准备测试环境
测试数据和测试SQL
import spark.implicits._
import java.time.LocalDateTime
import java.time.format.DateTimeFormatter
import java.sql.Timestamp
spark.range(-1000, 1000).map {
id =>
val dt = Timestamp.valueOf(LocalDateTime.now.plusDays(id))
val dt_str = LocalDateTime.now.plusDays(id).format(DateTimeFormatter.ofPattern("yyyyMMdd"))
val dt_int = dt_str.toInt
(id.toInt, dt, dt_str, dt_int)
}.toDF("id", "dt", "dt_str", "dt_int")
.createOrReplaceTempView("tab")
spark.sql(
s"""create table dim_date (
| id int,
| dt timestamp,
| dt_str string,
| dt_int int
|)
|stored as parquet;
|""".stripMargin)
spark.sql("insert overwrite table dim_date select * from tab")
spark.sql(s"""select *
|from test_table t1
|join (
| select dt_str
| from dim_date
| where dt_int = 20201116
|) t2
|on t1.dt = t2.dt_str
|limit 1000
|""".stripMargin).show(10, false)
SQL Plan
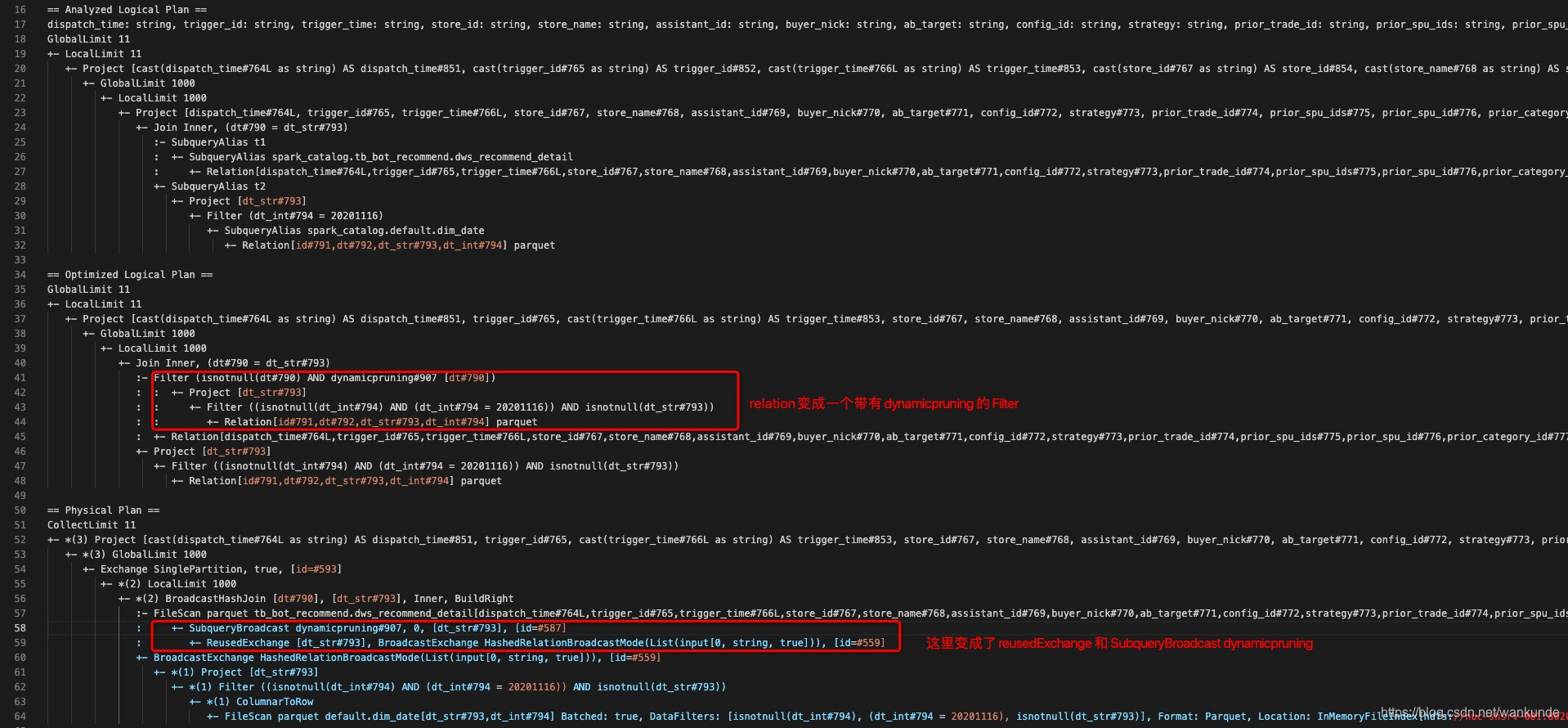
源码走读
通过上面SQL的执行计划可以看出,DPP的优化主要发生在Optimizer 优化和 Physical Plan生成两个阶段。接下来分析一下实现的主要代码。
PartitionPruning 逻辑计划优化
PartitionPruning Rule的优化结果是在可以进行DPP的relation替换成 Filter(DynamicPruningSubquery(..), pruningPlan) 对象。
其中有一个对于canPruneLeft() 和 canPruneRight() 的判断逻辑说要说明一下:
| JOIN 类型 | canPruneLeft | canPruneRight | 逻辑说明 | |
|---|---|---|---|---|
| INNER JOIN: | TRUE | TRUE | 两边都支持分区过滤,没问题 | |
| LEFT OUTER JOIN | FALSE | TRUE | 此时Left table数据是全的,Right Table是不全的,所以只能Broadcast Left table, 然后根据Left Table的结果去Prune Right Table Partition; 反之,Broadcast Right table来对Left Table Prune的时候,会导致Left Table读取数据的造成数据丢失。 | |
| RIGHT OUTER JOIN | TRUE | FALSE | 和上面相反,只能Prune Left Table | |
| LEFT SIME JOIN | TRUE | FALSE | 这个也是要求Right Table数据是全的,以便于Left Table做Exists判断,所以等同于RIGHT OUTER JOIN |
object PartitionPruning extends Rule[LogicalPlan] with PredicateHelper {
/**
* Search the partitioned table scan for a given partition column in a logical plan
*/
def getPartitionTableScan(a: Expression, plan: LogicalPlan): Option[LogicalRelation] = {
// 迭代找plan的自节点,返回a 和 a属性来自的leafNode
val srcInfo: Option[(Expression, LogicalPlan)] = findExpressionAndTrackLineageDown(a, plan)
// leafNode如果是 LogicalRelation(fs: HadoopFsRelation, _), 取 fs的所有分区字段
// 如果a的属性为分区字段的子集,返回leafNode,否则返回None
srcInfo.flatMap {
case (resExp, l: LogicalRelation) =>
l.relation match {
case fs: HadoopFsRelation =>
val partitionColumns = AttributeSet(
l.resolve(fs.partitionSchema, fs.sparkSession.sessionState.analyzer.resolver))
