新人全面学习了解Python
一篇文章告诉你python的一切,Know EveryThing!
本文旨在概述 Python 编程语言的所有关键点,力图用最简短、专注的语言去解释最重要、需要的主题。
阅读此文不需要具备任何先前的编程知识就可以很快掌握所有必需的概念。
欢迎收藏、关注,点赞支持!pythontip 出品,Happy Coding!
接下来,通过介绍 Python 编程语言的热门讨论问题,逐步建立知识。
读完此文后,希望你将对Python有一个透彻的了解,能够使用任何 Python 库或者改善自己的Python程序。
下面包含 25 个关键主题,开始吧!少年,长文预警。
1. 介绍Python
什么是 Python?
- 解释型的、高级的、面向对象的、动态类型的脚本语言。
- 因此,通常会遇到运行时的错误。
为什么是 Python?
- Python 是最流行的语言,因为它更容易编码和理解。
- Python 是一种面向对象的编程语言,也可用于编写函数式代码。
- 它是一种合适的语言,可以在业务和开发人员之间架起桥梁。
- 与 C#/Java 等其他语言相比,将 Python 程序推向市场所需的时间更少。
- 有大量的python机器学习和分析包。
- 大量社区和书籍可用于支持 Python 开发人员。
- 几乎所有类型的应用程序,从预测分析到 UI,都可以用 Python 实现。
- 不需要声明变量类型。因此,实现 Python 应用程序会更快。
为什么不是 Python?
- Python 比 C++、C#、Java 慢。这是因为 Python 中缺少 Just In Time 优化器。
- Python 语法空白约束使新编码人员难以实现。
- Python 不像 R 那样提供高级统计功能。
- Python 不适合低级系统和硬件交互。
Python 是如何工作的?
下图说明了 python 如何在我们的机器上运行:
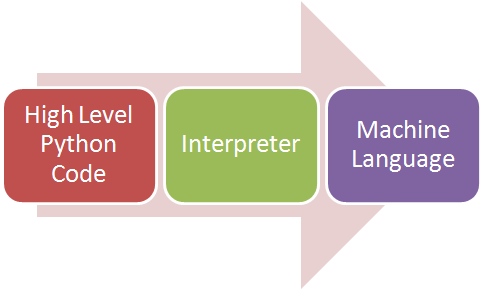
这里的关键是Interpreter,负责将高级Python语言翻译成低级机器语言。
Python的工作方式如下:
- 在安装包(库)的地方创建一个 Python 虚拟机。(我们可以将虚拟机视为容器。)
- 然后将 python 代码写入
.py文件中 - CPython 将 Python 代码编译为字节码。此字节码用于 Python 虚拟机。
现在,这个虚拟机依赖于机器,但 Python 代码不是。
- 当你想执行字节码时,代码将在运行时被解释。然后代码将从字节码转换为机器代码。字节码不依赖于运行代码的机器。这使得 Python 与机器无关。
Python 字节码依赖于 Python 虚拟机,这使得 Python 机器独立。
因为Python是垮平台的,我们可以在一个操作系统中编写 Python 代码,将其复制到另一个操作系统中并简单地运行它。
2. 变量 —— 对象类型和范围
- 变量用来存储程序中需要使用和[或]需要更改的信息。此信息可以是整数、文本、集合等。
- 变量用于保存用户输入、程序的本地状态等。
- 变量有一个名称,以便它们可以在代码中被引用。
- 要理解的基本概念是 Python 中的一切都是对象。
Python 支持数字、字符串、集合、列表、元组和字典。这些是标准数据类型。我将详细解释它们中的每一个。
声明和赋值
myFirstVariable = 1
mySecondVariable = 2
myFirstVariable = "Hello You"
在上面的示例中,我们已将值1赋值给变量myFirstVariable。
请注意,可以将整数值 1 和字符串值“Hello You”分配给同一个 myFirstVariable 变量。
这是由于在 python 中,数据类型是动态的。 这也是 Python 被称为动态类型编程语言的原因。
如果要将相同的值分配给多个变量,则可以使用链式赋值:
myFirstVariable = mySecondVariable = 1
数字
- 支持整数、小数、浮点数。
value = 1 # 整数
value = 1.2 # float 带浮点数
- 支持常类型,它们的后缀为
L,例如:9999999999999L
字符串
- 文本信息。
- 字符串是一个字符数组。
- 字符串用引号括表示。可以是单引号、双引号或三引号。
name = 'farhad'
name = "farhad"
name = """farhad"""
- 字符串是不可变的。一旦它们被创建,它们就不能改变,例如:
a = 'me'
# 试图改变a,将会报错
a[1]='y'
# It will throw a Type Error
- 当字符串变量被分配一个新值时,python内部会创建一个新对象来存储该值,然后创建了一个指向对象的引用/指针,并将该指针指配给该字符串变量,因此可以使用该变量。也可以将一个变量赋值给另一个变量。它所做的只是创建一个指向同一个对象的新指针。
a = 1 # 创建新对象并在那里存储1,创建新指针,指针将a连接到1
b = a # 没有创建新的对象,创建了将 b 连接到 1 的新指针。
局部变量和全局变量
局部变量
- 在函数中声明的变量只存在于函数块中。
- 在函数块之外,变量不可用。
def some_funcion():
TestMode = False
print(TestMode) #中断报错:因为外部不存在这个变量
