目录
索引
存储引擎支持的索引类型
索引是存储引擎用于快速查找记录的一种数据结构,索引有很多种类型,可以为不同的场景提供更好的性能。不同的存储引擎支持的索引类型不一样,即使多个存储引擎支持同一种索引类型,其底层的实现也有可能不同。MySQL中主要使用的索引结构是Hash和B+Tree.
| 存储引擎 | 支持的索引类型 |
|---|---|
| InnoDB | BTREE |
| MyISAM | BTREE |
| MEMORY/HEAP | HASH, BTREE |
| NDB | HASH,BTREE |
哈希索引
哈希索引基于哈希表实现,它根据给定的哈希函数Hash(Key)和处理冲突(不同索引列值有相同的哈希值)方法将每一个索引列值都映射到一个固定长度的地址,哈希索引只存储哈希值和行指针。

- 哈希索引只支持等值比较,包括=、in()、<=>,查询速度非常快。
- 哈希索引不支持范围查询。
二叉查找树
二叉查找树,也称之为二叉搜索树、二叉排序树,它的每个节点最多有两个子节点,左子树上的节点值均小于它的根节点值,右子树上的节点值均大于它的根节点值,左右子树也分别是二叉排序树。
- 二叉查找树可以做范围查询。
- 但是极端情况下,二叉树会退化成线性链表,二分查找也会退化成遍历查找。
红黑树
二叉查找树存在不平衡的问题,因此就有了自平衡二叉树,能够自动旋转和调整,让树始终处于平衡状态,常见的自平衡二叉树有红黑树和AVL树。红黑树是一种自平衡的二叉查找树。
- 通过自平衡解决了二叉查找树有可能退化成线性链表的问题。
- 但是极端情况下,红黑树有“右倾”趋势,并没有真正解决树的平衡问题。
平衡二叉树
平衡二叉树,又称AVL树,指的是左子树上的所有节点的值都比根节点的值小,而右子树上的所有节点的值都比根节点的值大,且左子树与右承树的嬴度差最大为1。
- AVL树从根本上解决了红黑树的“右倾”问题,查找效率得到提升,无极端低效情况。
- 数据库查询的瓶颈在磁盘I/O,数据量很大的情况下,AVL树的高度会很高,查询需要更多I/O。
B-Tree
B-Tree,即B树(不要读成B减树),它是一种多路搜索树(多叉树),可以在平衡二叉树的基础上2降低树的高度,从而提升查找效率。
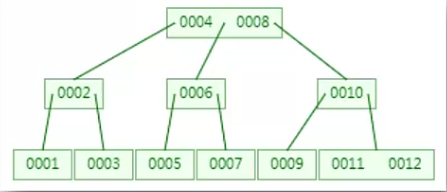
- B树通过多叉、一个节点可有多个值,有效地控制了树的高度,比平衡二叉树查询效率高。
- 但是范围查询的效率仍然有待提升(回到上一层结点)。
B+Tree
B+Tree是B树的变体,比B树有更广泛的应用。
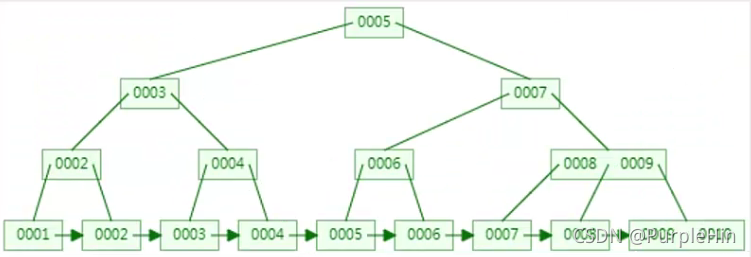
- +Tree在叶子节点增加了有序链表,包含了所有节点,非常适合范围查询。
- 非叶子节点存在部分冗余。
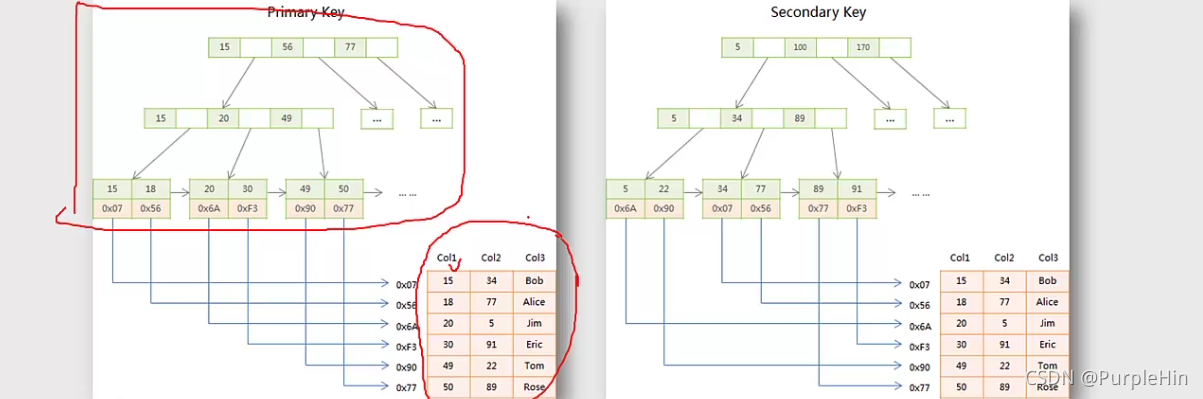
MyIASM索引结构
MyISAM存储引擎使用B+Tree作为索引结构,叶子节点的data域存放的是数据记录的地址。因此索引检索会按照B+Tree的检索算法检索索引,如果指定的Key存在,则取出其data域的值(地址),然后根据地址读取相应的数据记录。
InnoDB的索引结构