if (resExp.references.subsetOf(partitionColumns)) {
return Some(l)
} else {
None
}
case _ => None
}
case _ => None
}
}
/**
* {
{
{ 具体负责插入DPP Filter}}}
*/
private def insertPredicate(
pruningKey: Expression,
pruningPlan: LogicalPlan,
filteringKey: Expression,
filteringPlan: LogicalPlan,
joinKeys: Seq[Expression],
hasBenefit: Boolean): LogicalPlan = {
val reuseEnabled = SQLConf.get.exchangeReuseEnabled
val index = joinKeys.indexOf(filteringKey)
if (hasBenefit || reuseEnabled) {
// insert a DynamicPruning wrapper to identify the subquery during query planning
Filter(
DynamicPruningSubquery(
pruningKey,
filteringPlan,
joinKeys,
index,
!hasBenefit || SQLConf.get.dynamicPartitionPruningReuseBroadcastOnly),
pruningPlan)
} else {
// abort dynamic partition pruning
pruningPlan
}
}
/**
* 主要是通过CBO分析,在进行prune后的代价是否足够的优化,不满足阀值,则禁止该分区下推
*/
private def pruningHasBenefit(
partExpr: Expression,
partPlan: LogicalPlan,
otherExpr: Expression,
otherPlan: LogicalPlan): Boolean = {
}
private def prune(plan: LogicalPlan): LogicalPlan = {
plan transformUp {
// skip this rule if there's already a DPP subquery on the LHS of a join
// 1. skip已经存在DPP的join
case j @ Join(Filter(_: DynamicPruningSubquery, _), _, _, _, _) => j
case j @ Join(_, Filter(_: DynamicPruningSubquery, _), _, _, _) => j
case j @ Join(left, right, joinType, Some(condition), hint) =>
var newLeft = left
var newRight = right
// extract the left and right keys of the join condition
// 2. 解析出join条件的keys
val (leftKeys, rightKeys) = j match {
case ExtractEquiJoinKeys(_, lkeys, rkeys, _, _, _, _) => (lkeys, rkeys)
case _ => (Nil, Nil)
}
// checks if two expressions are on opposite sides of the join
def fromDifferentSides(x: Expression, y: Expression): Boolean = {
def fromLeftRight(x: Expression, y: Expression) =
!x.references.isEmpty && x.references.subsetOf(left.outputSet) &&
!y.references.isEmpty && y.references.subsetOf(right.outputSet)
fromLeftRight(x, y) || fromLeftRight(y, x)
}
// 将join条件中的AND拆分为 Seq[Expression],然后遍历处理每个join condition expression
splitConjunctivePredicates(condition).foreach {
// 过滤Expression: EqualTo条件类型且EqualTo的两边属性分别属于join的左右表
case EqualTo(a: Expression, b: Expression)
if fromDifferentSides(a, b) =>
val (l, r) = if (a.references.subsetOf(left.outputSet) &&
b.references.subsetOf(right.outputSet)) {
a -> b
} else {
b -> a
}
// there should be a partitioned table and a filter on the dimension table,
