正则表达式
一、正则表达式概述
正则表达式:
- 是一个特殊的字符序列,作用是帮助用户便捷地检查一个字符串是否与某种模式匹配
- Python的正则模块是re,是Python的内置模块,不需要安装,导入即可
正则语法
| 元字符 | 说明 |
|---|---|
| . | 匹配任意字符 |
| ^ | 匹配字符串的开头 |
| $ | 匹配字符的末尾 |
| * | 匹配前一个元字符0到多次 |
| + | 匹配前一个元字符1到多次 |
| ? | 匹配前一个元字符0到1次 |
| {m} | 匹配前一个元字符m次 |
| {m,n} | 匹配前一个元字符m到n次 |
| {m.n}? | 匹配前一个元字符m到n次,并且取尽可能少的情况 |
| \ | 对特殊字符进行转义 |
| [] | 一个字符的集合,可匹配其中任意一个字符 |
| | | 逻辑表达式“或”,如a|b代表匹配a或者b |
| (…) | 括号中表达式作为一个元组,find_all在有组的情况下,只显示组的内容 |
特殊序列
| 元字符 | 说明 |
|---|---|
| \A | 只在字符串开头进行匹配 |
| \b | 匹配位于开头或者结尾的空字符串 |
| \B | 匹配不位于开头或者结尾的空字符串 |
| d | 匹配任意十进制数,相当于[0-9] |
| \D | 匹配任意非数字字符,相当于[^0-9] |
| \s | 匹配任意空白字符,相当于[\t\n\r\f\v] |
| \S | 匹配任意非空白字符,相当于[^\t\n\r\f\v] |
| \w | 匹配任意数字、字母、下划线,相当于[a-z A-Z 0-9] |
| \W | 匹配任意非数字、字母、下划线,相当于[^a-z A-Z 0-9] |
| \Z | 只在字符串结尾进行匹配 |
| [\u4e00-\u9fa5] | 匹配中文 |
正则处理函数
| 函数 | 说明 |
|---|---|