InnoDB存储引擎也使用B+Tree作为索引结构,但具体实现方式却跟MyISAM存储引擎截然不同,最主要的区别是InnoDB的数据文件本身也是B+Tree。MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址;而InnoDB的表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录,这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引文件。
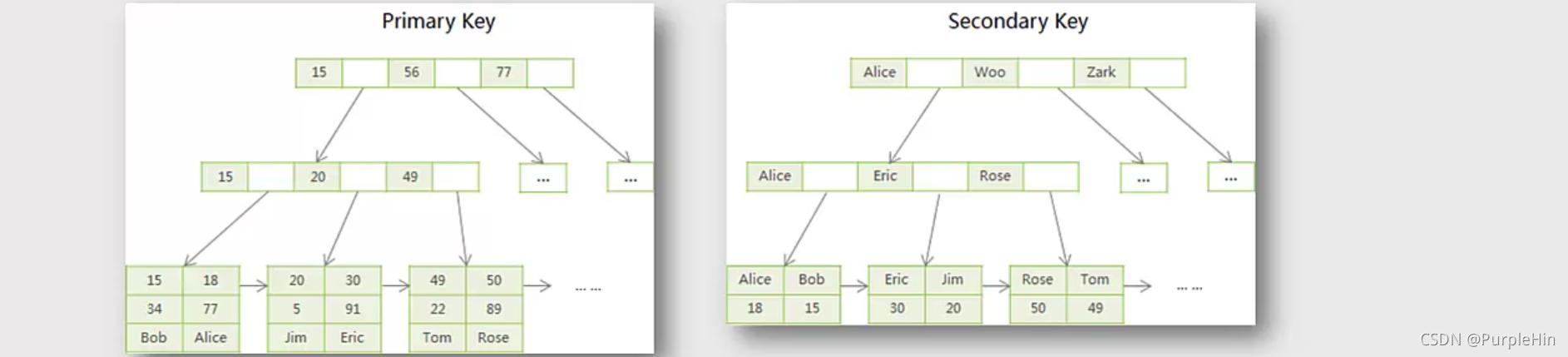
思考:为什么表必须要一个主键(primary key)?
- 找MyISAM中,如果是主键索引,data放置的是数据记录的地址。
- 在InnoDB中,如果是主键索引,他的data放的是数据记录,如果是辅助索引,他的data放的是主键,然后再根据主键去寻找数据记录。
事物与锁机制
事物的四个特性
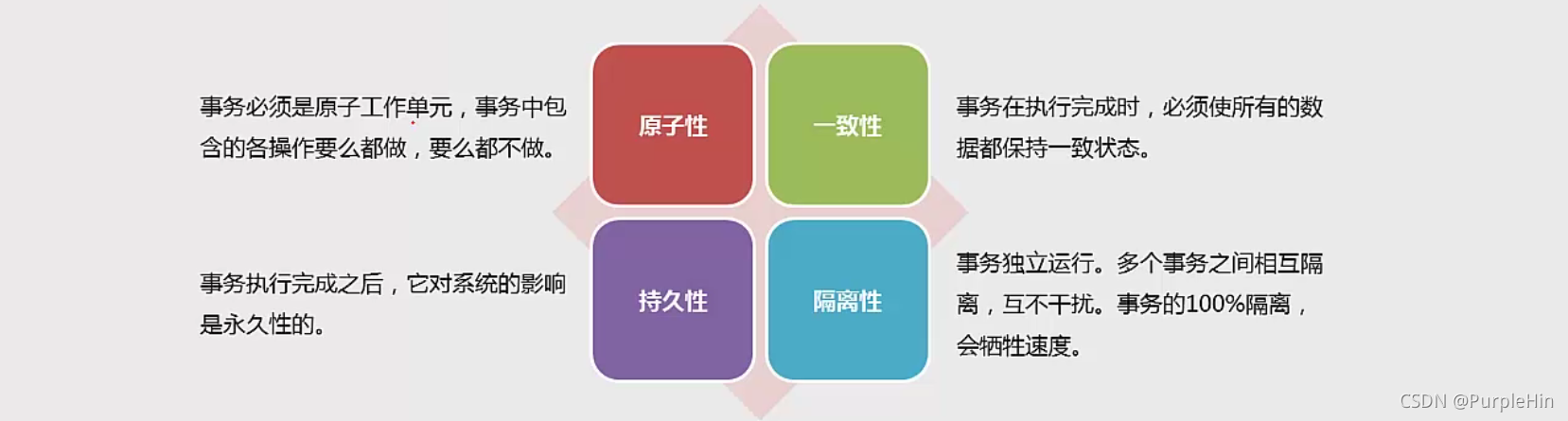
如果某个数据库声称支持事务,那么该数据库必须具备ACID四个特性,即Atomicity(原子性)、Consistency (一致性)、Isolation(隔离性)和Durability(持久性)。
事物并发带来的问题
- 脏读:事务A可以读取到事务B未提交的执行结果,即读取未提交的数据。
- 幻读:事务A读取不到事务B未提交、已提交的执行结果。这会产生一个新的问题,即事务B插入一条数据并提交,事务A查询不到事务B提交的数据,也无法插入同样的数据,产生“幻读”。
- 不可重复读:事务A只能读取到事务B已提交的执行结果。事务A执行同样的查询,在事务B提交之前、提交之后,会得到不同的查询结果。
MySQL的事物隔离级别
MySQL的事务隔离级别有4种,由低到高分别是读未提交、不可重复读、可重复读和串行化。大多数数据库默认的事务隔离级别是不可重复读,而MySQL默认的事务隔离级别是可重复读。
| 事务隔离级别 | 描述 |
|---|---|
| 读未提交(read-uncommitted ) | 一个事务可以读取另一个事务未提交的数据,会产生脏读,一个事务只能读取到其他事务已提交的数据。 |
| 不可重复读(read-committed ) | 解决了脏读问题,但这样又会出现另一个问题,即对于同一数据A事务在B事务提交之前、提交之后可能会读取到不同的结果,这就会产生不可重复读。一个事务在其他事务提交之前、提交之后,对于同一数据读取到的结果是相同的。 |
| 可重复读(repeatable-read ) | 解决了不可重复读问题。但这样又会出现另一个问题,即事务B插入一条数据并提交,事务A查询不到事务B提交的数据,也无法插入同样的数据,产生“幻读”。 |
| 串行化( serializable ) | 最高的事务隔离级别,在该级别下事务是按照串行的顺序执行的。串行化可以避免脏读、不可重复读与幻读。但是这种事务隔离级别效率低下,比较耗数据库性能,一般不使用。 |
不同隔离级别可能产生的问题
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 可能 | 可能 | 可能 |
| 不可重复读 | 不可能 | 可能 | 可能 |
| 可重复读 | 不可能 | 不可能 | 对InnoDB不可能 |