// otherwise the pruning will not trigger
// partScan 为根据join条件解析得到的leafNode,也就是分区表Relation对象
var partScan = getPartitionTableScan(l, left)
if (partScan.isDefined && canPruneLeft(joinType) &&
hasPartitionPruningFilter(right)) {
val hasBenefit = pruningHasBenefit(l, partScan.get, r, right)
newLeft = insertPredicate(l, newLeft, r, right, rightKeys, hasBenefit)
} else {
partScan = getPartitionTableScan(r, right)
if (partScan.isDefined && canPruneRight(joinType) &&
hasPartitionPruningFilter(left) ) {
val hasBenefit = pruningHasBenefit(r, partScan.get, l, left)
newRight = insertPredicate(r, newRight, l, left, leftKeys, hasBenefit)
}
}
case _ =>
}
Join(newLeft, newRight, joinType, Some(condition), hint)
}
}
}
PlanDynamicPruningFilters 物理计划生成
数据处理主逻辑:
- case DynamicPruningSubquery
- 如果当前Plan中存在BroadcastHashJoinExec,且BroadcastHashJoinExec的build side就是上面的 buildPlan, canReuseExchange = true
- 创建BroadcastExchangeExec(mode, QueryExecution.prepareExecutedPlan(sparkSession, QueryExecution.createSparkPlan(buildPlan))) 对象
- 创建 InSubqueryExec(value, broadcastValues, exprId)对象
case class PlanDynamicPruningFilters(sparkSession: SparkSession)
extends Rule[SparkPlan] with PredicateHelper {
/**
* Identify the shape in which keys of a given plan are broadcasted.
*/
private def broadcastMode(keys: Seq[Expression], plan: LogicalPlan): BroadcastMode = {
val packedKeys = BindReferences.bindReferences(HashJoin.rewriteKeyExpr(keys), plan.output)
HashedRelationBroadcastMode(packedKeys)
}
/**
* {
{
{
* 数据处理逻辑:
* 1. case DynamicPruningSubquery
* 2. 如果当前Plan中存在BroadcastHashJoinExec,且BroadcastHashJoinExec的build side就是上面的 buildPlan, canReuseExchange = true
* 3. 创建BroadcastExchangeExec(mode, QueryExecution.prepareExecutedPlan(sparkSession, QueryExecution.createSparkPlan(buildPlan))) 对象
* 4. 创建 InSubqueryExec(value, broadcastValues, exprId)对象
* }}}
*/
override def apply(plan: SparkPlan): SparkPlan = {
if (!SQLConf.get.dynamicPartitionPruningEnabled) {
return plan
}
plan transformAllExpressions {
case DynamicPruningSubquery(
value, buildPlan, buildKeys, broadcastKeyIndex, onlyInBroadcast, exprId) =>
val sparkPlan = QueryExecution.createSparkPlan(
sparkSession, sparkSession.sessionState.planner, buildPlan)
// Using `sparkPlan` is a little hacky as it is based on the assumption that this rule is
// the first to be applied (apart from `InsertAdaptiveSparkPlan`).
