目录
3、torch.optim.lr_scheduler.MultiStepLR
10、PyTorch中的损失函数--L1Loss /L2Loss/SmoothL1Loss
16、python a[:, 0:1] originSeed[:, 0:1]
np.arange([start, ]stop, [step, ]dtype=None)
1、下载
以上说明,install和安装库的源头没关系,那怎么解决?
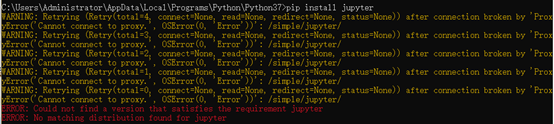
这里引入了另外一个镜像网站:
pip install pyrender -i http://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com
2、split()
split(‘[’)[0] :输出[前的内容
split(‘[’)[1] :输出[后的内容
split(‘[’)[-1]:保留[后的内
example:x.split('_')[-1].split('.')[0] #model_000008.ckpt r:000008
split(':')[0].split(',')]#[1 3 5 7]
lrepochs.split(':')[1])# (1, 3, 5, 7:2) r:23、torch.optim.lr_scheduler.MultiStepLR
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
milestones为一个数组,如 [50,70]. gamma为倍数。如果learning rate开始为0.01 ,则当epoch为50时变为0.001,epoch 为70 时变为0.0001。当last_epoch=-1,设定为初始lr。
4、DataLoader
DataLoader(test_dataset, args.batch_size, shuffle=False, num_workers=4, drop_last=False)
比如:想打乱一下数据的排序,可以设置 shuffle(洗牌)为True;
比如:想数据是一捆的输入,可以设置 batch_size 的数目;
比如:想随机抽取的模式输入,可以设置 sampler 或 batch_sampler。如何定义抽样规则,可以看sampler.py脚本。这里不是重点;
比如:像多线程输入,可以设置 num_workers 的数目;
torch.utils.data.DataLoader(
dataset,#数据加载
batch_size = 1,#批处理大小设置
shuffle = False,#是否进项洗牌操作
sampler = None,#指定数据加载中使用的索引/键的序列
batch_sampler = None,#和sampler类似
num_workers = 0,#是否进行多进程加载数据设置
collate_fn = None,#是否合并样本列表以形成一小批Tensor
pin_memory = False,#如果True,数据加载器会在返回之前将Tensors复制到CUDA固定内存
drop_last = False,#True如果数据集大小不能被批处理大小整除,则设置为删除最后一个不完整的批处理。
timeout = 0,#如果为正,则为从工作人员收集批处理的超时值
worker_init_fn = None )5、torch.optim
而torch.optim包则主要包含了用来更新参数的优化算法,比如SGD、AdaGrad、RMSProp、 Adam(使用动量和自适应学习率来加快收敛速度)等。
6、torch.nn
torch.nn包中主要包含了用来搭建各个层的模块(Modules),比如全连接、二维卷积、池化等;torch.nn包中还包含了一系列有用的loss函数,这些函数也是在训练神经网络时必不可少的,比如CrossEntropyLoss、MSELoss等;另外,torch.nn.functional子包中包含了常用的激活函数,如relu、leaky_relu、prelu、sigmoid等。
7、zero_grad()
模型的参数梯度设成0 二种方法
model.zero_grad()
optimizer.zero_grad() # 当optimizer=optim.Optimizer(model.parameters())时,两者等效
另外Pytorch 为什么每一轮batch需要设置optimizer.zero_grad:
根据pytorch中的backward()函数的计算,当网络参量进行反馈时,梯度是被积累的而不是被替换掉;但是在每一个batch时毫无疑问并不需要将两个batch的梯度混合起来累积,因此这里就需要每个batch设置一遍zero_grad 了。
8、torch.nn.functional
https://pytorch-cn.readthedocs.io/zh/latest/package_references/functional/
9、 isinstance
isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
sinstance() 与 type() 区别:
-
type() 不会认为子类是一种父类类型,不考虑继承关系。
-
isinstance() 会认为子类是一种父类类型,考虑继承关系
如果要判断两个类型是否相同推荐使用 isinstance()。
>>>a = 2
>>> isinstance (a,int)
True
>>> isinstance (a,str)
False
>>> isinstance (a,(str,int,list)) # 是元组中的一个返回 True
True
