学习自:
- https://blog.csdn.net/zxzxzx0119/article/details/79826380
- https://zhuanlan.zhihu.com/p/42586566
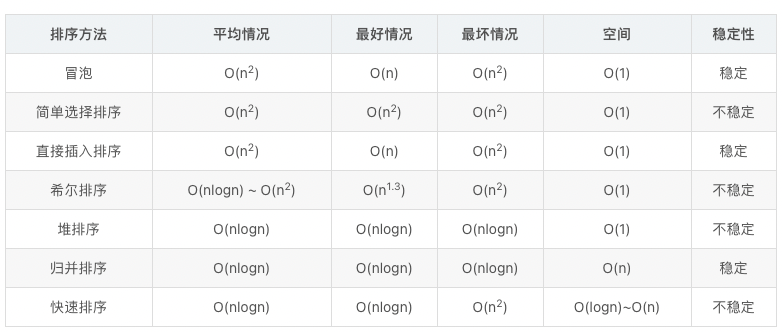
对常见的排序算法进行三方面总结:
- 基本思路与实现
- 稳定性
- 复杂度分析
文章目录
一、总览
什么是排序算法的稳定性?
简单来说如果原本数组中的两个相等的数的次序为相对一前一后,排序结束后仍然为相对一前一后,那么就可以说这个排序算法是稳定的。即保证排序前后两个相等的数的相对顺序不会改变
所以在具体的排序算法中可以进行特定的处理改变稳定性
举例:对于冒泡排序,原本是稳定的排序算法,如果将记录交换的条件改成arr[i] >= arr[i + 1],则两个相等的记录就会交换位置,从而变成不稳定的排序算法。
二、冒泡排序
1. 基本思路
每次沉底一个最大的数,将大的数一直向后交换,大的沉底,小的自动上浮
func bubbleSort(nums []int) {
// i:当前需要冒泡的数组长度
for i:=len(nums)-1; i>0; i-- {
// j:冒泡的位置
for j:=0; j<i; j++ {
// 如果前一个数大就和后一个交换,不断沉底
if nums[j] > nums[j+1] {
nums[j], nums[j+1] = nums[j+1], nums[j]
}
}
}
}
时间复杂度:
- 最好 O ( N ) O(N) O(N): 唯一的情况是数组已经有序
- 平均 O ( N 2 ) O(N^2) O(N2)
- 最差 O ( N 2 ) O(N^2) O(N2)
优化思路一: 设立flag,如果当前长度没有发生任何交换,则说明已经有序,直接结束
func bubbleSort(nums []int) {
flag := true
// i:当前需要冒泡的数组长度
for i:=len(nums)-1; i>0; i-- {
// j:冒泡的位置
for j:=0; j<i; j++ {
// 如果前一个数大就和后一个交换,不断沉底
if nums[j] > nums[j+1] {
nums[j], nums[j+1] = nums[j+1], nums[j]
// 一旦发生了交换,就改变标记
flag = false
}
}
// 一旦发现没有交换就直接结束
if flag {
break
}
}
}
时间复杂度:平均优化到 O ( N ) O(N) O(N)
优化思路二:记录上次最后一次交换的位置,最后一次交换位置后面的位置都是有序的,所以只需要到达这个位置即可
func bubbleSort(nums []int) {
flag := true
// i:当前需要冒泡的数组长度
for i:=len(nums)-1; i>0; i-- {
// 记录上一次结束位置,初始化时为i
end := i
// j:冒泡的位置
for j:=0; j<i; j++ {
// 如果前一个数大就和后一个交换,不断沉底
if nums[j] > nums[j+1] {
nums[j], nums[j+1] = nums[j+1], nums[j]
// 一旦发生了交换,就改变标记
flag = false
// 记录最后一次交换位置
end = j+1
}
}
// 替换i
i = end
// 一旦发现没有交换就直接结束
if flag {
break
}
}
}
2. 稳定性
因为当两个数相等时不交换,所以稳定