| re.match(pattern,string,flags=0) | 尝试从字符串的开始位置匹配一个模式,如果匹配成功,就返回一个匹配成功的对象,否则返回None |
| re.search(pattern,string,flags=0) | 扫描整个字符串并返回第一次成功匹配的对象,如果匹配失败,就返回None |
| re.findall(pattern,string,flags=0) | 获取字符串所有匹配的字符串,并以列表的形式返回 |
| re.sub(pattern,repl,string,count=0,flags=0 | 用于替换字符串中的匹配项,如果没有匹配的项,则返回没有匹配的字符串 |
| re.compile(pattern[,flag]) | 用于变异正则表达式,生成一个正则表达式(Pattern)对象,供match()和search()函数使用 |
二、正则表达式基本使用
import re
s = 'Istudy Python3.8 every day'
print('-------------match()方法,从起始位置开始匹配-------------------')
print(re.match('I',s).group())
print(re.match('\w',s).group())
#匹配任意字符
print(re.match('.',s).group())
print('---------------search()方法,从任意位置开始匹配,返回第一个---------------')
print(re.search('study',s).group())
print(re.search('s\w',s).group())
print('----------------findall方法,从任意位置开始匹配,匹配多个------------------')
print(re.findall('y',s)) #结果为列表
print(re.findall('Python',s))
print(re.findall('P\w+.\d',s))