type() 与 isinstance()区别
class A:
pass
class B(A):
pass
isinstance(A(), A) # returns True
type(A()) == A # returns True
isinstance(B(), A) # returns True
type(B()) == A # returns False10、PyTorch中的损失函数--L1Loss /L2Loss/SmoothL1Loss
L1 Loss

L2loss
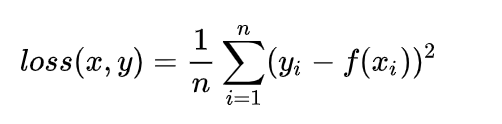
SmoothL1Loss
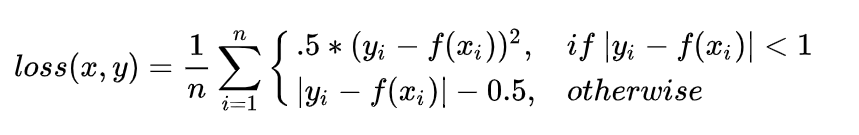
仔细观察可以看到,当预测值和ground truth差别较小的时候(绝对值差小于1),其实使用的是L2 Loss;而当差别大的时候,是L1 Loss的平移。SooothL1Loss其实是L2Loss和L1Loss的结合,它同时拥有L2 Loss和L1 Loss的部分优点。
1. 当预测值和ground truth差别较小的时候(绝对值差小于1),梯度不至于太大。(损失函数相较L1 Loss比较圆滑)
2. 当差别大的时候,梯度值足够小(较稳定,不容易梯度爆炸)。

size_average=True or False
在pytorch中,所有的损失函数都带这个参数,默认设置为True。
当size_average为True的时候,计算出来的结果会对mini-batch取平均。反之,为False的时候,那算出来的绝对值不会除以n。
11、np.flipud
用于翻转列表,将矩阵进行上下翻转
第n行----->第1行
第n-1行----->第2行
..................... #(这是省略号的意思)
第2行----->第n-1行
第1行----->第n行
[[1 0 0 0]
[0 2 0 0]
[0 0 3 0]
[0 0 0 4]]
np.flipud(a) #执行完这句会自动输出结果
array([[0, 0, 0, 4],
[0, 0, 3, 0],
[0, 2, 0, 0],
[1, 0, 0, 0]])
b=[1,2,3,4]
np.flipud(b) #执行完这句会自动输出结果
array([4,3,2,1])
c=[[1],[2],[3],[4]]
np.flipud(c) #执行完这句会自动输出结果
array([[4],
[3],
[2],
[1]])
12 Image.fromarray
简而言之,就是实现array到image的转换
1. PIL image转换成array
img = np.asarray(image)2. array转换成image
Image.fromarray(np.uint8(img))13 Python 字符串索引
https://www.runoob.com/w3cnote/python-string-index.html
在 python 中,字符串中的字符是通过索引来提取的,索引从 0 开始。python 可以取负值,表示从末尾提取,最后一个为 -1,倒数第二个为 -2,即程序认为可以从结束处反向计数。

下面是对 python 索引和切片的总结:
1. 索引获取特定偏移的元素
- 字符串中第一个元素的偏移为 0
- 字符串中最后一个元素的偏移为-1
- str[0] 获取第一个元素
- str[-2] 获取倒数第二个元素
2. 分片提取相应部分数据
- 通常上边界不包括在提取字符串内
- 如果没有指定值,则分片的边界默认为0和序列的长度
- str[1:3 ]获取从偏移为1的字符一直到偏移为3的字符串,不包括偏移为3的字符串 : "tr"
- str[1:] 获取从偏移为1的字符一直到字符串的最后一个字符(包括最后一个字符): "tring"
- str[:3] 获取从偏移为0的字符一直到偏移为3的字符串,不包括偏移为3的字符串 : "str"
- str[:-1] 获取从偏移为0的字符一直到最后一个字符(不包括最后一个字符串): "strin"
- str[:] 获取字符串从开始到结尾的所有元素 : "string"
- str[-3:-1] 获取偏移为 -3 到偏移为 -1 的字符,不包括偏移为 -1 的字符 : "in"
- str[-1:-3] 和 str[2:0] 获取的为空字符,系统不提示错误: ""
- 分片的时候还可以增加一个步长,str[::2] 输出的结果为: "srn"
14 python 列表索引与切片
https://www.cnblogs.com/tinglele527/p/11678549.html
3.切片索引 例题:list2 = ['江苏','安徽','浙江','上海','山东','山西','湖南','湖北']
print(list2[2:6]) #取出“浙江”至“山西”四个元素 排号在 3 4 5 6号4个元素 值得注意的是不包括 "list2[6]” 第7个元素
print(list2[1:6:2]) #取出“安徽”,“上海”,“山西”三个元素 从第2个元素开始取,(step 步长为2,每隔一个元素取一个),直到取到第6个元素
print(list2[-3:-1]) # 结果是:[''山西,'湖南'],此时取出来的并不包含'湖北',这种负索引的方式 换成'-1'换成0 或者是别的值都不能取出来湖北
4.无限索引 可以用[::step]来表示
print(list2[:3]) #取前3个元素
print(list2[3:]) #从3个元素后面所有的元素
print(list2[-3:]) #取最后3个元素
print(list2[::]) #取所有的元素
print(list2[::2]) #取奇数位的所有元素 1 3 5 7 ...