3. 复杂度分析
时间复杂度:
- 最好 O ( N ) O(N) O(N): 唯一的情况是数组已经有序
- 平均 O ( N 2 ) O(N^2) O(N2),优化后可到达 O ( N ) O(N) O(N)
- 最差 O ( N 2 ) O(N^2) O(N2)
空间复杂度 O ( 1 ) O(1) O(1)
三、选择排序
1. 基本思路
每次找到最大的,然后与最后一个数交换
func selectSort(nums []int) {
// 一共需要n-1次
for i:=0; i<len(nums)-1; i++ {
maxIndex := 0
for j:=0; j<len(nums)-i; j++ {
if nums[j] > nums[maxIndex] {
maxIndex = j
}
}
// 和最后一个交换
nums[maxIndex], nums[len(nums)-i-1] = nums[len(nums)-i-1], nums[maxIndex]
}
}
2. 稳定性
用数组实现的选择排序是不稳定的,用链表实现的选择排序是稳定的
一般排序算法描述的都是数组,所以可以说是不稳定的
3. 复杂度分析
时间复杂度:
- 最好 O ( N 2 ) O(N^2) O(N2)
- 平均 O ( N 2 ) O(N^2) O(N2),优化后可到达 O ( N ) O(N) O(N)
- 最差 O ( N 2 ) O(N^2) O(N2)
空间复杂度 O ( 1 ) O(1) O(1)
四、插入排序
1. 基本思路
从前往后维护一个有序窗口,每次考察窗口的下一个元素,如果比窗口的最右侧/最大元素小,则从右往左遍历窗口直到合适顺序的地方插入。初始化认为数组的第一个位置有序。 (像是一种向前的冒泡排序)
func insertSort(nums []int) {
// i: 这个有序窗口的最右边位置的下一个考察的位置, 起始位置0默认有序
for i:=1; i<len(nums); i++ {
// 从窗口的下一个判定位置,一直向左遍历
for j:=i; j>0; j-- {
// 如果当前位置j比窗口位置j-1小,则一直向右侧交换
if nums[j] < nums[j-1] {
nums[j], nums[j-1] = nums[j-1], nums[j]
}else {
// 如果已经大于,那么就已将该元素加入到了有序窗口
break
}
}
}
}
优化思路:二分法查找插入排序的位置
func insertSort(nums []int) {
// i: 有序窗口的下一个考察的位置(target), 起始位置0默认有序
for i:=1; i<len(nums); i++ {
// 二分法找出当前窗口中合适顺序的位置,插入
l, r, target := 0, i-1, nums[i]
for l <= r {
mid := (l+r) >> 1
if nums[mid] < target {
l = mid+1
}else {
// 即使找到了相同的值,也舍去,目的是找到合适插入的位置(刚好大于target的位置)
r = mid-1
}
}
// l就是刚好大于target的位置
// 从i开始移位,赋值
for j:=i; j>=l+1; j-- {
nums[j] = nums[j-1]
}
//插入
nums[l]= target
}
}
2. 稳定性
如果遇到相同的值比较,不会进行交换,所以是稳定的
3. 复杂度分析
在数组较大的时候不适用。但是,在数据比较少的时候,是一个不错的选择,一般做为快速排序的扩充。
