遇到一个需求,需要提取代码中所有用到的汉字,有lua代码c++代码还有oc代码,于是研究了一个脚本,专门提取代码中的汉字,现在研究好了,在这里贴一下,供大家参考
# -*- coding: UTF-8 -*-
import os
strStr = []
suf_set = ('.lua','.cpp','.h','.hpp','.m','.mm')
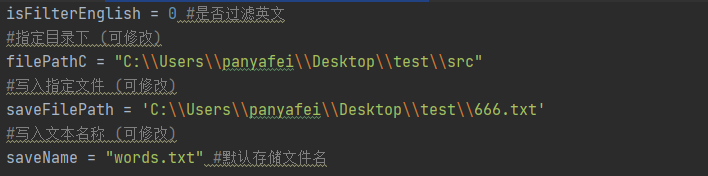
isFilterEnglish = 0 #是否过滤英文
#指定目录下 (可修改)
filePathC = "C:\\Users\\panyafei\\Desktop\\test\\src"
#写入指定文件 (可修改)
saveFilePath = 'C:\\Users\\panyafei\\Desktop\\test\\666.txt'
#写入文本名称 (可修改)
saveName = "words.txt" #默认存储文件名
# 遍历指定目录,显示目录下的所有文件名
def eachFile(filepath,saveFilePath):
for root, dirs, files in os.walk(filepath):
for file in files:
luaFileName = os.path.join(root, file)
if luaFileName.endswith(suf_set):
readFile(luaFileName,saveFilePath)
# 保存字符串到文本中
def save_to_file(file_name, contents):
str = ""
content = ""
if isFilterEnglish == 1:
for char in contents:
if ord(char)>=65 and ord(char)<90 or ord(char)>=97 and ord(char)<122:
print("过滤英文")
else:
content = content + char
else:
content = contents
f = open(file_name, 'r')
str = f.read()
f.close()
fh = open(file_name, 'w')
if str == "":
fh.write(str + content)
else:
fh.write(str+ '\n' +content)
fh.close()
# 读取文件内容并打印
def readFile(filename,saveFilePath):
# 搜寻以下文件类型
isPiZS = 0 # 批注释
f = open(filename) # 返回一个文件对象
line = f.readline() # 调用文件的 readline()方法
while line:
line = line.lstrip()
line = line.lstrip('\t')
#print("line = "+line) # 后面跟 ',' 将忽略换行符
l = len(line)
if l>0:
#如果是批注释的话不管是不是中文字符都不管
index = filename.find(".lua")
if judgeIsZhiShiBegan(filename, line):
isPiZS = 1
#如果是批注释中,那么就找到结尾,并且把结尾后的字符截取出来
if isPiZS == 1 :
pos = 0
isfound,pos = judgeIsZhiShiEnd(filename,line)
if isfound == 1:
if pos+2<l-1:
line = line[pos+2:l-1]
else:
line = "\n"
isPiZS = 0
l = len(line)
if judgeIsZhuShi(filename,line) == 1 or line[0] == '\n' or isPiZS != 0 :
print("过滤注释!")
else:
findChinaStr(line,saveFilePath)
line = f.readline()
f.close()
#检测这是否是一个注释行
def judgeIsZhuShi(filename,str):
value = filename.find(".lua")
pos = 0 #表示的是生效开始下表位置
lens = len(str)
isZhuShi = 0
# pp = ord(' ')
for num in range(0,lens-1): # 迭代 0 到 len 之间的数字
if str[num] !=' ':
pos = num
break
if value>0: #lua文件
if str[pos] == '-' and (lens-pos) >= 2 and str[pos+1] == '-':
isZhuShi = 1
else:
if ord(str[pos]) == 47 and (lens-pos) >= 2 and ord(str[pos]) == 47:
isZhuShi = 1
return isZhuShi
#检测批注释的开始
def judgeIsZhiShiBegan(filename,str):
value = filename.find(".lua")
pos = 0 # 表示的是生效开始下表位置
lens = len(str)
isZhuShi = 0
for num in range(0, lens - 1): # 迭代 0 到 len 之间的数字
if str[num] != ' ':
pos = num
break
if value > 0: # lua文件
if str[pos] == '-' and (lens - pos) >= 4 and str[pos+1] == '-' and str[pos+2] == '[' and str[pos+3] == '[':
isZhuShi = 1
else:
if ord(str[pos]) == 47 and (lens - pos) >= 2 and ord(str[pos+1]) == 42:
isZhuShi = 1
return isZhuShi
#检测批注释的结尾
def judgeIsZhiShiEnd(filename,str):
value = filename.find(".lua")
pos = 0 # 表示的是生效开始下表位置
lens = len(str)
isZhuShi = 0
for num in range(0, lens - 1): # 迭代 0 到 len 之间的数字
if str[num] != ' ':
pos = num
break
if value > 0:
if str.find('\]'):
pos = str.find(']')
if pos != -1 and lens >= pos + 2 and str[pos + 1] == ']':
# print('找到结尾的批注释!')
isZhuShi = 1
else:
for num in range(0, lens - 1):
if ord(str[num]) == 42 and num+1<lens and ord(str[num+1]) == 47:
# print('找到结尾的批注释!')
pos = num
isZhuShi = 1
break
return isZhuShi,pos
def findChinaStr(str,saveFilePath):
chinese = ""
dataLen = len(str)
i = 0
while i < dataLen:
value = ord(str[i])
if value == 34 and i + 1 < dataLen:
i = i + 1
while ord(str[i]) != 34 and i + 1 < dataLen:
chinese = chinese + str[i]
i = i + 1
if isCanShow(chinese) == True and isCanSave(chinese)==1:
strStr.append(chinese)
save_to_file(saveFilePath, chinese)
print(chinese.decode('utf-8').encode('gbk'))
chinese = ""
i = i + 1;
def isCanSave(chinese):
for str in strStr:
if str == chinese:
return 0
return 1
# 全部ASCII码,不需要显示
def isCanShow(str):
flag = False
tick = 0
for cha in str:
value = ord(cha)
if value <= 127:
tick = tick + 1
if tick == len(str):
return False
return True
if __name__ == '__main__':
if filePathC == "" or (os.path.exists(filePathC) == False):
str = "未设置路径或者路径不存在,是否默认当前路径,按任意键继续,退出请关闭!"
print(str.decode('utf-8').encode('gbk'))
os.system("pause")
filePathC = os.getcwd()
if saveFilePath == "" :
path = os.path.abspath(os.path.dirname(filePathC))
saveFilePath = path + "\\" + saveName
if os.path.exists(saveFilePath):
print('文件存在,清空内容!')
f = open(saveFilePath, "r+")
f.truncate()
else:
print('文件不存在,创建文件')
file = open(saveFilePath, 'w')
file.close()
eachFile(filePathC,saveFilePath)
print("--------------------finish--------------------")
os.system("pause")脚本中可以自己设置需要查找的路径和保存文本的名字,如果没有设置路径的话会默认指向当前路径,
同时也支持设置文本类型,暂时支持
'.lua','.cpp','.h','.hpp','.m','.mm'这六种类型,后期可以自己增加删除文件类型。
isFilterEnglish 可以设置是否过滤中文中间夹杂的英文字符,默认是不过滤的,如有需求可以自行修改 0->表示不过滤 1->表示过滤还有一点需要说明,就是这个保存的文本类型,我这里写的是.txt格式的,如果你需要的是一个表格形式的文本,那么只要把saveName = "words.txt" 改成 saveName = "words.xls" 或者 saveName = "words.xlsx" 即可。
好了,到这里就结束了,此脚本如有更新,会自动上传更新!