| 串行化 | 不可能 | 不可能 | 不可能 |
设置隔离级别
从MySQL 5.7.20开始,就增加了变量transaction_isolation作为tx_isolation的别名。从MySQL8.0开始,变量 tx_isolation被弃用并删除,使用transaction_isolation表示事务的隔离级别。
#查看事务隔离级别
select @@transaction_isolation;#或者
show variables like 'transaction_isolation';#设置事务隔离级别
set transaction_isolation ='read-uncommitted';
锁机制
锁是计算机协调多个进程或线程并发访问集一资源的机制。在数据库中,除传统的计算资源(如CPU、RAM、I/O等)的争用以外,数据也是一种共享的资源。如何保证数据并发访问的一致性、有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。因此,锁对数据库而言显得尤其重要,也更加复杂。
相对其他数据库而言,MySQL的锁机制比较简单,其最显著的特点是不同的存储引擎支持不同的锁机制。按照锁的粒度来划分,可以分为表锁、行锁和页锁。
| 描述 | MyISAM | InnoDB | BDB | |
|---|---|---|---|---|
| 表锁 | 开销小,加锁快;不会出现死锁;锁定力度大,发生锁冲突概率高,并发度最低 | 1 | 1 | 1 |
| 行锁 | 开销大,加锁慢;会出现死锁;锁定粒度小,发生锁冲突的概率低,并发度高 | 0 | 1 | 0 |
| 页锁 | 开销和加锁速度介于表锁和行锁之间;会出现死锁;锁定粒度介于表锁和行锁之间,页锁,并发度一般 | 0 | 0 | 1 |
MyISAM的表锁
MyISAM存储引擎只支持表锁。在执行查询操作( select)前,会自动给涉及的所有表加读锁;在执行更新操作( insert、update、delete等)前,会自动给涉及的所有表加写锁。
| 是否兼容 | 读锁 | 写锁 |
|---|---|---|
| 读锁 | 是 | 否 |
| 写锁 | 否 | 否 |
说明:
- MyISAM表的读操作,不会阻塞其他用户对相同表的读操作,但会阻塞对相同表的写操作;
- MyISAM表的写操作,会阻塞其他用户对相同表的读操作、写操作;
- MyISAM表的读、写操作之间,以及写操作之间是串行的。
lock tables xxx read; # 加表锁
InnoDB的行锁
InnoDB存储引擎既支持行锁也支持表锁,但默认情况下是采用行锁。InnoDB的行锁是通过锁定索引项来实现的,而不是锁定物理行记录。InnoDB的锁,与索引、事务的隔离级别有关。InnoDB的锁类型有很多种,这也是需要我们重点掌握的。
| 锁 | 描述 |
|---|---|
| 共享锁 | Share Locks,即S锁,读锁。当一个事务对某行上读锁时,允许其他事务对该行进行读操作,但不允许写。 |
| 排他锁 | Exclusive Locks,即X锁,写锁。当一个事竟对某行数据上排他锁,其他事务就不能再对该行上任何锁。 |
