原文:https://www.cnblogs.com/lshs/p/6038547.html
一、快速重传介绍
按照TCP协议,RTO超时重传是一个非常重要的事件,当RTO超时的时候,TCP会同时通过两种方式非常谨慎的降低发送数据包的速率,一种是基于拥塞控制削减发送窗口的大小,另外一个是通过指数回退增加每次RTO超时的时间(即karn算法的第二部分)。所以RTO超时后有可能会导致网络容量的利用不足。
最开始我们介绍tcp重传的时候就介绍过TCP还有另外一种重传方式--快速重传。快速重传是RFC5681定一个的一个过程。快速重传不依赖定时器的超时,而是依靠ACK确认包来进行重传。使用快速重传相比RTO超时重传通常可以更高效的修复TCP丢包问题。快速重传是基于一个前提:即按照RFC5681,当TCP收到一个乱序报文的时候应该立即回复ACK确认包,而不会延迟ACK(延迟ACK介绍参考之前文章介绍)确认。另外RFC5681还指出如果接收序列号空间存在洞,新接收的报文完全填充了这个洞或者部分填充了这个洞,TCP也应该立即回复一个ACK确认包以便发送端及时获取接收端相关的信息。
我们举个例子假设有5个TCP报文,P1(1-10)、P2(11-20)、P3(21-30)、P4(31-40)、P5(41-50),其中括号中标注的是报文的比特系列号,每个报文的长度都为10bytes。假设发送端依次发送这5个报文,其中P2报文在网络传输过程中丢失,P1、P3、P4、P5报文依次按序到达,接收端收到这P1的时候发送ack=11的确认包(实际上这里可能会延迟发送ACK报文,为了描述简单我们假设立即发送ACK报文),接收端收到P3的时候发现是乱序的报文则会立即回复ack=11确认包(还记得ACK是累计确认的吧,因为P2丢失了ACK只能累计到11),同样后面收到P4和P5的时候还是会回复ack=11的确认包。这样发送端就会连续接收到4个ack=11的确认包,后面三个确认包因为和第一个ack number重复,因为称呼为duplicate ACK。因此接收端就可以依据dup ACK来推测接收端的接收情况。但是我们之前说过IP层不会向TCP提供有序的数据报文,如果网络传输过程中发生乱序导致接收端接收顺序变为P1、P3、P2、P4、P5,这样的情况下也会产生一个dup ACK。另外还有一种情况是IP层dup了ACK报文。我们通过一个dup ACK并不能可靠的确认是发生了丢包还是发生了乱序传输,因此会存在一个门限(duplicate ACK threshold或者叫做dupthresh),当TCP收到的dup ACK数超过这个门限的时候,就会认为发生了丢包,进而初始化一个快速重传。最初协议中给出的dupthresh这个门限是3,但是RFC 4653给出了一种调整dupthresh的方法。Linux中则可以通过/proc/sys/net/ipv4/tcp_reordering来设置默认值,另外Linux可能还会根据乱序测量的结果来更新实际的dupthresh。dupthresh的范围最终会在/proc/sys/net/ipv4/tcp_reordering和/proc/sys/net/ipv4/tcp_max_reordering之间。在没有使能SACK的时候,快速重传只会重传一个数据包,在使能SACK时候,SACK可以反映接收端是否存在系列号洞,进而允许发送端根据SACK的情况同时传输多个数据包。SACK的内容留到后面介绍。