易混乱区笔记:列表切片表示的时候后面标号的数字,其实标记的是真实的位置 例如:
list[6] 表示的是列表的第7号位置的元素
list[1:6] 表示的是从第2个至第6号位置的元素(6号位置元素包含在内)
15 xml.etree.ElementTree
模块实现了一个简单高效的API,用于解析和创建XML数据
XML是一种固有的分层数据格式,最自然的表示方法是使用树。为此, ET 有两个类: ElementTree 将整个XML文档表示为一个树, Element 表示该树中的单个节点。与整个文档的交互(读写文件)通常在 ElementTree 级别完成。与单个XML元素及其子元素的交互是在 Element 级别完成的。
https://blog.csdn.net/weixin_42547344/article/details/81097633
16、python a[:, 0:1] originSeed[:, 0:1]
X[:,0]是numpy中数组的一种写法,表示对一个二维数组,取该二维数组第一维中的所有数据,第二维中取第0个数据,直观来说,X[:,0]就是取所有行的第0个数据, X[:,1] 就是取所有行的第1个数据。
举例说明:
import numpy as np
X = np.array([[0,1],[2,3],[4,5],[6,7],[8,9],[10,11],[12,13],[14,15],[16,17],[18,19]])
print X[:,0]
[ 0 2 4 6 8 10 12 14 16 18]
import numpy as np
X = np.array([[0, 1], [2, 3], [4, 5], [6, 7], [8, 9], [10, 11], [12, 13], [14, 15], [16, 17], [18, 19]])
print(X[:, 1])
[ 1 3 5 7 9 11 13 15 17 19]
X = np.array([[0,1,2],[3,4,5],[6,7,8],[9,10,11],[12,13,14],[15,16,17],[18,19,20]])
print (X[:,1:3])
[[ 1 2]
[ 4 5]
[ 7 8]
[10 11]
[13 14]
[16 17]
[19 20]]
Process finished with exit code 0
X[n,:]是取第1维中下标为n的元素的所有值。
X[1,:]即取第一维中下标为1的元素的所有值,输出结果:
X[:, m:n],即取所有数据的第m到n-1列数据,含左不含右
17、Python requirement 导入导出包
https://blog.csdn.net/a12355556/article/details/112094394
在使用Python的时候,需要把安装的Package通过requirements.txt导出来,一个命令便可部署新环境。
requirements.txt,是用于记录所有依赖包及其精确的版本号。
自动生成requirement.txt命令:
pip freeze > requirements.txt
- 执行成功后,会在当前目录下自动生成requirement.txt文件
安装requirement.txt在新环境:
执行命令即可一键安装完所需要的第三方库。
pip install -r requirements.txt18、numpy.arccos
np.arccos(2 * originSeed[:, 1:2] - 1 ) #功能: 对数组中的每个元素求其反余弦值。如果y = cos(x),那么x = arccos(y)参数:
- 数组:这些是要计算其反cos值的数组元素。
- Out:这是输出数组的形状。
import numpy as np
arr = [0, 0.3, -1]
print ("Input array : \n", arr)
arccos_val = np.arccos(arr)
print ("\nInverse cos values : \n", arccos_val)
Input array :
[0, 0.3, -1]
Inverse cos values :
[1.57079633 1.26610367 3.14159265]同理 np.sin np.arcsin np.tan np.arctan
19、np.arrange
np.arange([start, ]stop, [step, ]dtype=None)
作用:
arange函数用于创建等差数组
start:可忽略不写,默认从0开始;起始值
stop:结束值;生成的元素不包括结束值
step:可忽略不写,默认步长为1;步长
dtype:默认为None,设置显示元素的数据类型
import numpy as np
nd1 = np.arange(5)#array([0, 1, 2, 3, 4])
nd2 = np.arange(1,5)#array([1, 2, 3, 4])
nd3 = np.arange(1,5,2)#nd3 = np.arange(1,5,2)
print(nd1)
print(nd2)
print(nd3)
[0 1 2 3 4]
[1 2 3 4]
[1 3]