在 Python 中,if-else 和 for/while 会创建全局变量:
for i in range(1, 11):
test_scope = "variable inside for loop"
print(test_scope)
#输出:variable inside for loop
is_python_awesome = True
if is_python_awesome:
test_scope = "Python is awesome"
print(test_scope)
#输出:Python is awesome
全局变量
- 可以从任何函数访问。它们存在于 main 框架中。
- 可以在函数之外声明一个全局变量。请务必注意,要为全局变量指配一个新值,必须使用global关键字:
TestMode = True
def some_function():
global TestMode
TestMode = False
some_function()
print(TestMode) #全局变量在函数中被修改了。返回 False
删除global TestMode行只会在 some_function() 函数中将变量设置为False,但不影响全局变量。
注意:如果你想在多个模块之间共享一个全局变量,那么可以创建一个共享模块文件,例如 configuration.py 并在那里找到你的变量。最后,在使用者模块中导入共享模块。
输出变量类型
- 如果要查看变量的类型:
type('farhad')
# 返回: <type 'str'>
用逗号来定义多个变量
a, b ,c = 9,8,7 #三个数值变量
3. 运算操作
- 变量是可以运算的
数值运算
- Python 支持基本的
*、/、+、- - Python 也支浮点数除法
1//3 #返回 0
1/3 #返回 0.333
- 注意:除法的返回类型总是浮点数,如下:
a = 10/5
print(type(a)) #输出:float
- 此外,python 支持通过
*运算符取幂:
2**3 = 2 * 2 * 2 = 8
- Python 也支持取模(余数)运算符:
7%2 = 1
还有一个 divmod 内置方法。它返回整数结果和余数:
print(divmod(10,3)) #返回(3,1)
字符串操作
连接字符串:
print('A' + 'B') # 结果为'AB'
记住字符串是一种不可变的数据类型,因此,连接字符串会创建一个新的字符串对象。
复制字符串:
print('A'*3) # 将重复 A 三遍:AAA
切片:
y = 'ABC'
y[:2] # 'AB'
y[1:] # 'BC'
y[:-2] # 'A'
y[-2:] # 'BC'
反转:
x = 'abc'
x[::-1] #输出:'cba'
倒序索引:
如果要从最后一个字符开始,请使用负索引。
y = 'abc'
print(y[:-1]) # 返回ab
数组中的每个元素都有两个索引:
- 从左到右,索引: 0,1,2
- 从右到左,索引: -1,-2,-3
- 因此,如果我们执行 y[0] 和 y[-len(y)] 那么两者都将返回相同的值:‘a’
y = 'abc'
y[0] # 返回 'a'
y[-len(y] # 返回 'a'
查找索引
name = 'farhad'
index = name.find('r') #index为2
name = 'farhad'
index = name.find('a', 2) # index为第二个a的索引,即4
对于模式匹配,请使用:
split():通过正则表达式将一个字符串拆分成一个列表sub():通过正则表达式替换匹配的字符串subn():通过正则表达式替换匹配的字符串并返回替换次数
转化
str(x): 转为字符串int(x): 转为整数float(x): 转为浮点数x.upper():转化为大写x.lower():转化为小写
集合操作
- 集合是没有任何重复项的无序数据集合。我们可以定义一个集合变量为:
set = {
9,1,-1,5,2,8,3, 8}
print(set)
这将打印:{1, 2, 3, 5, 8, 9, -1}
注意: 重复项被删除。
集合是一个包含元素的项目,可以使用:len(set)获取元素的个数,也可也是用 for item in set,遍历集合中的元素。
但是它不支持索引,以及切片。
一些重要的集合操作是:
set.add(item)— 增加元素set.remove(item)— 移除元素,不存在会报错set.discard(item)— 如果存在则移除set.pop()— 返回集合中的一个元素,如果集合唯为空则报错set.clear()清空集合
交集
a = {
1,2,3}
b = {
3,4,5}
c = a.intersection(b) # c = {3}
print(c)
差集
a = {
1,2,3}
b = {
3,4,5}
c = a.difference(b) # c = {1,2}
print(c)
并集
a = {
1,2,3}
b = {
3,4,5}
c = a.union(b) # c = {1,2,3,4,5}
print(c)
三元操作
x = 'No'
Received = True if x == 'Yes' else False
print(Received)