时间复杂度:
- 最好 O ( N ) O(N) O(N)
- 平均 O ( N 2 ) O(N^2) O(N2)
- 最差 O ( N 2 ) O(N^2) O(N2)
空间复杂度 O ( 1 ) O(1) O(1)
五、希尔排序
1. 基本思路
希尔排序使更高效的插入排序,它的思想在于:
- 把数组分成几块,每一块进行一个插入排序;
- 而分块的依据在于增量的选择分好块之后,从gap开始到n,每一组和它前面的元素(自己组内的)进行插入排序;
每次和组内的元素比较完之后,最后的元素基本就是有序的了,希尔排序相对于插入排序的优势在于插入排序每次只能将数据移动一位,在数组较大且基本无序的情况下性能会迅速恶化。

func shellSort(nums []int) {
// gap每次减小为原来的一半
for gap:=len(nums)/2; gap>0; gap/=2 {
// i为每个分组的起始位置
for i:=0; i<gap; i++ {
// 下面对每个分组进行插入排序
for j:=i+gap; j<len(nums); j+=gap {
for k:=j; k>i; k-=gap {
if nums[k-gap] > nums[k] {
nums[k-gap], nums[k] = nums[k], nums[k-gap]
}else {
break
}
}
}
}
}
}
2. 稳定性
不稳定。插入排序是一种稳定的排序算法,但是希尔排序不是,因为在多次插入的过程中,相同元素完全有可能在不同的插入轮次中移动破坏稳定性
3. 复杂度分析
时间复杂度:
- 最好 O ( N 1.3 ) O(N^{1.3}) O(N1.3)
- 平均 O ( N l o g N ) O(NlogN) O(NlogN)~$ O(N^2)$
- 最差 O ( N 2 ) O(N^2) O(N2)
空间复杂度 O ( 1 ) O(1) O(1)
希尔排序时间复杂度的大小还是要取决于步长的合适度
在大量数据面前,Shell排序不是一个好的算法。但是,中小型规模的数据完全可以使用它。
六、快速排序
1. 基本思路
- 从数列中挑出一个元素,称为"基准/轴值"(pivot),
- 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任何一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归地(recursively)把小于基准值元素的子数列和大于基准值元素的子数列排序。
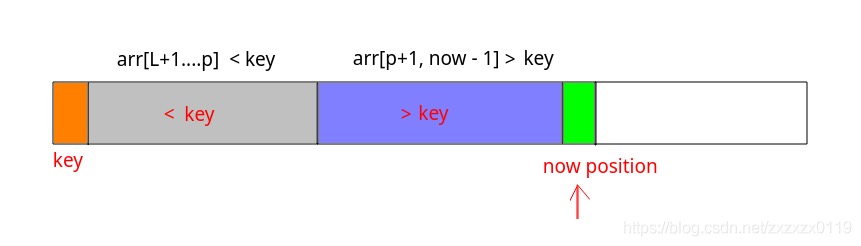
func quickSort(nums []int) {
var quickProcess func(int, int)
gitMid := func(l, r int) int {
pivot := nums[l]
for l < r {
for l < r && nums[r] >= pivot {
r-- }
nums[l] = nums[r]
for l < r && nums[l] <= pivot {
l++ }
nums[r] = nums[l]
}
nums[l] = pivot
return l
}
quickProcess = func(l, r int) {
if l < r {
mid := gitMid(l, r)
// 左半部
quickProcess(l, mid-1)
// 右半部
quickProcess(mid+1, r)
}
}
quickProcess(0, len(nums)-1)
