一致性HASH算法研究
投稿者: 地下潜行者
1.引言
在研究分布式存储Ceph的CRUSH算法时,看到文章介绍它是一种特殊的一致性HASH算法,于是我便开始研究一致性HASH算法,做先期准备,发现理念确实接近,所以先研究一致性HASH算法的实现思路。
2.一致性HASH的出现背景及其优势
在分布式系统中,常常利用HASH算法进行数据分布,使得海量数据均匀的分布在不同的缓存服务器上,目的是希望将数据均匀的分布到各节点,分担压力,尤其是在缓存系统中。一个典型的设计如下:
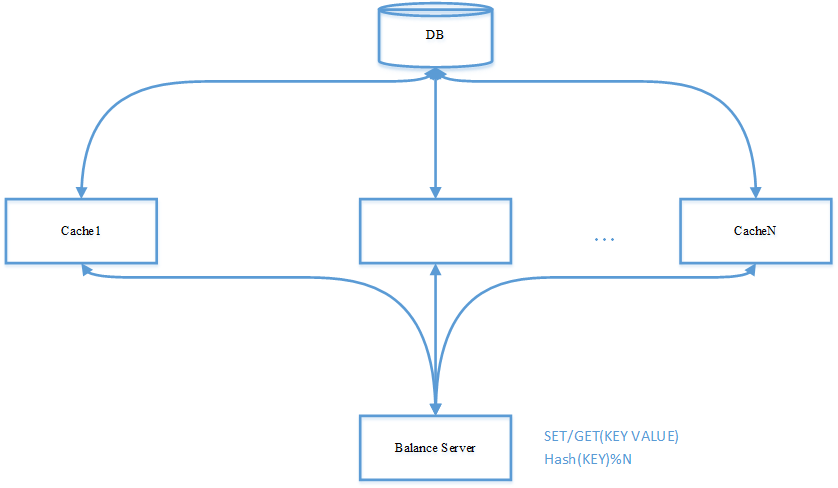
2.1场景说明
为了提升系统性能,解决数据库访问性能瓶颈,设置N个缓存服务器,每个缓存服务器负责数据库1/N的数据。应用程序在访问数据时,根据数据结构中的关键字计算得到hash值,并根据该HASH值定位到数据所在的缓存节点,进而访问到该数据。
2.2最简单模型
最简单的办法是,采用hash(key) % N的办法计算文件落在的服务器位置,那么在Find Cache Server步骤中,需要增加一个取摸操作,存在的问题是:
集群添加机器,计算公式变为hash(key) % (N + newAddedCount)
集群退出机器,计算公式变为hash(key) % (N - removedCount)
由于计算公式的分母变化,在计算数据所在服务器位置时,计算结果将发生变化,会出现大量KEY的计算结果无法命中,缓存失效的情况,进而出现直接访问数据库的情况,数据库的压力会陡增,系统的访问延迟也会变大。我们需要找到一种方法,当对集群进行扩容,或者从集群中移除失效机器时,只有少量的数据访问失效,可以很快的在正常的机器或者新增的机器上重新构建起缓存,从而保证系统的稳定性和可靠性。
2.2.1 Hash算法
上图中的Hash(KEY)代表的就是Hash算法,一般叫做散列算法,负责把任意长度的输入通过散列算法,变换成固定长度的输出,相当于一种映射转换,将任意长度的消息压缩到某一固定长度的消息摘要的函数。将一个数据集合,从一个空间转换到另外一个空间。取模运算是一种最简单的HASH算法。也最容易理解。
加法Hash:把输入元素一个一个的加起来构成最后的结果。下文算法以字符串输入为例,说明如何根据字符串,计算得出一个HASH值。
/**
* 加法hash
*
* @param key
* 字符串
* @param prime
* 一个质数
* @return hash结果
*/
public static int additiveHash(String key, int prime) {
int hash, i;