4. 注释
单行注释
#这是单行注释
多行注释
- 使用三个单引号或者三个双引号
"""这是多行注释"""
'''这也是多行注释'''
5. 表达式
逻辑运算生产表达式,例如:
- 等于:
== - 不等于:
!= - 大于:
> - 小于:
< - 大于或等于
>= - 小于或等于
<=
6. 对象存储
用pickling 来处理 将对象转换为字符串 或者 将字符串转储为二进制文件
7. 函数
- 函数是可以在代码中执行的语句序列。如果发现某段代码可以重复利用,则创建的函数并在程序中多次使用它。
- 函数还可以调用其他函数。
- 函数消除了代码中的重复。这使得调试和发现问题变得更加容易。
- 最后,函数使代码易于理解和管理。
- 简而言之,函数允许我们将大型应用程序拆分为更小的块。
定义函数
def my_new_function():
print('这是我的新功能')
调用函数
my_new_function()
系统函数
例如:调用len(x) 函数
len('你好') # 输出2
参数
- 可以向函数添加参数以使函数具有通用性。
- 可以将变量传递给函数,并且函数可以使用这些变量。
def my_new_function(my_value):
print('这是我的新函数,带有 ' + my_value)
print(my_new_function("pythontip"))
- 可选参数:
可以通过为参数提供默认值来传递可选参数:
def my_new_function(my_value='hello'):
print(my_value)
my_new_function() #输出 hello
my_new_function('test') #输出 test
- 可变参数:
如果你的函数需要 不定量参数 则在参数名称前添加 *:
def myfunc(*arguments):
return arguments
myfunc(a) # 输出 (a,)
myfunc(a,b) # 输出 (a,b)
myfunc(a,b,c) # 输出 (a,b,c)
- 关键字参数:
如果你的函数需要 关键字参数 则在参数名称前添加 **:
def test(*args, **kargs):
print(args)
print(kargs)
print(args[0])
print(kargs.get('a'))
alpha = 'alpha'
beta = 'beta'
test(alpha, beta, a=1, b=2)
# 输出如下:
"""
('alpha', 'beta')
{'a': 1, 'b': 2}
alpha
1
"""
返回
- 函数可以返回值,例如:
def my_function(input):
return input + 2
- 如果一个函数需要返回多个值,那么我们返回一个元组(逗号分隔值)。稍后我将解释元组:
def get_result():
return 'a',1
resultA, resultB = get_result()
# get_result() can return ('a', 1) which is a tuple
print(resultA, resultB)
特殊函数:lambda
- 单表达式匿名函数。
- 它是一个内置函数。
my_lambda = lambda x,y,z : x - 100 + y - z
my_lambda(100, 100, 100) # 返回 0
== 和 is
var1 = "a"*30
var2 = "a"*30
print('var1: ', id(var1)) #318966315648
print('var2: ', id(var2)) #168966317364
print('== :', var1 == var2) #returns True
print('is :', var1 is var2) #returns False
8. 模块
什么是python模块
- Python 附带了 200 多个标准模块。
- 模块是将 Python 解决方案的类似功能分组的组件。
- 任何python代码文件都可以打包成一个模块然后导入。
- 模块鼓励组件化设计。
- 提供了命名空间的概念来共享数据和服务。
- 模块鼓励代码可重用性并减少变量名称冲突。
python 路径
- 此环境变量指示 Python 解释器需要导航以定位模块的位置。PYTHONHOME 是另一种模块搜索路径。
如何导入模块
import MyFirstPythonFile
print(my_module.my_object)
注意:如果不希望解释器在加载时执行模块,可以检查
__name__ == '__main__'
来源
- 如果您只想从模块访问对象或模块的一部分,那么您可以实现:
从 my_module 导入 my_object
- 这将使您能够在不引用您的模块的情况下访问您的对象:
打印(我的对象)
- 我们也可以从 * 导入所有对象
从 my_module 导入 *
注意:模块仅在第一次导入时导入。
- 如果你想在 C 中使用 Python 模块:
使用 PyImport_ImportModule(module_name)
命名空间 — 两个具有相同对象名称的模块:
如果我们想使用在两个不同模块中定义的相同名称,请使用 import over from。
9. 包
- 包是模块的目录