val canReuseExchange = SQLConf.get.exchangeReuseEnabled && buildKeys.nonEmpty &&
plan.find {
case BroadcastHashJoinExec(_, _, _, BuildLeft, _, left, _) =>
left.sameResult(sparkPlan)
case BroadcastHashJoinExec(_, _, _, BuildRight, _, _, right) =>
right.sameResult(sparkPlan)
case _ => false
}.isDefined
if (canReuseExchange) {
val mode = broadcastMode(buildKeys, buildPlan)
val executedPlan = QueryExecution.prepareExecutedPlan(sparkSession, sparkPlan)
// plan a broadcast exchange of the build side of the join
val exchange = BroadcastExchangeExec(mode, executedPlan)
val name = s"dynamicpruning#${exprId.id}"
// place the broadcast adaptor for reusing the broadcast results on the probe side
val broadcastValues =
SubqueryBroadcastExec(name, broadcastKeyIndex, buildKeys, exchange)
DynamicPruningExpression(InSubqueryExec(value, broadcastValues, exprId))
} else if (onlyInBroadcast) {
// it is not worthwhile to execute the query, so we fall-back to a true literal
DynamicPruningExpression(Literal.TrueLiteral)
} else {
// we need to apply an aggregate on the buildPlan in order to be column pruned
val alias = Alias(buildKeys(broadcastKeyIndex), buildKeys(broadcastKeyIndex).toString)()
val aggregate = Aggregate(Seq(alias), Seq(alias), buildPlan)
DynamicPruningExpression(expressions.InSubquery(
Seq(value), ListQuery(aggregate, childOutputs = aggregate.output)))
}
}
}
}
物理执行计划
我们从 FileSourceScanExec 的 def doExecute(): RDD[InternalRow] 方法看起
- 在执行
execute()方法之前,SparkPlan会先等待所有subquery执行和updateResult()。对于DPP的subqueryInSubqueryExec会将subquery的结果 collect, 再 broadcast 出去,返回broadcast的引用resultBroadcast - 返回对象依赖于内部的
inputRDD对象 inputRDD由createReadRDD()创建,又主要分为两部分,一是确定要读哪些文件,包括分区过滤,Bucket处理以及第三方的文件处理插件;二是确定读文件的方法readFile- 偏函数
val readFile: (PartitionedFile) => Iterator[InternalRow]根据relation的 fileFormat创建读文件的方法(这块对于ORC 和 Parquet 还有特殊处理),包括参数filters = pushedDownFilters ++ dynamicPushedFilters - dynamicPushedFilters 是lazy对象,在实际Executor执行Task的时候,会执行
readFile()方法,对于DynamicPruningExpression实例,会先执行child.predicate()方法, 该方法会读取 broadcast 的数据,存储到result对象中,然后根据该结果返回inSet对象 - Inset 对象就是一个大set,在执行
def eval(input: InternalRow): Any和def doGenCode(ctx: CodegenContext, ev: ExprCode)的时候,根据传入的row 数据,到 set 中判断数据是否存在,达到过滤数据的效果
@transient
private lazy val dynamicPushedFilters = {
dataFilters.flatMap {
case DynamicPruningExpression(child: InSubqueryExec) => Some(child.predicate)
case _ => Nil
}.flatMap(DataSourceStrategy.translateFilter(_, supportNestedPredicatePushdown))
}
abstract class SparkPlan extends QueryPlan[SparkPlan] with Logging with Serializable {
/**
* Executes a query after preparing the query and adding query plan information to created RDDs
* for visualization.
*/
protected final def executeQuery[T](query: => T): T = {
RDDOperationScope.withScope(sparkContext, nodeName, false, true) {
prepare()
waitForSubqueries()
query
}
}
/**
* Blocks the thread until all subqueries finish evaluation and update the results.
*/
protected def waitForSubqueries(): Unit = synchronized {
// fill in the result of subqueries
runningSubqueries.foreach {
sub =>
sub.updateResult()
}
runningSubqueries.clear()
}
}
case class InSubqueryExec(
child: Expression,
plan: BaseSubqueryExec,
exprId: ExprId,
private var resultBroadcast: Broadcast[Set[Any]] = null) extends ExecSubqueryExpression {
@transient private var result: Set[Any] = _
@transient private lazy val inSet = InSet(child, result)
def updateResult(): Unit = {
val rows = plan.executeCollect()
result = rows.map(_.get(0, child.dataType)).toSet
resultBroadcast = plan.sqlContext.sparkContext.broadcast(result)
}
def predicate: Predicate = {
prepareResult()
inSet
}
private def prepareResult(): Unit = {
require(resultBroadcast != null, s"$this has not finished")
if (result == null) {
result = resultBroadcast.value
}
}
}
case class InSet(child: Expression, hset: Set[Any]) extends UnaryExpression with Predicate {
protected override def nullSafeEval(value: Any): Any = {
if (set.contains(value)) {
true
} else if (hasNull) {
null
} else {
false
}
}
}