}
缺点: 如果每次选择的pivot都是极端数值(最大或者最小),导致后面划分的数组极度不平衡,复杂度灰降低到 O ( N 2 ) O(N^2) O(N2)

改进策略: 随机快排/快速选择(就是选择pivot时不选择最左边的而是随机选择)
func quickSort(nums []int) {
rand.Seed(time.Now().UnixNano()) // 随机种子
var quickProcess func(int, int)
gitMid := func(l, r int) int {
// 选取最左边为pivot
pivot := nums[l]
for l < r {
for l < r && nums[r] >= pivot {
r-- }
nums[l] = nums[r]
for l < r && nums[l] <= pivot {
l++ }
nums[r] = nums[l]
}
nums[l] = pivot
return l
}
quickProcess = func(l, r int) {
if l < r {
// 改为随机选择
randIdx := rand.Int() % (r-l+1) + l
// 与最左边的数交换
nums[randIdx], nums[l] = nums[l], nums[randIdx]
mid := gitMid(l, r)
// 左半部
quickProcess(l, mid-1)
// 右半部
quickProcess(mid+1, r)
}
}
quickProcess(0, len(nums)-1)
}
2. 稳定性
不稳定,因为我们无法保证相等的数据按顺序被扫描到和按顺序存放。
3. 复杂度分析
时间复杂度:
- 最好 O ( N l o g N ) O(NlogN) O(NlogN)
- 平均 O ( N l o g N ) O(NlogN) O(NlogN)
- 最差 O ( N 2 ) O(N^2) O(N2)
空间复杂度 O ( l o g N ) O(logN) O(logN)~ O ( N ) O(N) O(N), O ( N ) O(N) O(N)是最坏情况,每次都选取到了最大/最小值,每次只能划分出一个数,调用栈的大小就是 O ( N ) O(N) O(N);如果每次运气都很好,选择的pivot都刚刚好平分数组,那么调用栈的时间复杂度就是 O ( l o g N ) O(logN) O(logN)
时间复杂度 O ( N l o g N ) O(NlogN) O(NlogN): 最优情况下, 对于每个pivot都需要折半的递归调用,折半递归到最底层一个数的时间复杂度就是 O ( l o g N ) O(logN) O(logN)(共有 O ( l o g N ) O(logN) O(logN)层,有这么多次操作)。在每一层中,需要遍历 N N N个元素调换顺序,所以总的时间复杂度最优为 O ( N l o g N ) O(NlogN) O(NlogN)
七、归并排序
1. 基本思路
归并排序也是分治法一个很好的应用,先递归到最底层,然后从下往上每次两个序列进行归并合起来,是一个由上往下分开,再由下往上合并的过程,而对于每一次合并操作,对于每一次merge的操作过程如下:

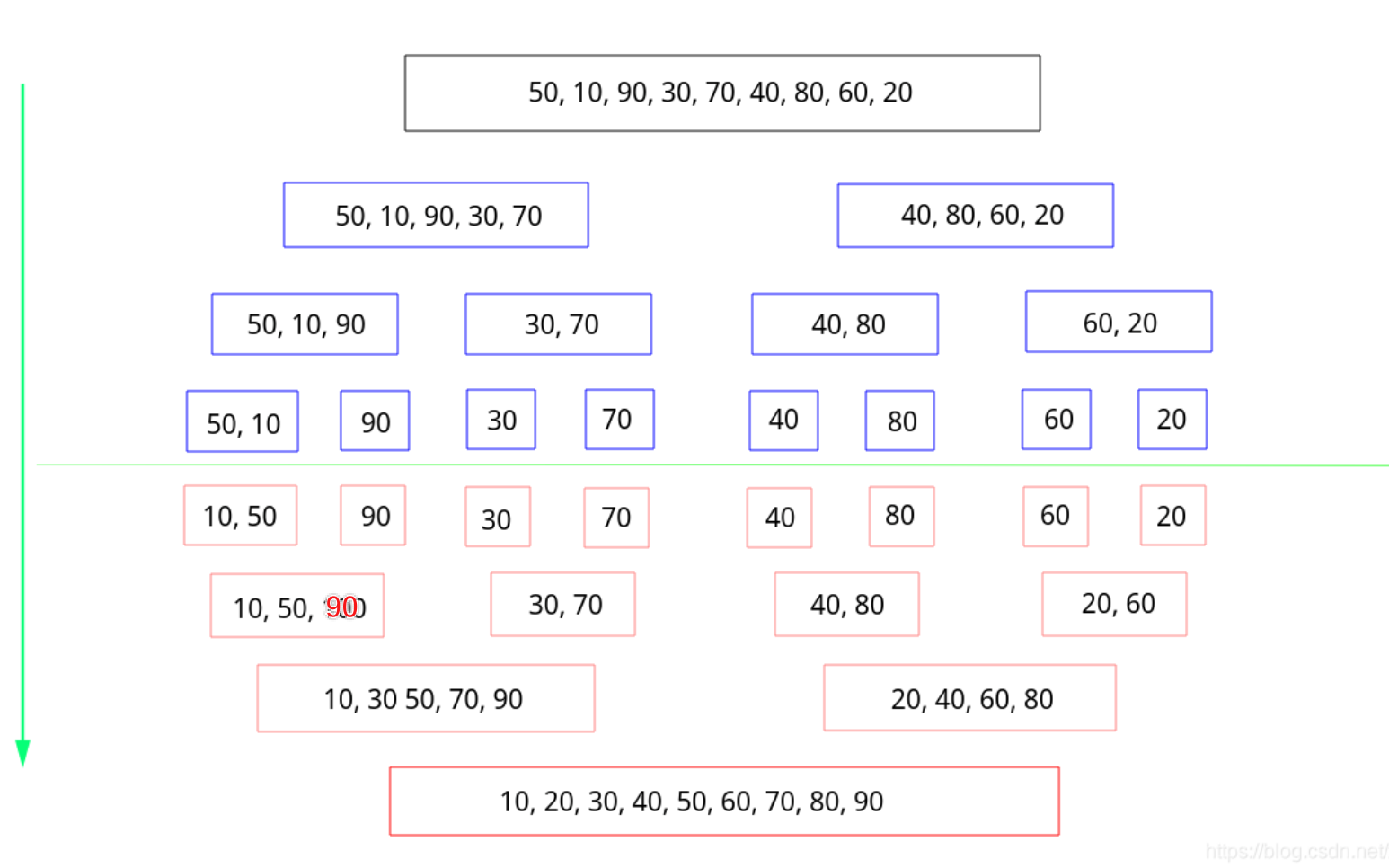
func mergeSort(nums []int) {
mergeProcess(nums, 0, len(nums)-1)
}