| 意向锁 | Intention Locks,包括意向共享锁和意向排他锁,是表级锁,InnoDB自动添加,无需要人工干预。 |
| 记录锁 | Record Locks,锁定索引记录,可以防止其他事务更新或删除行。 |
| 自增锁 | Auto-inc Locks,针对自动增长的主键。 |
| 间隙锁 | Gap Locks,锁定索引记录之间的间隙。 |
| 临键锁 | Next-key Locks,记录锁与间隙锁的组合。 |
begin; # 开启一个事物,innodb一般是事物中的
commit;
友好的共享锁
共享锁(Share Locks )也称之为S锁、<读锁当一个事务对某行记录上了共享锁,允许其他事务对该记录进行读操作,但不允许写操作。
#共享锁加锁方式
SELECT ...LOCK IN SHARE MODE
霸道的排他锁
排他锁(Exclusive Locks )也称之为X锁、写锁当一个事务对某行记录上了排他锁,其他事务即不能对该行记录进行读操作,也不能进行写操作。InnoDB会自动对增删改操作加排他锁。
#另一种加排他锁的方式
SELECT ... FOR UPDATE
自增锁及其作用
自增锁(Auto-inc Locks)是当向含有AUTO_INCREMENT列的表中插入数据时需要获取的一种特殊的表级锁。在最简单的情况下,如果一个事务正在向表中插入值,则任何其他事务必须等待对该表执行自己的插入操作,以便第一个事务插入的行的值是连续的。
特殊的表级锁: insert出现在事务中,自增锁是在insert之后立即释放,而不是等事务提交才释放。
InnoDB还提供了参数innodb_autoinc_lock_mode 用于设置自增锁模式,它可以对插入操作实现性能与并发的平衡。
取值说明:
- 0 : traditional,传统锁模式,语句级锁,保证值分配的可预见性、连续性、可重复性,保证主从复制的一致性。
- 1 : consecutive,连续锁模式,锁在语句得到值后就释放,并发插入性能优于传统模式,MySQL 5.x默认模式。
- 2 : interleaved,交错锁模式,最快最具扩展性的模式,基于binlog的复制与恢复不安全,MySQL 8.0默认模式。
InnoDB的三种行级锁
除了表级锁之外,InnoDB还支持行级锁,行级锁能够有效地减少锁冲突。按照锁定范围的不同,MySQL支持3种行级锁:记录锁、间隙锁和临键锁。
| 锁 | 描述 |
|---|---|
| 记录锁 | Record Locks,锁定某行记录。 |
| 间隙锁 | Gap Locks,锁定一个范围,不包括记录本身。 |
| 临键锁 | Next-key Locks,锁定记录本身和左右两边相邻的范围。 |
主从复制
主从复制是MySQL的重要功能之一。主从复制是指一个节点作为主数据库,另外一个或多个节点作为从数据库,主数据库中的数据自动复制到从数据库中。
主从复制的原理
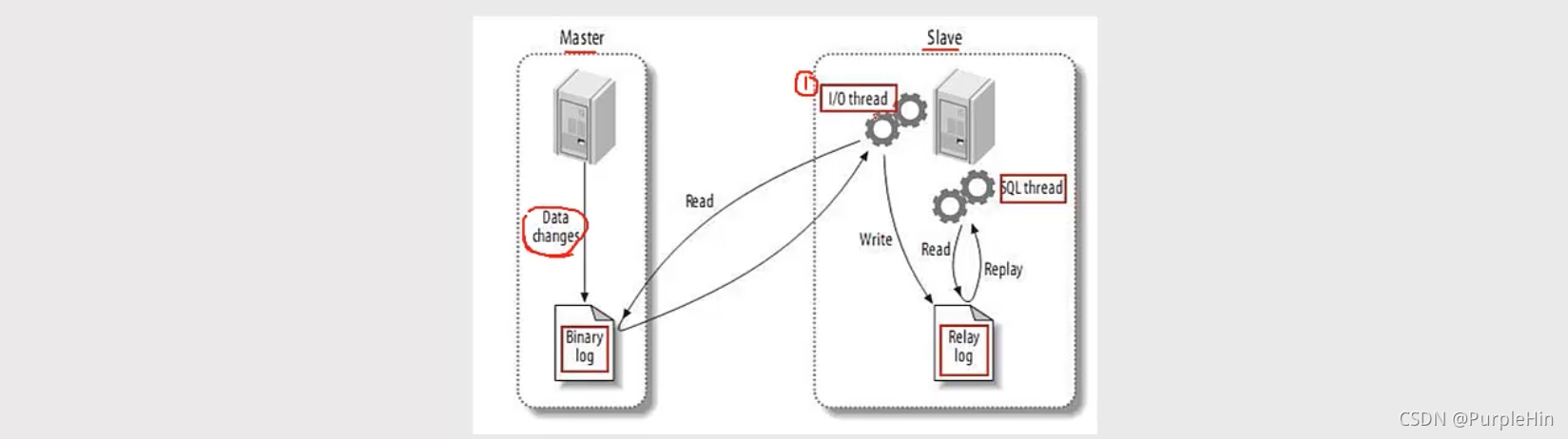
- Master上面的任何修改都会保存在二进制日志Binary log里面。
- Slave上面启动一个V/O thread,连接到Master上面请求读取二进制日志,然后把读取到的二进制日志写到本地的一个Realy log里面。