for (hash = key.length(), i = 0; i < key.length(); i++)
hash += key.charAt(i);
return (hash % prime);
}
该示例代码由JAVA编写。
位运算Hash;这类型Hash函数通过利用各种位运算(常见的是移位和异或)来充分的混合输入元素
/**
* 旋转hash
*
* @param key
* 输入字符串
* @param prime
* 质数
* @return hash值
*/
public static int rotatingHash(String key, int prime) {
int hash, i;
for (hash = key.length(), i = 0; i < key.length(); ++i)
hash = (hash << 4) ^ (hash >> 28) ^ key.charAt(i);
return (hash % prime);
}
乘法Hash;这种类型的Hash函数利用了乘法的不相关性
static int bernstein(String key)
{
int hash = 0;
int i;
for (i=0; i<key.length(); ++i)
{
hash = 33*hash + key.charAt(i);
}
return hash;
}
除法Hash;和乘法HASH类似,应用较少。
混合Hash;混合Hash算法利用了以上各种方式。各种常见的Hash算法,比如MD5、Tiger都属于这个范围。

String MD5(byte[] source)
{
String s = null;
char hexDigits[] = { // 用来将字节转换成 16 进制表示的字符
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f'};
try {
java.security.MessageDigest md = java.security.MessageDigest.getInstance("MD5");
md.update(source);
byte tmp[] = md.digest(); //MD5的计算结果是一个 128 位的长整数,
// 用字节表示就是 16 个字节
char str[] = new char[16 * 2]; //每个字节用 16 进制表示的话,使用两个字符,
// 所以表示成 16进制需要 32 个字符
int k = 0; //表示转换结果中对应的字符位置
for (int i = 0; i < 16; i++) { //从第一个字节开始,对 MD5 的每一个字节
// 转换成 16 进制字符的转换
byte byte0 = tmp[i]; //取第i个字节
str[k++] = hexDigits[byte0 >>> 4 & 0xf]; //取字节中高4位的数字转换,
// >>> 为逻辑右移,将符号位一起右移
str[k++] = hexDigits[byte0 & 0xf]; //取字节中低4位的数字转换
}
s = new String(str); // 换后的结果转换为字符串
} catch (Exception e) {
e.printStackTrace();
}
return s;
}
}
查表Hash;通过一系列Hash算法集作为Hash函数组,从组中随机取出一个函数进行计算。
环HASH。就是一致性HASH的基础。
- 求哈希值, 分配到 0~2^32 的圆上,其实把机器编号 hash 到这个环上。
- 采用同样的方法求出存储数据键的哈希值,并映射到相同的圆上
- 然后从数据映射到位置开始顺时针开始找,将数据保存到找到的第一个服务器,如果 2^32 仍然找不到服务器,就会保存到第一台服务器上。
Hash算法的介绍,参考了知乎的文档:https://zhuanlan.zhihu.com/p/168772645
2.2.2 HASH碰撞
HASH碰撞指不同的KEY,计算后对应的HASH值相同。对于这种情况,有多种不同的存储形式来处理解决。
2.2.2.1 基于拉链法的散列表
基于拉链法的散列表采用桶的形式组织数据,在进行HASH计算后,发生碰撞的数据,放置到一个桶里面。一旦桶的数量发生变化,数据所在的位置,就会发生剧烈抖动。
在做算法实现时,可以将Bucket桶理解为一个数组空间,里面有一个指针,通过指针将一系列碰撞的数据,通过指针进行链接起来。
和缓存服务器集群进行类比时,每个桶,就是一个缓存服务器。将Hash值相同的数据集合,放到一个缓存服务器上。
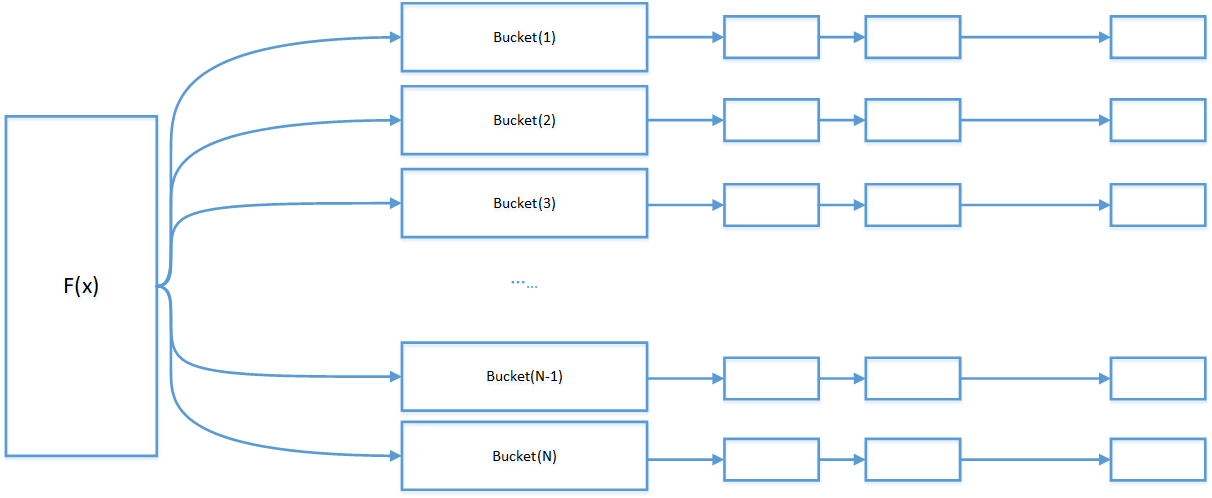
2.2.2.2 基于线性探测法的散列表
基于线性探测法的散列表的实现思路是,当碰撞发生时,直接检查散列表的下一个位置。找到一个可用的位置进行数据保存。这种情况下,一般散列表的空间,要大于KEY的数量。当碰撞发生时直接检测散列表的下一个位置(将索引加一)。这样的线性探测可能会产生三种情况:
- 命中,该位置已有被占用,键和被查找的键相同,将对应的VALUE覆盖即可;
- 未命中,该位置还未被占用,键为空;
- 继续查找,该位置的键和被查找的键不同,继续检查下一个,一直到找到该键,或者遇到一个空元素。