func mergeProcess(nums []int, l, r int) {
if l < r {
// 分为两部分
mid := l + (r-l) >> 1
// 左右分离
mergeProcess(nums, l, mid)
mergeProcess(nums, mid+1, r)
// 此时已经分割开,有序, 进行合并
if nums[mid] > nums[mid+1] {
// 优化:如果两个部分前后已经有序就不需要合并了
merge(nums, l, mid, r)
}
}
}
func merge(nums []int, l, mid, r int) {
// 两个部分的起始位置
p1, p2 := l, mid+1
// 创建中间辅助数组
help := make([]int, 0)
for p1<=mid && p2<=r {
if nums[p1] <= nums[p2] {
help = append(help, nums[p1])
p1 ++
}else {
help = append(help, nums[p2])
p2 ++
}
}
// 处理两边剩余部分
for p1 <= mid {
help = append(help, nums[p1])
p1++
}
for p2 <= r {
help = append(help, nums[p2])
p2++
}
// 赋值到原数组
for i, v := range help {
nums[l+i] = v
}
}
注意几点:
- 注意上面的代码中
if(arr[mid] > arr[mid+1])防止一开始数组很有序的情况; - 注意在外排比较的时候,为了保证稳定性,左右相等的时候,先拷贝左边的;
2. 稳定性
归并排序是稳定的
3. 复杂度分析
时间复杂度:
- 最好 O ( N l o g N ) O(NlogN) O(NlogN)
- 平均 O ( N l o g N ) O(NlogN) O(NlogN)
- 最差 O ( N l o g N ) O(NlogN) O(NlogN)
因为不断的二分区域,所以分到长度为1即只有一个数时的时间复杂度为 O ( l o g N ) O(logN) O(logN)(因为共有 O ( l o g N ) O(logN) O(logN)层,分了这么多次),再看每一层中都需要进行merge操作,看上面的过程图就可以发现每层不管分成几组几个,总的都是 N N N个,所以每一层merge操作的时间复杂度就是 O ( N ) O(N) O(N), 总体就是 O ( N l o g N ) O(NlogN) O(NlogN)
空间复杂度 O ( N ) O(N) O(N), 来源于其中的辅助数组
归并排序在数据量比较大的时候也有较为出色的表现(效率上),但是,其空间复杂度 O ( n ) O(n) O(n)使得在数据量特别大的时候(例如,1千万数据)几乎不可接受。而且,考虑到有的机器内存本身就比较小,因此,采用归并排序一定要注意。
八、堆排序
1. 基本思路
可用数组表示的完全二叉树。
-
已知父节点数组索引i
父节点是i, 则左子节点为2i,右子节点为2i+1
通常数据的0索引位置创建但不使用,根节点从index1开始,否则上述规律无意义
-
已知子节点数组索引为i
则其父节点索引为i/2,其当前层为i/2 (除2也可以用效率更高的位运算)
-
大顶堆:父节点的值比其所有子节点都大
-
小顶堆:父节点的值比其所有子节点都小
这里的“值”可以代表为任意属性优先值,进而得到优先队列(也就是堆):特殊的队列,取出元素的顺序按照元素的优先权而不是先后顺序