- Slave上面开启一个SQL thread定时检查Realy log,如果发现有更改立即把更改的内容在本机上面执行一遍。
常见的几种主从架构
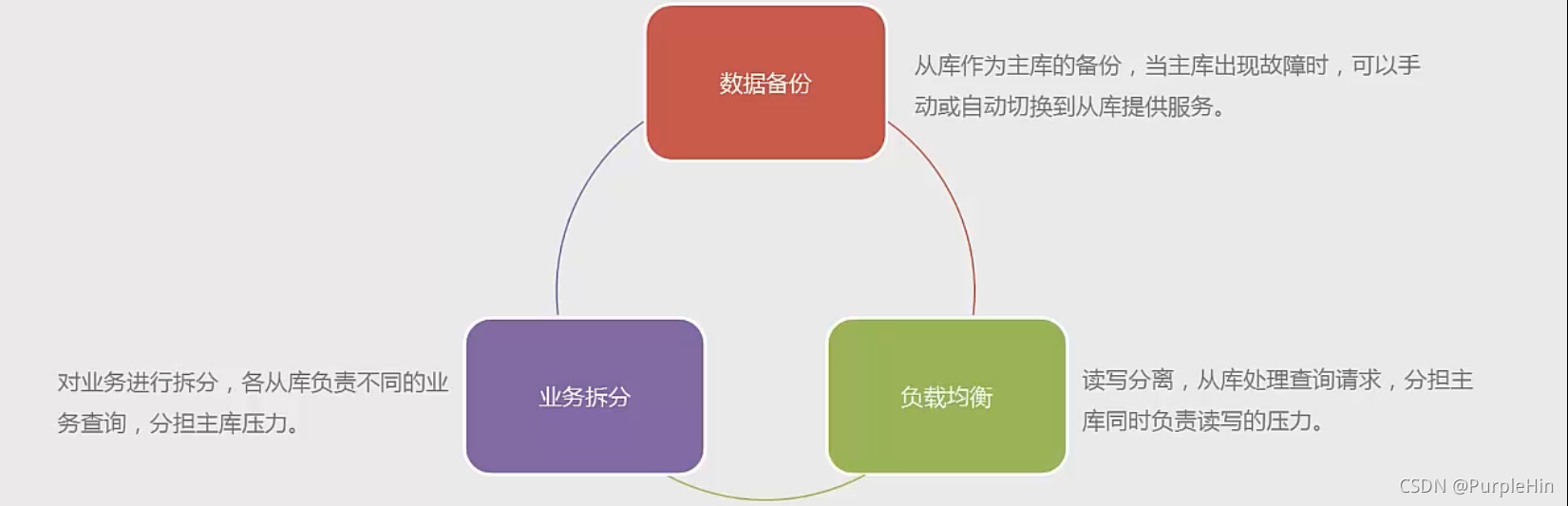
- 一主一从通常用于做热备(如果Master节点宕机,Slave节点能切换为Master继续提供服务),以提高系统的可用性和容灾,并非用于提高系统的性能。
- 一主多从的主从架构中有多个Slave节点,这些Slave节点可以做热备,可以做数据备份,可以做查询统计。一主多从能够提高系统的性能、可用性和容灾性。
- 对于一主多从(Maste)节点的压刀非吊大,如宋IMIaSlel mE, 的上的言可田旧容易造成催生了双主架构,即主主复制。主主复制可以在一定程序上保证Master节点的高可用,但容易造成数据的不一致。
- 级联复制主要用于减轻Master节点的压力。
主从复制的几种方式
MySOL的主从复制有异步复制、全同步复制和半同步复制3种方式,默认采用的是异步复制。
- 异步复制:Master将事务binlog事件写入到binlog文件中,此时Master会通知Dump线程发送这些新的binlog,然后Master就会继续处理提交操作,而不会保证这些binlog传到任何一个Slave节点上。
- 全同步复制:当Master提交事务之后,所有的Slave节点必须收到、APPLY并且提交这些事务,Master才能继续做后续操作。
- 半同步复制:介于异步复制与全同步复制之间,Master只需要等待至少一个从库节点收到并且Flush binlog到Relay Log文件即可,Master不需要等待所有Slave的反馈。
主从复制的实现(异步)
两个MySQL节点做主从,Master : 192.168.81.128,Slave : 192.168.81.129。
修改Master节点的配置文件my.cnf,修改完成后重启MySQL
[mysql]
server_id=1
# 开启binlog日志
log-bin=mysql-bin
# 不需要同步数据库
binlog-ignore-db=mysql
在Master节点创建用户,给Slave节点使用
create user 'repl'@'192.168.81.129' identified with mysql_native_password by 'Repl_123';
grant replication slave on *.* to 'repl' @'192.168.81.129';
flush privileges;
获取主节点binlog文件名和位置( position)
SHOW MASTER STATUS;
修改Slave节点配置文件my.cnf,修改完成后重启MySQL
[mysql]
server_id=2
在Slave节点执行命令
change master to master_host='192.168.81.128',master_port=3306,
master_user='repl',
master_password='Repl_123",
master_log_file='mysql-bin.000001',
master_log_pos=1725;
开启主从复制
start slave;
查看主从复制状态
show slave status;