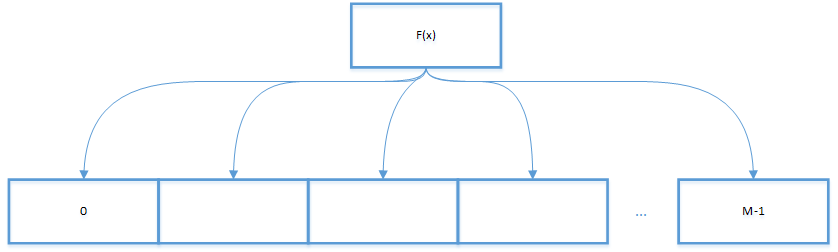
2.3 一致性HASH模型
为了避免传统的HASH方式,在缓存节点出现新增和删除时数据位置的剧烈抖动,专业人士更提出了明确的要求,并形成论文,一致性HASH便产生。
一致性HASH论文
2.3.1 一致性HASH基本设计思路
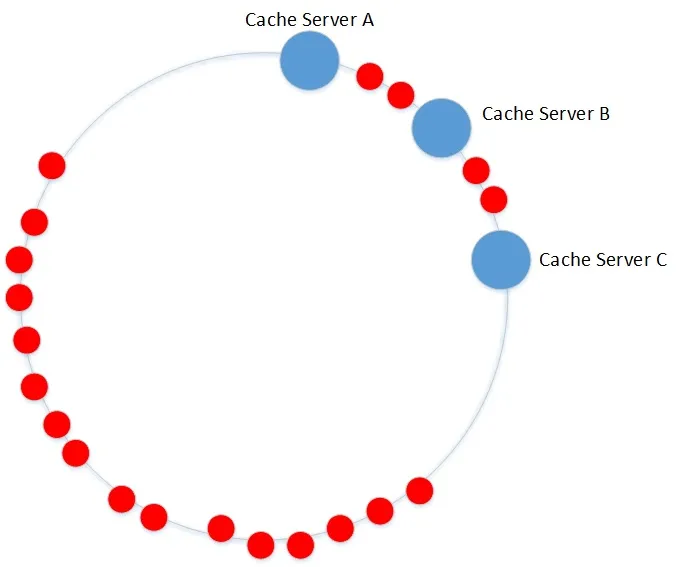
一致性哈希构造hash环,将服务器节点映射到环上,将obj也映射到环上,将他们至于同一个空间中(0~2^32-1),针对每一个对象,顺时针查找第一个>=hash(obj)的设备节点,这就是它要存放的目标系统,如果没有找到,按照顺时针,就回归到第一个服务器。
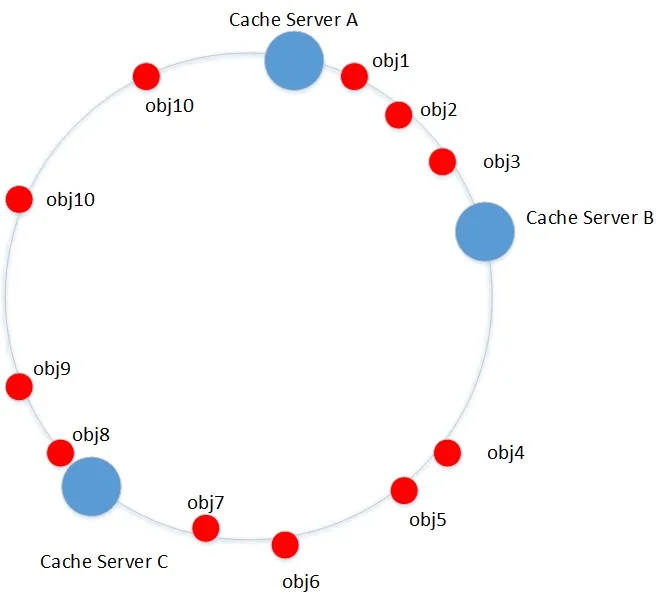
在上图实例中,
obj1 ~ 3归属于Cache Server B;
obj4 ~ 7归属于Cache Server C;
obj8~10归属于Cache Server A.
正是按照上述规则分析下来的结果。
但是存在一个问题,就是数据分布不均衡的问题,在下图中可以看到,大量的数据会在服务器A上,但是B,C上只有少量的数据。数据分布明显不平衡。
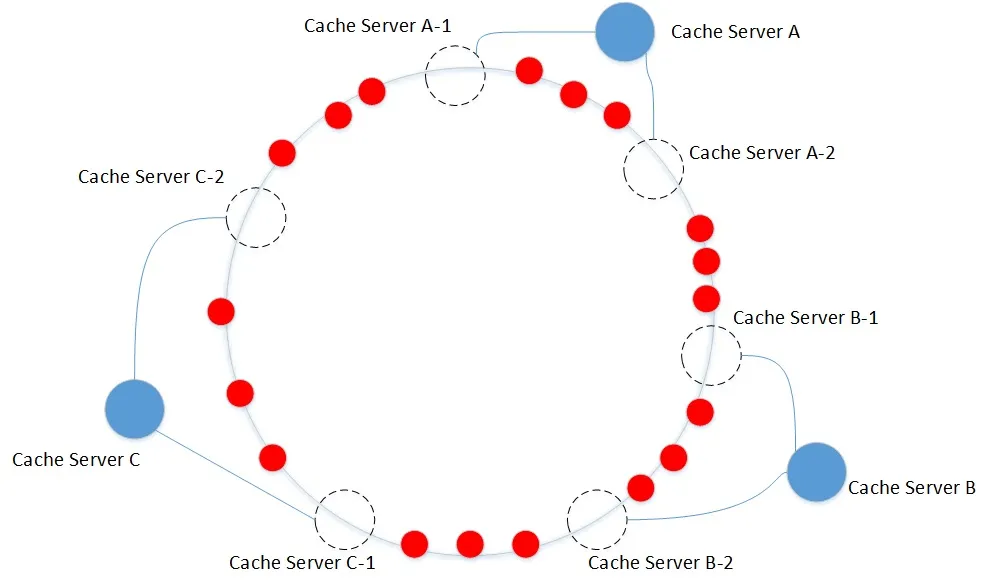
为了解决数据不均衡的问题,一致性HASH中引入了虚拟节点,将对象均匀的映射到虚拟节点,再将虚拟节点映射到物理节点。
通过设置大量的虚拟节点,将数据平均分布到虚拟节点上,最终达到平均分布到物理节点上的效果。
此处,一致性hash是符合我们的期望的:
1、平衡性(Balance):hash后的结果能够平均分布,比如在存储中,数据可以平均分布到各节点,不会出现个别节点数据量特别少,个别特别多的情况;
2、单调性(Monotonicity):当新增或者移除节点时,要么映射到原有的位置,或者映射到新节点;
2.3.2 数据分布均衡测试
为了测试一致性hash算法的特性以及虚拟节点对数据分布平衡的影响,我用C++实现了一个一致性hash算法,进行统计试验。
实际物理设备节点为5,数据量为1万。对应的IP地址为 (原先采用的公网网址测试,为了安全问题隐藏了IP地址):
xxx.xx.x.31
xxx.xx.x.32
xxx.xx.x.33
xxx.xx.x.34
xxx.xx.x.35
- 在相同数据,相同的物理节点下,测试不同虚拟节点数量下,数据的分布情况:
测试样本:10000条URL记录,用作对象名称,作为hash函数的输入
采用的hash函数:c++11中默认的std::hash()