print(re.findall('P.+\d',s))
print('-----------------sub方法,替换--------------------------')
print(re.sub('study','like',s))
print(re.sub('s\w+','like',s))
-------------match()方法,从起始位置开始匹配-------------------
I
I
I
---------------search()方法,从任意位置开始匹配,返回第一个---------------
study
st
----------------findall方法,从任意位置开始匹配,匹配多个------------------
['y', 'y', 'y', 'y']
['Python']
['Python3.8']
['Python3.8']
-----------------sub方法,替换--------------------------
Ilike Python3.8 every day
Ilike Python3.8 every day
Process finished with exit code 0
三、案例
下载糗事百科小视频
请求的URL:https://www.qiushibaike.com/video
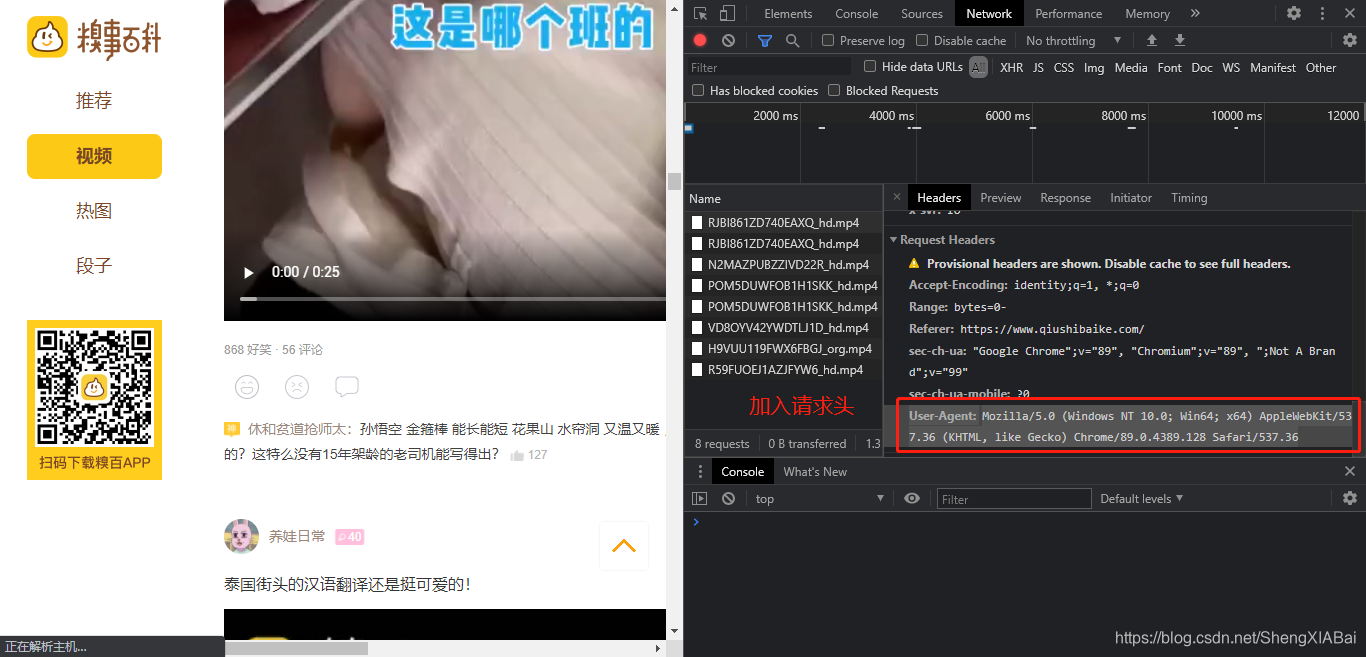
加入请求头
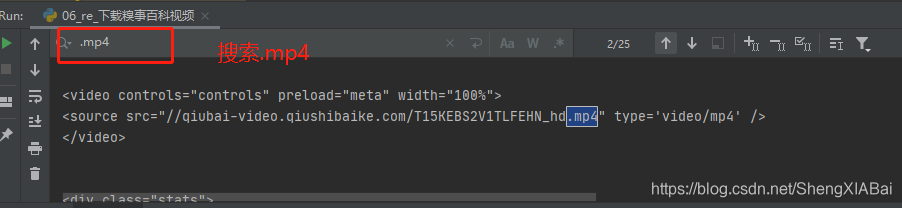
查找资源所在位置

注意:直接复制代码可能会产生搜索结果为0的问题,所以在pycharm中直接搜索“.mp4”即可
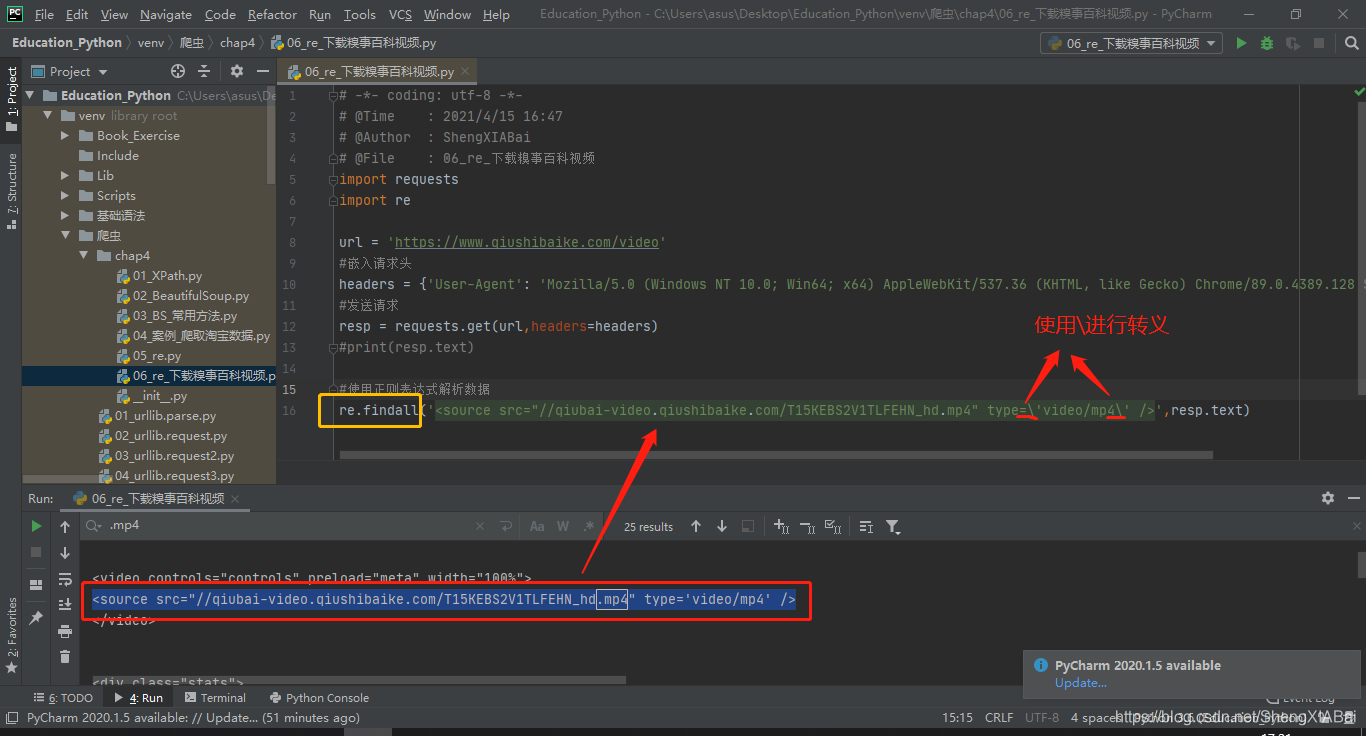
使用上面的参数只能返回一条数据,返回多条数据需要使用正则

结果

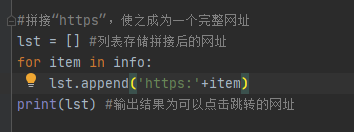