停止主从复制
stop slave;
半同步复制
MySQL缺省采用异步复制方式,选择异步复制主要是出于性能考虑,与同步复制相比,异步复制显然更快,但异步复制的缺点也同样明显。
- 异步复制无法保证主从数据的实时一致性。如果做读写分离,写主库读从库,要求从库实时能够读取到主库写入的数据,则异步复制无法满足该需求。
- 异步复制可能会导致数据丢失。例如主库宕机,已经提交的事务可能还没传到从库上,此时如果进行主从切换,可能会导致新主库上的数据是缺失的。
MySQL的半同步复制是通过插件Semi-sync实现的,安装插件后才可以通过与之关联的参数来控制它。在安装插件之前,这些参数是不可用的。
说明
- MySQL发行版包含了主从两端的半同步复制插件文件semisync_master.so和semisync_slave.so,缺省位于MySQL安装目录下的lib/plugin目录下。
- 必须在主库和从库都启用半同步复制,否则使用异步事制。从库在连接主库时表明它是否支持半同步复制。
- 如果在主库启用了半同步复制,并且至少有一个支持半同步复制的从库,则主库上执行事务提交的线程将等待,直到至少一个半同步从库确认已收到事务的所有事件(从库会向主库发送ACK,Acknowledgement ),或者直到发生超时。
- 只有在将事件写入其中继日志并刷新到磁盘后,从库才会确认收到事务的事件,向主库发送ACK。
- 如果在没有任何从库确认事务的情况下发生超时,则主库将退化为异步复制。当至少有一个半同步从库赶上时,主库恢复半同步复制。
半同步复制的实现
主库配置
#查看是否安装半同步复制插件
rpl_semi_sync_mastershow plugins;
#安装半同步复制插件
install plugin rpl_semi_sync_master soname 'semisync_master.so';
#启用半同步复制插件
show variables like 'rpl%';
set persist rpl_semi_sync_master_enabled=on;
#检查半同步复制插件是否安装成功
SELECT PLUGIN_NAME, PLUGIN_STATUSFROM INFORMATION_SCHEMA.PLUGINSWHERE PLUGIN_NAME LIKE '%semi%';
从库配置
#查看是否安装半同步复制插件
rpl_semi_sync_slaveshow plugins;
#安装半同步复制插件
install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
#启用半同步复制插件
show variables like 'rpl%';
set persist rpl_semi_sync_slave_enabled=on;
#重启从库I/O线程(重启后配置才生效)
stop slave io_thread;
start slave io_thread;
延时复制
MySQL主从延时复制就是设置一个固定的延迟时间(n秒),即当主库数据发生变更时,从库隔n秒才开始同步。
实现主从的延时复制,只需要在Slave节点修改MASTER_DELAY参数的值即可。
stop slave;