数据中虚拟节点数量参数是指每个物理节点对应的虚拟节点数量。
1虚拟节点(一个物理设备对应1个虚拟节点)
xxx.xx.x.31:80 764
xxx.xx.x.32:80 2395
xxx.xx.x.33:80 1478
xxx.xx.x.34:80 786
xxx.xx.x.35:80 4577
10节点(一个物理设备对应10个虚拟节点)
xxx.xx.x.31:80 1139
xxx.xx.x.32:80 4862
xxx.xx.x.33:80 1484
xxx.xx.x.34:80 1243
xxx.xx.x.35:80 1272
100节点(一个物理设备对应100个虚拟节点)
xxx.xx.x.31:80 2646
xxx.xx.x.32:80 2576
xxx.xx.x.33:80 1260
xxx.xx.x.34:80 705
xxx.xx.x.35:80 2813
512虚拟节点(一个物理设备对应512个虚拟节点)
xxx.xx.x.31:80 2015
xxx.xx.x.32:80 2038
xxx.xx.x.33:80 1948
xxx.xx.x.34:80 2128
xxx.xx.x.35:80 1871
1024虚拟节点(一个物理设备对应1024个虚拟节点)
xxx.xx.x.31:80 2165
xxx.xx.x.32:80 1389
xxx.xx.x.33:80 2045
xxx.xx.x.34:80 2123
xxx.xx.x.35:80 2278
2048节点(一个物理设备对应2048个虚拟节点)
xxx.xx.x.31:80 1976
xxx.xx.x.32:80 1939
xxx.xx.x.33:80 1892
xxx.xx.x.34:80 2164
xxx.xx.x.35:80 2029
4096节点(一个物理设备对应4096个虚拟节点)
xxx.xx.x.31:80 1972
xxx.xx.x.32:80 2139
xxx.xx.x.33:80 2095
xxx.xx.x.34:80 1879
xxx.xx.x.35:80 1915
从数据可以看到,随着对应的虚拟节点越来越多,数据的分布也越来越平衡,但是虚拟节点到达一定数量后,到达了瓶颈,毕竟不可能实现绝对的平衡。
2.3.3 一致性hash算法实现
//构建带虚拟节点的hash环,对每个真实的物理节点,配置若干虚拟节点,并进行排序
for (RNode node : rnodes)
{
for (int i = 1; i <= virtual_node_count; i++)
{
VNode vnode;