- 包使我们能够更好地组织模块,有助于更轻松地解决问题和查找模块。
- 可以将第三方包导入到代码中,例如
pandas和tensorflow等等。 - 一个包可以包含大量的模块。
from packageroot.packagefolder.my_module import my_object
在上面的例子中,packageroot是根文件夹。packagefolder 是 packageroot 下的子文件夹。my_module 是packagefolder 文件夹中的模块 python 文件。 此外,文件夹的名称可以作为命名空间,例如
from data_service.database_data_service.microsoft_sql.mod
注意:init.py 文件是在导入模块之前导入的,因此您可以添加自定义逻辑,例如启动服务状态检查或打开数据库连接等。
- PIP 是一个 Python 包管理器。
- 使用 PIP 下载软件包:
pip install package_name
10. 条件
IF-ELSE
a = 1
b = 20
if a == b:
print('a is b')
elif a < b:
print('a is less than b')
elif a > b:
print('a is greater than b')
else:
print('a is different')
类型检查
my = '12'
if not isinstance(my, int):
print('Expected int')
return None
嵌套
a = 1
b = 20
if a == b:
print('a is b')
else:
if a == 2:
print('within if of else')
else:
print('within else of else')
11. 循环
while
input = 10
while (input < 0):
do_something(input)
input = input-1
for
for i in range(0,10): # 按次数
print(i)
for i in 'hello': # 按元素
print(i)
行表达式
ret = [i**2 for i in range(0,10)]
print(ret)
带IF的for
name = 'onename'
anothername = 'onenameonename'
for character in name:
if character in anothername
print(character)
break
for i in range(0,10):
if (i==5):
break
while True:
x = get_value()
if (x==1):
break
12.递归
调用自身的函数称为递归。
例1:
# 0!= 1 #0 的因数是 1
# n!= n(n-1)!#n的阶乘是 n * n-1 的阶乘
# 创建一个名为 factorial 的函数,输入为 n
# 如果 n = 0 返回 1 否则做 n-1 的 nx 阶乘
def factorial(n):
if n==0:
return 1
else:
return n * factorial(n-1)
例2:
# 前两位数字是 0 和 1
# 其余加最后两位数
# 创建一个名为 fibonacci 的函数,它接受输入 n
# 创建两个变量 first 和 second 并为它们分配值 0 和 1
# 如果 n =0 返回 0,如果 n = 1 返回 1 否则返回 (n-1) + (n-2)
def fibonacci(n):
if (n<=1):
return n
else:
return fibonacci(n-1)+fibonacci(n-2)
print(fibonacci(6))
退出时进行检查很重要,否则该函数将进入无限循环。
13. 帧和调用栈
- Python 代码被加载到位于堆栈中的帧中。
- 函数与参数和变量一起加载到框架中。
- 随后,帧以正确的执行顺序加载到堆栈中。
- 堆栈概述了函数的执行。在函数外声明的变量存储在 main 中
- 堆栈首先执行最后一帧。
如果遇到错误,可以使用回溯来查找函数列表。
14. 常用数据类型
列表
- 列表是可以保存任何数据类型的值序列的数据结构。它们是可变的(可更新)。
- 列表由整数索引。
- 要创建列表,请使用方括号:
my_list = ['A', 'B']
- 要添加/更新/删除项目,请使用索引:
my_list.append('C') # 在列表最后增加一个元素
my_list[1] = 'D' # 更新
my_list.pop(1) # 移除索引为 1 的元素
del my_list[1:2] # 移除索引 1 到 2 的元素(不包含2)
my_list.extend(another_list) # 在列表最后增加另一个列表的所有元素
- 加法、重复和切片可以应用于列表(就像字符串一样)。
- List 也支持排序
my_list.sort() #列表本身排序,返回值为None
关于 pop() 的注意事项:
- 从末尾弹出一个元素,时间复杂度为
O(1) - 从开始弹出一个元素,时间复杂度为
O(n)
如果需要频繁删除索引位置0,请使用collections.deque.