堆的根节点一定是最大/小值,但是节点的顺序未知
堆的原始操作,时间复杂度都为nlogk,k为按优先级分类的规模(例如按数组中元素出现次数划分,共有k个规模)
- 上浮 shift up: 向堆尾新加入一个元素,堆规模 +1,依次向上与父节点比较,如小于父节点就交换。
- 下沉 shift down: 从堆顶取出一个元素(堆规模 -1,用于堆排序)或者更新堆中一个元素(本题),依次向下与子节点比较,如大于子节点就交换。
堆排序的过程是一个反复调整堆的过程:
- 利用数组建立一个小顶堆;
- 调用
siftDown,把堆(无序区)的尺寸缩小1,取出栈顶元素,并从新的堆顶元素开始进行堆调整; - 重复步骤,直到堆的大小为
1;
// 堆排序
type myMinHeap []int // 小顶堆
func (h *myMinHeap) shiftUp(v int) {
*h = append(*h, v)
// 调换位置
i := len(*h)-1
for i > 1 && (*h)[i] < (*h)[i/2] {
// 小于父节点,调换位置
(*h)[i], (*h)[i/2] = (*h)[i/2], (*h)[i]
i /= 2
}
}
func (h *myMinHeap) shiftDown() int {
n := len(*h)
v := (*h)[1]
(*h)[1] = (*h)[n-1]
*h = (*h)[:n-1]
// 调整
minPoint, i := 1, 1
for {
// 找出父、左右孩子中最小的节点
if 2*i < n-1 && (*h)[i] > (*h)[2*i] {
minPoint = 2*i
}
if 2*i+1 < n-1 && (*h)[minPoint] > (*h)[2*i+1] {
minPoint = 2*i+1
}
if minPoint == i {
// 如果已经满足,则不需要调整了,因为底下本来就是有序的
break
}
// 将父节点与最小的交换
(*h)[i], (*h)[minPoint] = (*h)[minPoint], (*h)[i]
i = minPoint
}
return v
}
func heapSort(nums []int) {
// 创建小顶堆
minHeap := myMinHeap([]int{
0})
for _, v := range nums {
minHeap.shiftUp(v)
}
// 每次删除掉一个
for i:=0; i<len(nums); i++ {
nums[i] = minHeap.shiftDown()
}
}
2. 稳定性
不稳定
3. 复杂度分析
时间复杂度:
- 最好 O ( N l o g N ) O(NlogN) O(NlogN)
- 平均 O ( N l o g N ) O(NlogN) O(NlogN)
- 最差 O ( N l o g N ) O(NlogN) O(NlogN)
完美二叉树时间复杂度 O ( l o g N ) O(logN) O(logN), 每次删除一个共 N N N个最坏情况下操作 O ( N l o g N ) O(NlogN) O(NlogN)次
空间复杂度 O ( 1 ) O(1) O(1)
堆排序在建立堆和调整堆的过程中会产生比较大的开销,在元素少的时候并不适用。但是,在元素比较多的情况下,还是不错的一个选择。尤其是在解决诸如“前n大的数”一类问题时,几乎是首选算法。
觉得不错的话,请点赞关注呦~~你的关注就是博主的动力
关注公众号,查看更多go开发、密码学和区块链科研内容: