以自己的手机为用户名注册一个新的用户。
第三步,申请应用。成功登录网站之后,你会进入服务控制台界面,然后选择文字识别功能,再新创建一个文字识别类型的应用。创建应用之后,就可以在服务控制台中的应用列表中查看百度云提供的 APP_ID、API_KEY、SECRET_KEY 三个变量。在这三个变量中,APP_ID 在百度云的控制台中创建用户之后会自动创建。
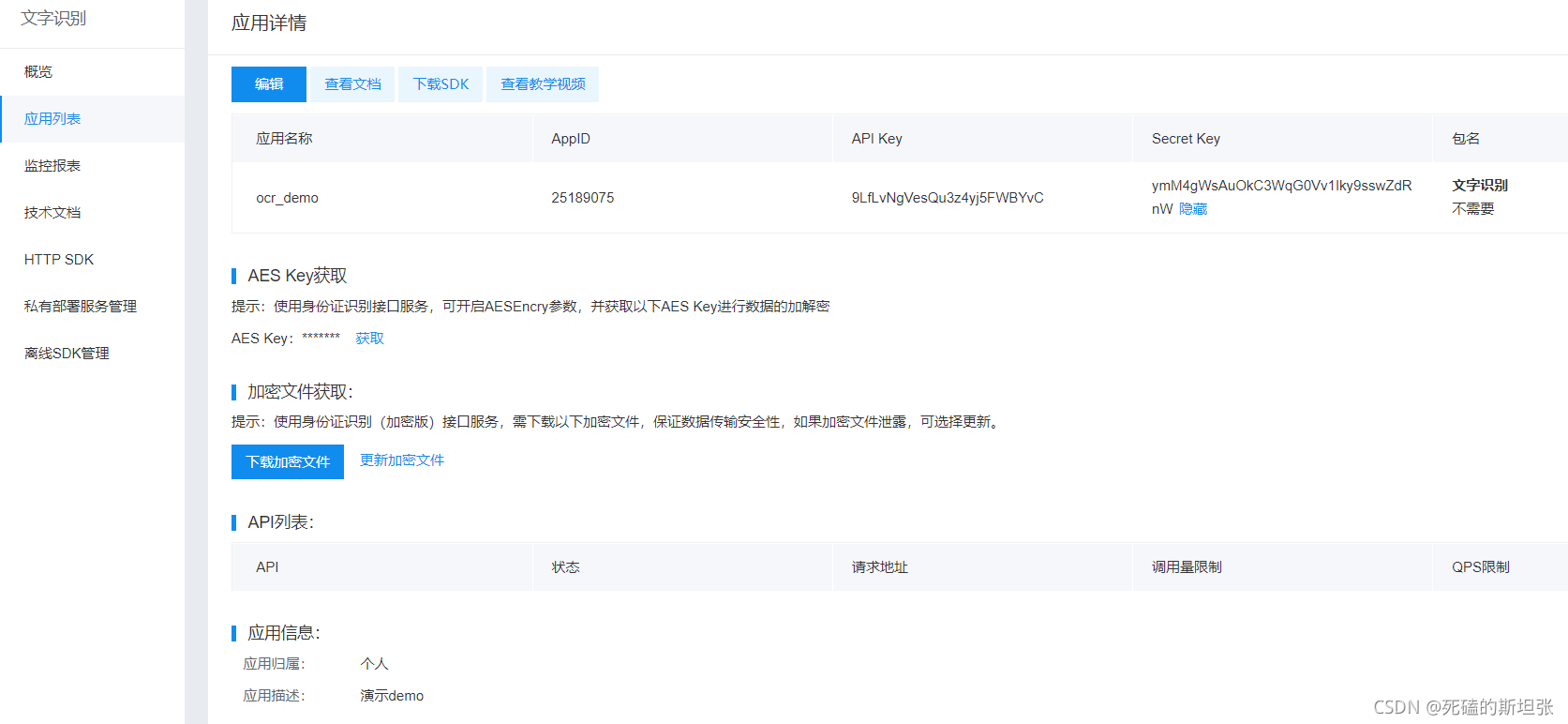
完成以上三个步骤之后,我们需要把指定路径的图片上传到百度云,通过第 12 行的 get_file_content 函数,把图片的路径和名称作为参数传入这个函数之后,再交给 client.basicGeneral(image) 函数处理,这样就能够完成图片的上传功能了,图片的识别和返回结果都会由 AipOcr 包自动处理以后放入 result 变量中。
离线识别方式
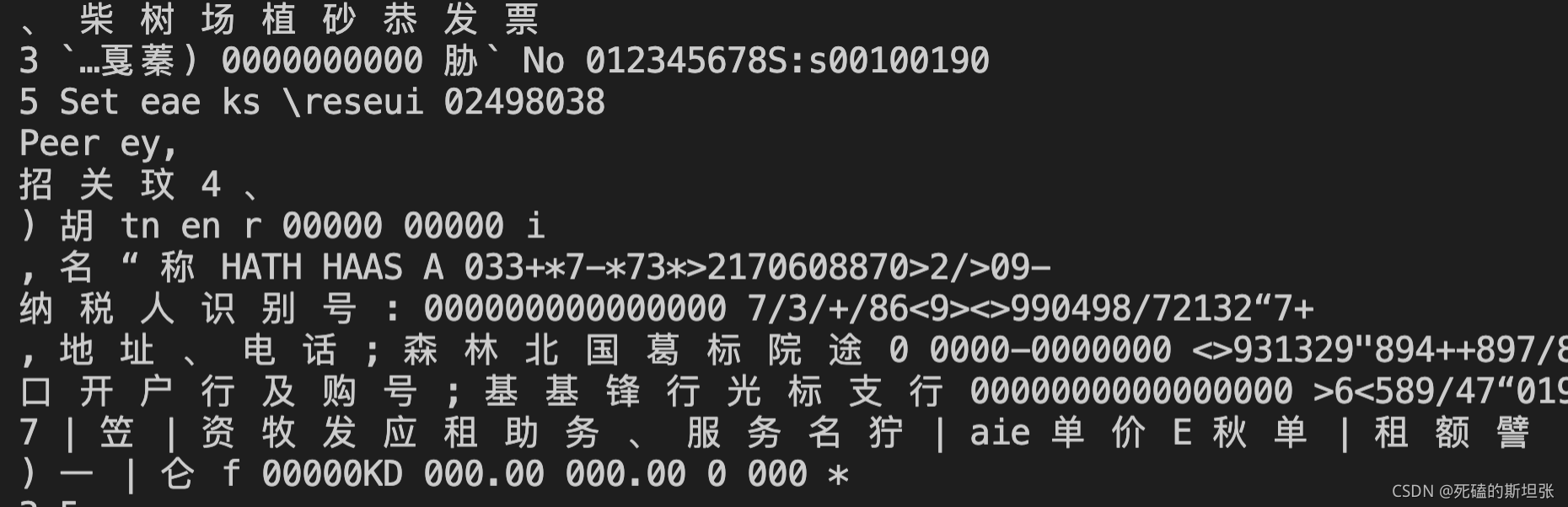
再看第二种,离线识别的方式。这种方式在识别过程中不需要连接网络,节省了在线传输图片的时间,适合那些对实时性要求比较高或网络信号比较差的场景。但是离线识别方式的问题就在于,初次识别文字的准确率比较低,识别完之后必须要经过人工二次纠正才行。所以在前期人工校对,花费的时间相对来说会比较长。
实现案例
import pytesseract
from PIL import Image
# 打开图片
image = Image.open('example.png')
# 转为灰度图片
imgry = image.convert('L')
# 二值化,采用阈值分割算法,threshold为分割点,根据图片质量调节
threshold = 150
table = []
for j in range(256):
if j < threshold:
table.append(0)
else:
table.append(1)
temp = imgry.point(table, '1')
# OCR识别:lang指定中文,--psm 6 表示按行识别,有助于提升识别准确率
text = pytesseract.image_to_string(temp, lang="chi_sim+eng", config='--psm 6')
# 打印识别后的文本
print(text)
在进行离线识别的时候,有一个现成的文字识别库,那就是 pytesseract 库,这个库实现了对图片中的文字识别功能。使用 pytesseract 库,可以自动实现文字的切分和识别功能,识别效果如下