元组
- 元组就像列表,因为它们可以存储一系列对象。同样,对象可以是任何类型。
- 元组比列表更快。
- 这些集合由整数索引。
- 元组是不可变的(不可更新)
my_tuple = tuple()
my_tuple = 'f','m'
my_tuple = ('f', 'm')
注意:如果元组包含一个列表,那么可以修改该列表。此外,如果为对象分配值并将对象存储在列表中,然后更改对象,则列表中的对象将得到更新。
字典
- 字典是编程世界中最重要的数据结构之一。它存储键/值对对象。
- 它有很多好处,例如优化的数据检索功能。
my_dictionary = dict()
my_dictionary['my_key'] = 1
my_dictionary['another_key'] = 2
- 创建一个字典:
my_dictionary = {
'my_key':1, 'another_key':2}
- 打印字典内容
for key in dictionary:
print(key, dictionary[key])
- 字典的值可以是任何类型,包括字符串、数字、布尔值、列表甚至字典。
dictionary.items() # returns items
#checking if a key exists in a dictionary
if ('some key' in dictionary):
#do something
pass
几个重要的功能:
get(key, default) # 取值,如果不存在,返回默认值
pop(key, default) # 删除,并返回。如果不存在,返回默认值
popitem() # 随机删除
dictionary1.update(dictionary2) # 合并两个字典
- 如果要对列表执行矢量化/矩阵操作,请使用 NumPy Python 包
15.编译和链接
编译
- 只要编译器支持,这些功能可用于使用用另一种语言(例如 C 或 C++ 等)编写的文件。
- 将代码写入文件后,即可将该文件放置在发行版的 Modules 目录中。
- 在 Setup.local 文件中添加一行很重要,以确保可以加载新创建的文件。使用 spam file.o 运行文件
- 更改文件需要运行rebuildMakefile
汇编:
- 允许编译新扩展而没有任何错误
链接:
- 一旦扩展被编译,它们就可以被链接。
16. 迭代器
iter
- 允许遍历集合
- 所有迭代器都包含 iter() 和 next() 函数
- 列表、字典、字符串或集合是可迭代的。
- 当
X = iter(Y)时,X将是Y的迭代器,next(X)获取下一个迭代。 - 如果集合中有大量项目并且不打算一次将所有文件加载到内存中,则迭代器很有用。迭代器具有内存效率,可以表示无限流。
- 有一些常见的迭代器使开发人员能够实现函数式编程语言范式:
filter
- 根据条件过滤掉值
map
- 对集合的每个值应用计算。它将一个值映射到另一个值,例如将文本转换为整数。
reduce
- 将一组值减少到一个单一值(或更小的集合),例如集合的总和。它本质上可以是迭代的。
zip
- 获取多个集合并返回一个新集合。
- 新集合包含项目,其中每个项目包含来自每个输入集合的一个元素。
- 它允许我们同时横向多个集合
name = 'farhad'
suffix = [1,2,3,4,5,6]
zip(name, suffix)
# 返回 (f,1),(a,2),(r,3),(h,4),(a,5),(d,6)
enumerate
- enumerate 可以遍历一个可迭代对象,并为每个元素返回一个自动索引:
for index, element in enumerate(iterator):
pass
迭代器要求我们实现两个关键方法:__iter__()、__next__()。
此外,当没有要返回的值时,需要引发 StopIteration。
我们可以使用Generator使函数返回迭代器。所要做的就是使用yield关键字而不是return。关键是一次产生一个项目。
17. 面向对象设计 —— 类
- Python 允许我们创建自定义类型。这些用户定义的类型称为类。类可以具有自定义属性/属性和函数。
- 面向对象的设计允许程序员将他们的业务模型定义为具有所需属性和功能的对象。
- 一个属性也可以引用另一个对象。
- Python 类可以引用其他类。
- Python 支持封装——实例函数和变量。
- Python 支持继承。
class MyClass:
def MyClassFunction(self): # 引用自身
return 5
m = MyClass() # 实例对象
returned_value = m.MyClassFunction() # 调用实例函数
- 类的实例称为对象。对象是可变的,一旦创建对象,它们的属性就可以更新。
__init__
__init__函数存在于所有类中。当我们需要实例化一个类的对象时,它会被执行。它可以接受我们想要设置的任何属性:
class MyClass:
def __init__(self, first_property):
self.first_property = first_property
