1. 漏桶是出,令牌是进 2. 令牌是允许伸缩
漏桶算法
漏桶算法(Leaky Bucket)是网络世界中流量整形(Traffic Shaping)或速率限制(Rate Limiting)时经常使用的一种算法,它的主要目的是控制数据注入到网络的速率,平滑网络上的突发流量。漏桶算法提供了一种机制,通过它,突发流量可以被整形以便为网络提供一个稳定的流量。
漏桶可以看作是一个带有常量服务时间的单服务器队列,如果漏桶(包缓存)溢出,那么数据包会被丢弃。 在网络中,漏桶算法可以控制端口的流量输出速率,平滑网络上的突发流量,实现流量整形,从而为网络提供一个稳定的流量。
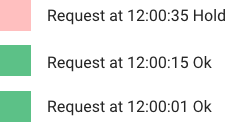
如图所示,把请求比作是水,水来了都先放进桶里,并以限定的速度出水,当水来得过猛而出水不够快时就会导致水直接溢出,即拒绝服务。
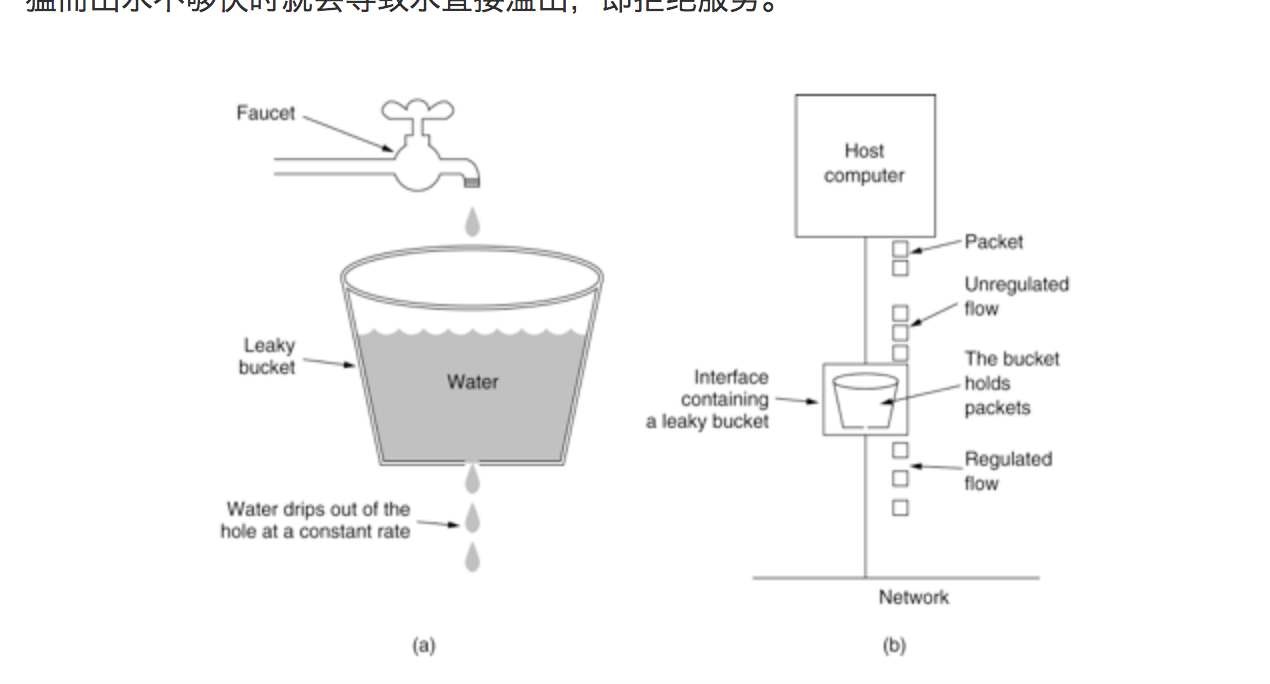
image.png
可以看出,漏桶算法可以很好的控制流量的访问速度,一旦超过该速度就拒绝服务。
令牌桶算法
令牌桶算法是网络流量整形(Traffic Shaping)和速率限制(Rate Limiting)中最常使用的一种算法。典型情况下,令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送。
令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。从原理上看,令牌桶算法和漏桶算法是相反的,一个“进水”,一个是“漏水”。
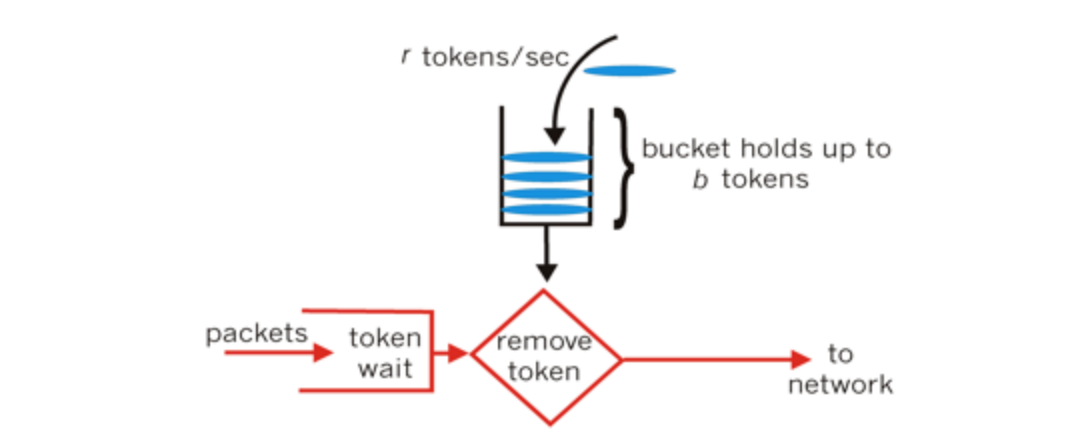
image.png
Google的Guava包中的RateLimiter类就是令牌桶算法的解决方案。
漏桶算法和令牌桶算法的选择
漏桶算法与令牌桶算法在表面看起来类似,很容易将两者混淆。但事实上,这两者具有截然不同的特性,且为不同的目的而使用。
漏桶算法与令牌桶算法的区别在于,漏桶算法能够强行限制数据的传输速率,令牌桶算法能够在限制数据的平均传输速率的同时还允许某种程度的突发传输。
需要注意的是,在某些情况下,漏桶算法不能够有效地使用网络资源,因为漏桶的漏出速率是固定的,所以即使网络中没有发生拥塞,漏桶算法也不能使某一个单独的数据流达到端口速率。因此,漏桶算法对于存在突发特性的流量来说缺乏效率。而令牌桶算法则能够满足这些具有突发特性的流量。通常,漏桶算法与令牌桶算法结合起来为网络流量提供更高效的控制。
常用的算法介绍
从简单到复杂依次介绍了如下几种算法:
-
Leaky Bucket
-
Fixed Window
-
Sliding Log
-
Sliding Window
Leaky Bucket
桶算法,做法是预先设置一个请求数的上限,小于这个上限的时候会接收请求, 大于这个上限的话会直接拒绝,只有等到系统处理掉了一些在桶里的请求, 桶里有新的坑位了,才会接收新的请求。
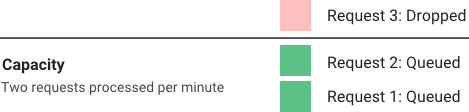
image
优点:
-
能够平滑请求数,使系统以一个均匀的速率处理请求
-
容易实现,可以用一个队列/FIFO 来做
-
可以只用很小的内存做到为每个用户限流
缺点:
-
桶满了以后,新的请求都会被扔掉,系统忙着处理旧请求
-
无法保证请求能够在一个固定的时间内处理完
Fixed Window
固定窗口算法,设置一个时间段内(窗口)接收的请求数,超过的这个请求数的请求会被丢弃。
-
窗口通常选择人们熟悉的时间段:1 分钟/1小时
-
窗口的起始时间通常是当前时间取地板(floor),比如 12:00:03 所在的窗口 (以一分钟的窗口为例)就是 12:00:00 - 12:01:00
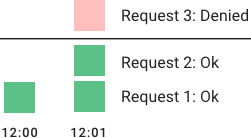
image
优点:
-
和漏桶相比,能够让新来的请求也能够被处理到
缺点:
-
在窗口的起始时间,最差情况下可能会带来 2 倍的流量
-
很多消费者可能都在等待窗口被重置,造成惊群效应
Sliding Log
滑动日志算法,利用记录下来的用户的请求时间,请求数,当该用户的一个新的 请求进来时,比较这个用户在这个窗口内的请求数是否超过了限定值,超过的话 就拒绝这个请求。
image
优点:
-
避免了固定窗口算法在窗口边界可能出现的两倍流量问题
-
由于是针对每个用户进行统计的,不会引发惊群效应
缺点:
-
需要保存大量的请求日志
-
每个请求都需要考虑该用户之前的请求情况,在分布式系统中尤其难做到
Sliding Window
滑动窗口算法,结合了固定窗口算法的低开销和滑动日志算法能够解决的边界情 况。
-
为每个窗口进行请求量的计数
-
结合上一个窗口的请求量和这一个窗口已经经过的时间来计算出上限,以此 平滑请求尖锋
举例来说,限流的上限是每分钟 10 个请求,窗口大小为 1 分钟,上一个 窗口中总共处理了 6 个请求。现在假设这个新的窗口已经经过了 20 秒,那么 到目前为止允许的请求上限就是 10 - 6 * (1 - 20 / 60) = 8。
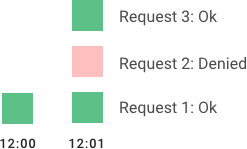
image
滑动窗口算法是这些算法中最实用的算法:
-
有很好的性能
-
避免了漏桶算法带来的饥饿问题
-
避免了固定窗口算法的请求量突增的问题
分布式实现
同步的策略
难点在于限流上限都是针对全站的流量设置的,那么每个节点该如何协调各自处理的量呢?
解决的方法通常都是使用一个统一的数据库来存放计数,比如 Redis 或者 Cassandra。 数据库中将存放每个窗口和用户的计数值。这种方法的主要问题是需要多访问一次数据库, 以及竞争问题。
竞争问题

image
竞争问题就是当有两个以上的线程同时执行 i += 1 的时候,如果没有同步这 些操作的话,i 的值可能会有多种情况。
处理竞争问题可以通过加锁来做,不过在限流的场景下,这样做肯定会成为系统的瓶颈, 毕竟限流时每个请求都会来竞争这个锁。
更好的办法是通过 set-then-get 的方法,限流场景中用到的只是计数 +1, 利用这一点以及数据库实现的性能更好的原子操作可以达到我们的目的。
性能优化

image
利用集中式的数据库的另一个问题是每次请求都要查一下数据库带来的延迟开销, 数据库再快也会带来几毫秒的延迟。
解决这个问题的方法可以通过在内存里面维护一个计数值,代价是稍微的放松限 流的精确度。通过设置一个定时任务从数据库拿计数值,周期内在内存中维护这 个计数,周期结束时把计数同步到数据库并拿取新的计数,如此往复。
这个同步周期往往是做成可以配置的,小的周期能够带来更精确的限流, 大的周期则能减轻数据库的 I/O 压力。
python 可用limits库
https://github.com/hugoren/limits
可选用的limit策略