但是所获得的上图中数据链接路径不完整,需要拼接上“https”,使之成为一个完整的网址
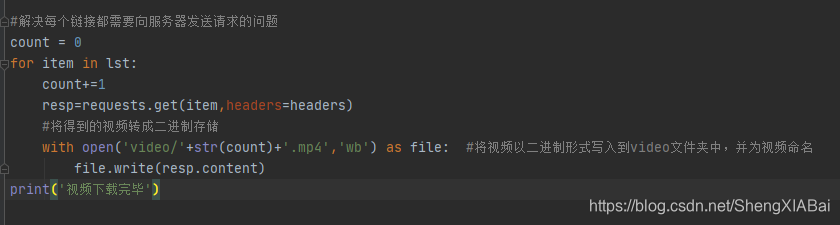
解决每个链接都需要向服务器发生请求的问题
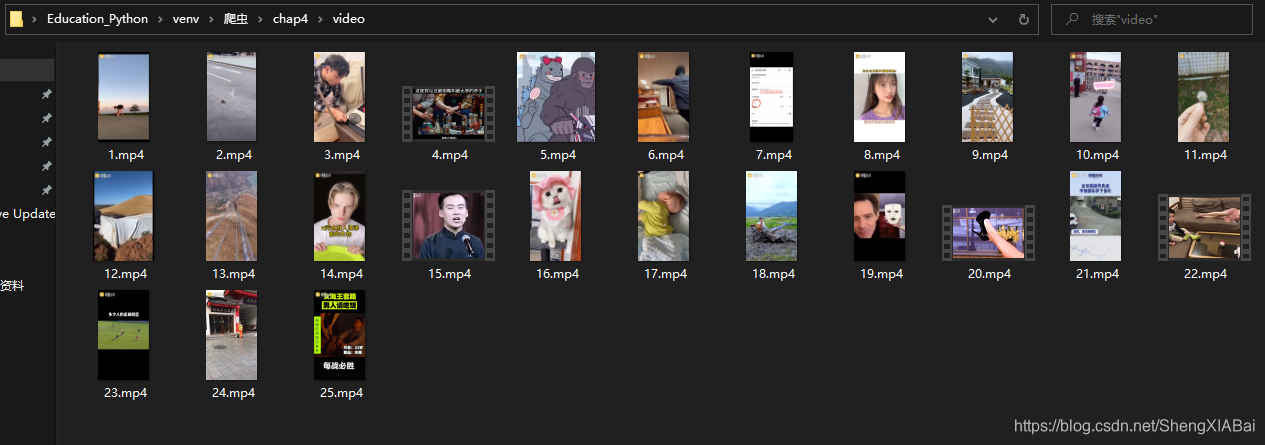
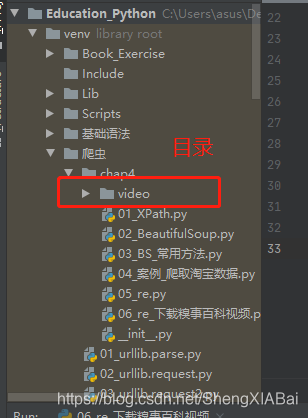
需要新建一个video目录
具体实现代码
import requests
import re
url = 'https://www.qiushibaike.com/video'
#嵌入请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36'}
#发送请求
resp = requests.get(url,headers=headers)
#print(resp.text)
#使用正则表达式解析数据
info = re.findall('<source src="(.*)" type=\'video/mp4\' />',resp.text)
#print(info)
#拼接“https”,使之成为一个完整网址
lst = [] #列表存储拼接后的网址
for item in info:
lst.append('https:'+item)
#print(lst) #输出结果为可以点击跳转的网址
#解决每个链接都需要向服务器发送请求的问题
count = 0
for item in lst:
count+=1
resp=requests.get(item,headers=headers)
#将得到的视频转成二进制存储
with open('video/'+str(count)+'.mp4','wb') as file: #将视频以二进制形式写入到video文件夹中,并为视频命名
file.write(resp.content)
print('视频下载完毕')
结果存储在文件夹中寻找