def MyClassFunction(self):
return self.first_property
m = MyClass(123)
r = m.MyClassFunction() # r = 123
重载
-
可以通过提供更多参数作为实例来重载对象的方法。如
__str__,__camp__ -
我们还可以通过实现自己的
__add__实现来重载一个运算符,例如 +
对象的浅拷贝与深拷贝
- 等效对象 - 包含相同的值
- 相同的对象——引用相同的对象——内存中的相同地址
- 如果要复制整个对象,则可以使用
copy模块
import copy
m = MyClass(123)
mm = copy.copy(m)
- 这将导致浅复制,因为将复制属性的引用指针。
- 因此,如果对象的属性之一是对象引用,那么它将简单地指向与原始对象相同的引用地址。
- 因此,更新源对象中的属性将导致更新目标对象中的属性。
- 因此浅拷贝复制引用指针。
- 幸运的是,我们可以利用深拷贝:
import copy
m = MyClass(123)
mm = copy.deepcopy(m)
- 如果 MyClass 包含引用 MyOtherClass 对象的属性,则该属性的内容将通过
deepcopy复制到新创建的对象中。 - 因此,深拷贝对对象进行了新的引用。
18. 面向对象设计 —— 继承
- Python 支持对象继承。因此,对象可以继承其父对象的功能和属性。
- 继承的类可以在其函数中包含不同的逻辑。
- 如果您有一个类:
ParentClass和 两个子类:SubClass1、SubClass2, 那么可以使用 Python 将类创建为:
class ParentClass:
def my_function(self):
print('I am here')
class SubClass1(ParentClass):
pass
class SubClass2(ParentClass):
pass
- 像上面的定义:两个子类都将包含函数
my_function()。 - 继承可以提高代码的可重用性和维护性。
- 注意:与 C# 不同的是 Python 支持多重继承
- 使用 Python 的
abc模块可以确保所有子类都包含抽象基类所需的功能。
# A 同时继承 B and C
class A(B,C):
pass
- 如果要调用父类函数,则可以执行以下操作:
super(A, self).function_name()
我们应该熟悉常见的内部方法:
__str__(self):该函数返回一个用户友好的值来表示对象。__repr__(self):该函数返回一个对开发人员友好的值来表示对象。如果__str__()丢失,则调用__repr()__。__eq__(self, other):该函数返回两个对象是否相等。
class Human:
def __init__(self, name, friends=[]):
self.name = name
self.friends = friends
def __str__(self):
return f'Name is: {
self.name}'
def __repr__(self):
return 'Human({self.name}, {self.friends})'
def __eq__(self, other):
return self.name == other.name
human = Human('Farhad', ['Friend1', 'Friend2'])
print(human)
上面代码将打印:Name is: Farhad
如果我们删除 __str__ 函数,那么它将调用 __repr__ 代替:
这将打印: Human(Farhad, ['Friend1', 'Friend2'])
如果创建两个具有相同名称和不同朋友的人类实例,根据__eq__ 函数的定义,它们是相等的:
human1 = Human('Farhad', ['Friend1', 'Friend2'])
human2 = Human('Farhad', ['ABC', 'DEF'])
print(human1 == human2) #prints True
19. 垃圾回收——内存管理
- Python 中的所有对象都存储在堆空间中。Python 解释器可以访问此空间。它是私有的。
- Python 有一个内置的垃圾收集机制。
- 这意味着 Python 可以自动为程序分配和取消分配内存。跟 C++ 或 C# 一样。
- 它的职责是清除程序中未引用/使用的那些对象的内存空间。
由于多个对象可以共享内存引用,python 采用了两种机制:
- 引用计数:计算对象被引用的项目数,如果计数为 0,则取消分配对象。当变量被分配给对象或作为参数传递给任何方法时,引用会增加。
- 第二种机制处理循环引用,也称为循环引用,通过仅取消分配分配数量大于阈值的对象。
- 新对象是在 Python 的第 0 代中创建的。他们可以通过以下方式进行检查:
import gc
collected_objects = gc.collect()
- 手动垃圾收集可以在及时或基于事件的机制上执行。