vnode.ip_port = node.ip_port + "#" + to_string(i);
vnode.id = myhash(vnode.ip_port); //虚拟节点在hash环上的映射
circle.push_back(vnode);
node.virtual_nodes.push_back(vnode);
}
}
sort(circle.begin(), circle.end(), cmpVNode);
//计算每个URL落在那个虚拟节点
VNode getLocation(string url, vector<VNode>& vnodes)
{
VNode tmp;
tmp.id = myhash(url.c_str());
vector<VNode>::iterator iter = std::lower_bound(vnodes.begin(), vnodes.end(), tmp, cmpVNode);
if (iter == vnodes.end())
{
return vnodes[0];
}else
{
return *iter;
}
}
//根据虚拟节点,找到对应物理节点
string real_node = getRealNodeInfo(vnode);
3.CRUSHMAP的进一步研究
研究一致性HASH的目的是为了更好的理解Ceph中关于分布式存储的原理。
CRUSHMAP算法,此处简单说明Ceph中对象是如何映射到具体设备的某块硬盘上的。
在Ceph中,每个对象都属于某个PG,我把这些PG理解为一致性哈希中的虚拟节点,目的是为了让对象分布更均匀。
而pg是如何映射到OSD呢。在上文中,这种映射关系比较简单,就是多对一,在ceph中则比较复杂,因为映射关系依赖于集群的拓扑结构,而每个对象都还有多副本,需要指定的映射算法,计算出pg所在的主OSD以及副本OSD。
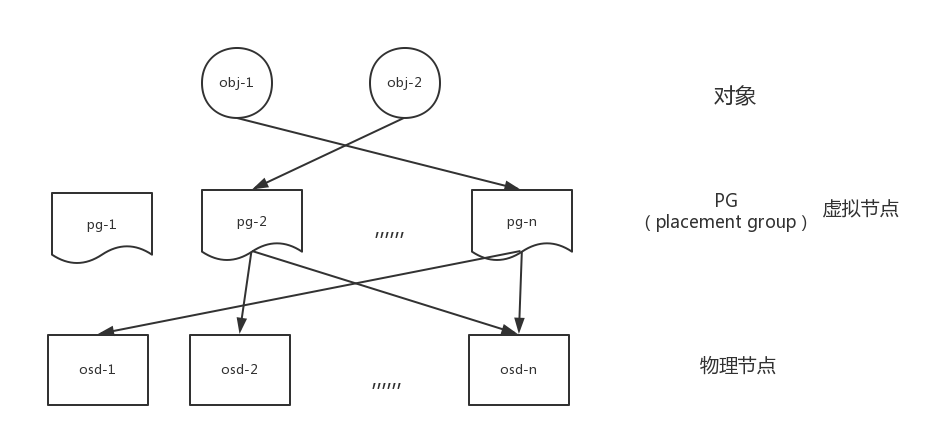
我会在以后的博客中,结合论文,说明obj和pg的映射关系,以及pg和osd之间是如何做映射的。
4 附录
一致性HASH算法应用之广非常广泛,在分布式存储,缓存系统中会用到,在nginx的负载均衡中也会用到,理解一致性HASH算法,对理解分布式系统中的实现机制非常有帮助。下文是一致性hash更深入的文章,可研究之。
nginx中一致性HASH的使用
数据库分表中的一致性HASH
Ceph数据分布:CRUSH算法与一致性Hash - shanno
亚马逊的Dynamo系统
jump Consistent hash:零内存消耗,均匀,快速,简洁,来自Google的一致性哈希算法