change master to master_delay=10; // 延迟时间
start slave;
上述操作完成后,查看Slave状态,可以看到与延时复制有关的2个参数。
- SQL_Delay :显示已设置的主备延迟的时间,单位秒
- SQL_Remaining_Delay:显示剩余的主备延迟时间,单位秒
读写分离
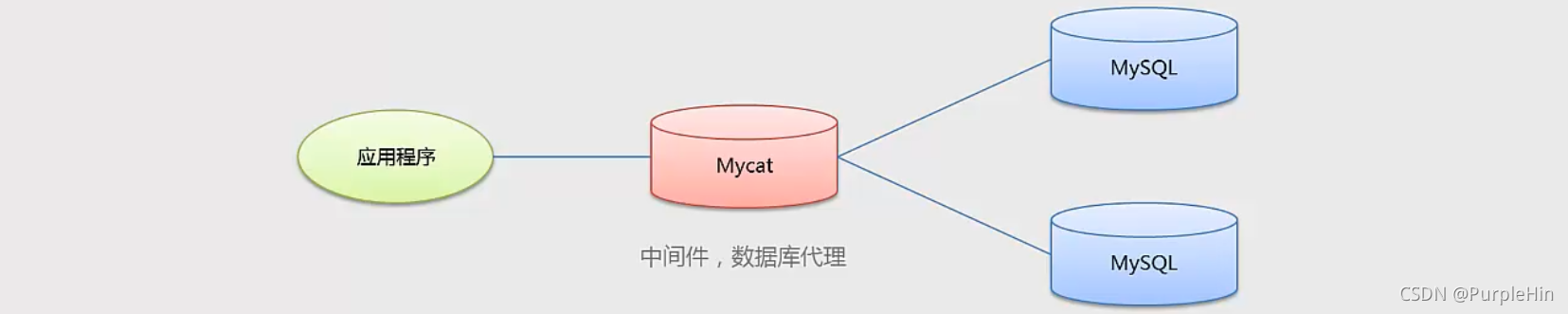
数据库中间件
数据库中间件介于应用程序与数据库之间。中间件本身并不存储数据,数据是在后端的数据库中存储的;但对于应用程序而言,中间件近似等于数据库。
| 中间件 | 描述 |
|---|---|
| MySQL Proxy | MySQL Proxy是MySQL官方提供的数据库中间件,但官方不推荐将其用于生产环境。下载地址: https://downloads.mysql.com/archives/proxy/ |
| MySQL Router | MySQL Router是MySQL官方提供的一个轻量级MySQL中间件,用于取代SQL Proxy.下载地址: https://dev.mysql.com/downloads/router/ |
| Mycat | 基于阿里开源的Cobar产品而研发,社区比较活跃。,官方网站:http://www.mycat.org.cn/ |
| Atlas | Atlas是由奇虎360基于MySQL Proxy改写的数据库中间件。下载地址: https://github.com/Qihoo360/Atlas |
| Amoeba | Amoeba for Mysql致力于MySQL的分布式数据库前端代理层。下载地址:https://sourceforge.net/projects/amoeba/files/ |
| TDDL | TDDL ( Taobao Distributed Data Layer ),具有主备,读写分离,动态数据库配置等功能。下载地址:https:/lgitee.com/justwe9891/TDDL |
| ShardingSphere | Apache ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,已于2020年4月16日成为Apache 软件基金会的顶级项目。官方网站:http://shardingsphere.apache.org |
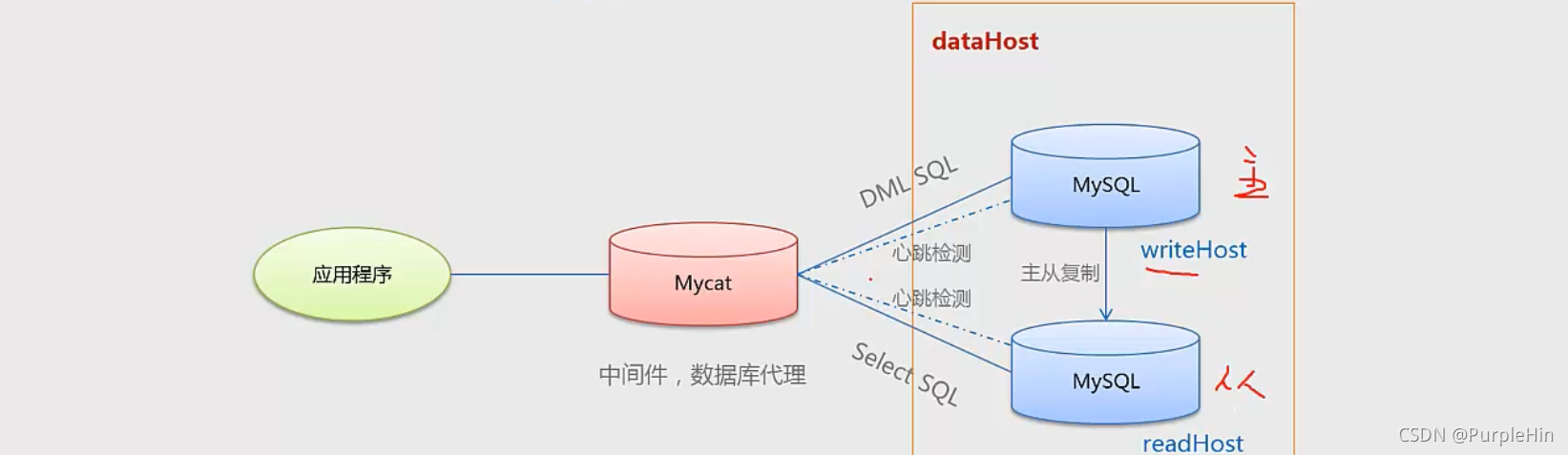
MyCat读写分离架构
随着应用的访问量和并发量的增加,对数据库做读有分离是很有必要的,这样能够分担主库压力。读写分离的前提是数据库已经做好主从复制
MyCat的配置
server.xml:server.xml包含mycat的系统配置信息,它有两个标签system和user。system标签中的参数主要用于Mycat调优,user标签中的参数用于定义Mycat的用户和权限。
<system>
<property name="serverPort" >8066</property>服务端口
<property name="managerPort" > 9066</property>管理端口
<property name="processors">1</property>