- 当 Python 程序存在时,Python 会尝试删除全局对象和具有循环引用的对象。
20. 输入/输出
键盘
user_says = raw_input()
print(user_says)
文件
- 使用
with/as语句打开和读取文件。它等效于 C# 中的 using 语句。 with语句可以处理连接的关闭和其他清理活动。
with open(file path, 'r') as my_file:
for line in my_file
# File is closed due to with/as
注意:也可以用
readline()来读取文件的一行。
打开两个文件:
with open(file path) as my_file, open(another path) as second_file:
for (line number, (line1, line2)) in enumerate(zip(my_file, second_file):
写文件:
with open(file path, 'w') as my_file:
my_file.write('test')
文件模式
rw— 读写模式r— 读取模式rb— 以二进制格式读取,例如pickle 文件r+— 以读取和写入模式读取a— 附加模式。w+— 用于读写,如果文件存在则覆盖
SQL
打开连接
import MySQLdb
database = MySQLdb.connect(
host=server,
user=username,
password=password,
db=database)
cursor = database.cursor()
执行一条 SQL 语句
cursor.fetch("Select * From MyTable")
database.close()
Web Services
请求服务
import requests
url = 'http://myblog.com'
response = requests.get(url).text
JSON
反序列化:
import json
my_json = {
"A":"1","B":"2"}
json_object = json.loads(my_json)
value_of_B = json_object["B"]
序列化:
import json
a = "1"
json_a = json.dumps(a)
21. 错误处理
抛出异常
try:
raise TypError
except:
print('exception')
捕捉异常
try:
do_something()
except TypeError:
print('exception')
try:
do_something()
except TypeError:
print('exception')
finally:
close_connections()
- try/catch/finally:
try:
do something
except IfTryRaisedException1:
do something else
except (IfTryRaisedException2, IfTryRaisedException3)
if exception 2 or 3 is raised then do something
else:
no exceptions were raised
- 不管最终还是触发了部分代码,都可以使用
finally来关闭与数据库/文件等的连接。
Try/Except/Else
try:
do something
except IfTryRaisedException1:
do something else
except (IfTryRaisedException2, IfTryRaisedException3)
if exception 2 or 3 is raised then do something
else:
no exceptions were raised
else在没有引发异常时执行。- 还可以通过执行以下操作为变量分配异常:
try:
do something
except Exception1 as my_exception:
do something about my_exception
- 使用
assert自定义的约束:
assert <bool>, 'error to throw'
注意:Python 的Exception 支持继承
通过以下方式创建自己的异常类:
class MyException(Exception):
pass
22. 多线程和 GIL
- GIL 是全局解释器锁。
- 它确保线程可以在任何时间执行,并允许 CPU 周期选择要执行的所需线程。
- GIL 被传递到当前正在执行的线程上。
- Python 支持多线程。
注意:GIL 会增加执行的开销。因此,请确保真的需要多个线程。
23. 装饰器
- 装饰者可以为代码添加功能。它们本质上是调用其他对象/函数的函数。
- 装饰器是可调用的函数 —— 因此当被装饰的函数被调用时,它们返回稍后要调用的对象。
- 可以包装一个类/函数,然后在任何时候调用该函数时都会执行特定的代码。
