(11)Shared内存块组成结构及4031错误产生原因分析

视频链接:
https://www.bilibili.com/video/BV1Zt411w7eQ?p=13
讲解shared pool内存块组成结构
1、shared pool的组成
3块区域:free、library cache、 row cache
free:空闲空间
library cache(库缓存):缓存sql语句及执行计划
row cache(数据字典缓存)
最容易出问题的是library cache和free 。
可以设置shared pool的大小,但是无法设置library cache和row cache的大小,它们是由oracle自动管理的。
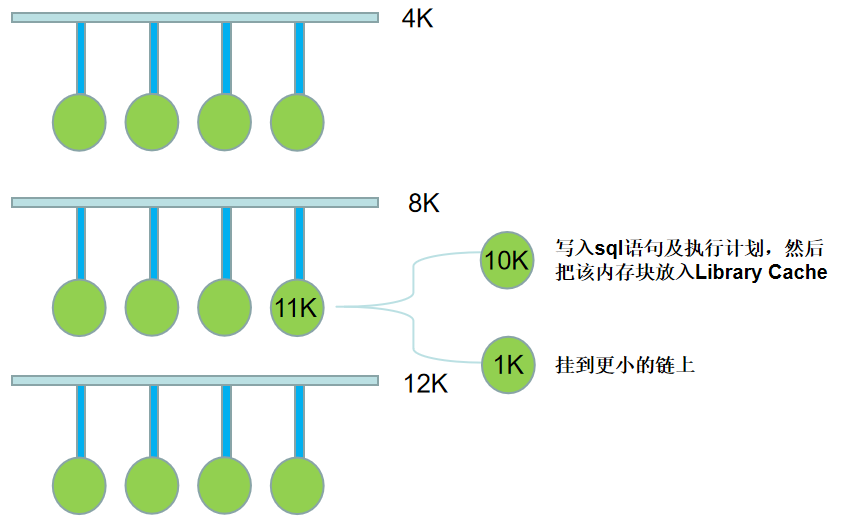
free空间是一个个小的内存块,通过chain链接起来,这些小的内存块都挂在链上,每个链上挂的内存块大小是不一样的,从上往下3条,挂的内存块越来越大。
解析语句后,会根据需要的空间大小到相应的链上选择内存块,找到合适的内存块后,把sql语句和执行计划写入内存块,然后把剩下的空闲空间挂到相应大小的链上。
问:什么时候需要从free里找chunk?
答:硬解析时
硬解析时,除了从free里找chunk,还产生了一些小chunk(碎片),所以若系统中有大量的硬解析,会产生大量的碎片,所以可能出现free有很大空间,但是解析失败的情况。然后会报ora-4031错误。
ora-4031错误产生原因:
- 大量硬解析
- 大量硬解析产生大量碎片后,突然又来了一个比较大的sql语句,需要较大的空间。
chain的特点:
- 把功能/特性类似的内存块有组织的串联起来
- 可以遍历
library cache中的链
library cache也是用链来组织和管理chunk的,但是不是以大小来管理的,而是以sql语句运算后得出的数字来挂到相应的链上的。library cache中的链上有内容:sql/执行计划
把sql语句中的字母转换成ASCII码,然后对这一堆数字进行运算得到一个数字,这个数字再进行运算得出library cache中链的编号。
当再次执行相同的sql语句时,会对sql语句中的字母转换成ASCII码,然后对这一堆数字进行运算得到一个数字,这个数字再进行运算得出library cache中链的编号。然后oracle会锁住对应链上,然后遍历该链上的chunk,拿着SQL语句的Hash值和链上的chunk比较,找到对应chunk后,就发生软解析。
select count(*) from x$ksmsp;--shared pool中的每个chunk在该表中都有一行信息
select count(*) from dba_objects;
select count(*) from x$ksmsp;
alter system flush shared_pool;--会将library cache和row cache中的所有内容清空,慎用!