<property name="processorExecutor"> 32</property>
</system>
<user name="user" > MySQL用户账号
<property name="password" > user</property>密码
<property name="schemas">TESTDB</property>库名
<property name="readOnly" >true</property>
<property name="defaultSchema" >TESTDB</property>
</user>
schema.xml:schema.xml用于定义mycat的逻辑库,管理着mycat的逻辑库、表、分片规则、DataNode以及DataSource。
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="travelrecord,address" dataNode="dn1,dn2,dn3"
rule="auto-sharding-long" splitTableNames ="true" />
</schema>
分片
<dataNode name="dn1" dataHost="localhost1" database="db1" />
balance即是否开启读写分离
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="O" writeType="0"
dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
主库
<writeHost host="hostM1" url="master:3306" user= "root" password="123456">
从库
<readHost host="hostS1" url="slave:3306" user="root" password="123456"/>
</writeHost>
</dataHost>
数据库备份和数据恢复
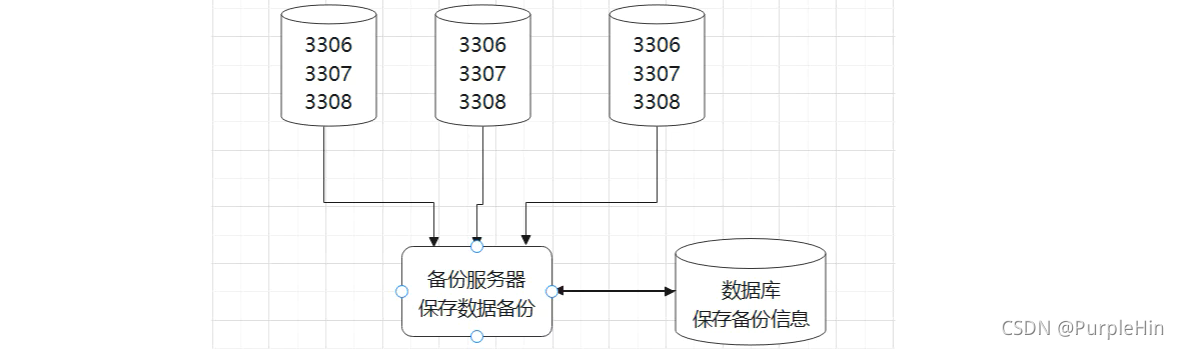
整个备份环境包括
- 备份服务器
- 需要备份的各服务器上的数据库。
各服务器上数据库备份完成以后,会自动发送备份邮件,并将备份文件自动发送到备份服务器上进行异机备份。
备份服务器上部署有数据信息库,会将需要备份的所有数据库信息,以及生成的备份文件信息(备份的大小,文件名,备份时间等)和备份过程的日志保存在数据库中。
数据备份工具:mysqldump
# 备份指定的数据库或者某些表
mysqldump [options] db_name [tables]
# 备份指定的一个或多个数据库
mysqldump [options] --databases db1 [db2][db3]
# 备份所有数据库
mysqldump [options] --all-database
such as
mysqldump -uroot -p --all-database > all.sql
数据恢复
source 备份文件目录;
数据量大的可使用Xtrabackup,mysqldump只适用于数据量小于10G都数据