- 可以实现通用逻辑来记录日志、检查安全检查等功能。
- 要理解的最重要的概念是,在 Python 中,函数是对象。这意味着一个函数可以返回另一个函数,一个函数可以将另一个函数作为参数。我们也可以在另一个函数中定义一个函数。函数也可以分配给变量。
理解装饰器:
本质上,装饰器是一个函数。它接受另一个函数作为参数。它还返回一个函数。了解一下步骤:
- 装饰器是一个函数,它接受一个函数作为输入并返回一个内部函数:
def my_decorator(input):
def my_inner_decorator(*args, **kwargs):
print('Hi pyedu')
input(*args, **kwargs)
print('Bye pyedu')
return my_inner_decorator
-
装饰器的input 就是装饰器要装饰的函数。
-
内部函数是对输入函数执行适当动作然后装饰器返回内部函数的函数。
要使用装饰器,请使用 @ 符号:
def my_decorator(input):
def my_inner_decorator(*args, **kwargs):
print('Hi pyedu')
input(*args, **kwargs)
print('Bye pyedu')
return my_inner_decorator
@my_decorator
def print_num(number):
print('inside function:',number)
print_num(1)
""" # 输出内容如下:
Hi pyedu
inside function: 1
Bye pyedu
"""
如果需要,还可以将其他参数传递给装饰器。
24. Python 中的单元测试
- Python中有许多可用的单元测试和模拟库。
- 使用unittest:
代码:
def my_function(input):
return input-1
测试:
import unittest
class TestClass(unittest.TestCase):
def my_test(self):
self.assertEqual(my_function(1), 0)) # 测试输入1是否得到0
还可以使用doctest来测试用 docstrings 编写的代码。
25. 热门 Python 问题
为什么要使用 Python?
- 易于编码和学习
- 面向对象的编程语言
- 出色的第三方报,如机器学习库
- 更快地开发代码
- 提供内置的内存管理
- 巨大的社区支持和应用程序可用
- 无需编译,因为它是一种解释性语言
- 动态类型——无需声明变量
如何让 Python 跑得快?
- Python 是一种高级语言,不适合访问系统级程序或硬件。
- 此外,它不适合跨平台应用程序。
- 与低级语言相比,Python 是一种动态类型解释语言的事实使其优化和运行速度较慢。
- 实现基于 C 语言的扩展。
- 使用 Spark 或 Hadoop 创建多进程
- 利用 Cython、Numba 和 PyPy 来加速您的 Python 代码或用 C 编写它并像 NumPy 一样在 Python 中公开它
人们使用哪些 IDE?
- Spyder,PyCharm。此外还使用了各种笔记本,例如 Jupyter
有哪些专业的 Python 框架和包?
- PyUnit (unit testing), PyDoc (documentation), SciPy (algebra and numerical), Pandas (data management), Sci-Kit learn (ML and data science), Tensorflow (AI), Numpy (array and numerical), BeautifulSoap (web pages scrapping), Flask (microframework), Pyramid (enterprise applications), Django (UI MVVM), urllib (web pages scraping), Tkinter (GUI), mock (mocking library), PyChecker(bug detector), Pylint (module code analysis)
如何执行python程序?
-
Unix: 在python脚本最前面加上
#!/usr/bin/env python -
在命令行中执行python脚本
-
使用 PyPRI or PyPI 执行python脚本
如何在python中使用R?
- 在R里面有大量的统计分析工具
- 在python里面可以用rpy2调用R,也可以在jupyter notebook里面运行R。
如何在python运行前,先检查一下代码是否有错误?
- 可以用 PyChecker 或者 PyLink
小结
这篇文章以简明扼要的方式突出概述了 Python 中最重要的 25 个概念。真诚地希望它能帮助大家更好地理解Python。
如果觉得还可以,点赞收藏,好人一生平安 。
pythontip 出品,Happy Coding!
公众号: 夸克编程