最后补充一下window update的判断,一般如果一个TCP报文满足下面三个条件之一的话,linux就会认定这个报文是window update消息,被认定为window update的确认包是不会统计到dup ACK里面的,后面介绍窗口管理的时候还会进一步介绍一下window update。
1、ack number比之前接收的最大的ack number还要大
2、系列号seq比之前接收到的最大系列号还要大
3、系列号seq与之前接收到的系列号相同,但是TCP头中的window size字段发生了变化
二、wireshark示例
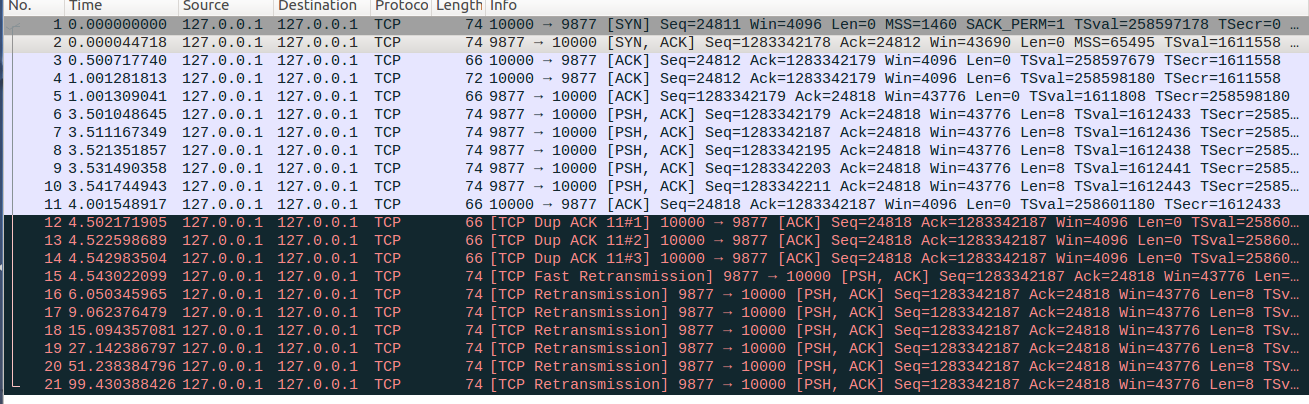
1、快速重传与RTO超时
设置/proc/sys/net/ipv4目录下tcp_retries2=8,tcp_early_retrans=0,tcp_sack=0,tcp_reordering=3,tcp_discard_on_port =9877(该参数为自加参数)。
-
client通过rawsocket与server建立连接,对应No1-No3报文
-
client先发送6bytes的数据,服务器回复ACK确认包,对应No4-No5报文
-
服务器连续发送5个len=8的报文,对应No6-No10
-
client对No6报文回复ACK确认报文,对应No11
-
client丢弃No7报文来模拟传输过程中丢包,并对No8-No10报文回复dupACK,对应No12-No14
-
server端在收到三个dup ACK后,认为No7报文已经丢失并立即触发快速重传,同时设置RTO超时定时器,对应No15
-
client对之后收到的报文直接丢弃不在回复ACK确认包
-
server端RTO超时后,继续重传对应的报文,并进行指数回退过程。最终多次RTO超时重传失败后,server端释放TCP连接,对应No16-No21。
2、快速重传与window update消息
设置/proc/sys/net/ipv4目录下tcp_retries2=8,tcp_early_retrans=0,tcp_sack=0,tcp_reordering=3,tcp_discard_on_port =9877(该参数为自加参数)。
-
client通过rawsocket与server建立连接,对应No1-No3报文
-
client先发送6bytes的数据,服务器回复ACK确认包,对应No4-No5报文
-
服务器连续发送5个len=8的报文,对应No6-No10
-
client丢弃No6报文来模拟传输过程中丢包,并对No7-No10报文回复dupACK,对应No11-No14
-
从wireshark抓包看,server端在收到四个dup ACK后,才认为No6报文已经丢失并立即触发快速重传,同时设置RTO超时定时器,对应No15
-
client对之后收到的报文直接丢弃不在回复ACK确认包
-
server端RTO超时后,继续重传对应的报文,并进行指数回退过程。最终多次RTO超时重传失败后,server端释放TCP连接,对应No16-No21。
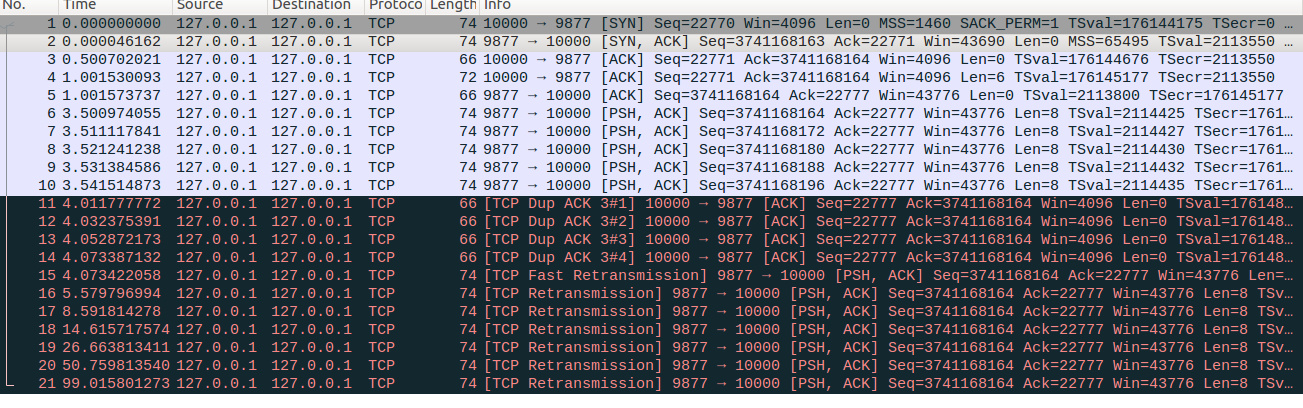
那么这里问题来了,我们设置的tcp_reordering为3,也就是dupthresh值为3(实际上dupthresh可以动态调整,但是在这次测试中没有发生调整),那为什么这里快速重传的触发需要四个dup ACK呢?原因是这里No11对应的ACK报文,相比于No4的ACK报文虽然ack number都为3741168164,但是两者的Seq却发生了变化,因此linux认为No11是一个window update消息,而linux并不把window update消息计入dup ACK,后面收到的No12-No14报文才会被TCP认为是dup ACK,因此直到收到No14报文TCP才会认为dup ACK达到快速重传门限,触发快速重传。这里也反映了wireshark和linux在dup ACK认定上的差异性。
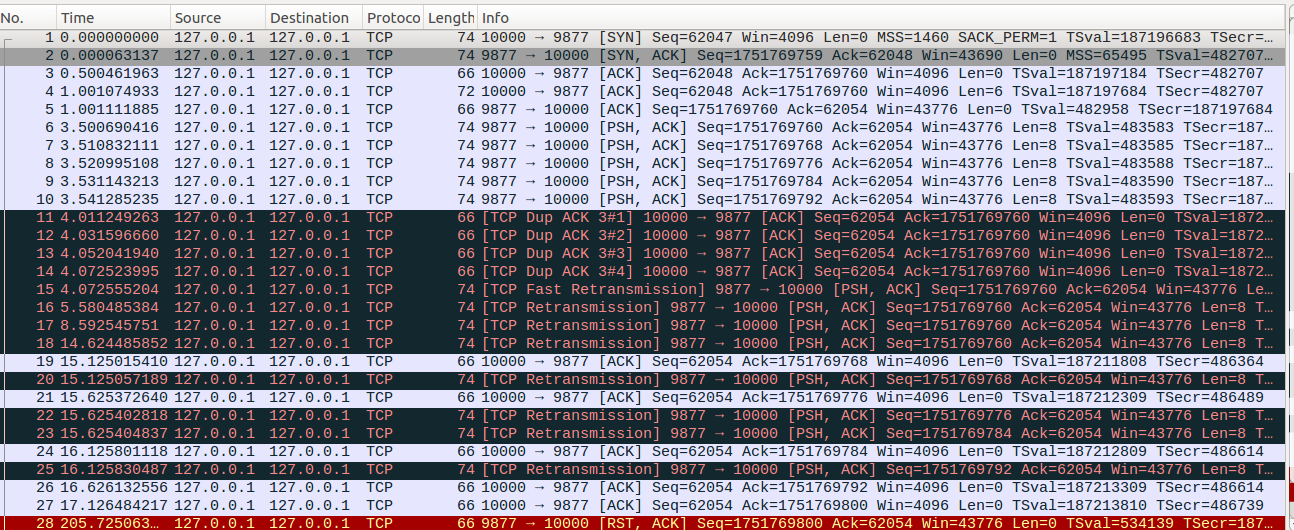
3、快速重传与recovery point
下面我们在看一个快速重传后触发RTO超时重传然后收到ACK确认包的场景。这个测试过程与上一个示例类似,差异部分在于接收端在收到No18的重传报文以及之后的报文的时会回复一个ACK确认包。我们可以看到在触发快速重传之前,正常传输的数据中最高系列号的下一个待发送系列号为No10报文对应的1751769800(即1751769792+8),这个系列号节点称呼为recovery point,而No19确认包中Ack=1751769768小于之前的1751769800,对于这种ACK确认报文,TCP称呼为partial ACK。在TCP收到parital ACK报文的时候则会立即触发快速重传,如No20、No22、No23、No25所示。截图中最后一个RST消息则是由于server端应用层没有读取server缓存中的数据(No4报文的数据)而直接close,因此会产生RST消息。实际的消息流中还有一个No29消息则是由于client使用raw socket编写的程序没有处理server端的RST消息,client关闭的时候简单的发送了一条RST消息来通知server。
我们同时注意到,在发送端收到No19一个ACK确认包的时候,只是发出去了一个重传包,而在收到No21确认包的时候,TCP却发出去了两个重传包。这种差异则是由于TCP的拥塞控制造成的,后面我们讲到拥塞控制的时候在通过几个示例来介绍说明。
补充说明:
1、快速重传代码点tcp_fastretrans_alert,window update消息和dup ack的判断在tcp_ack_update_window和tcp_ack中